Как известно, в Oracle Database 10 g Release 1 были сделаны революционные изменения в диагностике производительности и в настройке. Все методы ручного сбора данных и анализа, которые мы обсуждали в предыдущих главах, стали теперь полностью автоматизированными и сделаны частью базы данных. Для сбора различных статистических данных в Oracle Database 10 g использованы механизм и интеллектуальная архитектура, получившие общее название Manageability Infrastructure (управляемая инфраструктура). Мало того, что она удовлетворяет всем требованиям к быстрому и точному анализу первопричин, обсуждавшимся в Главе 4, но эта инфраструктура также предлагают "ремонтно-восстановительные" решения в терминах рекомендаций, консультаций и сгенерированных сервером предупреждений предварительного оповещения.
В этой главе мы приводим компоненты управляемой инфраструктуры, которые делают возможным подобную автоматическую диагностику и настройку. Сначала мы рассмотрим различные типы статистик базы данных, собираемые Oracle Database 10 g .
Статистика базы данных
Для диагностирования проблем в Oracle Database 10 g собираются и анализируются связанные с производительностью статистические данные. Фиксирование данных осуществляется с использованием облегченных методов сбора данных, которые не привносят в систему никакой измеримой дополнительной нагрузки. Эти методы сообщают о главных проблемах и предлагают корректирующие действия или информационные сообщения для их решения. Кроме того, они сообщают о непроблематичных областях; таким образом, вы можете сосредоточиться только на проблематичных областях.
- Собранные статистические данные могут быть в общих чертах поделены на категории следующих типов:
- Статистические данные модели времени
- Статистические данные модели ожидания
- Статистические данные операционной системы
- Дополнительная статистика SQL
- Метрики базы данных
Статистические данные модели времени
Статистические данные модели времени впервые появились в Oracle Database 10 g . Как мы упоминали в Главе 2, OWI всего лишь сообщает о времени ожидания событий, которых ожидает сеанс. Статистические данные модели времени обеспечивают разбивку времени сеанса, потраченного на различных шагах выполнения текущей задачи, типа полного или частичного синтаксического анализа, выполнения SQL , выполнения PL / SQL , выполнения Java и так далее. Эти статистические данные выводятся в представлении V$SESS_TIME_MODEL. Итоговые статистические данные модели времени на системном уровне выводятся в представлении V$SYS_TIME_MODEL, как показано в следующем примере:
select stat_name, value from v$sys_time_model;
STAT_NAME VALUE
-------------------------------------------------- ----------
DB time 835243622
DB CPU 633280130
background elapsed time 3737809876
background cpu time 1869951797
sequence load elapsed time 122400
parse time elapsed 192685706
hard parse elapsed time 151503406
sql execute elapsed time 828428484
connection management call elapsed time 856270
failed parse elapsed time 243612
failed parse (out of shared memory) elapsed time 0
hard parse (sharing criteria) elapsed time 861810
hard parse (bind mismatch) elapsed time 798655
PL/SQL execution elapsed time 94173710
inbound PL/SQL rpc elapsed time 0
PL/SQL compilation elapsed time 94186909
Java execution elapsed time 0
17 rows selected.
Самой важной статистикой модели времени является время DB . Оно показывает полное время, израсходованное сеансами на вызовы базы данных. Это эквивалентно сумме процессорного времени и времени ожидания всех сеансов, не ожидающих событий, отнесенных к классу Idle wait (ожидание запроса на операцию). Однако оно фиксируется отдельно. Следующее разбиение статистик модели времени показывает, какие статистические данные являются подмножествами:
1. background elapsed time (общее затраченное время)
2. background cpu time (процессорное время в фоновом режиме)
3. DB time (время DB)
4. DB CPU (время центрального процессора DB )
5. connection management call elapsed time (общее затраченное время на вызовы управления подключениями)
6. sequence load elapsed time (общее затраченное время на загрузку последовательностей)
7. sql execute elapsed time (общее время выполнения sql -предложений)
8. parse time elapsed (общее время синтаксического разбора sql -предложений)
9. hard parse elapsed time (время полного, "тяжелого", синтаксического разбора)
10. hard parse (sharing criteria) elapsed time ( время тяжелого разбора с разделяемыми (общими) условиями)
11. hard parse ( bind mismatch ) elapsed time (время тяжелого разбора с несочетающимися bind -переменными)
12. failed parse elapsed time (время на ошибочные тяжелые разборы)
13. failed parse ( out of shared memory ) elapsed time (время на ошибочные по причине недостатка разделяемой памяти) тяжелые разборы)
14. PL / SQL execution elapsed time (общее время на выполнение PL / SQL -объектов)
15. inbound PL / SQL rpc elapsed time (общее время выполнения входящих rpc -вызовов PL / SQL )
16. PL / SQL compilation elapsed time (общее время на компиляцию PL / SQL -объектов)
17. Java execution elapsed time (общее время выполнения Java -программ)
Если сеанс затрачивает меньше времени на вызовы базы данных, это значит, что он лучше выполняется. Цель проводимой вами настройки должна состоять в том, чтобы сократить для сеанса полное время DB .
Статистические данные модели ожидания
Сегодня статистические данные модели ожидания давно уже не являются новостью для пользователей. В Oracle Database 10 g Release 1 отслеживается более 800 событий ожидания, чтобы сообщать о времени, проведенном сеансом в ожидании этих событий. Они классифицированы по 12 классам ожидания. Такая классификация позволяет более просто проводить высокоуровневый анализ событий ожидания. Классификация базируется на том решении, которое обычно применяется для разрешения проблемы с событием ожидания.
Статистические данные операционной системы
Статистические данные операционных систем предлагают информацию об использовании таких системных ресурсов, как центральный процессор, память и файловые системы. В версиях Oracle до Oracle Database 10 g , некоторые из этих статистических данных не были доступны из среды базы данных. Чтобы собрать статистику машинного уровня для исследования связанных с аппаратными средствами проблем, вы должны были использовать команды OS или инструментальные средства уровня OS . В Oracle Database 10 g такая статистика собирается внутри базы данных и отчет о ней предлагается в представлении V$OSSTAT, как показано ниже:
select stat_name, value
from v$osstat;
STAT_NAME VALUE
-------------------------------------------------- ----------
NUM_CPUS 1
IDLE_TICKS 22201887
BUSY_TICKS 3385285
USER_TICKS 2101041
SYS_TICKS 1284244
IOWAIT_TICKS 78316
AVG_IDLE_TICKS 22201887
AVG_BUSY_TICKS 3385285
AVG_USER_TICKS 2101041
AVG_SYS_TICKS 1284244
AVG_IOWAIT_TICKS 78316
OS_CPU_WAIT_TIME 9.2061E+11
RSRC_MGR_CPU_WAIT_TIME 0
IN_BYTES 123883520
OUT_BYTES 0
AVG_IN_BYTES 123883520
AVG_OUT_BYTES 0
17 rows selected.
Дополнительная статистика SQL
Дополнительные статистики SQL предлагают информацию на операторном уровне о времени класса ожидания, выполнении PL / SQL , выполнении Java и выбранных ( sampled ) переменных связывания. Кроме того, в Oracle Database 10 g вводится новое значение хеш-функции, SQL _ID, как строка символов для оператора SQL , которая уникальна, нежели в ранних версиях Oracle Database .
Метрики базы данных
Как известно, почти все статистики базы данных, отчет о которых приводится в различных V$-представлениях, являются накопительными (кумулятивными), начиная с момента запуска экземпляра. Как было сказано в Главе 2, чтобы найти скорость изменения значений статистик, о которых идет речь в этих представлениях, нужно делать снимки ( snapshot - снэпшот) через различные интервалы времени. В диагностике производительности скорость изменения более важна, чем кумулятивное значение статистики. В Oracle Database 10 g эти показатели легко доступны для разнообразных величин, типа времени, вызовов базы данных и транзакций. Для большинства этих метрик используется интервал одна минута, а для вывода применяются различные V$ - представления. Архивные данные метрик выводятся с помощью различных метрических V$ - представлений. Несколько таких представлений метрик перечислены в Таблице 9-1.
ТАБЛИЦА 9-1.
Представления метрик (неполный список)
|
V$METRICNAME |
Выводит идентификатор метрики ( ID ), название метрики вместе с названием группы метрик и идентификатором группы. Всего насчитывается 10 групп метрик и более 180 различных метрик. |
|
V$EVENTMETRIC |
Выводит значения метрик события ожидания. |
|
V$WAITCLASSMETRIC |
Выводит значения метрик класса события ожидания. |
|
V$SESSMETRIC |
Выводит значения метрик для статистик сеансового уровня. |
|
V$SYSMETRIC |
Выводит значения метрик для статистик системного уровня. |
|
V$FILEMETRIC |
Выводит значения метрик файла. |
Новые фоновые процессы
Ответственность за сбор, дискретность выборки и поддержание статистических данных в Oracle Database 10 g несут два новых фоновых процесса. Эти процессы называются MMON и MMNL .
Процесс MMON ( Manageability Monitor - монитор управляемости) несет ответственность за различные задачи управляемости, типа получения снимков-снэпшотов для различной статистической информации через предписанные интервалы времени и рассылку предупреждений в тех случаях, когда значения метрик превышают определенные пороги. Для выполнения этих задач процесс MMON может порождать множество подчиненных процессов.
Процесс MMNL ( Manageability Monitor - Lightweight - монитор управляемости - облегченный) несет ответственность за вычисление различных показателей и ежесекундное получение снэпшотов активных сеансов. Мы обсудим это позднее в разделе "Предыстория активных сеансов".
Примечание: С экземпляром базы данных ничего не произойдет, если процесс MMON или MMNL завершится по любой причине. Процесс PMON перезапустит отказавший процесс. В журнал оповещений будут записаны релевантные (относящиеся к делу - прим. пер.) сообщения.
Итак, как же Oracle Database 10 g фактически собирает и ведет отчетность и обслуживает данные о статистике производительности? Все перечисленное выше делается с помощью автоматически управляемого репозитория рабочей нагрузки.
Автоматически управляемый репозиторий рабочей нагрузки
В ядре Oracle Database хранятся многочисленные статистические данные, которые могут использоваться для идентификации проблем производительности. К сожалению, многие статистики базы данных не сохраняются на диске. Эти недостающие данные о предшествующих периодах становятся большой проблемой для специалистов-практиков, занимающихся производительностью, когда они пытаются идентифицировать и разрешить проблему, которая произошла некогда в прошлом. Архивные данные и статистика очень важны для мониторинга производительности базы данных и планирования загрузки оборудования.
В Oracle Database 10 g механизм сбора данных усовершенствован благодаря введению инструментов Automatic Workload Repository (автоматически управляемого репозитория рабочей нагрузки) и Active Session History (предыстория активных сеансов), которые пришли на замену предыдущих инструментальных средств сбора данных о производительности, типа Statspack и utlbstat /utlestat. К числу главных различий между сегодняшними репозиториями и предыдущими инструментальными средствами можно отнести следующее:
- У ранее использовавшихся инструментальных средств отсутствовал автоматизированный способ интерпретации собранных данных и результатов, продуцируемых в соответствии с имеющимися отчетами. Для сырых данных и отформатированного вывода из инструментального средства Statspack требовалась ручная интерпретация.
- В ранее использовавшихся инструментальных средствах отсутствовал превентивный мониторинг. Администратор базы данных мог настроить базу данных или решить любую проблему только после ее возникновения. Инструментальное средство Automatic Database Diagnostics Monitor ( ADDM - монитор автоматической диагностики экземпляра сервера базы данных) в Oracle Database 10 g обнаруживает проблему прежде, чем она нанесет удар, и сообщает возможные пути ее разрешения.
- Для обнаружения проблемы на уровне сегмента базы данных ADDM работает на детальном уровне. Например, если имеются "горячий" блок или "горячий" объект, вызывающие проблемы производительности, ADDM определяет объект и предлагает рекомендации по настройке, хотя эта информация не фиксируется непосредственно в отчете Statspack .
- Проблемы типа избыточных входов в систему и выходов из системы, ожиданий ITL и проблем, связанных с обслуживанием RAC , также не зафиксируются в отчете Statspack , но ADDM фиксирует эту информацию и предлагает консультации по настройке.
В автоматически управляемом репозитории рабочей нагрузки фиксируются все данные, которые фиксировались Statspack в более ранних версиях RDBMS Oracle . Кроме того, в нем фиксируются новые статистики, описанные в предыдущих разделах. AWR является хранилищем данных о производительности Oracle Database 10 g . Эти данные постоянно находятся в SGA , и к тому же сохранены на диске.
Собранные данные выводятся через доступные представления и отчет AWR , похожий на отчет, генерировавшийся Statspack . Однако доступ к этой информации намного более прост и удобен при использовании Oracle Enterprise Manager ( OEM ).
Снэпшоты репозитория
По умолчанию, AWR бывает готов к работе сразу после его установки. Для использования нового фонового процесса MMON требуется получать снэпшоты статистики базы данных каждые 60 минут. Данные сохраняются в наборе таблиц схемы SYS в новом обязательном табличном пространстве - SYSAUX . Как и в Statspack , каждый снэпшот определяется уникальным идентификатором, который называется SNAP_ID. По умолчанию, данные, хранящиеся более семи дней, удаляются. Многие из этих таблиц секционированы по диапазону, причем в качестве ключа секционирования используется уникальный идентификатор базы данных - DBID и столбец SNAP_ID. Подобная стратегия секционирования очень полезна в операциях доступа к данным и их обслуживания.
Примечание: Даже если не инсталлирована опция Oracle Partitioning , Oracle Database 10 g создаст для внутреннего использования требующиеся секционированные таблицы и индексы. Но для собственного пользования Oracle Partitioning вам все равно потребуется лицензировать и инсталлировать эту опцию.
В Oracle Database 10 g Release 1 имеется 140 таблиц, в которых хранятся данные AWR , и они доступны через 67 представлений. Имена таблиц имеют формат WRI$_*, WRH$_* и WRM$_*. " WR " означает " Workload Repository ", " I " означает " internal " (внутренний), "H" означает " historical " (архивные данные), а "M" означает " metadata " (метаданные). Есть несколько представлений, построенных на этих базовых таблицах. Имена представлений имеют формат DBA_HIST_*; звездочка (*) обозначает какую именно статистику показывает представление или таблица. Например, представление DBA_HIST_LATCH показывает связанную с защелками статистику для архивных снэпшотов. Это представление базируется на таблице WRH$_LATCH. Чтобы получить список имен этих таблиц и представлений, можно использовать следующий SQL -код:
select table_name
from dba_tables
where owner = "SYS"
and table_name like "WR%";
select view_name
from dba_views
where owner = "SYS"
and view_name like "DBA\_HIST\_%" escape "\";
Прототипы снэпшотов
AWR позволяет создавать прототипы ( baselines ) снэпшотов для сбора статистики производительности в конкретных временных рамках. Вообще говоря, вы создаете прототип для получения снэпшотов в тех случаях, если была обработана типичная рабочая нагрузка и производительность была приемлемой. В том случае, если та же самая рабочая нагрузка была обработана позже, но производительность является неприемлемой, может быть создан новый прототип для этих временных рамок для сравнения его с предыдущим прототипом. Различия в статистике производительности могут пролить свет на причины плохой производительности. Базовые снэпшоты также называют Preserved Snapshot Sets (сохраняемыми наборами снэпшотов).
Использование EM для управления AWR
Сегодня Oracle EM является основным инструментом взаимодействия с AWR . Однако можно также использовать процедуры поставляемого Oracle пакета для управления функциональностью AWR . Ручные (неавтоматические) процедуры описываются в следующем разделе.
Вы можете обратиться к AWR с домашней страницы Database Control пакета Oracle Enterprise Manager . Находясь на этой странице, сначала кликните по ссылке Administration (Администрирование), чтобы обратиться к странице администрирования, а затем кликните по ссылке Automatic Workload Repository под заголовком Workload в нижней части этой страницы.
Страница Automatic Workload Repository показана на Рис. 9-1. На этой странице вы можете просматривать и редактировать снэпшоты AWR и управлять ими.
Блок информации General (общая информация) показывает текущие параметры настройки снэпшотов и время снятия следующего снэпшота. Кнопка Edit отсылает вас к новой странице, на которой можно изменить интервал снятия снэпшотов и продолжительность использования (срок хранения) снэпшота, а также выполнить операцию погружения, чтобы изменить уровень сбора данных статистики.
Под заголовком Manage Snapshot and Preserved Snapshot Sets (управление снэпшотами и сохраняемые наборы снэпшотов) вы увидите общее число имеющихся снэпшотов и сохраняемых снэпшотов, которые используются в прототипах, а также дату и время создания первого (самого раннего) и последнего доступного снэпшота.
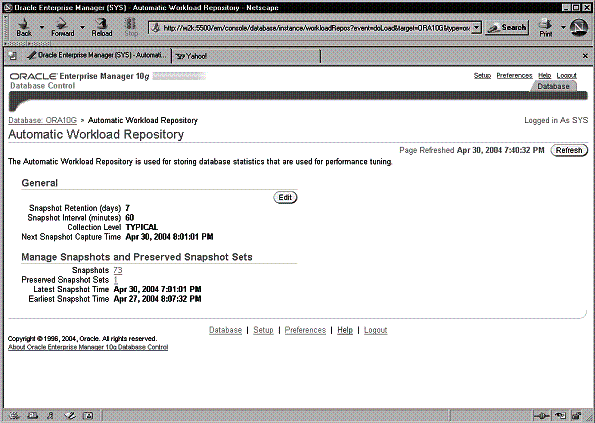
Рис. 9-1. Домашняя страница репозитория рабочей нагрузки
Если кликнуть по числу, показанному после Snapshot , можно оказаться на домашней странице Snapshots , где можно просмотреть информацию о снэпшотах. На Рис. 9-2 показана домашняя страница Snapshots .
- Используя выпадающее меню Actions , можно выполнять следующие задачи:
- Создавать набор сохраняемых снэпшотов (создание прототипа)
- Просматривать отчет (сравнение статистики из двух снэпшотов)
- Создавать задачу ADDM (для выполнения анализа набора снэпшотов)
- Удалять диапазон снэпшотов
- Сравнивать временные шкалы (с использованием двух наборов снэпшотов для двух периодов времени)
- Создавать наборы для настройки SQL ( SQL Tuning Set ), чтобы иметь возможность отслеживать и настраивать SQL -операторы
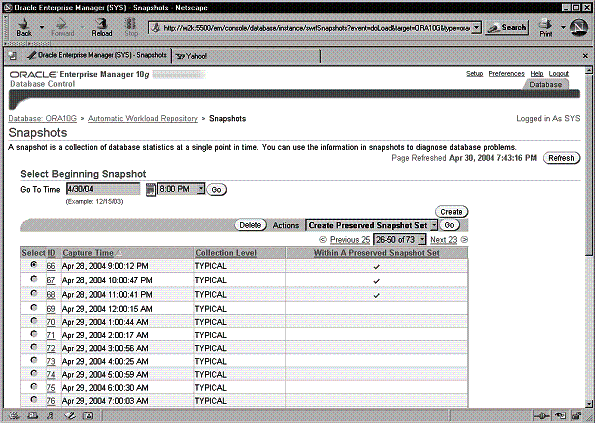
Рис. 9-2. Домашняя страница Snapshots
Чтобы вручную создать новый снэпшот, можно кликнуть по кнопке Create . Кнопка Delete удаляет указанный снэпшот. Кнопка Go инициализирует выбранную задачу из выпадающего меню Actions . Мы находим, что размещение кнопок Go , Create и Delete на этой странице сначала кажется немного запутанным, возможно из-за их положения на странице. В столбце Within a Preserved Snapshot Set (в составе набора сохраняемых снэпшотов) отмечены ID снэпшотов, которые являются частью прототипа или набора сохраняемых снэпшотов.
Вернувшись на домашнюю страницу AWR (Рис. 9-1), кликните по номеру, показанному рядом с Preserved Snapshot Set , и попадете на домашнюю страницу Preserved Snapshot Set , как показано на Рис. 9-3. На этой странице перечислены детали сохраняемых наборов снэпшотов, или прототипов, созданных в AWR . В выпадающем меню Actions будут предложены различные задачи, которые могут быть выполнены для этих базовых снэпшотов. Пожалуйста, обратите внимание, что идентификатор сохраняемого набора снэпшотов отличается от идентификатора снэпшота. Идентификатор снэпшота применим только к прототипам или сохраняемым снэпшотам AWR .
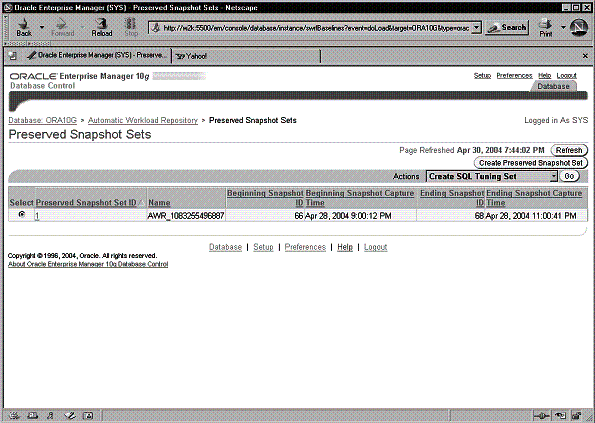
Рис. 9-3. Домашняя страница Preserved Snapshot Sets (прототипы)
Управление AWR вручную
Поставляемый Oracle пакет DBMS_WORKLOAD_REPOSITORY предлагает несколько подпрограмм, процедур и функций для ручного взаимодействия с AWR . Эти подпрограммы позволяют создавать снэпшоты по требованию, вычеркивать определенные диапазоны снэпшотов, создавать базовые снэпшоты, удалять их, а также - как мы обсуждали в предыдущих разделах - изменять интервалы снэпшотов и период сохранения данных, и так далее.
Изменение параметров настройки снэпшота
Частота снятия снэпшота, или интервал и время сохранения данных могут быть изменены, как это будет показано далее: в предлагаемом примере интервал изменяется на 30 минут, а продолжительность хранения данных - на 15 дней:
begin
dbms_workload_repository.modify_snapshot_settings (
interval => 30,
retention => 15 * 1440 );
end;
/
PL/SQL procedure successfully completed.
Примечание: Оба значения - и интервала, и продолжительности хранения - должны быть определены в минутах. Именно поэтому продолжительность хранения (15 дней) умножается на 1440 (минут в сутках).
Определенное для интервала значение должно находиться в диапазоне от 10 до 52 560 000 минут (то есть, 100 лет). Oracle c генерирует ошибку ( ORA -13511), если значение интервала будет вне этого диапазона. Однако у нулевого значения имеется специальный смысл: когда интервал установлен на нуль, Oracle отключает механизм снятия автоматических и ручных снэпшотов. В таком случае, Oracle просто генерирует для этого параметра очень большое значение (40150 дней).
Точно так же значение параметра продолжительности хранения должно находиться в диапазоне от 1400 минут (1 день) до 52 560 000 минут (100 лет). Oracle сгенерирует ошибку ( ORA -13510), если значение будет вне этого диапазона. И здесь у нулевого значения имеется специальный смысл. В том случае, если продолжительность хранения устанавливается на нуль, Oracle будет хранить снэпшот постоянно. В таком случае Oracle использует для этого параметра очень большое значение (40 150 дней).
Ниже показано, как можно увидеть текущие значения этих параметров. Данные столбца выводятся в формате дней и часов (+DDDDD HH:MI:SS.S):
col snap_interval for a20
col retention for a20
select snap_interval,
retention
from dba_hist_wr_control;
SNAP_INTERVAL RETENTION
------------------------------- --------------------
+00000 00:30:00.0 +00015 00:00:00.0
Примечание: Таблицы AWR постоянно находятся в табличном пространстве SYSAUX . AWR ежедневно производит зачистку данных снэпшотов, как только для них было достигнуто максимальное время сохранения. Если AWR обнаружит, что в табличном пространстве SYSAUX ощущается нехватка доступного пространства, то будет выполнена процедура "аварийной чистки", эффективно сокращающая время сохранения, а в файл трассировки и в журнал предупреждений будут записаны релевантные сообщения. Однако, вероятно, еще задолго до того как потребуется аварийная чистка, программный код уровня выделения пространства инициализирует сгенерированное сервером предупреждение из-за снижения уровня доступного пространства.
Создание и удаление снэпшотов
Возможно, в тех случаях, когда интервал автоматического создания снэпшотов является слишком большим для диагностирования проблем с производительностью, а именно для небольших заданий или при меньшей рабочей нагрузке, вам потребуется создавать снэпшоты вручную. В этом случае может понадобиться получить снэпшоты вручную - перед выполнением задания и сразу после того, как оно закончится.
Для создания снэпшотов по требованию можно использовать подпрограмму CREATE_SNAPSHOT. Эта подпрограмма может выполняться как процедура или как функция. Когда она выполняется как функция, она возвращает SNAP_ID только что созданного снэпшота. Дополнительный параметр flush_level управляет уровнем статистики, которая фиксируется в таблицах репозитория для этого снэпшота или сбрасывается на диск. Значение этого параметра по умолчанию равно TYPICAL . Но если требуются все детализированные статистики, вы должны установить параметр flush_level на ALL .
В следующих ниже примерах показано использование CREATE_SNAPSHOT и как процедуры, и как функции:
REM - As a Procedure
begin
dbms_workload_repository.create_snapshot();
end;
/
PL/SQL procedure successfully completed.
REM - As a Function
select dbms_workload_repository.create_snapshot('ALL') from dual;
DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT('ALL')
-----------------------------------------------
1931
Напротив, процедура DROP_SNAPSHOT_RANGE может использоваться для перманентного удаления диапазона снэпшотов. Для работы этой процедуры нужно знать значения SNAP_ID начала и конца диапазона удаляемых снэпшотов. У процедуры имеются два обязательных параметра - low_snap_id и high_snap_id . Дополнительный параметр dbid по умолчанию принимает значение идентификатора локальной базы данных. В приведенном ниже примере удаляется диапазон SNAP_ID с номерами от 1981 до 2004:
begin
dbms_workload_repository.drop_snapshot_range (
low_snap_id => 1981,
high_snap_id => 2004 );
end;
/
PL/SQL procedure successfully completed.
Как показано ниже, представление DBA_HIST_SNAPSHOT представляет список информации о доступных снэпшотах. В этом примере мы выбирали только столбцы, необходимые для только что обсуждавшейся процедуры:
col snap_id for 999999
col begin_interval_time for a26
col end_interval_time for a26
select snap_id, dbid, begin_interval_time, end_interval_time
from dba_hist_snapshot
order by 1 desc;
SNAP_ID DBID BEGIN_INTERVAL_TIME END_INTERVAL_TIME
------- ---------- -------------------------- -------------------------
2397 2847681843 29-MAR-04 06.00.47.194 PM 29-MAR-04 06.30.33.990 PM
2396 2847681843 29-MAR-04 05.30.58.107 PM 29-MAR-04 06.00.47.194 PM
2395 2847681843 29-MAR-04 05.00.07.715 PM 29-MAR-04 05.30.58.107 PM
2394 2847681843 29-MAR-04 04.30.21.575 PM 29-MAR-04 05.00.07.715 PM
2393 2847681843 29-MAR-04 04.00.32.191 PM 29-MAR-04 04.30.21.575 PM
2392 2847681843 29-MAR-04 03.30.43.423 PM 29-MAR-04 04.00.32.191 PM
2391 2847681843 29-MAR-04 03.00.57.354 PM 29-MAR-04 03.30.43.423 PM
2390 2847681843 29-MAR-04 02.30.06.223 PM 29-MAR-04 03.00.57.354 PM
2389 2847681843 29-MAR-04 02.00.17.503 PM 29-MAR-04 02.30.06.223 PM
Создание и удаление прототипа (набор сохраняемых снэпшотов)
Прототип или набор сохраняемых снэпшотов можно создать, используя подпрограмму CRATE_BASELINE из пакета DBMS_WORKLOAD_REPOSITORY. Подпрограмма может выполняться как функция или как процедура. Обязательные параметры - start _ snap _ id , end _ snap _ id и baseline _ name . Значение по умолчанию дополнительного параметра dbid равно идентификатору локальной базы данных. Когда она выполняется как функция, подпрограмма возвращает идентификатор прототипа или сохраняемого набора снэпшотов. В следующих примерах показывается использование подпрограммы CREATE_BASELINE как функции и как процедуры:
REM - As a Procedure
begin
dbms_workload_repository.create_baseline(
start_snap_id => 2305,
end_snap_id => 2310,
baseline_name => 'Good Nightly Batch');
end;
/
PL/SQL procedure successfully completed.
REM - As a Function
REM - Using 2200 for start_snap_id, 2205 for the end_snap_id and
REM - "Good Special Batch" for the baseline_name.
select dbms_workload_repository.create_baseline(
2200, 2205, 'Good Special Batch')
from dual;
DBMS_WORKLOAD_REPOSITORY.CREATE_BASELINE(2200,2205,'GOODSPECIALBATCH')
----------------------------------------------------------------------
3
Вновь созданному прототипу Oracle назначает уникальный идентификатор прототипа. Снэпшоты, попадающие в диапазон номеров снэпшотов, используемых для прототипа, будут сохраняться все время, пока в AWR существует прототип. Такие снэпшоты могут быть удалены только после удаления прототипа.
В том случае, если заданные идентификаторы снэпшотов не являются допустимыми, Oracle генерирует ошибку ( ORA -13506). Кроме того, задаваемое имя прототипа должно быть уникальным, иначе будет сгенерирована ошибка ( ORA -13528).
Процедура DROP_BASELINE удаляет указанный прототип. Для ее работы вы должны задать параметр baseline_name. У процедуры имеется опция для сохранения или удаления связанных с удаляемым прототипом снэпшотов. В том случае, если задается каскадное удаление, будут удалены все снэпшоты, входящие в прототип. Значением по умолчанию для этого параметра является FALSE , что означает, что связанные снэпшоты сохранятся, и будет удален только прототип. Значение по умолчанию дополнительного параметра, dbid , равно идентификатору локальной базы данных. В следующем примере удаляется прототип, названный " Routine Jobs ' ("стандартные задания") вместе со связанными с ним идентификаторами снэпшотов:
begin
dbms_workload_repository.drop_baseline('Routine Jobs', true);
end;
/
PL/SQL procedure successfully completed.
3
Отчеты AWR
В AWR содержится несколько SQL -скриптов для продуцирования отчетов по репозиторию рабочей нагрузки, которые напоминают отчеты Statspack . Однако отчет по репозиторию рабочей нагрузки содержит намного больше детвльной информации, чем отчет Statspack , так как в нем сообщается обо всех новых статистиках базы данных, которые мы обсуждали в предыдущих разделах; например, о статистиках модели времени и операционной системы. Кроме того, в отчете содержится статистика уровня имен сервисов и модулей.
В поставляемых Oracle скриптах awrrpt . sql и awrrpti . sql отчеты для указанного диапазона идентификаторов снэпшотов генерируются или в формате HTML, или в текстовом формате. Выходные данные этих сценариев, по существу, одни и те же, но последний сценарий позволяет определять конкретный экземпляр в среде базы данных со многими экземплярами. Для выполнения этих сценариев требуются привилегии администратора базы данных. Эти скрипты находятся в каталоге $ORACLE_HOME/rdbms/ admin .
Представления AWR
Просматривать статистику AWR можно, используя для этого различные представления. В Таблице 9-2 перечислены некоторые из этих представлений и кратко описано их содержание.
В дополнение к сохранению данных статистики производительности в таблицах AWR в табличном пространстве SYSAUX , Oracle Database 10 g также часто снимает снэпшоты активных сеансов и хранит эту информацию для анализа предыстории процесса. Этот механизм называют Active Session History (предыстория активных сеансов).
Предыстория активных сеансов
В Oracle Database 10 g активность выполняющихся в настоящее время сеансов может быть получена с помощью представлений V$SESSION и V$SESSION_WAIT . Представление V$SESSION_WAIT_HISTORY предлагает информацию о последних 10 событиях ожидания, с которыми столкнулся сеанс. Однако для расследования проблем с производительностью эти представления не обладают достаточным объемом информации об активности сеанса в период до начала наблюдений. В Oracle Database 10 g эта проблема решается путем введения предыстории активных сеансов ( Active Session History ).
Как следует из названия, Oracle предлагает информацию об активности сеанса в период до начала наблюдений для активных сеансов. База данных производит выборку значений для всех активных сеансов каждую секунду, чтобы отследить их состояние и сохраняет эту информация в одном из буферов SGA .
ТАБЛИЦА 9-2.
Представления AWR (неполный список )
|
Название представления |
Описание |
|
DBA_HIST_ACTIVE_SESS_HISTORY |
Отображает предысторию содержимого представления V$ACTIVE_SESSION_HISTORY. |
|
DBA_HIST_BASELINE |
Отображает информацию о прототипах, хранящихся в AWR . |
|
DBA_HIST_DATABASE_INSTANCE |
Отображает информацию о базе данных и экземпляре. |
|
DBA_HIST_SNAPSHOT |
Отображает информацию о снэпшотах AWR . |
|
DBA_HIST_SQL_PLAN |
Отображает информацию о планах выполнения SQL . |
|
DBA_HIST_WR_CONTROL |
Отображает установки, управляющие свойствами AWR . |
Информация о прошедших периодах отображается в представлении V$ACTIVE_SESSION_HISTORY. Это представление похоже на объединение представлений V$SESSION и V$SESSION_WAIT с данными для активных сеансов за период до начала наблюдений.
Другим важным различием между представлениями V$ACTIVE_SESSION_HISTORY и V$SESSION_WAIT_HISTORY является архивирование данных. Содержимое ASH записывается в таблицы базы данных средствами AWR . Подобное представление можно (грубо) назвать представлением "ретроспективного сеанса", поскольку оно помогает выполнять анализ участка ( spot analysis ) сеанса, диагностируя проблемы, которые, возможно, произошли в недавнем прошлом. Однако нельзя гарантировать, что такая информация всегда будет доступной в этом представлении. В очень активной базе данных с большим числом активных сеансов внутренний буфер может быстро переполниться. Доступная информация будет собираться Oracle и записываться в таблицу AWR , которую можно просмотреть через представление DBA_HIST_ACTIVE_SESSION_HISTORY . Представление V$ACTIVE_SESSION_HISTORY действует как единая опорная точка для различных частей информации, типа событий ожидания, объектов, к которым были обращения, израсходованное время центрального процессора, детали об операторе SQL , например, значение хэш-функции и план выполнения SQL .
Что такое - активный сеанс?
В предыдущем разделе мы упоминали о том, что ASH производит выборку значений для активных сеансов. Но что такое активный сеанс? Статус сеанса ACTIVE (активен) не следует путать с переменной V$SESSION.STATE, которая может иметь одно из двух значений - ACTIVE или INACTIVE . В ASH считается, что сеанс активен ( ACTIVE ), если вызов пользователем ядра RDBMS попадает в любую из следующих категорий:
- операции PARSE или EXECUTE, или FETCH
- Ожидание завершения ввода-вывода
- Ожидание сообщения или буфера из удаленного экземпляра (в RAC )
- Использует ЦП
- Отсутствие ожидания рекурсивного сеанса
- Для параллельного подчиненного процесса: отсутствие ожидания события PX_IDLE
- Любое другое ожидание, которое не попадает в класс ожидания Idle (не занято)
и собирает данные деятельности сеанса
Компоненты ASH
Для ASH не требуется выполнения никаких установок параметров инициализации или какого-либо скрипта инсталляции. Она считается активированной по умолчанию сразу после создания или проведения обновления до Oracle Database 10 g .
Новый фоновый процесс MMNL (облегченная версия MMON ) является ответственным за запись выбранных данных в находящийся в оперативной памяти циклический буфер в фиксированной области SGA . Затем производится выборка контента буфера и запись его в AWR -таблицу WRH$_ACTIVE_SESSION_HISTORY при каждом сбросе содержимого AWR на диск (по умолчанию это происходит каждый час). Кроме того, процесс MMNL также сбрасывает содержимое буфера в таблицу AWR всякий раз, когда буфер заполняется. Этому процессу для обновления содержимого буфера не требуется никаких защелок, и он не создает каких-либо проблем для деятельности базы данных.
По умолчанию верхний предел размера размещенного в оперативной памяти ASH -буфера равен 30 Мбайт. Минимальный размер буфера - 1 Мбайт. Размер буфера ASH в оперативной памяти зависит от таких факторов, как количество центральных процессоров, размер разделяемого пула, значение, установленное для SGA _TARGET, и некоторое произвольное округление чисел. В Oracle Database 10 g Release 1 для получения размер буфера применяется следующая формула; однако, в будущих выпусках она может измениться:
max (min (#of CPUs * 2MB, 5% of SHARED_POOL_SIZE, 30MB), 1MB)
Представление V$ACTIVE_SESSION_HI STORY базируется на структурах X$KEWASH и X$ASH . В структуре X$ASH содержатся выборочные детали каждого активного сеанса. В структуре X$KEWASH содержатся детальные сведения о количестве выборок, взятых в экземпляре.
Имеется несколько скрытых параметров инициализации, которые изменяют поведение используемых в ASH значений по умолчанию. Не стремитесь поскорее начать использовать их. Перед использованием таких параметров сначала всегда следует получить одобрение от службы Oracle Support .
Если динамический параметр _ASH_ENABLE установлен на FALSE , это приводит к дезактивации функциональных возможностей ASH , и представление V$ACTIVE_SESSION_HISTORY не будет больше заполняться. Значение по умолчанию _ASH_DISK_WRITE_ENABLE равняется TRUE , чтобы можно было сбрасывать хранящиеся в оперативной памяти данные ASH на диск. Установка этого параметра на FALSE приведет к отключению записи этих данных на диск. Так что, если по каким-то причинам вы не хотите сохранять данные ASH в AWR , но хотите сохранить их в памяти, вы можете установить этот параметр на FALSE . Вы можете также увеличить размер буфера, установив параметр _ASH_SIZE на значение, большее 30 Мбайт.
Представление V$ACTIVE_SESSION_HISTORY
В Таблице 9-3 описываются столбцы представления V$ACTIVE_SESSION_HISTORY и там, где это возможно, приводится их связь со столбцами, уже имеющимися в других представлениях V$.
Представление V$ACTIVE_SESSION_HISTORY может быть рассмотрено как таблица фактов в хранилище данных, где его (представления) столбцы являются измерениями таблицы фактов. Контенты находятся в памяти; так что доступ к ним через эти столбцы очень быстр. Из этого представления вы можете узнать почти все о деятельности любых сеансов. Вы можете быстро ответить на такие вопросы, как: сколько именно сеансов находилось в ожидании конкретного события ожидания за последние пять минут, и как долго? Какие объекты сеансов ожидают дольше других, и чего именно? Важно отметить, что эта информация базируется на выборочных данных, которые фиксировались каждую секунду. По этой причине она будет очень близка к тому, чтобы быть точной и достаточной для целей вашего анализа.
ТАБЛИЦА 9-3.
Представление V$ACTIVE_SESSION_HISTORY
|
Имя столбца |
Тип |
Описание |
|
SAMPLE_ID |
NUMBER |
Идентификатор ( ID ) выбранного снэпшота . |
|
SAMPLE_TIME |
TIMESTAMP(3) |
Время выполнения выборки. |
|
SESSION_ID |
NUMBER |
Идентификатор сеанса, отображается на V$SESSION.SID. |
|
SESSION_SERIAL# |
NUMBER |
Порядковый номер сеанса, отображается на V $ SESSION . SERIAL #. |
|
USER_ID |
NUMBER |
Идентификатор пользователя Oracle , отображается на V $ SESSION . USER #. |
|
SQL _ID |
VARCHAR2 (13) |
SQL -идентификатор оператора SQL . |
|
SQL _CHILD_NUMBER |
NUMBER |
Номер дочернего оператора SQL . |
|
SQL _PLAN_HASH_VALUE |
NUMBER |
Значение хэш-функции плана SQL , отображается на V$SQL.PLAN_HASH_VALUE. |
|
SQL _OPCODE |
NUMBER |
Код операции SQL , отображается на V$SESSION.COMMAND. |
|
SERVICE_HASH |
NUMBER |
Хэш сервиса, отображается на V $ ACTIVE _ SERVICES . NAME _ HASH . |
|
SESSION_TYPE |
VARCHAR2 (10) |
FOREGROUND или BACKGROUND . |
|
SESSION_STATE |
VARCHAR2 (7) |
Состояние: WAITING (ОЖИДАНИЕ) или ON CPU (ИСПОЛЬЗУЕТ ЦП). |
|
QC_SESSION_ID |
NUMBER |
ID координатора запроса для параллельного запроса. |
|
QC_INSTANCE_ID |
NUMBER |
ID экземпляра координатора запроса. |
|
EVENT |
VARCHAR2 (64) |
Если SESSION_STATE = WAITING , то событие, которого ожидает сеанс во время осуществления выборки. |
|
EVENT_ID |
NUMBER |
Идентификатор ресурса или события, отображается на V$EVENT_NAME.EVENT_ID. |
|
EVENT# |
NUMBER |
Номер ресурса или события, отображается на V$EVENT_NAME.EVENT#. |
|
SEQ# |
NUMBER |
Порядковый номер, однозначно идентифицирует ожидание, отображается на V$SESSION.SEQ#. |
|
P1 |
NUMBER |
Первый дополнительный параметр ожидания. |
|
P2 |
NUMBER |
Второй дополнительный параметр ожидания. |
|
P3 |
NUMBER |
Третий дополнительный параметр ожидания. |
|
WAIT_TIME |
NUMBER |
Равно 0, если сеанс находится в ожидании, отображается на V $ SESSION . WAIT _ TIME . |
|
TIME_WAITED |
NUMBER |
Если SESSION_STATE = WAITING , время, проведенное сеансом в ожидании этого события ( EVENT ) будет равно 0, пока не закончится ожидание. |
|
CURRENT_OBJ# |
NUMBER |
ID объекта для объекта, если сеанс ожидает некоторых связанных с вводом-выводом событий или некоторых событий ожидания " enqueue ", отображается на V$SESSION.ROW_WAIT_OBJ#. |
|
CURRENT_FILE# |
NUMBER |
Номер файла для файла, если сеанс ожидает некоторых связанных с вводом-выводом событий или некоторых событий ожидания " enqueue ", отображается на V$SESSION.ROW_WAIT_FILE#. |
|
CURRENT_BLOCK# |
NUMBER |
ID блока, если сеанс ожидает некоторых связанных с вводом-выводом событий или некоторых событий ожидания " enqueue ", отображается на V$SESSION.ROW_WAIT_BLOCK#. |
|
PROGRAM |
VARCHAR2 (48) |
Имя программы операционной системы, отображается на V$SESSION.PROGRAM. |
|
MODULE |
VARCHAR2 (48) |
Имя исполняемого модуля, если он выбран, как установлено процедурой DBMS_APPLICATION_INFO.SET_MODULE. |
|
ACTION |
VARCHAR2 (32) |
Имя выполняемого действия, если оно выбрано, как установлено процедурой DBMS_APPLICATION_INFO.SET_ACTION. |
|
CLIENT_ID |
VARCHAR2 (64) |
Идентификатор клиента сеанса; отображается на V $ SESSION . CLIENT _ ID . |
Подобный онлайновый анализ становится возможным, благодаря хранящемуся в оперативной памяти буферу ASH . В следующем примере показывается, как найти, какие сеансы находились в состоянии ожидания за последние пять минут, какими именно были события ожидания, как долго длилось ожидание и сколько раз они в него попадали:
select session_id, event, count(*), sum(time_waited)
from v$active_session_history
where session_state = 'WAITING'
and time_waited > 0
and sample_time >= (sysdate - &HowLongAgo/(24*60))
group by session_id, event;
Enter value for howlongago: 5
old 5: and sample_time >= (sysdate - &HowLongAgo/(24*60))
new 5: and sample_time >= (sysdate - 5/(24*60))
SESSION_ID EVENT COUNT(*) SUM(TIME_WAITED)
---------- ------------------------------ ---------- ------------
126 db file scattered read 276 16958032
131 db file scattered read 270 17728709
131 log file switch completion 1 418071
133 class slave wait 1 5125049
133 db file sequential read 4 151610
138 db file scattered read 5 354926
138 db file sequential read 20 974258
138 log file switch completion 1 418261
138 control file sequential read 1 27706
153 null event 1 45580
153 db file sequential read 26 6900220
153 control file sequential read 4 202271
166 control file parallel write 8 1896634
166 control file sequential read 1 55883
167 log file parallel write 8 359185
167 control file single write 1 30063
168 db file parallel write 9 362689
17 rows selected.
При выполнении запроса к представлению V $ ACTIVE _ SESSION _ HISTORY Oracle должен предварительно запросить все обычные защелки для синтаксического разбора операторов, обращения к буферам и т.д. Если имеется связанная с защелкой для синтаксического разбора проблема, приводящая к зависанию базы данных, можно не получить доступ к информации в представлении V$ACTIVE_SESSION_HISTORY, которая могла бы помочь диагностировать проблему. Однако есть другой способ получить доступ к этой хранящейся в оперативной памяти ASH -информации, и именно его мы обсудим в следующем разделе.
ASHDUMP : формирование в файле трассировки дампа содержимого кольцевого буфера ASH
Содержимое буфера ASH может быть разгружено в файл трассировки, используя событие ASHDUMP . Это содержимое может затем быть загружено в таблицу базы данных. Структура этой таблицы напоминает представление V$ACTIVE_SESSION_HISTORY.
После подключения от имени sysdba можно продуцировать файл трассировки ASHDUMP , используя следующую последовательность команд oradebug :
oradebug setmypid
oradebug unlimit
oradebug dump ashdump 10
oradebug tracefile_name
Можно также использовать команду ALTER SESSION, чтобы произвести немедленный дамп буфера ASH , как показано ниже:
alter session set events "immediate trace name ashdump, level 10';
Файл трассировки будет размещен в каталоге UDUMP. Содержимое файла трассировки может быть загружено в таблицу в другой базе данных. В нескольких первых строках файла трассировки перечисляются все имена столбцов данных. Данные трассировки выводятся как разделенные запятыми значения соответствующих столбцов. Эта информация может использоваться в качестве входа для утилиты SQL * Loader , чтобы загрузить остальную часть содержимого файла трассировки в таблицу для дальнейшего анализа.
В следующем примере показывается содержимое файла трассировки ASHDUMP . Для ясности заголовочная информация, которую обычно можно найти в файлах трассировки, удалена.
<<>>
DBID, INSTANCE_NUMBER, SAMPLE_ID, SAMPLE_TIME, SESSION_ID, SESSION_SERIAL#,
USER_ID, SQL_ID, SQL_CHILD_NUMBER, SQL_PLAN_HASH_VALUE, SERVICE_HASH,
SESSION_TYPE, SQL_OPCODE, QC_SESSION_ID, QC_INSTANCE_ID, CURRENT_OBJ#,
CURRENT_FILE#, CURRENT_BLOCK#, EVENT_ID, SEQ#, P1, P2, P3, WAIT_TIME, TIME_
WAITED, PROGRAM, MODULE, ACTION, CLIENT_ID
<<>>
<<>>
2847681843,1,6033130,"04-13-2004
07:40:58.006572000",41,597,5,"2xbhdwsp8a0zd",0,0,3427055676,1,62,0,0,16314,
1,27521,2652584166,135,1,27709,1,121,0,"sqlplus@hptest (TNS V1-
V3)","SQL*Plus","",""
2847681843,1,6033129,"04-13-2004
07:40:56.976572000",41,597,5,"2xbhdwsp8a0zd",0,0,3427055676,1,62,0,0,16314,
1,27521,2652584166,135,1,27709,1,121,0,"sqlplus@hptest (TNS V1-
V3)","SQL*Plus","",""
. . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . .
2847681843,1,6032838,"04-13-2004
07:35:57.196572000",49,3,0,"6q766vsk5290x",0,0,165959219,2,47,0,0,429496729
5,0,0,866018717,189,300,0,0,3007426,0,"oracle@hptest (MMON)","","",""
2847681843,1,6032837,"04-13-2004
07:35:56.166572000",49,3,0,"6q766vsk5290x",0,0,165959219,2,47,0,0,429496729
5,0,0,866018717,189,300,0,0,3007426,0,"oracle@hptest (MMON)","","",""
<<>>
Хотя подобный процесс формирования дампа буфера ASH , загрузки данных файла трассировки в таблицу и последующей диагностики причин проблемы может показаться немного громоздким, он может иногда оказаться полезным, если приходится иметь дело с "зависшей" системой. Не нужно ждать, пока грянет гром, чтобы приступить к действиям. Вы можете экспериментировать, продуцируя файл трассировки ASHDUMP , используя команду ALTER SESSION и поддерживая сценарии в постоянной готовности к тому, чтобы загрузить данные в собственную таблицу ASH !
В предыдущих разделах мы обсуждали, как Oracle Database 10 g собирает данные о производительности, используя для этого AWR и снэпшоты ASH , как управлять процессом сбора данных и как вы можете просмотреть данные. Но не афишируя этого (так сказать, негласно), Oracle Database 10 g делает с этими данными намного больше, и эти действия и станут темой следующего раздела.
Монитор автоматической диагностики сервера базы данных ( ADDM )
Монитор автоматической диагностики сервера базы данных ( Automatic Database Diagnostic Monitor - ADDM ; произносится "Адам") - это не просто еще одна часть программного обеспечения, которое вы покупаете у корпорации Oracle и устанавливаете на своем сервере базы данных и рабочей станции.
ADDM является целостным механизмом самодиагностики, встроенным в Oracle Database 10 g . Он является неотъемлемой частью ядра. Он автоматически исследует и анализирует данные снэпшотов, собранные в AWR , чтобы превентивно определить любые главные проблемы системы, и во многих случаях он рекомендует корректирующие действия с определенными количественно измеримыми выгодами. Он постоянно ведет мониторинг вашей системы и диагностирует ее.
Цель ADDM состоит в том, чтобы идентифицировать области системы, которые потребляют большую часть времени DB - времени, расходуемого на вызовы базы данных. Он использует статистику модели ожидания и модели времени, чтобы найти, куда утекает время в базе данных. Он погружается до уровня первопричины проблемы, используя набор правил древовидной структуры. Эти правила хорошо себя зарекомендовали, и успешно используются корпорацией Oracle в течение нескольких последних лет в консалтинговой деятельности, связанной с настройкой производительности.
ADDM может обнаружить многие проблемы и сообщить о них, включая следующие типы проблем:
- "узкие места" для ЦП, вызванные как приложениями Oracle , так и другими приложениями
- проблемы с пропускной способностью подсистемы ввода-вывода
- высоко нагруженные SQL -операторы, которые могут потреблять слишком много системных ресурсов
- компиляция и выполнение операторов PL / SQL с высокой нагрузкой, потребляющих слишком много системных ресурсов
- Java -приложения с высокой нагрузкой, потребляющих слишком много системных ресурсов
- выделение недостаточного количества памяти структурам памяти, типа SGA , буферного кэша и журнального буфера
- плохое управление подключениями
- связанные с RAC проблемы с управлением глобальным кэшем и временем ожидания для межузлового соединения (interconnect latency)
- проблемы параллельного доступа к данным, приводящие к ожиданию занятого буфера
- проблемы конфигурирования базы данных, типа задания размеров журнального файла, архивирования или квазиоптимальных установок параметров
В дополнение к составлению отчетов о проблемных областях системы, ADDM также сообщает об областях, которые он считает не проблемными, таким образом, вы не расходуете время на анализ элементов, которые не воздействуют на полную производительность системы. Кроме того, ADDM рекомендует возможные решения часто встречающихся проблем, которые он обнаруживает. И снова, рекомендованные ADDM решения нацеливают вас на достижение меньшего времени DB .
Примечание: Поскольку рекомендации ADDM генерируются с помощью некоторого ряда предопределенных правил, они могут быть, или, возможно, не быть применимыми ко всем ситуациям. Вы можете решить, что некоторые из этих рекомендаций не подходят к вашей среде. Согласно Oracl , e целью ADDM не является настройка времени ответа для индивидуальных пользователей. Используйте методики трассировки, чтобы должным образом настроить время ответа для конкретных пользователей .
Настройка ADDM
Хотя монитор автоматической диагностики экземпляра сервера базы данных активирован по умолчанию, есть несколько параметров, о которых вы должны знать.
Чтобы функциональные возможности ADDM были активированы, параметр инициализации STATISTICS_LEVEL должен быть установлен либо на TYPICAL , либо на ALL . Его значение по умолчанию равно TYPICAL ; установка его на BASIC приводит к отключению ADDM и многих других опций.
Другой параметр не является параметром инициализации. Это специальный связанный с ADDM параметр задачи DBIO _EXPECTED, который ADDM использует для анализа производительности подсистемы ввода-вывода. Значение параметр DBIO _EXPECTED определяет среднее время (в микросекундах), которое требуется для чтения отдельного блока базы данных. Значение по умолчанию для этого параметра - 10 миллисекунд (10 000 микросекунд). Если вы считаете, что время ответа подсистемы ввода-вывода значительно отличается, можно это значение по умолчанию изменить.
Во-первых, нужно узнать среднее время считывания при случайном обращении какого-либо блока базы данных на вашем "железе". Пересчитайте его в микросекунды. Скажем, в данном примере порядка 30 000 микросекунд (несколько медленные диски).
Во-вторых, используйте следующую процедуру для установки значения DBIO _EXPECTED на 30 000:
REM - Run this as SYS user
begin
dbms_advisor.set_default_task_parameter (
"ADDM","DBIO_EXPECTED",30000);
end;
/
PL/SQL procedure successfully completed.
Использование EM для обращения к ADDM
Основным интерфейсом ADDM является Oracle EM Database Control . Ниже приводится ряд шагов, которые позволят увидеть результаты анализа ADDM .
На Рис. 9-4 и 9-5 показаны верхняя и нижняя части домашней страницы Database . На домашней странице Database показана информация, имеющая отношение к экземпляру базы данных, использованию центрального процессора хоста, активному сеансу, использованию дискового пространства, итогам диагностики, предупреждениям и анализу производительности. Кроме того, на ней содержатся ссылки для обращения к другим компонентам, которые выполняют несколько иных задач.
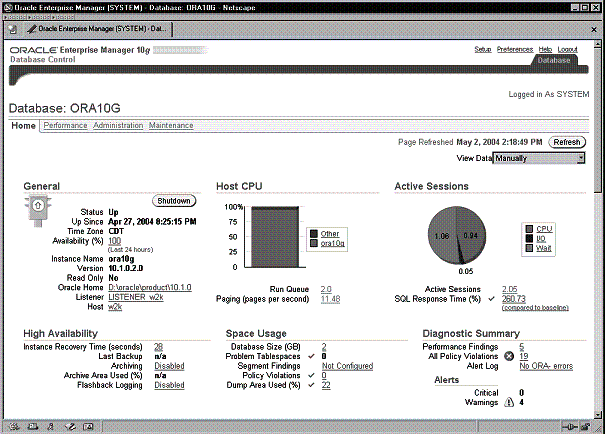
Рис. 9-4. Верхняя часть домашней страницы базы данных
На Рис. 9-4 количество полученных данных о производительности ADDM в течение периода последнего анализа ADDM показано в правом нижнем углу страницы под заголовком Diagnostic Summary .

Рис. 9-5. Нижняя часть домашней страницы базы данных
На рис. 9-5 полученные данные о производительности перечислены под заголовком Performance Analysis . Для каждой такой обнаруженной строки ADDM также предлагает несколько рекомендаций, которые показываются справа.
Первая строка утверждает, что в системе имела место конкуренция за центральный процессор. Кликнув по ссылке, связанной с этой строкой, можно опуститься на детальный уровень, как показано на рис. 9-6.
В данном случае, связанным с конкуренцией за центральный процессор, ADDM рекомендует рассмотреть вопрос о добавлении к серверу какого-то числа центральных процессоров или о добавлении дополнительных экземпляров базы данных на других серверах, чтобы помочь системе справиться с нагрузкой. Кроме того, ADDM идентифицирует два SQL -оператора, которые, возможно, нуждаются в исследовании.

Рис. 9-6. Детали и рекомендации находок для производительности
Вернитесь назад на домашнюю страницу Database , показанную на Рис. 9-5. Если теперь кликнуть по ссылке Advisor Central под заголовком Related Links в нижней части страницы, то попадаете на домашнюю страницу Advisor Central , показанную на Рис. 9-7.
Домашняя страница Advisor Central предлагает разнообразие консультаций почти по всем компонентам базы данных - от настройки SQL до управления пространством отката . На ней можно без труда увидеть детали автоматически управляемых рекомендующих (консультационных) задач, выполненных ADDM во время получения последнего снэпшота AWR . На этой странице показывается только последняя задача Advisor .

Рис. 9-7. Домашняя страница Advisor Central
Можно просмотреть отчеты по предыдущим задачам, используя для этого ниспадающее меню Advisor Runs . Можно выбрать либо последний прогон, либо последние 24 часа, либо последние 7 дней. Если кликнуть по имени консультант-задачи, вы попадете на страницу монитора автоматической диагностики экземпляра сервера базы данных ( ADDM ), как показано на рис. 9-8.

Рис. 9-8. Монитор автоматической диагностики экземпляра сервера базы данных
На этой странице показывается деятельность базы данных за несколько последних часов и дополнительная информация для задачи Advisor . Чтобы просмотреть отчет ADDM для этой конкретной задачи Advisor , кликните по кнопке View Report . Будет отображен детализированный отчет ADDM для выбранной задачи, показанный на рис. 9-9.

Рис. 9-9. Просмотр отчета ADDM
Вся эта информация была без труда зафиксирована и проанализирована Oracle Database 10 g . Она оказалась легко доступной, и, что важнее всего, ADDM проанализировал системную нагрузку и предложил рекомендации прежде, чем полученные им данные стали реальной проблемой.
Даже если вы не заглянете в полученные ADDM данные немедленно, можно обратиться к ним позже, потому что они сохранены в базе данных. Данные ADDM (и все данные инфраструктуры советника ADDM ) по умолчанию будут сохранены в течение 30 дней.
Однако администратор базы данных должен много раз выполнять диагностику проблемы в реальном времени. Сколько раз вы получали от пользователей звонки, где они заявляли о том, что база данных "тормозит"? Находясь на странице Performance EM Database Control , можно теперь легко узнать, что происходит в системе. На домашней странице (рис. 9-4) кликните по ссылке Performance , чтобы получить доступ к домашней странице Performance , как показано на рис. 9-10.
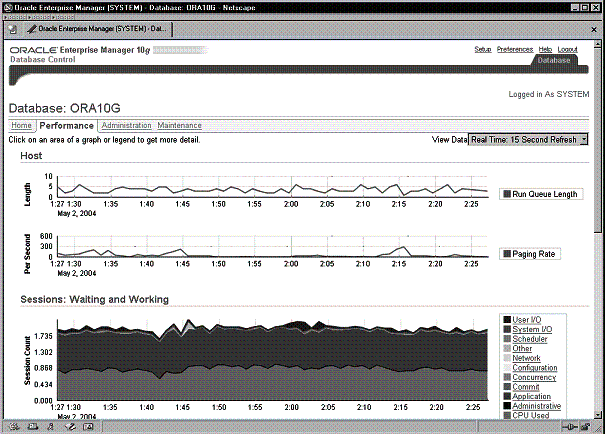
Рис. 9-10. Домашняя страница Performance
На странице Performance можно видеть, как используется центральный процессор и память, чтобы удостовериться, что они не являются критическими ресурсами. Можно оценить состояние базы данных с помощью диаграммы Sessions : Waiting and Working , которая показывает, как используется сеансами центральный процессор и есть ли какие-нибудь сеансы, ожидающие ресурсов.
Эта диаграмма предлагает довольно мало информации. По оси Y на ней указано среднее число активных сеансов в отношениях Wait class (класс ожидания) и CPU . По оси X указано время. По умолчанию данные обновляются каждые 15 секунд. Для указания различных классов ожидания в диаграмме используются различные цвета. Чем ярче блок цвета, тем серьезнее проблема. Если кликнуть по размещенной справа шкале цветов, которая также разбита по классам ожидания, вы переместитесь на страницу более низкого уровня, на которой показаны активные сеансы, ожидающие этого класса ожидания. В примере на рис. 9-10 самым бросающимся в глаза цветовым блоком является класс ожидания Application . Если кликнуть по легенде Application , вы перейдете к странице Active Sessions Waiting : Application , показанной на Рис. 9-11.
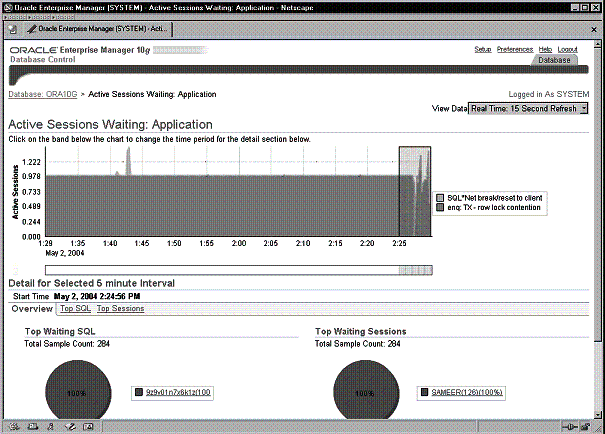
Рис. 9-11. Класс ожидания Active Sessions Waiting: Application
Вы видите, что событием ожидания является enq : TX row lock contention . Таким образом, в этом конкретном приложении имеется проблема блокировки.
Можно перейти на более низкий уровень, кликнув по ссылке под заголовком Top Waiting SQL , чтобы добраться до деталей SQL -оператора, показанных на Рис. 9-12. Там вы найдете ответ. Все дело в SQL -операторе, ожидающем блокировку, которая должна быть снята.
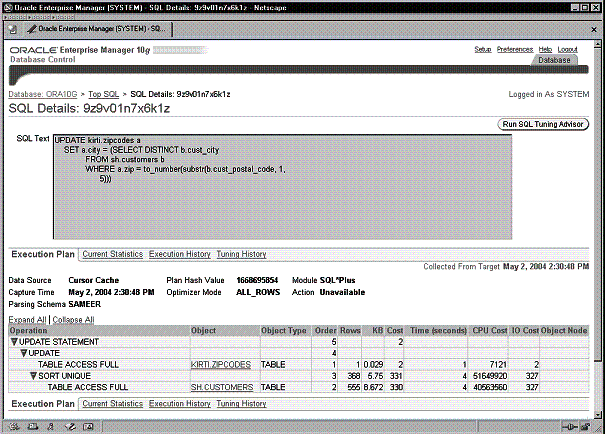
Рис. 9-12. Детали SQL , иллюстрирующие текст и план выполнения оператора SQL
Можно перейти на еще более низкий уровень, кликнув по ссылке под заголовком Top Waiting Sessions , чтобы найти детали для ожидающих сеансов, показанные на Рис. 9-13. Сеанс ожидал события ожидания enq : TX row lock contention .

Рис. 9-13. Детали сеанса, показывающие общую информацию
Если кликнуть по ссылке Wait Events на странице Session Details , вы сможете увидеть то произошедшее ранее событие ожидания, с которым сталкивается сеанс. В показанном на Рис. 9-14 примере сеанс в течение достаточно долгого времени ожидал события: enq : TX row lock contention .
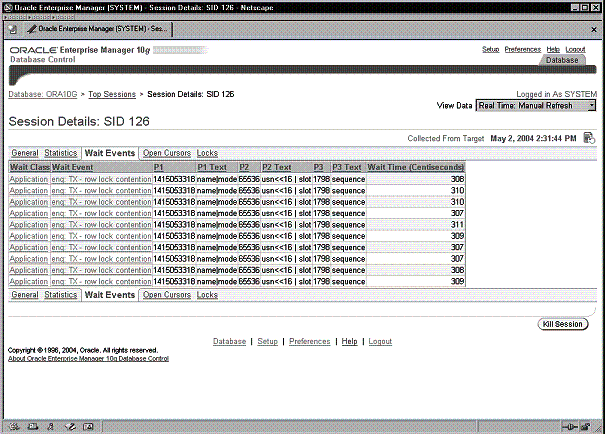
Рис. 9-14. Детали сеанса, показывающие ожидающие сеансы
Выполнение отчета ADDM вручную
Предпочтительным и самым простым способом выполнения отчета ADDM является его выполнение из Oracle EM . Однако для генерации отчетов о диагнозе ADDM можно также использовать поставляемые Oracle скрипты и пакеты процедур. Чтобы продуцировать такой отчетнужно знать любые два AWR -снэпшота. Эти снэпшоты должны присутствовать в AWR , и между ними не должно быть никаких рестартов базы данных.
В каталоге $ORACLE_HOME/rdbms/ admin есть два сценария, которые могут генерировать отчет о диагностике ADDM - addmrpt . sql и addmrpti . sql . Первый из вышеназванных сценариев генерирует отчет для локального экземпляра базы данных, в то время как второй может генерировать отчет для других экземпляров (например, в среде RAC ). Кроме того, в поставляемом Oracle пакете DBMS_ADVISOR имеются процедуры (API) для генерации отчета о диагностике ADDM .
Мы кратко обсудим, как использовать эти методы для генерации отчета о диагностике ADDM .
Для выполнения сценариев или для использования сценариев API нужно иметь привилегию ADVISOR .
При выполнении addmrpt . sql вам будет предложено предоставить идентификаторы начального и конечного снэпшотов из списка доступных снэпшотов, а также указать название выбранного отчета. После этого Oracle сгенерирует отчет о диагностике ADDM для указанного диапазона идентификаторов снэпшотов. Отчет может также быть выполнен и не в интерактивном режиме. В сценарии имеются команды, показывающие, как это можно сделать.
Для генерации отчета о диагностике ADDM с непосредственным использованием пакета DBMS_ADVISOR требуется немного больший объем действий по настройке, а именно:
1. Создать консультант-задание типа ADDM , используя процедуру CREATE_TASK.
2. Задать параметры START_SNAPSHOT и END_SNAPSHOT для выполнения только что созданного задания, используя процедуру SET_TASK_PARAMETER. Для этого диапазона снэпшотов будет сгенерирован отчет о диагностике ADDM .
3. Выполнить задание, используя для генерации отчета о диагностике процедуру EXECUTE_TASK.
4. Просмотреть сгенерированный отчет о диагностике ADDM , используя процедуру GET_TASK_REPORT.
Примечание : в главе 6 документа Oracle Database Performance Guide 10 g Release 1 ("Руководство по производительности Oracle Database 10g Release 1") в разделе "Выполнение ADDM с использованием API DBMS_ADVISOR" имеется превосходный пример, демонстрирующий использование пакета ADMS_ADVISOR для генерации и просмотра отчета о диагностике ADDM .
Представления ADDM
Предпочтительным интерфейсом для просмотра всей связанной с ADDM информации является Oracle EM . Однако для просмотра этой информации могут использоваться представления DBMS_ADVISOR. В Таблице 9-4 перечислены некоторые из этих представлений и приведено их описание.
ТАБЛИЦА 9-4.
Представления ADDM (Неполный список)
|
DBA_ADVISOR_FINDINGS |
Показывает все полученные данные, обнаруженные ADDM . |
|
DBA_ADVISOR_LOG |
Показывает текущее состояние всех задач в базе данных, например, прогресс заданий, сообщения об ошибках и время выполнения. Выводится по одной строке для каждого задания. |
|
DBA_ADVISOR_RATIONALE |
Показывает объяснения для всех рекомендаций. |
|
DBA_ADVISOR_RECOMMENDATIONS |
Показывает результаты всех законченных диагностических заданий с рекомендациями для обнаруженных проблем. Рекомендации ранжированы в столбце RANK. В столбце BENEFIT показаны ожидаемые после выполнения рекомендованных действий преимущества. |
|
DBA_ADVISOR_TASKS |
Показывает информацию обо всех существующих в базе данных задачах. |
Вместо резюме
Благодаря наличию большого количества таких опций, как AWR , ASH и ADDM , а также основанного на интернет-технологиях Oracle Enterprise Manager , в Oracle Database 10 g удалось революционизировать мониторинг производительности базы данных.
Теперь в Oracle Database 10 g полностью автоматизированы каждодневные задачи мониторинга базы данных и диагностики медленно выполняющихся заданий. Сегодня, когда все ретроспективные данные о производительности постоянно сохраняются в автоматически управляемом репозитории рабочей нагрузки и имеется интеллектуальный механизм для анализа этих данных, Oracle Database 10 g знает о поведении вашей базы данных больше, чем вы!
С такими мощными инструментальными средствами успешный мониторинг производительности перестает быть привилегией элитной группы консультантов и экспертов.