При проектировании учетных систем большое внимание уделяется разработке процедур контроля корректности вводимых данных. Причина вполне понятна: неправильные данные при заполнении заказа на покупку, ошибки при вводе информации в страховой контракт, противоречивая информация об одном и том же клиенте из разных систем могут служить причиной принятия неправильных решений и, как следствие, вести к финансовым и репутационным потерям компании. Традиционно, контроль правильности ввода информации ложится на СУБД и на бизнес-логику приложения. На уровне базы данных контролируется заполненность полей, ссылочная целостность, соблюдение простых бизнес-правил (например, количество приобретаемых товаров должно быть положительным). Соблюдение более сложных бизнес-правил (например, лимит задолжности покупателя при формировании нового заказа не должен превышать определенную сумму) часто контролируется на уровне приложения, хотя иногда этим также занимается база данных на уровне триггеров. Контроль непротиворечивости данных из различных систем, в процессе которого данные проверяются на соответствие различным правилам, часто осуществляется на уровне импорта их в общее аналитическое хранилище. Это позволяет, избегая явных коллизий, строить сводные аналитические отчеты по всем процессам в компании из всех учетных систем.
Все эти традиционные и необходимые подходы объединяет требование четкого описания и формализации всех правил, на соответствие которым система должна проверять входные данные. Однако существуют ошибки ввода, которые заранее предусмотреть очень трудно или невозможно. Например, мы можем предусмотреть формальные бизнес-правила, описывающие, что скидка на товар не может быть больше 100%; человек, берущий кредит, должен быть совершеннолетним; а в чеке все покупки должны быть с положительными величинами. В этом случае предоставленная скидка в размере 98% при покупке автомобиля; девятнадцатилетний возраст человека, оформляющего кредит на покупку дома; 5 килограмм петрушки в чеке в супермаркете теоретически не исключены, но крайне подозрительны. Существуют несколько подходов по выявлению таких подозрительных данных и сигнализации о них.
Первый подход основывается на принципах нечеткой логики, т.е. когда ограничения на размер скидки, возраст или объем закупки формулируются в несколько размытых терминах принадлежности к допустимому множеству. Т.е. функция принадлежности к категории "молодой человек" принимает значение 1 ("точно" молодой) в диапазоне возраста от 0 до 25 лет, значение 0 ("точно" не молодой) в диапазоне более 45 лет и промежуточное значение от 0 до 1 между 25 и 45 годами. Алгебра с нечеткими множествами целиком описывается операциями с нечеткими функциями принадлежности, так, например, является ли человек одновременно молодым и богатым описывается произведением функции его принадлежности к множеству молодых и функции принадлежности к множеству богатых. Этот подход достаточно распространен, но обладает недостатком, заключающимся в произвольности описания нечетких границ, формы функции принадлежности и выбором пороговых значений для принятия решений. Вследствие этого требуется большое время для адаптации таких правил к реальным требованиям, а также большая зависимость от экспертных оценок.
Второй и более эффективный, на наш взгляд, подход заключается в статистическом анализе вводимой записи и оценке ее вероятности в уже накопленной истории записей того же типа. Так как совокупность исторических записей может быть неоднородной, то мы должны учитывать уже сложившуюся структуру в накопленной информации. То есть сначала мы должны выделить в накопленной истории группы похожих по статистическим характеристикам записей (кластеров) и оценить вероятность проверяемой на подозрительность информации на принадлежность к одной из уже выделенных групп. Если вводимая информация не вписывается в сложившуюся структуру, т. е. вероятность ее принадлежности ко всем выделенным группам мала (ниже определенного порога), то система сигнализирует о наличии подозрительного ввода и необходимости проведения дополнительной проверки этой информации на правильность.
Мы предлагаем реализацию описанного подхода на платформе Microsoft SQL Server Analysis Services 2005/2008 с использованием алгоритма кластеризации Expectation Maximization. В качестве клиентского приложения визуального анализа подозрительных данных можно использовать Microsoft Excel 2007.
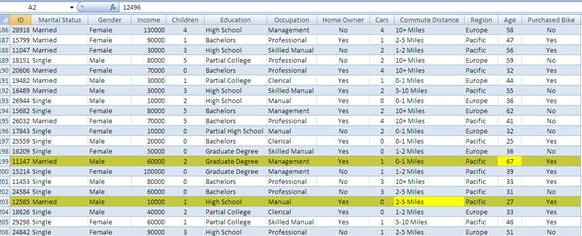 |
| Рис. 1 - Обнаруженные исключения выделены цветом. В строках также выделена наиболее "подозрительная" ячейка. |
Проиллюстрируем этот подход на демонстрационных данных о клиентах компании Adventure Works. У нас есть таблица со следующей информацией о клиентах:
- семейное положение
- пол
- годовой доход
- число детей
- образование
- род занятий
- владелец дома
- число машин
- расстояние до работы
- возраст
- Создадим структуру данных в Analysis Services для осуществления кластерного анализа при помощи следующего DMX-запроса:
CREATE MINING STRUCTURE [Input Cluster Structure]
(
[CustomerKey] LONG KEY,
[Семейное положение] TEXT DISCRETE,
[Пол] TEXT DISCRETE,
[Годовой доход] Long Continuous,
[Число детей] Long DISCRETE,
[Образование] TEXT DISCRETE,
[Род занятий] TEXT DISCRETE,
[Владелец дома] TEXT DISCRETE,
[Число машин] Long DISCRETE,
[Расстояние до работы] TEXT DISCRETE,
[Регион] TEXT DISCRETE,
[Возраст] LONG CONTINUOUS
)
- Создадим модель кластерного анализа в уже созданной структуре данных при помощи следующего DMX-запроса:
ALTER MINING STRUCTURE [Input Cluster Structure]
ADD MINING MODEL [Input Cluster Model]
(
[CustomerKey],
[Семейное положение] PREDICT,
[Пол] PREDICT,
[Годовой доход] PREDICT,
[Число детей] PREDICT,
[Образование] PREDICT,
[Род занятий] PREDICT,
[Владелец дома] PREDICT,
[Число машин] PREDICT,
[Расстояние до работы] PREDICT,
[Регион] PREDICT,
[Возраст] PREDICT
) USING Microsoft_Clustering(CLUSTER_COUNT = 0) WITH DRILLTHROUGH
- Обучим модель на накопленных данных из таблицы SQL при помощи следующего DMX-выражения:
INSERT INTO MINING STRUCTURE [Input Cluster Structure]
(
[CustomerKey],
[Семейное положение],
[Пол],
[Годовой доход],
[Число детей],
[Образование],
[Род занятий],
[Владелец дома],
[Число машин],
[Расстояние до работы],
[Регион],
[Возраст]
)
OPENROWSET
(
'SQLNCLI',
'Server=.;Database=AdventureWorksDW;Trusted_Connection=yes;',
'
SELECT
[CustomerKey],
[Семейное положение],
[Пол],
[Годовой доход],
[Число детей],
[Образование],
[Род занятий],
[Владелец дома],
[Число машин],
[Расстояние до работы],
[Регион],
[Возраст]
FROM
dbo.InputErrors
'
)
- Теперь мы можем написать запрос на получение вероятности каждой строки вводимых данных, а также на распределение вероятностей для всех столбцов для оценки вероятности значений в каждом столбце при помощи следующего DMX-выражения:
SELECT
T.[Семейное положение],
PredictHistogram([Семейное положение]) AS [Распределение для "Семейное положение"],
T.[Пол],
PredictHistogram([Пол]) AS [Распределение для "Пол"],
T.[Годовой доход],
Predict([Годовой доход]) AS [Среднее для "Годовой доход"],
PredictVariance([Годовой доход]) AS [Дисперсия для "Годовой доход"],
T.[Число детей],
PredictHistogram([Число детей]) AS [Распределение для "Число детей"],
T.[Образование],
PredictHistogram([Образование]) AS [Распределение для "Образование"],
T.[Род занятий],
PredictHistogram([Род занятий]) AS [Распределение для "Род занятий"],
T.[Владелец дома],
PredictHistogram([Владелец дома]) AS [Распределение для "Владелец дома"],
T.[Число машин],
PredictHistogram([Число машин]) AS [Распределение для "Число машин"],
T.[Расстояние до работы],
PredictHistogram([Расстояние до работы]) AS [Распределение для "Расстояние до работы"],
T.[Регион],
PredictHistogram([Регион]) AS [Распределение для "Регион"],
T.[Возраст],
Predict([Возраст]) AS [Среднее для "Возраст"],
PredictVariance([Возраст]) AS [Дисперсия для "Возраст"],
PredictCaseLikelihood() AS [Вероятность всей строки]
FROM
[Input Cluster Model]
PREDICTION JOIN
OPENROWSET
(
'SQLNCLI',
'Server=.;Database=AdventureWorksDW;Trusted_Connection=yes;',
'
SELECT
[CustomerKey],
[Семейное положение],
[Пол],
[Годовой доход],
[Число детей],
[Образование],
[Род занятий],
[Владелец дома],
[Число машин],
[Расстояние до работы],
[Регион],
[Возраст]
FROM
dbo.InputErrors
'
) AS T
ON
T.[Семейное положение] = [Input Cluster Model].[Семейное положение]
AND T.[Пол] = [Input Cluster Model].[Пол]
AND T.[Годовой доход] = [Input Cluster Model].[Годовой доход]
AND T.[Число детей] = [Input Cluster Model].[Число детей]
AND T.[Образование] = [Input Cluster Model].[Образование]
AND T.[Род занятий] = [Input Cluster Model].[Род занятий]
AND T.[Владелец дома] = [Input Cluster Model].[Владелец дома]
AND T.[Число машин] = [Input Cluster Model].[Число машин]
AND T.[Расстояние до работы] = [Input Cluster Model].[Расстояние до работы]
AND T.[Регион] = [Input Cluster Model].[Регион]
AND T.[Возраст] = [Input Cluster Model].[Возраст]
ORDER BY PredictCaseLikelihood()
- По результатам выполнения этого запроса можно выделить наименее вероятные записи. Такими в нашем примере являются:
- Женатый 30-летний мужчина из Северной Америки с двумя детьми с бакалаврским образованием, но работающий рабочим и получающий 10 000 долларов в год.
- 80-летний мужчина из Европы с годовым доходом 130 000 долларов в год с ученой степенью без машины и без дома.
Таким образом, использование средств Data Mining позволяет быстро и эффективно обнаруживать подозрительные и, возможно, ошибочные данные, что повышает контроль целостности и непротиворечивости информации в учетных и аналитических системах компании.