Законы микроэкономики утверждают, что система из специализированных элементов является более эффективной, чем та, в которой большинство участников выполняют все разнообразные действия, необходимые для существования этой системы. Образно говоря, мастер на все руки менее продуктивен в каждом конкретном деле, чем специалист в данной области. Этот факт известен под названием "сравнительное преимущество" (comparative advantage) - индивидуум имеет преимущество в выполнении специфической задачи, если он более опытен в выполнении этой задачи относительно других задач. Специализация способствует получению специфичных навыков.
Облачные вычисления прекрасно дополняют абстракцию MapReduce, позволяя не задумываться о том, где именно осуществляются операции над конкретными числами. Прежде чем рассматривать пример, давайте выясним, почему так успешна MapReduce.
MapReduce и облако
Принцип программирования MapReduce был разработан в Google. В документе MapReduce: упрощение обработки данных в больших кластерах (EN), опубликованном инженерами Google, подробно описываются принципы работы MapReduce. С момента появления этой публикации в 2004 году появилось множество реализаций MapReduce с открытыми исходными кодами.
Одной из причин успеха принципа MapReduce является то, что он разрабатывался как простая парадигма написания кода, пригодного для массового распараллеливания. Она родилась из идей функционального программирования языка Lisp и других функциональных языков.
Теперь самое интересное: почему MapReduce и облачные вычисления предназначены друг для друга? Основным выигрышным моментом MapReduce является ее способность отделить семантику оперативного распараллеливания (как именно осуществляется распараллеливание) от разработчика.
Если вы работаете в компании, имеющей тысячи свободных машин, - вам повезло, но обычно это не так. И даже при наличии свободных ресурсов часто возникает множество технических, политических и логистических барьеров, которые нужно преодолеть для построения в организации grid-системы.
|
Erlang в распределенныхвычислениях Облачные вычисления оказались приливом, поднявшим многие корабли, в том числе Erlang. Erlang - это уникальный язык программирования, имеющий много особенностей, свойственных операционным системам. В результате он является идеальным языком для создания больших распределенных систем. Неудивительно, что многие "облачные" реализации распределенных алгоритмов, например, CouchDB или Disco, написаны именно на Erlang. Язык Erlang использовался для создания облачных систем еще до того, как само это понятие окончательно сформировалось. |
Используя облако, разработчик может написать сценарий, который загружает любое количество машин и выполняет операции MapReduce, а затем оплатить только то время, которое использовалось на каждой системе. Это может быть 10 минут или 10 месяцев, но в любом случае это просто.
Отличный пример этой парадигмы имел место в Yelp ("Реальные люди. Реальные обзоры®: сайт обзоров для местных компаний"). В техническом блоге компании недавно появилась история о том, как компания использовала MapReduce для реализации функциональности своего сайта под названием People Who Viewed this Also Viewed... (Люди, просматривающие это, также просматривают…). Это классическая проблема больших данных, поскольку Yelp ежедневно генерирует 100 ГБ журнальных данных.
Вначале инженеры установили свой собственный кластер Hadoop, но в конечном итоге написали свою собственную MapReduce-инфраструктуру mrjob, работающую на сервисе Amazon Elastic MapReduce. Дэйв М. (Dave M), инженер по поиску и извлечению данных Yelp, рассказывает:
"Как мы реализовали функциональность People Who Viewed this Also Viewed...? ... Как вы могли бы догадаться, мы использовали MapReduce. MapReduce - это простейший способ разбить большую работу на маленькие части. По существу, распределители (mappers) читают строки входной информации и выдают кортежи ключ/значение (key, value). Каждый ключ и все соответствующие ему значения направляются в reducer... простое задание MapReduce, подсчитывающее частоту встречаемости слов и написанное в нашей Python-среде mrjob".
Дэйв М. продолжает:
"Мы делали то, что делают многие компании, работающие с кластером Hadoop... всякий раз, размещая наш код на Web-серверах, мы направляли его в Hadoop-машины.
Отчасти это было круто - наши задания могли ссылаться на любой другой код в нашей базе кода.
Но также это было не очень круто. Нельзя было с уверенностью сказать, собирается ли вообще выполняться задание, если не подтолкнуть его. Но, что хуже всего, большую часть времени наш кластер простаивал, затем изредка проходила действительно объемная работа, занимающая все наши узлы, при этом все остальные задания вынуждены были ждать".
MapReduce, выполняющаяся в облаке Amazon, помогла Yelp отправить в отставку их собственный кластер Hadoop. А инфраструктура Yelp mrjob теперь настолько стабильна (на протяжении года), что компания предоставила ее в общее пользование на GitHub.
Сочетание облачных вычислений и MapReduce идеально приспособлено для работы с большими объемами данных. Теперь я покажу вам, как обрабатывать большое количество журнальных данных.
Обработка реального журнального файла
Реальной проблемой, с которой сталкиваются многие, является обработка больших объемов журнальных данных. Исходный код, приведенный в листинге 1 (также доступен для загрузки), является примером того, как обработать 6.3 ГБ журнальных файлов Internet Information Services (IIS), используя только модуль многопроцессорной обработки Python. Его работа на MacBook Pro продолжалась примерно 2 минуты, в результате чего было получено 25 наиболее часто встречающихся IP-адресов.
Листинг 1. Использование модуля MP Python для обработки 6.3 ГБ журнальных файлов
Code Listing: iis_map_reduce_ipsum.py
"N-Core Map Reduce Log Parser/Summation"
from collections import defaultdict
from operator import itemgetter
from glob import glob
from multiprocessing import Pool, current_process
from itertools import chain
def ip_start_mapper(logfile):
log = open(logfile)
for line in log:
yield line.split()
def ip_cut(lines):
for line in lines:
try:
ip = line[8]
except IndexError:
continue
yield ip, 1
def mapper(logfile):
print "Processing Log File: %s-%s" % (current_process().name, logfile)
lines = ip_start_mapper(logfile)
cut_lines = ip_cut(lines)
return ip_partition(cut_lines)
def ip_partition(lines):
partitioned_data = defaultdict(list)
for ip, count in lines:
partitioned_data[ip].append(count)
return partitioned_data.items()
def reducer(ip_key_val):
ip, count = ip_key_val
return (ip, sum(sum(count,[])))
def start_mr(mapper_func, reducer_func, files, processes=8, chunksize=1):
pool = Pool(processes)
map_output = pool.map(mapper_func, files, chunksize)
partitioned_data = ip_partition(chain(*map_output))
reduced_output = pool.map(reducer_func, partitioned_data)
return reduced_output
def print_report(sort_list, num=25):
for items in sort_list[0:num]:
print "%s, %s" % (items[0], items[1])
def run():
files = glob("*.log")
ip_stats = start_mr(mapper, reducer, files)
sorted_ip_stats = sorted(ip_stats, key=itemgetter(1), reverse=True)
print_report(sorted_ip_stats)
if __name__ == "__main__":
run()
|
На рисунке 1 приведена схема обработки.
Рисунок 1. Схема MapReduce для журнального файла IIS
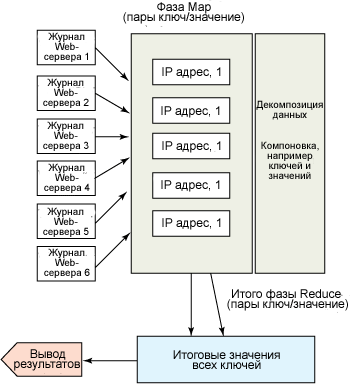
Давайте рассмотрим исходный код. Как можно заметить, он крошечный по объему и состоит примерно из 50 строк:
- Функция mapper фактически выбирает IP-адрес из каждой строки и возвращает его со значением 1. Это фаза извлечения пары (key,value), происходящего в каждом порожденном процессе. По мере получения результаты собираются в chained iterable для подготовки к фазе сокращения (reduction). Этот процесс называется декомпозицией (partitioning) данных.
- На следующем этапе MapReduce все промежуточные результаты сокращаются и суммируются. В нашем примере это функция reduction, осуществляющая фазу сокращения.
- В итоге мы получаем гигантский список и выводим первые 25 результатов.
Хотя для простоты объяснения MapReduce мы используем многопроцессорный модуль, если немного изменить этот код, он будет работать и в другом облаке MapReduce. Полный вывод результатов работы приведен в листинге 2.
Листинг 2. Полный вывод результатов выполнения листинга 1
lion% time python iisparse.py Processing Log File: PoolWorker-1-ex100812.log Processing Log File: PoolWorker-2-ex100813.log Processing Log File: PoolWorker-3-ex100814.log Processing Log File: PoolWorker-4-ex100815.log Processing Log File: PoolWorker-5-ex100816.log Processing Log File: PoolWorker-6-ex100817.log Processing Log File: PoolWorker-7-ex100818.log Processing Log File: PoolWorker-8-ex100819.log Processing Log File: PoolWorker-7-ex100820.log Processing Log File: PoolWorker-3-ex100821.log Processing Log File: PoolWorker-8-ex100822.log Processing Log File: PoolWorker-4-ex100823.log Processing Log File: PoolWorker-6-ex100824.log Processing Log File: PoolWorker-1-ex100825.log Processing Log File: PoolWorker-2-ex100826.log 10.0.1.1, 24047 10.0.1.2, 22667 10.0.1.4, 20234 10.0.1.5, 18180 [...output supressed for space, and IP addresses changed for privacy] python iisparse.py 57.40s user 7.48s system 54% cpu 1:59.47 total |
В основанных на облачных вычислениях реализациях MapReduce (как с открытыми исходными кодами, так и коммерческих) нет недостатка. Можно легко взять примеры из данной статьи и применить их к петабайтам журнальных файлов; именно этим полезна абстракция MapReduce, особенно в облачной среде.
Загрузка
|
Описание |
Имя |
Размер |
Метод загрузки |
|---|---|---|---|
| Пример Python-сценария для данной статьи | MapReducePythonScript.zip | 1 КБ | HTTP |