abstract : разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
Лирика
Очень частой проблемой, является попытка понять "насколько быстрый сервер?" Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно - выкиньте и не используйте.
bonnie++ и iozone меряют скорость файловой системы. Которая зависит от кеша, задумчивости ядра, удачности расположения FS на диске и т.д. Косвенно можно сказать, что если в iozone получились хорошие результаты, то это либо хороший кеш, либо дурацкий набор параметров, либо действительно быстрый диск (угадайте, какой из вариантов достался вам). bonnie++ вообще сфокусирована на операциях открытия/закрытия файлов. т.е. производительность диска она особо не тестирует.
dd без опции direct показывает лишь скорость кеша - не более. В некоторых конфигурациях вы можете получать линейную скорость без кеша выше, чем с кешем. В некоторых вы будете получать сотни мегабайт в секунду, при линейной производительности в единицы мегабайт.
С опцией же direct (iflag=direct для чтения, oflag=direct для записи) dd проверяет лишь линейную скорость. Которая совершенно не равна ни максимальной скорости (если мы про рейд на много дисков, то рейд в несколько потоков может отдавать большую скорость, чем в один), ни реальной производительности.
IOmeter - лучше всего перечисленного, но у него есть проблемы при работе в linux. 64-битная версия неправильно рассчитывает тип нагрузки и показывает заниженные результаты (для тех, кто не верит - запустите его на ramdisk).
Спойлер: правильная утилита для linux - fio. Но она требует очень вдумчивого составления теста и ещё более вдумчивого анализа результатов. Всё, что ниже - как раз подготовка теории и практические замечания по работе с fio.
Постановка задачи
(текущая VS максимальная производительность)
Сейчас будет ещё больше скучных букв. Если кого-то интересует количество попугаев на его любимой SSD'шке, ноутбучном винте и т.д. - см рецепты в конце статьи.
Все современные носители, кроме ramdisk'ов, крайне негативно относятся к случайным операциям записи. Для HDD нет разницы запись или чтение, важно, что головки гонять по диску. Для SSD же случайная операция чтения ерунда, а вот запись малым блоком приводит к copy-on-write. Минимальный размер записи - 1-2 Мб, пишут 4кб. Нужно прочитать 2Мб, заменить в них 4кб и записать обратно. В результате в SSD'шку уходит, например, 400 запросов в секундну на запись 4кб которые превращаются в чтение 800 Мб/с (!!!!) и записи их обратно. (Для ramdisk'а такая проблема могла бы быть тоже, но интрига в том, что размер "минимального блока" для DDR составляет около 128 байт, а блоки в тестах обычно 4кб, так что гранулярность DDR в тестах дисковой производительности оперативной памяти не важна).
Этот пост не про специфику разных носителей, так что возвращаемся к общей проблеме.
Мы не можем мерять запись в Мб/с. Важным является сколько перемещений головки было, и сколько случайных блоков мы потревожили на SSD. Т.е. счёт идёт на количество IO operation, а величина IO/s называется IOPS. Таким образом, когда мы меряем случайную нагрузку, мы говорим про IOPS (иногда wIOPS, rIOPS, на запись и чтение соотв.). В крупных системах используют величину kIOPS, (внимание, всегда и везде, никаких 1024) 1kIOPS = 1000 IOPS.
И вот тут многие попадают в ловушку первого рода. Они хотят знать, "сколько IOPS'ов" выдаёт диск. Или полка дисков. Или 200 серверных шкафов, набитые дисками под самые крышки.
Тут важно различать число выполненных операций (зафиксировано, что с 12:00:15 до 12:00:16 было выполнено 245790 дисковых операций - т.е. нагрузка составила 245kIOPS) и то, сколько система может выполнить операций максимум.
Число выполненых операций всегда известно и легко измерить. Но когда мы говорим про дисковую операцию, мы говорим про неё в будущем времени. "сколько операций может выполнить система?" - "каких операций?". Разные операции дают разную нагрузку на СХД. Например, если кто-то пишет случайными блоками по 1Мб, то он получит много меньше iops, чем если он будет читать последовательно блоками по 4кб.
И если в случае пришедшей нагрузки мы говорим о том, сколько было обслужено запросов "какие пришли, такие и обслужили", то в случае планирования, мы хотим знать, какие именно iops'ы будут.
Драма состоит в том, что никто не знает, какие именно запросы придут. Маленькие? Большие? Подряд? В разнобой? Будут они прочитаны из кеша или придётся идти на самое медленное место и выковыривать байтики с разных половинок диска?
Я не буду нагнетать драму дальше, скажу, что существует простой ответ:
- Тест диска (СХД/массива) на best case (попадание в кеш, последовательные операции)
- Тест диска на worst case. Чаще всего такие тесты планируются с знанием устройства диска. "У него кеш 64Мб? А если я сделаю размер области тестирования в 2Гб?". Жёсткий диск быстрее читает с внешней стороны диска? А если я размещу тестовую область на внутренней (ближшей к шпинделю) области, да так, чтобы проходимый головками путь был поболе? У него есть read ahead предсказание? А если я буду читать в обратном порядке? И т.д.
В результате мы получаем цифры, каждая из которых неправильная. Например: 15kIOPS и 150 IOPS.
Какая будет реальная производительность системы? Это определяется только тем, как близко будет нагрузка к хорошему и плохому концу. (Т.е. банальное "жизнь покажет").
Чаще всего фокусируются на следующих показателях:
- Что best case всё-таки best. Потому что можно дооптимизироваться до такого, что best case от worst будет отличаться едва-едва. Это плохо (ну или у нас такой офигенный worst).
- На worst. Имея его мы можем сказать, что СХД будет работать быстрее, чем полученный показатель. Т.е. если мы получили 3000 IOPS, то мы можем смело использовать систему/диск в нагрузке "до 2000".
Ну и про размер блока. Традиционно тест идёт с размером блока в 4к. Почему? Потому что это стандартный размер блока, которым оперируют ОС при сохранении файла. Это размер страницы памяти и вообще, Очень Круглое Компьютерное Число.
Нужно понимать, что если система обрабатывает 100 IOPS с 4к блоком (worst), то она будет обрабатывать меньше при 8к блоке (не менее 50 IOPS, вероятнее всего, в районе 70-80). Ну и на 1Мб блоке мы увидим совсем другие цифры.
Всё? Нет, это было только вступление. Всё, что написано выше, более-менее общеизвестно. Нетривиальные вещи начинаются ниже.
Для начала мы рассмотрим понятие "зависимых IOPS'ов". Представим себе, что у нас приложение работает так:
- прочитать запись
- поменять запись
- записать запись обратно
Для удобства будем полагать, что время обработки нулевое. Если каждый запрос на чтение и запись будет обслуживаться 1мс, сколько записей в секунду сможет обработать приложение? Правильно, 500. А если мы запустим рядом вторую копию приложения? На любой приличной системе мы получим 1000. Если мы получим значительно меньше 1000, значит мы достигли предела производительности системы. Если нет - значит, что производительность приложения с зависимыми IOPS'ами ограничивается не производительностью СХД, а двумя параметрами: latency и уровнем зависимости IOPS'ов.
Начнём с latency. Latency - время выполнения запроса, задержка перед ответом. Обычно используют величину, "средняя задержка". Более продвинутые используют медиану среди всех операций за некоторый интервал (чаще всего за 1с). Latency очень сложная для измерения величина. Связано это с тем, что на любой СХД часть запросов выполняется быстро, часть медленно, а часть может попасть в крайне неприятную ситуацию и обслуживаться в десятки раз дольше остальных.
Интригу усиливает наличие очереди запросов, в рамках которой может осуществляться переупорядочивание запросов и параллельное их исполнение. У обычного SATA'шного диска глубина очереди (NCQ) - 31, у мощных систем хранения данных может достигать нескольких тысяч. (заметим, что реальная длина очереди (число ожидающих выполнения запросов) - это параметр скорее негативный, если в очереди много запросов, то они дольше ждут, т.е. тормозят. Любой человек, стоявший в час пик в супермаркете согласится, что чем длиннее очередь, тем фиговее обслуживание.
Latency напрямую влияет на производительность последовательного приложения, пример которого приведён выше. Выше latency - ниже производительность. При 5мс максимальное число запросов - 200 шт/с, при 20мс - 50. При этом если у нас 100 запросов будут обработаны за 1мс, а 9 запросов - за 100мс, то за секунду мы получим всего 109 IOPS, при медиане в 1мс и avg (среднем) в 10мс.
Отсюда довольно трудный для понимания вывод: тип нагрузки на производительность влияет не только тем, "последовательный" он или "случайный", но и тем, как устроены приложения, использующие диск.
Пример: запуск приложения (типовая десктопная задача) практически на 100% последовательный. Прочитали приложение, прочитали список нужных библиотек, по-очереди прочитали каждую библиотеку… Именно потому на десктопах так пламенно любят SSD - у них микроскопическая задержка (микросекундная) на чтение - разумеется, любимый фотошоп или блендер запускается в десятые доли секунды.
А вот, например, работа нагруженного веб-сервера практически параллельная - каждый следующий клиент обслуживается независимо от соседнего, т.е. latency влияет только на время обслуживания каждого клиента, но не на "максимальное число клиентов". А, признаемся, что 1мс, что 10мс - для веб-сервера всё равно. (Зато не "всё равно", сколько таких параллельно запросов по 10мс можно отправить).
Трешинг. Я думаю, с этим явлением пользователи десктопов знакомы даже больше, чем сисадмины. Жуткий хруст жёсткого диска, невыразимые тормоза, "ничего не работает и всё тормозит".
По мере того, как мы начинаем забивать очередь диска (или хранилища, повторю, в контексте статьи между ними нет никакой разницы), у нас начинает резко вырастать latency. Диск работает на пределе возможностей, но входящих обращений больше, чем скорость их обслуживания. Latency начинает стремительно расти, достигая ужасающих цифр в единицы секунд (и это при том, что приложению, например, для завершения работы нужно сделать 100 операций, которые при latency в 5 мс означали полусекундную задержку...). Это состояние называется trashing.
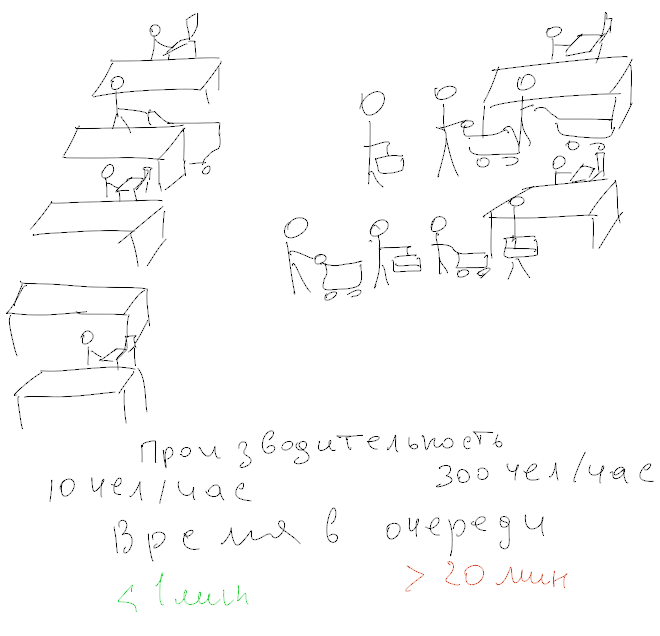
Вы будете удивлены, но любой диск или хранилище способны показывать БОЛЬШЕ IOPS'ов в состоянии trashing, чем в нормальной загрузке. Причина проста: если в нормальном режиме очередь чаще всего пустая и кассир скучает, ожидая клиентов, то в условии трешинга идёт постоянное обслуживание. (Кстати, вот вам и объяснение, почему в супермаркетах любят устраивать очереди - в этом случае производительность кассиров максимальная). Правда, это сильно не нравится клиентам. И в хорошихсупермаркетах хранилищах такого режима стараются избегать. Если дальше начинать поднимать глубину очереди, то производительность начнёт падать из-за того, что переполняется очередь и запросы стоят в очереди чтобы встать в очередь (да-да, и порядковый номер шариковой ручкой на на руке).
И тут нас ждёт следующая частая (и очень трудно опровергаемая) ошибка тех, кто меряет производительность диска.
Контроль latency во время теста
Они говорят "у меня диск выдаёт 180 IOPS, так что если взять 10 дисков, то это будет аж 1800 IOPS". (Именно так думают плохие супермаркеты, сажая меньше кассиров, чем нужно). При этом latency оказывается запредельной - и "так жить нельзя".
Реальный тест производительности требует контроля latency, то есть подбора таких параметров тестирования, чтобы latency оставалась ниже оговоренного лимита.
И вот тут вот мы сталкиваемся со второй проблемой: а какого лимита? Ответить на этот вопрос теория не может - этот показатель является показателем качества обслуживания . Другими словами, каждый выбирает для себя сам.
Лично я для себя провожу тесты так, чтобы latency оставалась не более 10мс. Этот показатель я для себя считаю потолком производительности хранилища. (при этом в уме я для себя считаю, что предельный показатель, после которого начинают ощущаться лаги - это 20мс, но помните, про пример выше с 900 по 1мс и 10 по 100мс, у которого avg стала 10мс? Вот для этого я и резервирую себе +10мс на случайные всплески).
Параллелизм
Выше мы уже рассмотрели вопрос с зависимыми и независимыми IOPS'ами. Производительность зависимых Iops'ов точно контролируется latency, и этот вопрос мы уже обсудили. А вот производительность в независимых iops'ах (т.е. при параллельной нагрузке), от чего она зависит?
Ответ - от фантазии того, кто изобретал диск или конструировал хранилище. Мы можем рассуждать о числе головок, шпинделей и параллельных очередей записи в SSD, но всё это спекуляции. С точки зрения практического использования нас интересует один вопрос: СКОЛЬКО? Сколько мы можем запустить параллельных потоков нагрузки? (Не забываем про latency, т.к. если мы разрешим отправить latency в небеса, то число параллельных потоков отправится туда же, правда, не с такой скоростью). Итак, вопрос: сколько параллельных потоков мы можем выполнять при latency ниже заданного порога? Именно на этот вопрос должны отвечать тесты.
SAN и NAS
Отдельно нужно говорить про ситуацию, когда хранилище подключено к хосту через сеть с использованием TCP. О TCP нужно писать, писать, писать и ещё раз писать. Достаточно сказать, что в линуксе существует 12 разных алгоритмов контроля заторов в сети (congestion), которые предназначены для разных ситуаций. И есть около 20 параметров ядра, каждый из которых может радикальным образом повлиять на попугаи на выходе (пардон, результаты теста).
С точки зрения оценки производительности мы должны просто принять такое правило: для сетевых хранилищ тест должен осуществляться с нескольких хостов (серверов) параллельно. Тесты с одного сервера не будут тестом хранилища, а будут интегрированным тестом сети, хранилища и правильности настройки самого сервера.
bus saturation
Последний вопрос - это вопрос затенения шины. О чём речь? Если у нас ssd способна выдать 400 МБ/с, а мы её подключаем по SATA/300, то очевидно, что мы не увидим всю производительность. Причём с точки зрения latency проблема начнёт проявляться задолго до приближения к 300МБ/с, ведь каждому запросу (и ответу на него) придётся ждать своей очереди, чтобы проскочить через бутылочное горлышко SATA-кабеля.
Но бывают ситуации более забавные. Например, если у вас есть полка дисков, подключенных по SAS/300x4 (т.е. 4 линии SAS по 300МБ каждая). Вроде бы много. А если в полке 24 диска? 24*100=2400 МБ/с, а у нас есть всего 1200 (300х4).
Более того, тесты на некоторых (серверных!) материнских платах показали, что встроенные SATA-контроллеры часто бывают подключены через PCIx4, что не даёт максимально возможной скорости всех 6 SATA-разъёмов.
Повторю, главной проблемой в bus saturation является не выедание "под потолок" полосы, а увеличение latency по мере загрузки шины.
Трюки производителей
Ну и перед практическими советами, скажу про известные трюки, которые можно встретить в индустриальных хранилищах. Во-первых, если вы будете читать пустой диск, вы будете читать его из "ниоткуда". Системы достаточно умны, чтобы кормить вас нулями из тех областей диска, куда вы никогда не писали.
Во-вторых, во многих системах первая запись хуже последующих из-за всяких механизмов снапшотов, thin provision'а, дедупликации, компрессии, late allocation, sparse placement и т.д. Другими словами, тестировать следует после первичной записи.
В третьих - кеш. Если мы тестируем worst case, то нам нужно знать, как будет вести себя система когда кеш не помогает. Для этого нужно брать такой размер теста, чтобы мы гарантированно читали/писали "мимо кеша", то есть выбивались за объёмы кеша.
Кеш на запись - особая история. Он может копить все запросы на запись (последовательные и случайные) и писать их в комфортном режиме. Единственным методом worst case является "трешинг кеша", то есть посыл запросов на запись в таком объёме и так долго, чтобы write cache перестал стправляться и был вынужден писать данные не в комфортном режиме (объединяя смежные области), а скидывать случайные данные, осуществляя random writing. Добиться этого можно только с помощью многократного превышения области теста над размером кеша.
Вердикт - минимум x10 кеш (откровенно, число взято с потолка, механизма точного расчёта у меня нет).
Локальный кеш ОС
Разумеется, тест должен быть без участия локального кеша ОС, то есть нам надо запускать тест в режиме, который бы не использовал кеширование. В линуксе это опция O_DIRECT при открытии файла (или диска).
Описание теста
Итого:
1) Мы тестируем worst case - 100% размера диска, который в несколько раз больше предположительного размера кеша на хранилище. Для десктопа это всего лишь "весь диск", для индустриальных хранилищ - LUN или диск виртуальной машины размером от 1Тб и больше. (Хехе, если вы думаете, что 64Гб RAM-кеша это много...).
2) Мы ведём тест блоком в 4кб размером.
3) Мы подбираем такую глубину параллельности операций, чтобы latency оставалось в разумных пределах.
На выходе нас интересуют параметры: число IOPS, latency, глубина очереди. Если тест запускался на нескольких хостах, то показатели суммируются (iops и глубина очереди), а для latency берётся либо avg, либо max от показателей по всем хостам.
fio
Тут мы переходим к практической части. Есть утилита fio которая позволяет добиться нужного нам результата.
Нормальный режим fio подразумевает использование т.н. job-файла, т.е. конфига, который описывает как именно выглядит тест. Примеры job-файлов приведены ниже, а пока что обсудим принцип работы fio.
fio выполняет операции над указанным файлом/файлами. Вместо файла может быть указано устройство, т.е. мы можем исключить файловую систему из рассмотрения. Существует несколько режимов тестирования. Нас интересует randwrite, randread и randrw. К сожалению, randrw даёт нам зависимые iops'ы (чтение идёт после записи), так что для получения полностью независимого теста нам придётся делать две параллельные задачи - одна на чтение, вторая на запись (randread, randwrite).
И нам придётся сказать fio делать "preallocation". (см выше про трюки производителей). Дальше мы фиксируем размер блока (4к).
Ещё один параметр - метод доступа к диску. Наиболее быстрым является libaio, именно его мы и будем использовать.
Практические рецепты
Установка fio: apt-get install fio (debian/ubntu). Если что, в squeze ещё её нет.
Утилита весьма хитро запрятана, так что "home page" у неё просто нет, только гит-репозиторий. Вот одно из зеркал: freecode.com/projects/fio
При тесте диска запускать её надо от root'а.
тесты на чтение
Запуск: fio read.ini
Содержимое read.ini
[readtest] blocksize=4k filename=/dev/sda rw=randread direct=1 buffered=0 ioengine=libaio iodepth=32
Задача подобрать такой iodepth, чтобы avg.latency была меньше 10мс.
Тесты на запись
(внимание! Ошибётесь буквой диска - останетесь без данных)
[writetest] blocksize=4k filename=/dev/sdz rw=randwrite direct=1 buffered=0 ioengine=libaio iodepth=32
Гибридные тесты
самая вкусная часть:
(внимание! Ошибётесь буквой диска - останетесь без данных)
[readtest] blocksize=4k filename=/dev/sdz rw=randread direct=1 buffered=0 ioengine=libaio iodepth=32 [writetest] blocksize=4k filename=/dev/sdz rw=randwrite direct=1 buffered=0 ioengine=libaio iodepth=32
Анализ вывода
Во время теста мы видим что-то вроде такого:
Jobs: 2 (f=2): [rw] [2.8% done] [13312K/11001K /s] [3250/2686 iops] [eta 05m:12s]
В квадратных скобках - цифры IOPS'ов. Но радоваться рано - ведь нас интересует latency.
На выходе (по Ctrl-C, либо по окончании) мы получим примерно вот такое:
^C
fio: terminating on signal 2
read: (groupid=0, jobs=1): err= 0: pid=11048
read : io=126480KB, bw=14107KB/s, iops=3526, runt= 8966msec
slat (usec): min=3, max=432, avg= 6.19, stdev= 6.72
clat (usec): min=387, max=208677, avg=9063.18, stdev=22736.45
bw (KB/s) : min=10416, max=18176, per=98.74%, avg=13928.29, stdev=2414.65
cpu : usr=1.56%, sys=3.17%, ctx=15636, majf=0, minf=57
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=99.9%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued r/w: total=31620/0, short=0/0
lat (usec): 500=0.07%, 750=0.99%, 1000=2.76%
lat (msec): 2=16.55%, 4=35.21%, 10=35.47%, 20=3.68%, 50=0.76%
lat (msec): 100=0.08%, 250=4.43%
write: (groupid=0, jobs=1): err= 0: pid=11050
write: io=95280KB, bw=10630KB/s, iops=2657, runt= 8963msec
slat (usec): min=3, max=907, avg= 7.60, stdev=11.68
clat (usec): min=589, max=162693, avg=12028.23, stdev=25166.31
bw (KB/s) : min= 6666, max=14304, per=100.47%, avg=10679.50, stdev=2141.46
cpu : usr=0.49%, sys=3.57%, ctx=12075, majf=0, minf=25
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=99.9%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued r/w: total=0/23820, short=0/0
lat (usec): 750=0.03%, 1000=0.37%
lat (msec): 2=9.04%, 4=24.53%, 10=49.72%, 20=9.56%, 50=0.82%
lat (msec): 100=0.07%, 250=5.87%
Нас из этого интересует (в минимальном случае) следующее:
read: iops=3526 clat=9063.18 (usec), то есть 9мс.
write: iops=2657 clat=12028.23
Не путайте slat и clat. slat - это время отправки запроса (т.е. производительность дискового стека линукса), а clat - это complete latency, то есть та latency, о которой мы говорили. Легко видеть, что чтение явно производительнее записи, да и глубину я указал чрезмерную.
В том же самом примере я снижаю iodepth до 16/16 и получаю:
read 6548 iops, 2432.79usec = 2.4ms
write 5301 iops, 3005.13usec = 3ms
Очевидно, что глубина в 64 (32+32) оказалась перебором, да таким, что итоговая производительность даже упала. Глубина 32 куда более подходящий вариант для теста.
Ориентировки по производительности
Разумеется, все уже расчехляют пи… попугаемерки. Привожу значения, которые я наблюдал:
- RAMDISK (rbd) - ~200kIOPS/0.1мс (iodepth=2)
- SSD (intel 320ой серии) - 40k IOPS на чтение (0.8мс); около 800 IOPS на запись (после длительного времени тестирования)
- SAS диск (15к RPM) - 180 IOPS, 9мс
- SATA диск (7.2, WD RE) - 100 IOPS, 12мс
- SATA WD Raptor - 140 IOPS, 12mc
- SATA WD Green - 40 IOPS, и мне не удалось добиться latency <20 даже с iodepth=1
Предупреждение: Если вы это будете запускать на виртуальных машинах, то
а) если за IOPS'ы берут деньги - это будут весьма ощутимые деньги.
б) Если у хостера плохое хранилище, которое надеется только на кеш в несколько десятков гигабайт, то тест с большим диском (>1Тб) приведёт к… проблемам у хостера и ваших соседей по хостингу. Некоторые хостеры могут обидеться и попросить вас вон.
с) Не забывайте обнулять диск перед тестом (т.е. dd if=/dev/zero of=/dev/sdz bs=2M oflag=direct)