Наше введение в базы данных будет неполным, если мы не рассмотрим процесс создания приложений, использующих базы данных, и средства, с помощью которых этот процесс осуществляется. Поэтому заключительная часть нашего цикла будет посвящена инструментальным средствам для проектирования данных (именно этому и посвящена настоящая статья), а также средствам разработки приложений, использующих базы данных, и средствам генерации отчетов и анализа данных (этому будут посвящены последующие статьи цикла).
Прежде чем приступить к рассказу о средствах проектирования данных, давайте рассмотрим, из чего состоит сам «производственный процесс», чтобы понять роль и место каждой из рассматриваемых в данном цикле категорий продуктов.
Роль проектирования данных в жизненном цикле информационных систем
Жизненный цикл информационной системы в общем случае начинается в момент принятия решения о ее создании и заканчивается в момент выведения ее из эксплуатации. Основными его этапами (если опустить детали) обычно являются:
- проведение предпроектного обследования;
- проектирование данных;
- разработка приложений, тестирование, написание документации;
- внедрение созданной информационной системы и обучение пользователей;
- эксплуатация и сопровождение;
- выведение из эксплуатации и утилизация.
На этапе предпроектного обследования осуществляются анализ и моделирование бизнес-процессов, подлежащих автоматизации (иногда этот процесс называется структурным моделированием), а также формулируются требования к будущему продукту. Нередко на этом же этапе производится выбор СУБД и инструментальных средств. Обычно подобное обследование проводится с участием потенциальных пользователей.
Этап проектирования данных также обычно происходит с участием потенциальных пользователей. Иногда в процессе проектирования данных создаются прототипы работающих приложений, позволяющих уточнить и дополнить требования к конечному продукту. Если предусматривается, что внедрение новой информационной системы будет сопровождаться выведением из эксплуатации ее предшественника, то принимаются решения о том, каким образом использовать унаследованные данные, и в модель данных, являющуюся итогом этого этапа, вносятся необходимые изменения.
Реальное же создание программного продукта, в том числе клиентских приложений и приложений, ответственных за генерацию отчетов и анализ данных, происходит на этапе разработки. Важной частью работы в этом случае является также тестирование и документирование создаваемого продукта. Данный этап обычно завершается созданием дистрибутива приложения или его частей и документированием процедуры его инсталляции.
Несмотря на то что рассмотрение этапов внедрения, эксплуатации и сопровождения, а также выведения из эксплуатации выходит за рамки нашего вводного цикла статей, нельзя не отметить, что эти этапы не менее важны, чем начальные этапы жизненного цикла информационных систем, связанные с проектированием и разработкой.
Авторы многих работ, посвященных общим принципам разработки проектов информационных систем, утверждают, что стоимость исправления ошибки, допущенной на предыдущем этапе жизненного цикла, примерно в десять раз превышает затраты на ее исправление на текущем этапе. В частности, многие разработчики сталкиваются с тем, что ошибки проектирования данных приводят иногда к написанию кода большого объема, так или иначе их компенсирующего, и нередко вызывают проблемы на этапе сопровождения готового продукта. Поскольку проектирование данных следует непосредственно за предпроектным обследованием, очень важно, чтобы эта часть работы над проектом была выполнена максимально качественно. Именно важность этого этапа обусловила стремительный рост популярности такой категории программного обеспечения, как средства проектирования данных, в течение последних десяти лет.
Многие современные СУБД содержат визуальные средства (нередко входящие в состав утилит администрирования), позволяющие создать новую схему базы данных или просмотреть уже имеющуюся. Существуют также и утилиты (поставляемые отдельно от СУБД), позволяющие разрабатывать или редактировать метаданные. Однако в последнее время все более популярными становятся CASE-средства (Computer-Aided System Engineering). Существует несколько типов CASE-средств, но для создания баз данных чаще всего используются те из них, что содержат в своем составе инструменты для создания диаграмм «сущность-связь» и проектирования данных.
Ниже мы рассмотрим процесс проектирования данных с помощью подобных инструментов.
Составные части процесса проектирования данных
Процесс проектирования данных можно условно разделить на два этапа: логическое моделирование и физическое проектирование. Результатом первого из них является так называемая логическая (или концептуальная) модель данных, выражаемая обычно диаграммой «сущность-связь» или ER (Entity-Relationship) диаграммой, которая представлена в одной из стандартных нотаций, принятых для отображения подобных диаграмм. Результатом второго этапа является готовая база данных либо DDL-скрипт для ее создания.
Логическое моделирование
Логическая модель данных описывает факты и объекты, подлежащие регистрации в будущей базе данных. Основными компонентами такой модели являются сущности, их атрибуты и связи между ними. Как правило, физическим аналогом сущности в будущей базе данных является таблица, а физическим аналогом атрибута - поле этой таблицы.
С логической точки зрения сущность представляет собой совокупность однотипных объектов или фактов, называемых экземплярами этой сущности. Физическим аналогом экземпляра обычно является запись в таблице базы данных. Как и записи в таблице реляционной СУБД, экземпляры сущности должны быть уникальными, то есть полный набор значений их атрибутов не должен дублироваться. И так же, как и поля в таблице, атрибуты могут быть ключевыми и неключевыми.
На этапе логического проектирования для каждого атрибута обычно определяется примерный тип данных (строковый, числовой, BLOB и др.). Конкретизация происходит на этапе физического проектирования, так как различные СУБД поддерживают разные типы данных и ограничения на их длину или точность.
Связь с логической точки зрения представляет собой соотношение между сущностями, которое нередко может быть выражено обычными фразами, например: «Клиент размещает заказ» («A customer places an order» - этой фразой вполне можно описать связь, изображенную на рис. 1), где существительными являются названия связанных между собой сущностей.
Подавляющее большинство средств проектирования данных позволяют создавать ER-диаграммы визуально, изображая сущности и соединяя их связями с помощью мыши. Интерфейс таких средств нередко настолько прост, что позволяет освоить логическое проектирование данных не только разработчику, но и пользователю-непрограммисту, если таковой участвует в проектировании данных как эксперт в предметной области.
Отметим, что на этапе логического проектирования можно описать поведение СУБД при нарушении правил ссылочной целостности, определяемых данной связью (например, при удалении сведений о заказчике, разместившем хотя бы один заказ, для связи, изображенной на рис. 1).
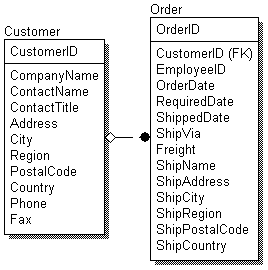
Рис. 1. Пример связи между сущностями логической модели
Для этого многие (но не все!) средства проектирования данных обладают языком шаблонов, не зависящим от СУБД, на котором можно описать алгоритм обработки подобной ситуации, например с помощью соответствующих триггеров или иных объектов базы данных, а также набором стандартных шаблонов, реализующих некоторые типовые алгоритмы подобной обработки (например, отказ от удаления с последующей генерацией диагностического сообщения, каскадное удаление дочерних записей и др.). В процессе создания физической модели (о ней будет рассказано чуть ниже) эти шаблоны преобразуются в код на процедурном расширении языка SQL, применяемом в конкретной СУБД.
Ряд публикаций проводит градацию категорий логических моделей по степени детализации описания сущностей, атрибутов и связей. Модель, обсуждаемая с заказчиком, являющимся обычно экспертом в подлежащей автоматизации предметной области, а не программистом или аналитиком, должна содержать, например, основные сущности и связи, но не обязана иметь их детальную техническую проработку (в частности, описания алгоритмов обработки нарушений ссылочной целостности). В то же время модель, служащая основой технического задания на разработку клиентских приложений, обязана содержать детальное представление структуры данных, ключевых атрибутов, их текстовое описание, а также представлять сущности в нормализованном виде (иногда такая модель называется полной атрибутивной моделью). Иными словами, нормализация модели данных обычно происходит на этапе логического проектирования (подробнее о нормализации рассказано в первой статье данного цикла, опубликованной в КомпьютерПресс № 3’2000).
Отметим, что логическая модель данных, как правило, не связана с конкретной СУБД и не учитывает технические особенности конкретных платформ, применяемых при ее последующей физической реализации.
Физическое проектирование данных
Физическое проектирование данных осуществляется на основе логической модели. Результатом этого процесса является физическая модель, содержащая полную информацию, необходимую для генерации всех необходимых объектов в базе данных. Для СУБД, поддерживающих системный каталог, физическая модель соответствует его содержимому.
Обычно на основании физической модели создается DDL -скрипт для создания объектов базы данных либо эти объекты создаются непосредственно из CASE-средства - подавляющее большинство современных средств такого класса поддерживает различные механизмы доступа к данным и может выступать в роли клиентского приложения, инициирующего выполнение DDL-скриптов.
Сноска: DDL (Data Definition Language) - язык определения данных, подмножество языка SQL
В процессе физического проектирования следует определить наименования таблиц и типы данных для всех полей. Если необходимо, на этом же этапе описываются представления (если таковые будут создаваться) и может быть создан код хранимых процедур. Далее обычно полагается определить, какие именно объекты и как будут создаваться: например, с помощью каких SQL-предложений создаются индексы, с помощью каких объектов - триггеров или серверных ограничений - реализуется ссылочная целостность, создаются ли индексы для альтернативных ключей и т.д.
Пример диаграммы, отображающей физическую модель для SQL Server 7.0, соответствующую приведенной выше логической модели, представлен на рис. 2
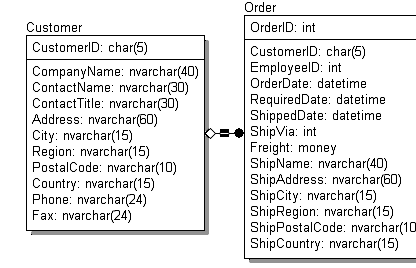
Рис. 2. Пример простейшей физической модели данных
а пример скрипта для создания объектов базы данных, сгенерированный на основании этой модели с помощью одного из рассмотренных ниже CASE-средств, приведен в листинге 1.
CREATE TABLE Customer ( CustomerID char(5) NOT NULL, CompanyName nvarchar(40) NOT NULL, ContactName nvarchar(30) NULL, ContactTitle nvarchar(30) NULL, Address nvarchar(60) NULL, City nvarchar(15) NULL, Region nvarchar(15) NULL, PostalCode nvarchar(10) NULL, Country nvarchar(15) NULL, Phone nvarchar(24) NULL, Fax nvarchar(24) NULL ) ALTER TABLE Customer ADD PRIMARY KEY (CustomerID) CREATE TABLE Order ( OrderID int IDENTITY, CustomerID char(5) NULL, EmployeeID int NULL, OrderDate datetime NULL, RequiredDate datetime NULL, ShippedDate datetime NULL, ShipVia int NULL, Freight money NULL, ShipName nvarchar(40) NULL, ShipAddress nvarchar(60) NULL, ShipCity nvarchar(15) NULL, ShipRegion nvarchar(15) NULL, ShipPostalCode nvarchar(10) NULL, ShipCountry nvarchar(15) NULL, FOREIGN KEY (CustomerID) REFERENCES Customer ) CREATE INDEX XIF1Order ON Order ( CustomerID) ALTER TABLE Order ADD PRIMARY KEY (OrderID)
create trigger tU_Customer on Customer for UPDATE as begin declare @numrows int, @nullcnt int, @validcnt int, @insCustomerID char(5), @errno int, @errmsg varchar(255) select @numrows = @@rowcount if update(CustomerID) begin if exists ( select * from deleted,Order where Order.CustomerID = deleted.CustomerID ) begin select @errno = 30005, @errmsg = ‘Cannot UPDATE Customer because Order exists.’ goto error end end return error: raiserror @errno @errmsg rollback transaction end
Как правило, современные средства проектирования данных поддерживают несколько типов СУБД (например, ERwin фирмы Computer Associates поддерживает более 20 различных СУБД). Уровень поддержки той или иной платформы в разных средствах проектирования данных может быть различен. Например, конкретное средство может поддерживать или не поддерживать для данной СУБД такие особенности, как создание хранимых процедур, генерация объектов физической памяти (табличных пространств, сегментов отката и др.), задание местоположения объектов базы данных в физических объектах и т.д. Поэтому, выбирая средство проектирования данных для решения конкретной задачи, стоит поинтересоваться, каковы его возможности с точки зрения поддержки особенностей той или иной платформы - при удачном раскладе можно сэкономить немало времени на «ручное» доведение создаваемой базы данных (или DDL-скрипта для ее генерации) до необходимого состояния. При этом, естественно, чем больше возможностей и платформ поддерживает конкретное средство проектирования данных, тем дороже оно стоит (следует отметить, что CASE-средства вообще относятся к не самым дешевым программным продуктам - цены на них составляют обычно от одной до нескольких десятков тысяч долларов).
Отметим, что физическое проектирование может включать и дополнительную «ручную» работу по доведению базы данных или скрипта для ее генерации до «товарного» вида. Например, нередко в скрипт также включаются SQL-предложения для заполнения некоторых таблиц, данные которых более или менее постоянны, таких, например, как список субъектов Российской Федерации или справочник телефонных кодов различных стран, а также нестандартные триггеры и процедуры.
В последнее время в техническое задание на разработку приложений нередко включается полное описание физической модели данных или ее части, с которой должно иметь дело разрабатываемое приложение. Подавляющее большинство современных средств проектирования данных предоставляют возможность не только документировать модель, но и создавать по ней отчеты, содержащие те или иные сведения о модели, в том числе сведения, необходимые для разработки приложений.
Некоторые средства проектирования данных позволяют хранить их модели в специальных репозитариях, а также осуществлять коллективное проектирование. Нередко средства проектирования данных дают возможность также присваивать таблицам и полям так называемые расширенные атрибуты, то есть свойства, связанные с отображением их в клиентских приложениях, созданных с помощью какого-либо средства разработки, а также генерировать код приложений для ввода и отображения данных.
Кроме того, подавляющее большинство средств проектирования данных позволяют восстанавливать физическую модель данных их системного каталога и представлять ее в виде ER-диаграммы (этот процесс называется обратным проектированием - reverse engineering), а также производить синхронизацию системного каталога и физической модели. При создании информационной системы, которая должна использовать унаследованные от предшествующих ей систем данные, такая особенность весьма полезна - в этом случае логическое проектирование можно начать с модификации уже имеющейся модели (этот процесс получил название round-trip engineering).
Обсудив, что представляет собой процесс проектирования данных, мы можем перейти к рассмотрению наиболее популярных продуктов, с помощью которых можно его осуществить.
Наиболее популярные средства проектирования данных
Итак, кратко рассмотрим особенности наиболее популярных CASE-средств, применяемых для проектирования данных. Их список приведен в таблице.
Наиболее популярные средства проектирования данных
| CASE - средство | Производитель | URL |
|---|---|---|
| Designer 2000 | Oracle | http://www.oracle.com/ |
| ERwin | Computer Associates | http://www.cai.com/ |
| PowerDesigner | Sybase | http://www.sybase.com/ |
| ER/Studio | Embarcadero | http://www.embarcadero.com/ |
| System Architect | Popkin Software | http://www.popkin.com/ |
| Visible Analyst | Visible Systems | http://www.visible.com |
| Visio Enterprise | Microsoft | http://www.microsoft.com/ |
Отметим, что многие из этих продуктов предназначены не только для проектирования данных, но и для решения других задач, например моделирования потоков данных или бизнес-процессов, функционального моделирования, прототипирования приложений, их документирования, управления проектами и т.д. В этом случае средства проектирования данных являются составными частями таких продуктов.
Designer/2000 (Oracle)
Designer/2000 (предыдущие версии продукта назывались Oracle*CASE) представляет собой универсальное CASE-средство, позволяющее моделировать бизнес-процессы, создавать диаграммы потоков данных и функциональные модели. Средство проектирования данных и создания ER-диаграмм является лишь одной из составных частей этого довольно сложного продукта и предоставляет возможность сохранять созданные модели данных и описанные бизнес-правила в предназначенном для этого репозитарии.
Designer/2000, предназначенный для использования главным образом с Oracle 8, поддерживает все особенности данной СУБД, включая объектные типы данных (CLOB, Arrays, вложенные таблицы и др.), равно как и специфические особенности физической реализации базы данных Oracle. Для Oracle 7 и Oracle 8 это CASE-средство позволяет создать определения ролей, сгенерировать триггеры, реализующие бизнес-логику, которая описана в моделях, используемых при генерации базы данных, а также cгенерировать объекты для распределенных базы данных. Кроме того, с помощью Designer/2000 можно создавать физические модели и осуществлять обратное проектирование и для других СУБД - Oracle RDB, DB2, Microsoft SQL Server, Sybase, ODBC-источников данных, а также осуществлять обратное проектирование на основании DDL-сценариев, если они соответствуют стандарту ANSI SQL.
Весьма привлекательной особенностью Designer/2000 является возможность генерации форм Oracle Developer/2000, проектов Visual Basic, классов C++, отчетов Oracle Reports, приложений для Oracle Web Application Server.
Дополнительная информация доступна на Web-сайте по адресу: http://www.oracle.com/tools/designer/.
ERwin (Computer Associates)
ERwin разработан компанией Logic Works, которая в 1988 году была приобретена фирмой Platinum Technologies, а ее, в свою очередь, приобрела компания Computer Associates. Этот продукт в течение последних десяти лет занимает лидирующие позиции среди средств проектирования данных.
ERwin представляет собой специализированное средство проектирования данных. Его применение предполагает, что моделирование бизнес-процессов и потоков данных производится с помощью других продуктов (например, BPwin), c которыми можно осуществлять обмен сведениями о моделях.
ERwin не ориентирован на какую-то конкретную СУБД и поддерживает более 20 типов СУБД, включая СУБД всех ведущих производителей серверов баз данных (Oracle, Sybase, Microsoft, IBM, Informix), а также все популярные форматы настольных СУБД (включая dBase, Clipper, FoxPro, Access, Paradox), кроме, возможно, самых последних версий. Дело в том, что новые версии ERwin не выпускались уже довольно давно - как минимум год не было обновлений имеющейся версии и более двух лет не выпускались новые версии этого продукта. Поэтому при использовании ERwin с последними версиями некоторых СУБД могут возникнуть проблемы (например, некоторые типы данных SQL Server 7.0 это CASE-средство поддерживает не совсем корректно). Тем не менее ERwin остается одним из самых популярных в мире продуктов этого класса благодаря поддержке большого количества платформ, простоте интерфейса и, что немаловажно, поддержке специфических особенностей организации физической памяти наиболее популярных серверных СУБД. Например, для СУБД Oracle, Microsoft SQL Server, Sybase этот продукт позволяет изменять местоположение и параметры хранения индексов, почти для всех популярных серверных СУБД создавать кластеризованные индексы и для многих из них - указывать характеристики табличных пространств и сегментов отката.
Сноска: Кластеризованный индекс - способ индексирования, при котором данные в таблице физически расположены отсортированными по значению поля, на котором построен индекс. Для каждой таблицы может быть создан только один кластеризованный индекс.
ERwin обладает встроенным макроязыком для написания в процессе логического проектирования не зависящих от СУБД шаблонов серверного кода, а также готовыми шаблонами для генерации триггеров, реализующих стандартные действия (например, каскадное удаление). При необходимости можно создавать и свои шаблоны триггеров, используя этот язык, причем каждая таблица может иметь свой набор шаблонов. При создании физической модели шаблоны преобразуются в код на процедурном расширении SQL того сервера, для которого создается физическая модель. Логическая и физическая модели ERwin хранятся в одном файле.
ERwin поддерживает обмен моделями с репозитарием Designer/2000 и Microsoft Repository, а также генерацию клиентских приложений для Visual Basic и PowerBuilder.
Помимо однопользовательской работы ERwin может выступать в роли клиентского приложения для другого CASE-средства - ModelMart, которое позволяет организовать коллективную разработку моделей данных, предоставляя для этой цели разделяемый репозитарий, хранящийся в одной из серверных СУБД.
Недавно компанией Computer Associates был выпущен новый продукт - ERwin Examiner, представляющий собой инструмент проверки баз данных и DDL-скриптов с целью выявления ошибок проектирования данных, сказывающихся на целостности данных и производительности сервера, таких, например, как ошибки нормализации, противоречивые ключи и т.д. В результате проверки ERwin Examiner предлагает способы устранения найденных ошибок, генерируя соответствующие DDL-скрипты. На нашем CD-ROM вы можете найти статью Сергея Маклакова, посвященную этому продукту. Ознакомительные версии ERwin, ModelMart и ERwin Examiner вы также можете найти на нашем CD-ROM.
Дополнительная информация доступна на Web-сайте по адресу: http://www.cai.com/products/alm/erwin.htm.
PowerDesigner (Sybase)
PowerDesigner (бывший S-Designor, принадлежавший компании PowerSoft) представляет собой инструмент, в состав которого входят средство создания концептуальных (то есть логических) моделей, средство создания физических моделей и средство объектно-ориентированного моделирования, используемое при генерации клиентских приложений. Средство создания физических моделей представляет собой отдельный продукт - PowerDesigner PhysicalArchitect. В состав продукта PowerDesigner DataArchitect входят средства создания концептуальных и физических моделей, в состав PowerDesigner Developer - средства объектно-ориентированного моделирования и создания физических моделей, а в состав PowerDesigner ObjectArchitect - все три средства.
Физические и концептуальные модели в PowerDesigner DataArchitect хранятся в разных файлах, однако возможна генерация как физической модели на основе модели концептуальной, так и наоборот.
Помимо серверных СУБД производства Sybase (Adaptive Server Enterprise 12.0, Sybase SQL Anywhere) PowerDesigner DataArchitect способен работать с любыми ODBC-источниками. Как и ERwin, он поддерживает генерацию триггеров серверных СУБД, осуществляющих стандартную обработку событий, связанных с нарушениями ссылочной целостности.
PowerDesigner Developer и PowerDesigner ObjectArchitect могут генерировать код клиентских приложений для PowerBuilder, а также классы Java и компоненты JavaBeans. Возможно и обратное проектирование диаграмм классов из исходных текстов Java, байт-кодов и архивов Java. Поддерживается также генерация кода Web-приложений и объектов для Sybase Enterprise Application Server на основе физической модели.
PowerDesigner DataArchitect может импортировать логические и физические модели ERwin.
PowerDesigner DataArchitect может хранить свои модели данных в коллективно разделяемом репозитарии, управляемом с помощью средства PowerDesigner MetaWorks и доступном как дополнительный модуль в составе любого из перечисленных выше продуктов.
Отметим, что PowerDesigner DataArchitect весьма популярен на российском рынке, причем не только среди пользователей СУБД и средств разработки Sybase.
Ознакомительную версию PowerDesigner DataArchitect вы сможете найти на нашем CD-ROM.
Дополнительная информация доступна на Web-сайте по адресу: http://www.sybase.com/products/designtools/powerdesigner/.
ER/Studio (Embarcadero Technologies)
ER/Studio менее известен в нашей стране, чем ERwin и PowerDesigner DataArchitect. Однако возможности этого продукта также заслуживают внимания.
По своему назначению этот продукт сходен с ERwin - он представляет собой специализированное средство проектирования данных и не содержит в своем составе инструментов для объектно-ориентированного моделирования или моделирования бизнес-процессов. Список поддерживаемых СУБД у этого продукта достаточно широк и включает все наиболее популярные серверные и настольные СУБД. В отличие от ERwin последняя версия этого продукта корректно поддерживает новые типы данных SQL Server 7.
ER/Studio поддерживает написание макросов на SAX Basic (клон Visual Basic for Applications). Этот язык позволяет создавать макросы для выполнения однотипных операций, например добавления стандартных полей к вновь создаваемым сущностям. С помощью этого же языка можно генерировать стандартные триггеры и хранимые процедуры для вставки, удаления, изменения записей. Код на этом языке можно даже отлаживать и обращаться к свойствам сущностей для конструирования серверного кода. Однако, в отличие от ERwin, ER/Studio не позволяет добавить к каждой таблице свои шаблоны триггеров или просмотреть код конкретного триггера в процессе разработки модели - чтобы получить код одного триггера, нужно сгенерировать скрипт для всей модели.
Модели ER/Studio можно сохранить не только в виде DDL-скрипта, но и в формате XML. Можно также создать репозитарий для их хранения в любой серверной СУБД. ER/Studio может импортировать модели ERwin, но при импорте теряются связи шаблонов серверного кода с конкретными таблицами, и не все макросы ERwin корректно преобразуются в макросы SAX Basic.
ER/Studio позволяет сгенерировать Java-классы для клиентских приложений.
Отметим, что ER/Studio является COM-сервером, что позволяет использовать его в других приложениях, предоставляя им возможность просмотра и редактирования моделей данных, а также создавать другие решения на его основе.
Ознакомительную версию ER/Studio вы сможете найти на нашем CD-ROM.
Дополнительная информация доступна на Web-сайте по адресу: http://www.embarcadero.com/products/Design/erdatasheet.htm.
System Architect (Popkin Software)
System Architect 2001 представляет собой универсальное CASE-средство, позволяющее осуществить не только проектирование данных, но и структурное моделирование. Средство проектирования данных и создания ER-диаграмм является одной из составных частей этого продукта.
Этот продукт поддерживает СУБД практически всех ведущих производителей, включая Oracle (Oracle 8), Sybase, DB2, SQL Server, IBM (AS400, DB2), Informix, Sybase, Access, dBASE, Paradox и др.
В процессе логического моделирования можно проверить модель на соответствие правилам проектирования данных (например, на соответствие ее первой, второй или третьей нормальным формам). При генерации DDL-скрипта можно сгенерировать триггеры (в том числе и нестандартные).
Все компоненты System Architect позволяют документировать процесс работы над проектом, включая техническое задание, план тестирования и др.
Модели System Architect 2001, как и в случае других CASE-средств, можно сохранять в репозитарии. Однако в отличие от традиционных репозитариев, обладающих более или менее стандартной структурой хранимых данных, репозитарий System Architect является настраиваемым - к сохраняемым объектам можно добавлять дополнительные свойства, определенные пользователем.
System Architect обладает встроенным Visual Basic for Application, что позволяет создавать разнообразные решения на базе этого продукта, включая автоматическую генерацию моделей и проектной документации.
System Architect 2001 позволяет генерировать код клиентских приложений для Visual Basic, Delphi и PowerBuilder (на сегодняшний день это практически единственное CASE-средство, поддерживающее генерацию кода Delphi), классы C++, а также код и текстовые экранные формы COBOL.
Ознакомительную версию System Architect вы сможете найти на нашем CD-ROM.
Дополнительная информация доступна на Web-сайте по адресу: http://www.popkin.com/products/sa2001/data/data.htm.
Visible Analyst (Visible Systems Corporation)
Visible Analyst - весьма популярный продукт компании Visible Systems Corporation. Широко известны также ранее производимые этой компанией CASE-средства EasyER и EasyCASE - предшественники Visible Analyst.
Этот продукт выпускается в трех редакциях: Visible Analyst DB Engineer, который включает средства проектирования данных, Visible Analyst Standard, который кроме проектирования данных позволяет осуществлять структурное моделирование, и Visible Analyst Corporate, который помимо указанных выше возможностей позволяет осуществлять также объектно-ориентированное моделирование.
Visible Analyst поддерживает довольно широкий спектр СУБД с точки зрения генерации серверного кода, включая Oracle 7, Sybase SQL Server (System 10 и 4.x); Informix, DB2, Ingres. Последние версии многих серверных СУБД (Oracle 8, Microsoft SQL Server 6.5/7/2000, последние версии серверов Sybase) в этом списке пока отсутствуют.
Для Informix и DB2 указанный продукт позволяет генерировать DDL-скрипты, учитывающие специфические особенности организации физической памяти наиболее популярных серверных СУБД, такие как управление табличным пространством, размером экстентов, режимами блокировки данных, степенью заполнения данными (fill factor), а также создавать кластеризованные индексы и генерировать триггеры для выполнения стандартных операций. Из этих же СУБД можно производить непосредственно обратное проектирование. Помимо этих двух СУБД обратное проектирование можно производить также из DDL-скриптов, сгенерированных для других СУБД, а также на основе кода COBOL.
Модели Visible Analyst можно сохранять в многопользовательском репозитарии, созданном в одной из серверных СУБД.
Кроме того, Visible Analyst позволяет на оcнове созданных моделей генерировать код для Visual Basic, С++ и COBOL.
Отметим, что продукты семейства Visible Analyst имеют относительно невысокую стоимость, что также является их весьма привлекательной чертой.
Демонстрационную версию Visible Analyst вы сможете найти на нашем CD-ROM.
Дополнительная информация доступна на Web-сайте по адресу: http://www.visible.com/dataapp/daprods.html.
Visio Enterprise (Microsoft)
Продукт под названием Visio, приобретенный в январе 2000 года корпорацией Microsoft вместе с его разработчиком - компанией Visio Corporation, позиционировался на рынке как одно из самых популярных средств создания схем и диаграмм. То, что один из членов семейства Microsoft Visio 2000 - Visio 2000 Enterprise - содержит в своем составе полноценное CASE-средство, было в определенной степени сюрпризом для пользователей CASE-инструментов. Однако, если вдуматься, появление своих средств проектирования данных, моделирования бизнес-процессов и объектно-ориентированного моделирования у Microsoft - шаг вполне закономерный, поскольку такие средства появляются рано или поздно у большинства производителей популярных серверных СУБД и средств разработки, каковым Microsoft является уже довольно давно.
Как и подавляющее большинство средств проектирования данных, Visio Enterprise позволяет производить прямое и обратное проектирование данных, преобразовывать логическую модель в физическую. Этим средством поддерживаются все ODBC- и OLE DB-источники данных. С его помощью можно создавать триггеры для стандартной обработки нарушений ссылочной целостности в случае, если DDL-скрипт создается для Microsoft SQL Server, и серверные ограничения, если скрипт создается для другой СУБД. Отметим, что Visio при генерации скриптов позволяет указывать параметры организации физической памяти Oracle, Informix, Microsoft SQL Server, DB2 и некоторых других СУБД.
Отметим, что помимо средств проектирования данных Visio включает средства объектно-ориентированного моделирования и генерации кода приложений Visual Basic 6, а также классов C++ и Java. Модели Visio можно сохранять в Microsoft Repository.
Visio, в отличие от специализированных средств проектирования данных, не обладает скриптовым языком, позволяющим создавать серверный код, не связанный с конкретной СУБД. При использовании этого продукта такой код нужно создавать на этапе физического проектирования в уже созданном скрипте. Однако справедливости ради заметим, что и стоимость Visio Enterprise по сравнению с ERwin или PowerDesigner DataArchitect невысока, тем более что Visio в целом представляет собой продукт более широкого назначения, нежели другие рассмотренные выше средства проектирования данных. К тому же этот продукт является сервером автоматизации, обладает весьма обширной объектной моделью и встроенным средством разработки - Visual Basic for Applications, что позволяет, в частности, создавать на его базе разнообразные решения, в том числе и автоматизировать разработку моделей данных.
Подробности о Visio и его использовании вы сможете найти в статье Алексея Федорова «Знакомство с Microsoft Visio 2000», опубликованной в ноябрьском номере нашего журнала.
Дополнительная информация доступна на Web-сайте по адресу: http://www.microsoft.com/office/visio/.
Заключение
В настоящей статье мы рассмотрели жизненный цикл информационных систем и убедились, что проектирование данных играет в нем ключевую роль. Мы также узнали, что представляют собой процессы логического (концептуального) и физического моделирования данных.
Помимо этого мы рассмотрели несколько наиболее популярных средств проектирования данных - как специализированных, так и входящих в состав комплексных CASE-средств. Изучение возможностей этих продуктов свидетельствует о том, что все они, обладая своими особенностями и имея в определенной степени различающиеся сферы применения, как правило, имеют и сходные черты, в число которых входят:
- Поддержка создания логических моделей, не зависящих от СУБД, и генерации физических моделей на их основе.
- Поддержка нескольких типов СУБД, включая не только серверные, но и настольные.
- Поддержка специфических особенностей тех или иных СУБД ведущих производителей (генерация триггеров, управление физическим хранением данных).
- Способность осуществлять обратное проектирование на основе либо имеющейся базы данных, либо имеющегося DDL-скрипта.
- Возможность генерации отчетов и проектной документации на основе созданной модели.
- Возможность сохранения модели в репозитарии, который во многих случаях может быть разделяемым.
- Поддержка генерации кода для одного или нескольких средств разработки или языков программирования. Следует отметить, что в этом отношении самым популярным средством разработки является, по-видимому, Visual Basic.
Рассмотрев процесс проектирования данных и средства, с помощью которых можно его осуществить, мы можем приступить к изучению следующего этапа жизненного цикла информационных систем - разработке клиентских приложений. Именно ей и будет посвящена следующая статья данного цикла.