Одним из самых печальных зрелищ является прекрасное приложение, которое медленно настолько, что его нельзя использовать - все долгие часы тяжелой работы потрачены впустую, потому что пользователи разочарованы медленной реакцией. За последние 12 лет мы потратили много времени на исследование и тестирование Domino-приложений и функциональности, для того чтобы понять, как и где можно оптимизировать производительность. Мы начали разрабатывать и поддерживать Domino-приложения в начале 1990-х годов и быстро увлеклись производительностью. Нам казалось тогда (и кажется до сегодняшнего времени), что многое из того, что мы принимали за проблемы производительности сервера, на самом деле является проблемами производительности приложения. И решения, следовательно, часто скрываются в приложении, а не на сервере.
В этой серии статей из двух частей мы поделимся с вами некоторыми своими знаниями. Данная серия охватывает следующие области производительности приложений: свойства базы данных, коллекции документов и представления (view). В первой части мы рассмотрим свойства базы данных и коллекции документов. В каждом случае мы выделим области, являющиеся наиболее важными, и предоставим краткие реальные примеры, для того чтобы помочь вам понять, что делать в своих собственных приложениях Мы будем использовать примеры из многих приложений. Возможно, вы обнаружите, что, по крайней мере, один из них совпадает с тем, что вы делаете, или с тем, что вы используете. Наша цель заключается в том, чтобы помочь вам создавать приложения, являющиеся столь же быстрыми, сколь и прекрасными.
В данной статье предполагается, что вы имеете опыт разработки приложений для Notes/Domino.
Свойства базы данных
Существует несколько свойств базы данных, которые имеют отношение к производительности вашего приложения.
Don't maintain unread marks (Не поддерживать метки нечитаемых документов)
Если вы отметите этот флажок, нечитаемые документы не будут отслеживаться в вашем приложении, независимо от настроек, которые у вас имеются для каждого представления. Мы использовали client_clock для контроля времени открытия базы данных, и то, что мы обнаружили, очень нас удивило. Для больших приложений (скажем, 20GB с 200000 документов) наш Notes-клиент мог открыть базу данных примерно за пять секунд без поддержки нечитаемых документов, включая сетевой трафик. С включенной поддержкой меток нечитаемых документов мы ждали дополнительно шесть и более секунд. Это дополнительное время тратилось в GET_UNREAD_NOTE_TABLE и RCV_UNREAD. С отключенной поддержкой меток нечитаемых документов эти вызовы не выполняются.
В более маленьких базах данных (менее 1GB) мы обнаружили экономию около 0.5 секунды с отключенными метками нечитаемыми документов. Конечно же, такая база данных в сравнении с большой базой данных открывается быстрее как с включенными метками нечитаемых документов, так и с отключенными. Поэтому вы должны решить, нужны ли в вашем приложении метки нечитаемых документов, до того, как вы запустите приложение в производство.
Optimize document table map (Оптимизировать карту таблицы документов)
Эта функциональная возможность не менялась на протяжении нескольких версий Lotus Notes/Domino. Она предназначена для ускорения индексирования представлений для приложений со структурами, повторяющими Domino Directory (другими словами, они содержат много документов, использующих одну форму, и мало документов, использующих другую форму; подумайте о документах Person в сравнении с документами Server в Domino Directory).
Идея состоит в том, что вместо проверки примечания каждого документа, для того чтобы узнать, должен ли он быть включен в индекс представления, мы совершаем два прохода. При первом проходе просто проверяется, связано ли с этим документом корректное название формы. На втором проходе, при необходимости, проверяются разные прочие условия, которые должны удовлетворяться для включения этого примечания документа в индекс представления.
Примечание: В настоящее время эта функциональная возможность, по-видимому, не улучшает время индексации даже для Domino Directories.
Don't overwrite free space (Не перезаписывать свободное пространство)
Эта функциональная возможность не менялась на протяжении нескольких версий Lotus Notes/Domino. Если вы снимете отметку с этого флажка, то при любом удалении документа Lotus Notes будет действительно перезаписывать биты данных вместо простого удаления ссылки на эти данные. Цель этого - сделать данные невосстанавливаемыми. Вам желательно использовать эту функцию только в случае опасения за физическую сохранность вашего жесткого диска. В сущности, для каждого приложения эта дополнительная физическая защита не гарантируется и является просто дополнительным действием при удалении данных.
Maintain LastAccessed property (Поддержка свойства LastAccessed)
Эта функциональная возможность не менялась на протяжении нескольких версий Lotus Notes/Domino. Если вы отметите этот флажок, Notes будет отслеживать последнее время, когда Notes-клиент открывал каждый документ в базе данных. Естественно, Lotus Notes всегда отслеживает время последнего сохранения в поле $UpdatedBy, но эта функция отслеживает также и последние чтения (однако она не отслеживает чтения Web-браузером).
Мы не встречали случаев использования этой функциональной возможности разработчиками, кроме как в приложениях с базами знаний, в которых данные архивируются, если они не читались определенное число месяцев или лет.
Коллекции документов
Мы уже много лет видим пользовательский код в агентах, в представлениях, в формулах полей формы и т.д. Исходя из нашего опыта, проблемы производительности в клиентских приложениях имеют склонность быть более сложными, чем на сервере, по нескольким причинам:
- Серверные процессы, обычно, отслеживаются более строго;
- Серверные процессы, обычно, не беспокоятся о сетевом трафике;
- С клиентскими проблемами бывает сложно разобраться. Пользователи, как правило, не уверены в том, какие действия адекватны; это приводит к тому, что они сообщают в вашу службу поддержки о несущественных и даже не относящихся к проблеме действиях.
Но независимо от источника кода, обнаруживая, что что-то работает медленно, мы начинаем исследовать код и с определенной долей вероятности находим следующие общие моменты:
- Код устанавливает определенный критерий из контекста, например, имя пользователя, состояние документа, с которым работает пользователь, текущая дата и т.д.;
- Код принимает коллекцию документов из этой или другой базы данных;
- Код выполняет чтение из этих документов, или/и запись в них.
Выполняя тестирование на протяжении многих лет, мы обнаружили, что, обычно, первый шаг является очень быстрым и не требует оптимизации, по крайней мере, пока нет более объемных задач. Третий шаг часто медленен, но, к сожалению, он не очень гибок. То есть, маловероятно, что вы обнаружите, что ваш код неэффективен при чтении информации или сохранения ее в набор документов. Например, пытаясь сохранить текущую дату в поле DateToday, вы, вероятно, использовали бы один из следующих методов:
Расширенный класс
Set Doc = dc.getfirstdocument
Do while not (Doc is Nothing)
Doc.DateToday = Today
Call Doc.Save
Set Doc = dc.getnextdocument ( Doc )
Loop
ReplaceItemValue
Set Doc = dc.getfirstdocument
Do while not (Doc is Nothing)
Call Doc.ReplaceItemValue ("DateToday", Today)
Call Doc.Save
Set Doc = dc.getnextdocument (Doc)
Loop
StampAll
Call dc.StampAll ("TodayDate", Today)
В наших тестах мы никогда не видели различий в производительности между первыми двумя из трех приведенных выше процедур. Использование расширенного синтаксиса класса doc.DateToday = Today кажется таким же быстрым, как и использование doc.ReplaceItemValue ("DateToday", Today). Теоретически, мы должны были бы увидеть некоторое различие в производительности, поскольку в одном случае мы не явно указываем Lotus Notes, что будем обновлять элемент поля, поэтому Lotus Notes должен был бы потратить немного больше времени, определяя, что DateToday на самом деле является полем. Однако практические тесты не показывают отличий.
Метод dc.StampAll быстрее, если вы обновляете много документов с одним значением, как в предыдущем примере. Существовали некоторые промежуточные версии, в которых программная ошибка делала данный метод значительно более медленным, поэтому, если вы не используете все самое новое и лучшее, убедитесь, что он работает оптимально (либо путем тестирования, либо путем проверки списка исправлений). В Lotus Notes/Domino 6.5 и 7 этот метод опять работает быстро. Однако существует так много проверок, выполняемых с данными или переменными данными для записи в документы, что dc.StampAll не всегда жизнеспособен. Мы относим его к категории ценной информации, которую вы в некоторых случаях можете использовать в конкретном приложении, а в некоторых нет.
При решении, на каком же из трех методов мы должны были бы остановиться, наш опыт подсказывает, что таким методом является ReplaceItemValue (получение коллекции документов). Оказывается, что он часто является самым продолжительным по времени участком кода, но, к счастью, наиболее сжимаемым. Ему мы уделяли основное внимание при тестировании, и именно его будем рассматривать до конца данного раздела.
Тестирование
Технология нашего тестирования заключалась в создании большой базы данных с документами примерно одинакового размера (около 2K) и с одинаковым количеством полей (примерно 200). Мы устанавливали в документах некоторые тщательно запрограммированные различия, для того чтобы мы могли выполнять поиск любого количества документов. В частности, мы настраивали документы так, чтобы мы могли искать 1, 2, 3, … 9, 10 документов, а также 20, 30, 40, … 90, 100; и 200, 300, 400, … 900, 1000 и т.д. Это давало нам огромное число информационных точек и позволяло проверять, не получаем ли мы хорошую производительность лишь для узкого набора условий. Например, db.search является отличным исполнителем при большом подмножестве документов в базе данных, но плохим исполнителем при маленьком подмножестве. Без тщательного тестирования на всем спектре условий, мы могли бы быть введены в заблуждение относительно характеристик производительности.
Мы запускали тесты на длительное время, записывая результаты в текстовые файлы, которые затем могли бы импортировать в электронные таблицы и презентационные программы для отображения в представлении двумерных графиков. После множества таких итераций и после работы как с маленькими базами данных (10 тысяч документов), так и с большими (4 миллиона документов), мы пришли к определенным выводам, которые, надеемся, будут полезны разработчикам приложений.
Какие методы самые быстрые?
Самым быстрым методом получения коллекции документов для чтения или записи является использование либо db.ftsearch, либо view.GetAllDocumentsByKey. Оказывается, что другие методы (смотрите список ниже) могут быть близки к ним по скорости (для некоторых наборов документов, рассматриваемых ниже), но ни один из них не может сравниться с этими методами одновременно для маленьких и для больших коллекций. Здесь мы перечислим методы и приведем краткое объяснение, а рассмотрим их более подробно позже.
- view.GetAllDocumentsByKey получает коллекцию документов на основе ключа в представлении, затем выполняет итерацию по этой коллекции, используя набор doc = dc.GetNextDocument (doc);
- db.ftsearch получает коллекцию документов на основе критерия полнотекстового поиска в базе данных, затем выполняет итерацию по этой коллекции, используя набор doc = dc.GetNextDocument (doc);
- view.ftsearch получает коллекцию документов на основе критерия полнотекстового поиска, но ограничивает результаты документами, которые уже имеются в представлении. Затем он выполняет итерацию по этой коллекции, используя набор doc = dc.GetNextDocument (doc);
- db.search получает коллекцию документов на основе не полнотекстового поиска документов в базе данных, затем выполняет итерацию по этой коллекции, используя набор doc = dc.GetNextDocument (doc);
- view.GetAllEntriesByKey получает коллекцию элементов представления в представлении, а затем либо читает непосредственно из значений столбцов, либо получает идентификатор документа на сервере через элемент представления. После чего он выполняет итерацию по этой коллекции, используя набор entry = nvc.GetNextEntry (entry).
Если у вас есть небольшая коллекция документов (например, 10) и маленькая база данных (например, 10000 документов), различные методы будут показывать примерно одинаковую производительность, и все они будут очень быстрыми. Это можно было бы назвать тривиальным случаем, и если этот код не выполняется повторно много раз (или не часто используется в вашем приложении), вы можете оставить его нетронутым и перейти к более насущным проблемам.
Однако вы все равно можете обнаружить небольшие отличия, и если вам нужно получать много коллекций документов, то даже экономия доли секунды при каждом выполнении вашего кода будет иметь значение. Кроме того, если ваше приложение велико (или растет), вы увидите, что различия во времени становятся основным вопросом!
Приведем два пользовательских примера: первый - запланированные агенты (scheduled agents), настроенные на очень частое выполнение (каждые несколько минут или при любой записи или при любом обновлении документов) и выполняющие итерацию по каждому новому документу для получения критерия поиска и последующего выполнения операций поиска на основе этого критерия. Если обрабатывается 10 новых документов, выполняется 10 операций поиска, а если обрабатывается 100 новых документов, выполняется 100 операций поиска. В этом случае, если бы мы могли сэкономить 0.5 секунды при получении коллекции документов, реальная экономия была бы равна произведению 0.5 на 10 или 100, умножалась далее на количество выполнений агента. Можно было бы легко сэкономить многие минуты в каждом часе в периоды большой загрузки, что существенно. Другой пример - главная форма имеет событие PostOpen или QuerySave, которое выполняет этот код. Если у вас происходят сотни редактирований в час (или больше), эти 0.5 секунды экономии умножатся до заметного результата.
За и против каждого метода
Объясняя коллегам или пользователям, почему некоторые из этих методов быстрее или проще, чем другие, мы часто бывали вовлечены в оживленные дискуссии, полные аргументов "с одной стороны" и "с другой стороны". К нашему глубокому удовлетворению, чем глубже мы погружались в эти аргументы, тем яснее становились проблемы. Мы попытаемся привнести это оживление в данную статью при помощи двух мифических спорящих оппонентов, Прометеуса (Prometheus, для друзей просто "Pro") и его скептического коллеги Конни (Connie, или просто "Con").
Prometheus: view.GetAllDocumentsByKey выглядит очень быстрым. Я решил советовать использовать его везде, где только возможно.
Connie: Прекрасно, мой друг, но что если вы ищете данные в Domino Directory? Вы не сможете легко получить разрешение создать там новые представления.
Pro: Согласен. Хорошо, я буду использовать этот метод в приложениях, где я контролирую поисковую базу данных.
Con: Да? А если вам придется создать 10 дополнительных представлений в базе данных, будет ли этот метод также хорош? Подумайте обо всех необходимых дополнительных индексациях представлений.
Pro: Это, возможно, покажется странным, но если я создаю оптимизированные представления, они, вероятно, индексируются менее чем за 100 миллисекунд каждые 15 минут при выполнении задания UPDATE - больше, если требуется операциями поиска. Неужели мы не можем пожертвовать несколько сотен миллисекунд каждые несколько минут?
Con: Как упростить эти представления? Сложно ли это? Сколько потребуется работы по обслуживанию?
Pro: Ничего страшного. Для оптимизации поискового представления (lookup view) сначала максимально оптимизируется критерий выбора. Это уменьшает размер индекса представления и, следовательно, время обновления индекса и выполнения операций поиска. Теперь подумайте о том, как будете выполнять поиск с этим представлением. Если вы собираетесь получать все документы, рассмотрите использование одного отсортированного столбца с формулой "1". Тогда получение всех документов в представлении является тривиальной задачей. Если необходимы различные поля с информацией, подумайте о создании второго столбца, объединяющего эти данные в одну операцию поиска. Одна операция поиска намного быстрее нескольких, даже если объем получаемых данных одинаков.
Con: Хорошо, возможно, вы меня убедили. Но имеется db.ftsearch, разрекламированный как очень быстрый, но я не уверен, что готов использовать этот метод. Такое впечатление, что для него необходима большая инфраструктура.
Pro: Это правда, использование db.ftsearch в коде оправдано. Но необходимо, во-первых, поддерживать полнотекстовый индекс и, во-вторых, конфигурация сервера Domino должна включать FT_MAX_SEARCH_RESULTS=n, где n - это число, большее максимального размера коллекции, которая должна возвращаться для вашего кода. Без этого вы ограничены 5000 документами.
Con: А что произойдет, если полнотекстовый индекс не обновляется достаточно быстро?
Pro: В этом случае ваш код может содержать вызов db.UpdateFTIndex для обновления индекса.
Con: Мое тестирование показывает, что это может быть довольно длительная по времени операция, и это время намного перекроет все преимущества в производительности, получаемые от использования db.ftsearch. И что произойдет, если полнотекстовый индекс так и не был создан?
Pro: Если база данных имеет менее 5000 документов, временный полнотекстовый индекс будет создаваться "на лету" за вас.
Con: С этим есть две проблемы. Во-первых, временный полнотекстовый индекс очень неэффективен, потому что он создается после запуска кода. Во-вторых, 5000 документов - не очень высокий порог. Похоже, что это могли бы быть лишь некоторые почтовые файлы в моей организации. Что если в базе данных имеется более 5000 документов?
Pro: В этом случае использование using db.UpdateFTIndex (True) создаст постоянный полнотекстовый индекс.
Con: Хорошо, но создание полнотекстового индекса для больших баз данных может быть очень длительной по времени процедурой. Я также знаю, что полнотекстовый индекс будет создаваться только для локальной базы данных, то есть, расположенной на том же сервере, что и выполняющийся код.
Pro: Совершенно верно. К счастью, Lotus Notes/Domino 7 имеет улучшенный вывод на консоль, а также обладает способностью использовать Domino Domain Monitoring (DDM) для более точного отслеживания таких проблем, как использование методов ftsearch с базами данных, не имеющими полнотекстового индекса. Вот пара сообщений, которые вы можете получить в консоли. Как видите, они довольно понятны:
Agent Manager: Full text operations on database 'xyz.nsf' which is not full text indexed. This is extremely inefficient.
mm/dd/yyyy 04:04:34 PM Full Text message: index of 10000 documents exceeds limit (5000), aborting: Maximum allowable documents exceeded for a temporary full text index
Con: Я заметил, что вы до сих пор не сказали ничего положительного о view.ftsearch, view.GetAllEntriesByKey или db.search. Мне кажется, я знаю, почему. Первые два в определенных условиях работают быстро, но, если представление структурировано так, что поисковые данные проиндексированы ближе к концу представления, они могут быть очень медленными. А db.search очень эффективен для маленьких коллекций документов.
Pro: Все верно. Однако db.search очень эффективен для операций поиска по времени/дате, в которых вы не хотите создавать представление с формулами времени/даты и поддерживать полнотекстовый индекс для использования метода db.ftsearch. Также, если вы выполняете поиск в базах данных, которые вы не контролируете, и если эти базы данных еще не имеют полнотекстового индекса, возможно, что db.search - это ваш единственный реальный вариант получения коллекции документов.
Приведем несколько диаграмм, которые помогут понять приведенные выше утверждения, высказанные Pro. Эти диаграммы показывают время всего лишь получения коллекции документов. Никакого чтения из этих документов не производится, и ничего в них не записывается. Это тестовое приложение в нашей тестовой среде, поэтому абсолютные значения должны восприниматься критически. Однако соотношения различных методов должны согласовываться с тем, что вы могли бы обнаружить в вашей собственной среде.
На рисунке 1 db.ftsearch и view.GetAllDocumentsByKey, фактически, неотличимы друг от друга; оба являются наилучшим выбором. Назовем это ничьей в борьбе за первое место. Третьим (очень близким к лидерам) был бы view.GetAllEntriesByKey, в то время как view.ftsearch начинает выполняться очень хорошо, но затем быстро ухудшает результаты при достижении числа документов около 40.
Рисунок 1. Коллекции документов, оптимизированные представления (до 100 документов)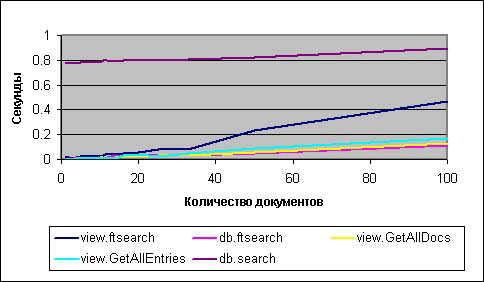
Рисунок 2 незначительно отличается от рисунка 1 в том, что db.search ищет все лучше и лучше по мере увеличения количества документов. Оказывается, что при увеличении размера коллекции с 5 до 10 процентов всех документов в базе данных, db.search будет также быстр, как и лидеры. А, как мы видели на рисунке 1, view.ftsearch при увеличении размеров коллекции работает все хуже и хуже.
Рисунок 2. Коллекции документов, оптимизированные представления (от 100 до 1000 документов)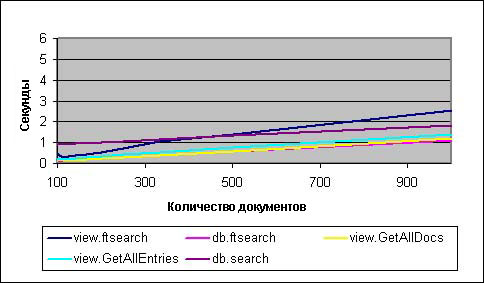
На рисунке 3 представления больше не оптимизированы на размещение результатов ближе к началу представления. То есть, если мы получаем коллекцию лишь небольшого числа документов в сравнении с нашей тестовой средой, то можем попытаться изменить результаты так, чтобы эти несколько документов были расположены ближе к началу или к концу поискового представления. На рисунках 1 и 2 эти документы были расположены ближе к началу представления, но на рисунке 3 они расположены ближе к концу. Для трех из приведенных выше методов это не важно (db.search, db.ftsearch и view.GetAllDocumentsByKey). Однако для view.ftsearch и view.GetAllEntriesByKey такое переключение катастрофично в смысле показателей производительности. Масштаб рисунков 2 и 3 необходимо изменить - по оси Y вместо одной секунды нужно установить шесть секунд!
Рисунок 3. Коллекции документов, не оптимизированные представления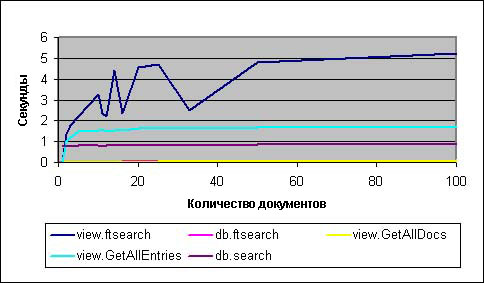
Заключение
Когда это возможно, используйте view.GetAllDocumentsByKey для получения коллекции документов. Вместе с этим оптимизируйте ваши поисковые представления так, чтобы они были максимально простыми и эффективными. Во второй части данной серии статей даются некоторые советы по этой теме.
Если ваш поиск должен выполняться по форматированным текстовым (rich text) полям, или ваша база данных уже имеет полнотекстовый индекс, db.ftsearch является отличным выбором, и его стоит использовать. Ваши результаты всегда должны содержать менее 5000 документов, иначе используйте параметр Notes.ini FT_MAX_SEARCH_RESULTS=n (где n - это максимальное число возвращаемых документов), чтобы гарантировать исключение возможности потери целостности ваших данных из-за данного ограничения.
Этим завершается первая часть нашего исследования производительности приложений для Notes/Domino 7. Во второй части мы рассмотрим, как можно создавать высокопроизводительные представления. До встречи!
- Купить книгу по Lotus Notes Domino для разработчиков приложений в интернет-магазине IT-Shop.ru
- Сертификация по Lotus Domino
- Купить BrightStor ARCserve Backup r11.1 для Lotus Domino со скидкой в интернет-магазине IT-Shop.ru
- Обратиться в компанию Interface Ltd. за дополнительной информацией/по вопросу приобретения продуктов
- Производительность приложений для Lotus Notes/Domino 7: часть 2