Hadoop представляет собой систему общего назначения, которая обеспечивает возможность высокопроизводительной обработки данных на ряде распределенных узлов. Но при всем этом Hadoop - многозадачная система, способная одновременно обрабатывать несколько наборов данных для нескольких задач и для нескольких пользователей. Такая возможность параллельной обработки означает, что система Hadoop может эффективнее сопоставлять задачи с ресурсами для оптимизации их использования.
Вплоть до 2008 г. система Hadoop поддерживала один-единственный планировщик, который задействовал логику сервиса JobTracker. Хотя такая реализация была идеальным решением для традиционных пакетных задач Hadoop (например, задач интеллектуального анализа журналов и Web-индексации), она не отличалась гибкостью и не могла адаптироваться. Кроме того, система Hadoop работала в пакетном режиме, в котором задачи поступали в очередь, а инфраструктура Hadoop просто выполняла их в порядке получения.
К счастью, был разработан отчет об ошибках (HADOOP-3412) для реализации планировщика, независимого от логики JobTracker. Что еще более важно, новый планировщик стал подключаемым, и это позволило использовать новые алгоритмы планирования для оптимизации задач, имеющих особые характеристики. Дополнительное преимущество данного изменения - это улучшенная удобочитаемость планировщика, которая открывает возможности для более широких экспериментов, а также возможность адаптации к постоянно расширяющемуся списку приложений Hadoop для растущего списка планировщиков.
Благодаря этому изменению теперь система Hadoop превратилась в многопользовательское хранилище данных, которое поддерживает самые разнообразные типы задач обработки, при этом среда подключаемых планировщиков предоставляет улучшенные возможности управления. Данная среда позволяет оптимально использовать кластер Hadoop в условиях разных рабочих нагрузок (во всем диапазоне от небольших задач до крупномасштабных). Уход от планирования по принципу FIFO (согласно которому приоритетность задачи определяется временем его поступления) позволяет кластеру Hadoop поддерживать различные рабочие нагрузки с разными приоритетами и ограничениями в отношении производительности.
Примечание: эта статья предполагает наличие у читателя определенных знаний в области Hadoop.
Кластер Hadoop имеет относительно простую архитектуру из главных (master) и подчиненных (slave) узлов (см. рисунок 1). Узел NameNode является самым главным объектом всего кластера Hadoop и отвечает за управление пространством имен файловой системы, а также за управление доступом для клиентов. Кроме того, имеется узел JobTracker, в задачу которого входит распределение задач по ожидающим узлам. Эти два объекта (NameNode и JobTracker) являются главным узлами в архитектуре Hadoop. К подчиненным узлам относится TaskTracker, который управляет выполнением задач (включая инициализацию и контроль выполнения задач, получение результатов выполнения задач и оповещение узла JobTracker о завершении выполнения задач). DataNode - это узел хранения в кластере Hadoop, который представляет собой распределенную файловую систему (или, по меньшей мере, какую-то ее часть при наличии нескольких узлов DataNode). Узлы TaskTracker и DataNode являются подчиненными узлами в кластере Hadoop.
Рисунок 1. Элементы кластера Hadoop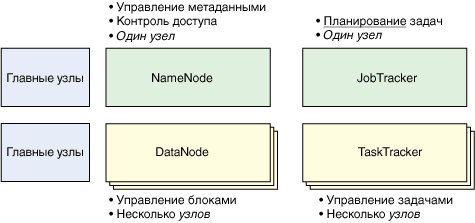
Обратите внимание на то, что система Hadoop является гибкой и поддерживает как кластеры, состоящие из одного узла (когда все объекты находятся на одном узле), так и кластеры из нескольких узлов (когда JobTracker и объекты NameNode распределены по тысячам узлов). О более крупных производственных средах известно мало, но крупнейшим из известных кластеров Hadoop является кластер Facebook, состоящий из 4000 узлов. Эти узлы разделяются по размерам (половина содержит 8- и 16-ядерные центральные процессоры). Кроме того, кластер Facebook поддерживает хранилище емкостью 21 ПБ, распределенное по множеству узлов DataNode. Учитывая большое количество ресурсов и вероятность поступления множества задач от многочисленных пользователей, планирование является важным направлением оптимизации на будущее.
С момента реализации подключаемого планировщика для него были разработаны несколько алгоритмов планирования. В следующих разделах рассматриваются различные доступные алгоритмы и сценарии их применения.
Первоначальный алгоритм планирования, который был интегрирован в JobTracker, назывался FIFO. Используя принцип FIFO ("первым пришел - первым обслужен"), JobTracker извлекал задачи из рабочей очереди в порядке их поступления. Такое планирование не предусматривало никаких концепций приоритетности или размерности задач, но оно было эффективным и простым в реализации.
В основе концепции равномерного планировщика лежит идея о назначении ресурсов задачам таким образом, чтобы в среднем с течением времени каждая задача получала равную долю доступных ресурсов. В результате, задачи, требующие меньше времени, могут обращаться к ЦП и завершаться вперемежку с выполнением задач, которые требуют больше времени. Подобный режим обеспечивает возможность некоторой согласованности задач Hadoop и повышает быстроту реагирования кластера Hadoop на различные типы поступающих задач. Равномерный планировщик был разработан порталом Facebook.
Реализация Hadoop создает набор пулов, в которые помещаются задачи для выборки планировщиком. Каждому пулу может быть назначена некоторая доля ресурсов для обеспечения сбалансированного распределения ресурсов по задачам в пулах (чем больше таких долей, тем больше ресурсов, с помощью которых выполняются задачи). По умолчанию все пулы имеют равное количество долей, но предусматривается возможность конфигурирования для предоставления большего или меньшего числа долей в зависимости от типа задач. Количество задач, активных в один и тот же момент времени, при необходимости также может быть ограничено, чтобы свести к минимуму вероятность перегрузки и обеспечить возможность своевременного выполнения работы.
Для соблюдения принципа равномерного распределения ресурсов каждый пользователь назначается какому-либо пулу. Таким образом, даже если один пользователь запускает много задач, он получает такую же долю ресурсов кластера, что и все остальные пользователи (независимо от количества задач). Независимо от количества назначенных пулам долей, если система не перегружена, задачи получают те доли ресурсов, которые в противном случае остались бы неиспользованными (эти доли распределяются по имеющимся задачам).
Реализация планировщика отслеживает время вычислений для каждой задачи в системе. Периодически планировщик проверяет задачи для определения разницы между временем вычислений для полученной задачи и временем, которое должна была бы получить задача в некоем идеальном планировщике. Результат определяет дефицит для задачи. Затем работа планировщика заключается в том, чтобы следующей была запланирована для выполнения задача с наибольшим дефицитом.
Равная доля ресурсов конфигурируется в файле mapred-site.xml. Данный файл определяет свойства, которые совместно регламентируют режим работы равномерного планировщика. Файл XML (для ссылки на который используется свойство mapred.fairscheduler.allocation.file) определяет назначение доли ресурсов каждому пулу. Для оптимизации в соответствии с размерами задач можно установить свойство mapread.fairscheduler.sizebasedweight, чтобы доли ресурсов назначались задачам в зависимости от их размера. Аналогичное свойство позволяет быстрее завершать выполнение задач меньшего размера путем корректировки весового коэффициента задачи по истечении 5 минут (mapred.fairscheduler.weightadjuster). Доступны и многие другие свойства, которые можно использовать для настройки распределения нагрузок по узлам (например, количество задач Map и Reduce, которыми может управлять узел TaskTracker) и определения того, следует ли производить "вытеснение" (preemption) задачи.
Планировщик вычислительной мощности
Планировщик вычислительной мощности имеет некоторые общие черты с равномерным планировщиком, но есть и значительные отличия. Во-первых, планирование вычислительной мощности предназначено для больших кластеров, которые могут иметь несколько независимых потребителей и несколько целевых приложений. По этой причине планирование вычислительной мощности предлагает расширенные возможности управления, а также предоставляет гарантированную минимальную вычислительную мощность и разделяет излишки вычислительной мощности между пользователями. Планировщик вычислительной мощности был разработан порталом Yahoo!.
При планировании вычислительной мощности вместо пулов создаются несколько очередей, каждая - с конфигурируемым количеством слотов Map и Reduce. Каждой очереди также назначается некоторая гарантированная вычислительная мощность, при этом общая вычислительная мощность кластера представляет собой сумму вычислительных мощностей всех очередей.
Очереди контролируются; и если какая-либо очередь не потребляет выделенную ей вычислительную мощность, излишки вычислительной мощности могут быть временно отданы другим очередям. С учетом того, что очереди могут представлять как физических лиц, так и крупные организации, любая свободная вычислительная мощность перераспределяется для использования другими потребителями.
Еще одно отличие от равномерного планирования - это возможность приоритезации задач в очереди. Как правило, задачи с более высоким приоритетом получают доступ к ресурсам быстрее, чем задачи с более низким приоритетом. В перспективе в Hadoop планируется организовать поддержку "вытеснения" (когда выполнение низкоприоритетной задачи может быть временно приостановлено для обеспечения возможности выполнения задачи с более высоким приоритетом), но эта функция еще не была реализована.
Другим отличием являются средства строгого контроля доступа к очередям (при условии, что очереди привязаны к какому-либо частному лицу или организации). Такие средства управления доступом определяются для каждой отдельной очереди. Они ограничивают возможность отправки задач в очереди, а также возможность просмотра и изменения задач в очередях.
Планировщик вычислительной мощности конфигурируется в нескольких конфигурационных файлах Hadoop. Очереди определяются в файле hadoop-site.xml, а конфигурации очередей - в файле capacity-scheduler.xml. Списки контроля доступа (ACL) можно конфигурировать в файле mapred-queue-acls.xml. Свойства отдельных очередей включают процент вычислительной мощности (где вычислительная мощность, выделяемая для всех очередей в кластере, меньше или равна 100 процентам), максимальную вычислительную мощность (предел использования излишков вычислительной мощности конкретной очередью), а также то, поддерживает ли очередь приоритеты. Что еще важнее, указанные свойства очередей можно настраивать во время выполнения, что позволяет изменять их без перерывов в использовании кластера.
Хотя это и не планировщик в чистом виде, Hadoop также поддерживает концепцию предоставления виртуальных кластеров из более крупных физических кластеров, которая называется Hadoop On Demand (Hadoop по запросу, HOD). Метод HOD предполагает использование диспетчера ресурсов Torque для выделения узлов на основании потребностей виртуального кластера. Выделив узлы, система HOD автоматически подготавливает конфигурационные файлы, а затем инициализирует систему на основании набора узлов в виртуальном кластере. После инициализации виртуальный кластер HOD может использоваться относительно автономно.
Кроме того, концепция HOD является адаптивной, так как обеспечивает сокращение ресурсов при изменении рабочей нагрузки. Обнаружив, что в течение определенного периода времени никакие задачи не выполняются, HOD автоматически удаляет узлы из виртуального кластера. Такой режим работы обеспечивает наиболее эффективное использование ресурсов всего физического кластера.
HOD представляет собой интересную модель для развертывания кластеров Hadoop в условиях облачной инфраструктуры. Преимущества данной модели заключаются в уменьшении совместного использования узлов, повышении степени защиты и (в некоторых случаях) повышении производительности вследствие отсутствия конфликтов в узлах в связи с необходимостью выполнения задач нескольких пользователей.
Когда следует использовать тот или иной планировщик
Из приведенного выше обсуждения вы могли увидеть, для каких целей предназначаются представленные алгоритмы планирования. Если вы используете большой кластер Hadoop с несколькими клиентами и задачами различных типов и с разными приоритетами, лучшим выбором является планировщик вычислительной мощности, который обеспечивает гарантированный доступ с возможностью повторного использования неиспользуемой вычислительной мощности и приоритезации задач в очередях.
Хотя равномерный планировщик является более простым, его применение оправдано в тех случаях, когда одна и та же организация с ограниченным количеством рабочих нагрузок использует и маленькие, и большие кластеры. Равномерное планирование все равно предоставляет средства для неравномерного распределения вычислительной мощности по пулам (задач), но они менее сложны и имеют меньше возможностей конфигурирования. Равномерный планировщик полезен при наличии многообразных задач, поскольку он способен обеспечить быстрое время реакции для сочетания небольших и более масштабных задач (поддерживая более интерактивные модели использования).
Будущие разработки в планировании Hadoop
Теперь, когда планировщик Hadoop стал подключаемым, ожидается разработка новых планировщиков для уникальных развертываний кластеров. В число двух находящихся на стадии разработки планировщиков (из перечня ожидающих решения вопросов Hadoop) входят адаптивный и обучаемый планировщики. Обучаемый планировщик (MAPREDUCE-1349) предназначается для поддержания определенного уровня использования ресурсов при наличии многообразного набора рабочих нагрузок. В настоящее время реализация данного планировщика специализируется на средних показателях загрузки ЦП, однако также планируется учитывать использование ресурсов сети и ресурсов ввода-вывода дисковых подсистем. Адаптивный планировщик (MAPREDUCE-1380) специализируется на адаптивном выделении ресурсов для конкретной задачи на основании производительности и определенных пользователем целей бизнеса.
Внедрение подключаемого планировщика стало еще одним шагом в эволюции кластерных вычислений с использованием системы Hadoop. Поддержка подключаемых планировщиков позволяет использовать (и разрабатывать) планировщики, оптимизированные для конкретной рабочей нагрузки и конкретного приложения. Кроме того, новые планировщики сделали возможным создание многопользовательских хранилищ данных с использованием системы Hadoop благодаря обеспечению возможности совместного использования всей инфраструктуры Hadoop несколькими пользователями и организациями.
Система Hadoop развивается по мере эволюции ее моделей использования и теперь поддерживает новые типы рабочих нагрузок и сценариев использования (например, большие многопользовательские хранилища данных и общие хранилища данных для нескольких организаций). Эти новые гибкие возможности, которые предоставляет Hadoop, являются громадным шагом вперед в направлении более оптимизированного использования кластерных ресурсов при анализе больших объемов данных.