Трудно представить сегодня Интернет без информационно-поисковых систем (ИПС). ИПС это стартовая точка для всех пользователей Интернет. Когда пользователю нужно найти сайт определенной тематики, можно зайти на веб сайт ИПС ввести пару ключевых слов и через сотые доли секунды поисковая система выдаст результаты, которые удивительно сильно подходят запросу пользователя.
Вот и приходится удивляться, как это происходит, ведь объемы Интернета - терабайты информации, а нужная информация находится за доли секунды через ИПС. На данный момент ни один суперкомпьютер не сможет добиться таких результатов без применения высоко интеллектуальных технологий.
Попробуем ответить на вопрос: как поисковые системы добиваются такой эффективности?
Архитектура ИПС
Классическая ИПС состоит из трех частей:
- web паук (робот, агент).
- Индексная база.
- Поисковый механизм (алгоритм).
web паук
web паук (робот, агент) - это программа, которая работает на нескольких компьютерах подключенных к сети Интернет, она следует по гиперссылкам (лазит по сети) из веб страниц и скачивает все найденные файлы. Т.е. программа скачивает весь просмотренный Интернет.
На первый взгляд все просто. Но это далеко не так. Во-первых, веб пауком может управлять владелец сайта. Достаточно сохранить в корневую директорию сайта специальный файл robots.txt. В этом файле на специальном языке описаны команды для веб пауков (что индексировать, как индексировать, что пропустить и т.д.). Это необходимо, в первую очередь, для сокрытия приватной информации от поисковой системы. Были случаи, когда через ИПС google при вводе запроса "номера кредитных карточек" выводилась приватная информация. После чего были даже судебные разбирательства.
Более того, такие пауки умеют обходить рекламные трюки по продвижению сайтов. В internet существуют "популярные запросы" т.е. слова и словосочетания, которые используют при поиске чаще всего. Например: "скачать музыку", "10000$ за день". И вот существует такой прием для повышения популярности сайта - "белым по белому" пишут "популярные запросы", таким образом, сайт может быть посвящен одной тематике, а для его рекламы используют слова совсем не связанные с основным смыслом сайта. Веб роботы очень сурово относятся к таким обманам и не вносят такие сайты в базу.
Также веб роботы принимают через веб сайт заявки на индексацию только что созданного сайта. На новые веб сайты никто не ссылается, и прийти рекурсивно по ссылкам других сайтов нельзя.
Индексатор
Другая часть ИПС - это индексатор. Его задача обрабатывать "скачанный Интернет". Это более сложная система. Она извлекает все слова из скачанных документов, и складывает в определенную индексную базу(индексные файлы). Для каждого слова извлекается информация о том, как это слово расположено на веб странице:
- Позиция слова в тексте страницы.
- Кол-во вхождений слова в странице.
- Цвет и шрифт, используемый для оформления слова.
Извлеченные слова заносятся в специальные словари (файлы определенного типа) при этом словари могут быть для нескольких языков. При занесении в словарь часто отсекают окончания и суффиксы для более эффективного хранения информации. Но это снижает точность поиска. Словари являются частью индекса.
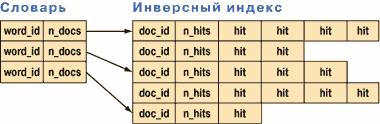
Словари в свою очередь связаны своими индефикаторами с индефикаторами веб страниц (они присваиваются при внесении). Любому слову из словаря соответствует набор doc_id-документов, в которых это слово встречается. Работой по постоянному формированию инверсного индекса занимаются сортировщики.
Рис. 1. Структура инверсного индекса (word_id - идентификатор слова; ndocs - количество документов с этим словом; doc_id - идентификатор документа; n_hits - частота, с которой слово встречается в документе)
Алгоритм поиска
Попробуем купить слона через поисковую систему. Почему слона?! Бытовую или компьютерную технику найти и купить легко. А вот для покупки экзотических товаров можно воспользоваться ИПС.
Итак, пусть от пользователя поступил запрос найти страницы с фразой "я хочу купить слона" и при этом у пользователя есть желание купить слона. Но перед тем, как обработать запрос на поиск, поисковая система делает ряд шагов:
- Проверяет орфографию запроса. Иногда, в процессе быстрого набора текста делаются описки. Новейшие системы могут находить ошибки в словах (как ms word) и предлагать ввести свой правильный вариант.
- Также, следует отметить, что происходит генерация похожих по смыслу слов (синонимов) и разных падежных форм. На запрос купить слона будут, также искаться "продать слона", "продажа слонов". Это существенно расширит границы поиска. Для этого используется специальные морфоанализаторы. Существует два типа морфоанализаторов: вероятностные и вероятнстно-словарные. Последние более качественные, т.к. обработанное слово дополнительно проверяется по словарю.
- Также, запрос переводится на другие языки. Возможно, у нас(в Белоруссии) не продаются слоны, тогда можно посмотреть предложения других стран.
- Стоп слова (местоимения, предлоги). В последнее время не используется. Раньше это делалось для экономии вычислительных ресурсов. В нашем запросе стоп словом было бы "я".
И только после этого идет запрос на поиск. Программа, формирующая результаты поиска, посмотрит в словарь, найдет там word_id для слов "хочу","купить", "слона" и всех похожих, и сформирует запрос в базу данных.
В результате мы получим сотни тысяч неупорядоченных результатов. В этих документах будет описание слонов, сказки, рассказы все что угодно и только несколько будет результатов в тему о продажи слонов. Таким образом, результаты нужно упорядочить.
И тут срабатывают алгоритмы для определения порядка вывода результатов поиска. За подбор оптимального алгоритма сейчас работают тысячи фирм по всему миру.
Каждому результату присваивается оценка, которая вычисляется по ниже приведенным критериям:
1) Кол-во вхождений. Понятно, что чем больше будет встречаться искомое слово в странице, тем больше вероятность, что эта нужная страница.
2) Расстояние между словами. Оно должно быть минимальной.
3) page rank. Это число характеризует качество материала. При этом это качество определяется владельцами других сайтов.
Расчетная формула, опубликованная С. Брином и Л. Пейджем, выглядит следующим образом:
где d - эмпирически подобранный коэффициент (d=0.85); Т1...tn - страницы, ссылающиеся на рассматриваемый документ; С(tn)... С(tn) - общее количество ссылок, ведущих вовне со страниц Т1...tn
Владельцы своих сайтов ставят ссылки, как правило, на интересные сайты. Т.е. они оценивают его и в случае положительной оценки поставят на него ссылку.
4) Каким шрифтом выделено слова. В спецификации html есть уровни шрифтов, как в ms word. Чем выше уровень, тем результат должен лучше соответствовать запросу. Если бы я продавал слона, то я бы создал страничку, где большими буквами вверху написал объявление о продаже, а ниже условие.
5) Язык пользователя. Понятно, что на первые места должны попасть результаты с сайтов белорусского происхождения. Но если в Белоруссии не продают слонов, то выводятся предложения зарубежных продавцов.
6) Возраст сайта. Считается, чем больше сайт живет в сети, тем больше опыт у его владельца и тем качественный материал или предложения. Я слона не купил бы у сайта, если у него нет хорошей репутации и списка клиентов.
Важно, что без хорошо-спланированных web паука и индексатора не возможно качественно упорядочить результаты поиска, т.к. критерии для упорядочивания сохраняются при первых двух этапах. Т.е. все компоненты ИПС крепко связаны друг с другом.
Как видим, параметров множества и тут стоит основная задача - сбалансировать их. Т.е. правильно оценить каждый критерий оценки. Результат может получить очень высокую оценку по одному критерию, по другим нулевую. Такие результаты считаются не качественными.
Следует отметить, что для удержания свих позиций крупнейшие разработчики к отличному поиску предоставляют другие сервисы:
- Контекстная реклама. Можно у владельцев ИПС купить показы рекламы при определенных запросах. Например, мы получим рекламу о продаже слонов при нашем запросе. Аналитики подсчитали, что это самый эффективный вид рекламы.
- google предлагает уникальный сервис - google кэш. В него дублируются "весь интеренет". Это очень полезно, если сайт исчез внезапно или временно не доступен по техническим причинам.
- Также система google определяет откуда клиент и настраивает интерфейс под его язык.
Заключение:
В результате на наш запрос о покупке слона мы получим массу дополнительной информации:
- Рекламу фирм по продаже слонов.
- Узнаем места, где продаются слоны в нашей стране.
- Найдем предложения о продаже из других стран.
- Узнаем цену на слонов.
- Получим советы для покупателей слонов.
- Описание видов слонов, чем питаются и как за ними ухаживать
- Адреса зоопарков.
Проанализировав данный результат, можно сделать вывод, о том, насколько полезны высоко-интеллектуальные технологии при работе с громадными объемами информации. Добавлю, что интеллектуальные технологии, также, активно используются в современных антивирусах (вирусах) и спам-фильтрах.