Облачные вычисления обеспечивают предоставление по требованию ресурсов и услуг через Интернет, как правило, в масштабах и с показателями надежности, характерными для центра обработки данных. MapReduce ― это модель программирования, предназначенная для параллельной обработки больших объемов данных с разделением работы на множество независимых задач. Это стиль параллельного программирования, который поддерживается некоторыми облачными службами, работающими по принципу "емкость по требованию", такими как Google BigTable, Hadoop и Sector.
В этой статье используется алгоритм выравнивания нагрузки, соответствующий подходу рандомизированного гидродинамического выравнивания нагрузки (подробнее об этом - в следующих разделах). Виртуализация используется для уменьшения фактического количества физических серверов и стоимости ресурсов; что еще важнее, виртуализация позволяет добиться эффективного использования процессоров физической машины.
Чтобы получить максимум пользы от этой статьи, нужно иметь общее представление о концепции облачных вычислений, методе рандомизированного гидродинамического выравнивания нагрузки и модели программирования Hadoop MapReduce. Поможет и общее представление о параллельном программировании, а любые знания в области программирования на языке Java или других объектно-ориентированных языках станут хорошим инструментом поддержки.
В этой статье алгоритм MapReduce реализован в системе с использованием:
- Hadoop 0.20.1,
- Eclipse IDE 3.0 или выше (либо Rational Application Developer 7.1),
- Ubuntu 8.2 или выше.
Прежде чем погрузиться в алгоритм MapReduce, мы рассмотрим основы облачной архитектуры, выравнивания нагрузки, MapReduce и параллельного программирования.
На рисунке 1 показана подробная схема всей системы, платформ, программного обеспечения и их использования для достижения цели, поставленной в этой статье.
Рисунок 1. Облачная архитектура
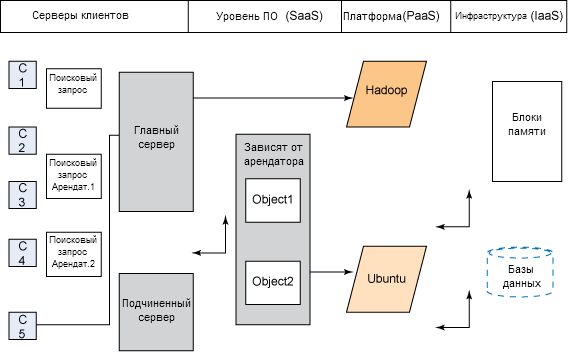
Как видите, в качестве операционных систем используются Ubuntu 9.04 и 8.2; в качестве платформ ― Hadoop 0.20.1, Eclipse 3.3.1 и Sun Java 6; в качестве языка программирования ― Java; а в качестве языков сценариев ― HTML, JSP и XML.
Эта облачная архитектура содержит главный и подчиненные узлы. В данной реализации основной сервер получает запросы от клиентов и обрабатывает их в зависимости от типа запроса. Главный узел находится в основном сервере, а подчиненные узлы ― в дополнительном сервере.
Поисковые запросы направляются в узел NameNode платформы Hadoop, которая находится в главном сервере, как видно на рисунке 2. Затем Hadoop NameNode выполняет операции поиска и индексирования, инициируя большое количество процессов Map и Reduce. Когда операция MapReduce для определенного ключа поиска завершена, NameNode возвращает выходное значение серверу, а тот, в свою очередь, ― клиентам.
Рисунок 2. Функции Map и Reduce выполняют поиск и индексирование
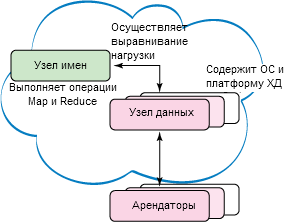
Если запрос обращен к определенному программному обеспечению, выполняется проверка подлинности на основе идентификатора арендатора клиента с учетом оплаты, прав на использование соответствующего ПО и срока его аренды. Затем сервер выполняет этот запрос и позволяет пользователю работать с выбранным набором ПО.
Здесь реализовано свойство multitenancy SaaS, когда один экземпляр программного обеспечения обслуживает нескольких арендаторов. Запрос каждого арендатора изолируется от других с применением его идентификатора. Все эти запросы обслуживаются одним экземпляром ПО.
Если определенный клиентский запрос арендатора состоит в поиске файлов или употреблении какого-либо другого multitenant-ПО, используется Hadoop на предоставленном экземпляре операционной системы (PaaS). Кроме того, для хранения своих данных - возможно, базы данных или файлов - в облаке, клиенту потребуется некоторый объем памяти центра обработки данных (IaaS). Все эти шаги прозрачны для конечного пользователя.
Рандомизированное гидродинамическое выравнивание нагрузки: основы
Выравнивание нагрузки используется для того, чтобы никакие ресурсы не простаивали, пока используются другие. Для распределенного выравнивания нагрузки можно переносить нагрузку от узлов-доноров (где наблюдается избыток рабочей нагрузки) к сравнительно мало нагруженным узлам.
Выравнивание нагрузки во время выполнения программы называется динамическим выравниванием нагрузки - это можно делать прямым или итерационным методом по выбору исполняющего узла:
- при итерационных методах конечный узел назначения определяется за несколько итераций;
- при прямых методах конечный узел назначения выбирается за один шаг.
В этой статье применяется метод рандомизированного гидродинамического выравнивания нагрузки, гибридный метод, который использует преимущества обоих методов ― прямого и итерационного.
Программы MapReduce предназначены для параллельного вычисления больших объемов данных. Для этого необходимо распределять нагрузку между большим количеством машин. Hadoop представляет собой систематический способ реализации этой парадигмы программирования.
В процессе вычисления множество входных пар ключ/значение преобразуется в множество выходных пар ключ/значение. При этом выполняются две основные операции: Map и Reduce.
Операция Map, написанная пользователем, преобразует входную пару ключ/значение в набор промежуточных пар. Библиотека MapReduce группирует все промежуточные значения, связанные с одним и тем же промежуточным Ключом №1, и передает их функции Reduce.
Функция Reduce, также написанная пользователем, принимает промежуточный Ключ №1 и набор значений для этого ключа. Она объединяет эти значения, формируя по возможности меньший набор значений. Обычно при каждом вызове Reduce образуется выходное значение 0 или 1. Промежуточные значения передаются в функцию Reduce пользователя с помощью итератора (объекта, который позволяет программисту перебрать все элементы коллекции, независимо от ее конкретной реализации). Это позволяет обрабатывать списки значений, которые слишком велики, чтобы поместиться в памяти.
Возьмем, к примеру, задачу WordCount. Она подсчитывает количество вхождений каждого слова в большом собрании документов. Функции Mapper и Reducer будут выглядеть, как показано в листинге 1.
Листинг 1. Функции Map и Reduce в задаче WordCount
mapper (filename, file-contents):
for each word in file-contents:
emit (word, 1)
reducer (word, values):
sum = 0
for each value in values:
sum = sum + value
emit (word, sum)
|
Функция Map выдает каждое слово, плюс соответствующее количество вхождений. Reduce суммирует все значения для данного слова. Построенная на кластере, эта базовая функциональность легко может превратиться в высокоскоростную систему параллельной обработки данных.
Выполнение вычислений над большими объемами данных производилось и раньше, как правило, в распределенной среде. Уникальным Hadoop делает упрощенная модель программирования, которая позволяет быстро писать и тестировать распределенные системы, - и эффективное, автоматическое распределение данных и работы между машинами с использованием внутреннего параллелизма процессорных ядер.
Попробуем разобраться в этом. Как говорилось выше, Hadoop-кластер содержит следующие узлы:
- NameNode (главный узел облака);
- узлы DataNode (подчиненные узлы).
В узлах кластера есть предустановленные локальные входные файлы. Когда запускается процесс MapReduce, NameNode использует процесс JobTracker для назначения задач, которые должны решаться узлами DataNode посредством процессов TaskTracker. В каждом DataNode работает несколько процессов Map, и промежуточные результаты передаются в суммирующий процесс, который ведет, например, подсчет слов в файле в одной машине (как в случае задачи WordCount). Значения смешиваются и направляются в процессы Reduce, которые выдают окончательное решение задачи.
Как используется выравнивание нагрузки
Выравнивание нагрузки полезно для равномерного перераспределения нагрузки между свободными узлами, когда узел перегружен. При исполнении алгоритма MapReduce выравнивание нагрузки не столь критично, но оно становится необходимым при работе с крупными файлами и когда загрузка аппаратных ресурсов имеет решающее значение. Это повышает эффективность использования оборудования в условиях ограниченных ресурсов с небольшим улучшением в производительности.
Специальный модуль выравнивает использование дискового пространства в кластере Hadoop с распределенной файловой системой, когда некоторые узлы обработки данных переполняются или когда к кластеру присоединился новые, свободные узлы. По достижении некоторого порогового значения запускается балансировщик (инструмент Class Balancer); этот параметр может принимать значение от 0 до 100%, а его значение по умолчанию составляет 10%. По нему определяется, сбалансирован ли кластер; чем меньше пороговое значение, тем лучше будет сбалансирован кластер. Но и тем больше времени потребуется для выравнивания нагрузки. (Примечание. Пороговое значение может оказаться настолько мало, что сбалансировать состояние кластера вообще не удастся, так как приложения могут записывать и удалять файлы одновременно.)
Кластер считается сбалансированным, если для каждого узла обработки данных отношение используемой емкости узла к его суммарной емкости (утилизация узла) отличается от отношения используемой емкости кластера к общей емкости кластера (утилизация кластера) не более, чем на пороговое значение.
Модуль перемещает блоки из интенсивно используемых узлов данных в слабо используемые узлы итерационным методом; за каждую итерацию узел передает или получает не больше пороговой доли своей емкости, и каждая итерация работает не более 20 минут.
В этой реализации узлы классифицируются как высоко утилизированные, средне утилизированные и недоиспользуемые. В зависимости от рейтинга утилизации каждого узла нагрузка передается между узлами, и кластер балансируется. Модуль работает следующим образом.
- Сначала он собирает информацию о соседях.
- Когда нагрузка узла DataNode увеличивается до порогового уровня, он посылает в NameNode запрос.
- NameNode содержит информацию об уровнях нагрузки своих ближайших соседей.
- NameNode сравнивает нагрузки и направляет в DataNode подробную информацию о свободных соседних узлах.
- Затем в работу включается DataNode.
- Каждый узел DataNode сравнивает свой объем нагрузки с суммарной нагрузкой своих ближайших соседей.
- Если уровень нагрузки DataNode больше суммы нагрузок соседних узлов, то нагрузка передается узлам (непосредственным соседям И другим узлам), которые выбираются случайным образом.
- После этого в выбранные узлы направляются запросы нагрузки.
- Наконец, запрос принят.
- В каждом узле имеются буферы входящих запросов нагрузки.
- Этим буфером управляет интерфейс передачи сообщений (MPI).
- Основной поток анализирует очередь в буфере и обслуживает поступающие запросы.
- Узлы вступают в фазу выполнения выравнивания нагрузки.
Различные наборы исходных файлов разного размера обрабатывались задачей MapReduce как в одно-, так и в двухузловых кластерах. При этом измерялось время выполнения, и мы пришли к выводу, что для исходных файлов большого размера MapReduce работает в кластерах гораздо эффективнее.
График, изображенный на рисунке 3, иллюстрирует результирующую производительность разных узлов.
Рисунок 3. Выравнивание нагрузки MapReduce эффективнее работает в кластерах
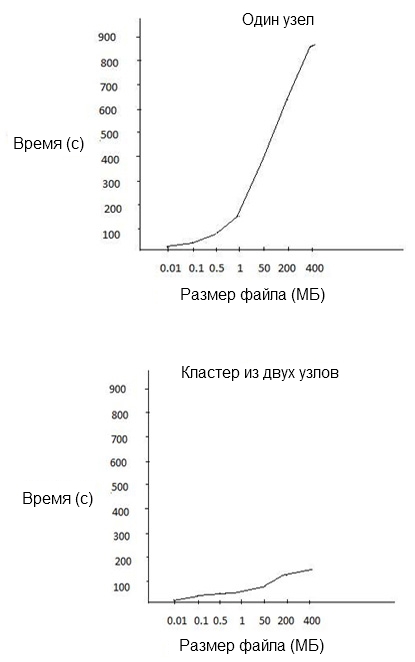
Наш эксперимент с Hadoop MapReduce и выравниванием нагрузки привел к двум несомненным выводам:
- В облачной среде структура MapReduce повышает эффективность обработки больших наборов данных. С другой стороны, в необлачной системе такое увеличение пропускной способности не гарантировано.
- Когда набор данных невелик, MapReduce и выравнивание нагрузки не приводят к значительному увеличению пропускной способности облачной системы.
Таким образом, при планировании обработки больших объемов данных в облачной системе следует рассмотреть сочетание параллельной обработки в стиле MapReduce и выравнивания нагрузки.