Введение
Доводы в пользу структурирования неструктурированных данных
В мире существует большой интерес к колоссальным массивам данных, генерируемых человечеством в неуклонно растущих объемах (будь то непосредственно в компаниях и организациях, в Интернете или в социальных сетях). Эти данные можно использовать разными способами для получения необходимых знаний, которые могут помочь, например, укрепить здоровье людей, улучшить демократию или усовершенствовать методы ведения бизнеса. Подобные знания, основанные на данных, являются традиционной сферой приложения средств аналитики (Analytics) или бизнес-анализа (Business Intelligence, BI), использующих, как правило, структурированные данные - даты, результаты финансовых расчетов, количественные показатели, названия компаний. Большинство данных, однако, представлены в неструктурированной форме - в виде текстов, изображений, фильмов. Доля таких неструктурированных данных составляет от 70% для корпоративных данных предприятий до почти 100% в социальных медиа.
Любое аналитическое приложение, которое использует только структурированные данные, фактически игнорирует около четырех пятых имеющейся информации. Насущная необходимость извлечения структурированной информации из неструктурированных источников появляется именно в эпоху Больших данных. Настоящее учебное пособие посвящено работе с текстовыми данными; в нем показано, как извлекать из этих данных терминологическую информацию, применимую на практике в сфере бизнеса.
IBM Watson Content Analytics
Решение IBM Content Analytics with Enterprise Search (ICAwES) представляет собой поисково-аналитическую платформу, использующую анализ обогащенного (форматированного) текста для получения новых применимых на практике знаний из разных источников и типов текстового контента, включая корпоративный контент, web-контент (в том числе контент социальных медиа), сообщения электронной почты и базы данных.
На практике IBM Watson Content Analytics (WCA) может применяться следующими двумя основными способами:
- Непосредственное использование аналитических обзоров WCA для быстрого извлечения знаний из больших наборов контента. Такие обзоры часто оперируют т.н. фасетами. Фасеты - это важные аспекты документов, полученные либо из метаданных, которые уже структурированы (например, дата, автор, теги), либо из понятий, извлеченных из текстового контента.
- Извлечение информационных объектов или понятий для использования в аналитическом обзоре или в других итоговых решениях. Типичными примерами являются: составление отчетов с результатами медицинских лабораторных анализов для заполнения историй болезни пациентов; извлечение именованных объектов-сущностей и связей для применения в исследовательском программном обеспечении; определение типологии настроений, выражаемых в социальных сетях, для более точного статистического анализа поведения потребителей.
WCA использует технологию обработки текстов на естественном языке (Natural Language Processing, NLP) для извлечения информации из неструктурированных данных (или текстов). Эта информация может извлекаться в следующих формах:
- Элементарные понятия или информационные объекты, такие как личности, места, компании, детали авиационной техники, производственные операции
- Сочетания вышеуказанной информации, отражающие, как правило, определенный уровень взаимосвязей между понятиями. Примеры таких комбинаций: человек и его работа, компания и ее сфера деятельности, операция технического обслуживания определенного узла самолета, анамнез пациента с описанием семейных связей и проблем со здоровьем.
WCA обрабатывает исходный текст из источников контента посредством конвейера операций, совместимых со стандартом UIMA. UIMA (Unstructured Information Management Architecture) - это программная архитектура, ориентированная на разработку и развертывание ресурсов для анализа неструктурированной информации. Конвейеры WCA включают в себя стадии обработки - такие как определение исходного языка, лексический анализ, извлечение объектов информации - или реализуют извлечение специальных понятий. Извлечение специальных понятий осуществляется аннотаторами, определяющими фрагменты информации, представленные в виде сегментов текста. Аннотаторы можно создавать с помощью IBM Content Analytics Studio (WCA Studio) - графической среды на базе Eclipse, которая облегчает проектирование и тестирование аннотаторов на основе словарей и правил.
Основная цель настоящего пособия - показать, как оптимизировать создание словарей предметной области. Создание таких словарей может показаться простой задачей, если имеется терминология данной предметной области. Проблема в том, что авторы контента не всегда следуют канонической терминологии. Отсюда возникает необходимость наличия корпуса текстов (т.е. подобранного и обработанного по определенным правилам собрания текстов), репрезентативного для исследуемой предметной области. В настоящем пособии используется корпус, состоящий из текстов заявлений, жалоб и претензий, поступивших от водителей автомобилей. Автор пособия описывает свое исследование этого корпуса текстов, направленное на выявление терминологии соответствующей предметной области с помощью лингвистических и аналитических функций WCA. В пособии показано, как эти операции можно оптимизировать до полуавтоматического процесса создания словарей, которые затем можно использовать в WCA Studio для выполнения задач аннотирования. В заключительном разделе пособия описано одно из возможных применений словарей, а именно тегирование рекламационных документов информацией об узлах и деталях, которые могут иметь отношение к проблеме.
Предполагается, что читатель обладает базовыми знаниями об IBM Watson Content Analytics. Для получения более подробной информации см. ниже раздел Ресурсы.
Создание источника корпуса текстов
Пример источника
Под эгидой Министерства транспорта США (United States Department of Transportation) функционирует Национальное управление по безопасности движения автотранспорта (National Highway Traffic Safety Administration, NHTSA). Эта организация через свой веб-сайт, по электронной почте и по телефону принимает от граждан заявления, рекламации, жалобы и претензии, связанные с безопасностью эксплуатации транспортных средств. Информация из этих документов, имеющая отношение к безопасности на автотранспорте, находится в свободном доступе.
На веб-сайте NHTSA (https://www-odi.nhtsa.dot.gov/VehicleComplaint/index.xhtml) пользователи могут указать информацию о транспортном средстве (производитель - модель - год выпуска) и обстоятельствах происшествия. Часть информационного блока об обстоятельствах происшествия содержит поля ввода, обязательные для заполнения - дата происшествия, был ли пожар/авария/вред здоровью, пробег, скорость, поврежденные детали/узлы (выбор из списка 17 основных автомобильных деталей и узлов) - а также поле для ввода текста в свободной форме под заголовком "Tell us what happened" ("Расскажите нам, что произошло"). В результате формируется сводная информация о происшествии, которая представляет собой типичную комбинацию структурированных и неструктурированных данных:
Рисунок 1. Форма NHTSA для составления заявления, связанного с безопасностью эксплуатации автотранспорта
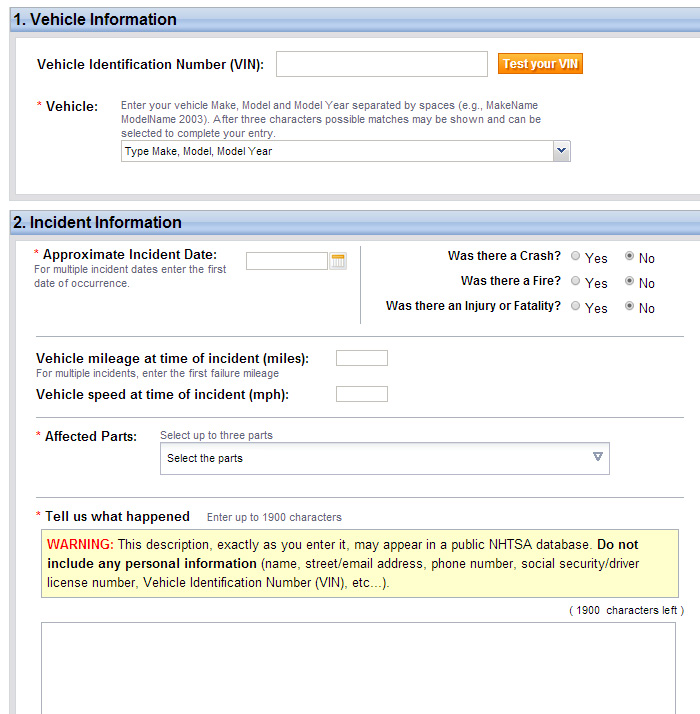
Сводные данные открыты для свободного доступа на веб-сайте NHTSA. Этот контент является анонимным, поскольку не содержит персональных идентификационных данных и государственных регистрационных номеров транспортных средств. Изучая данные из заявлений, автор обнаружил, что поле ввода "component" ("деталь/узел") заполнено более широким спектром значений, чем это допускается онлайновой формой, предлагающей список лишь из 17 основных деталей/узлов автомобиля. Это многообразие значений свидетельствует о том, что данные NHTSA пополняются дополнительной информацией после заполнения формы - хотя эта особенность никак не документирована на сайте организации.
Загрузка данных NHTSA в WCA
Данные NHTSA можно получить на странице FLAT FILE COPIES OF NHTSA/ODI DATABASES (текстовые копии баз данных NHTSA/ODI) официального веб-сайта. В разделе справочной информации по продукту WCA подробно описано, как импортировать файлы *.csv в коллекцию документов, поэтому в настоящем пособии детальное описание этого процесса не приводится.
Автор загрузил свыше 230000 записей, связанных с заявлениями пользователей, охватывающих период с 2005 по 2011 год.
Записи были импортированы в собрание (collection) документов Watson Content Analytics. В настройках для этого собрания документов было указано, что необходимо создать поля индекса и фасеты для всех полей структурированных данных, таких как дата происшествия, производитель и модель автомобиля, наличие факта аварии/пожара/вреда здоровью, а также детали/узлы автомобиля, которые упоминаются в заявлении.
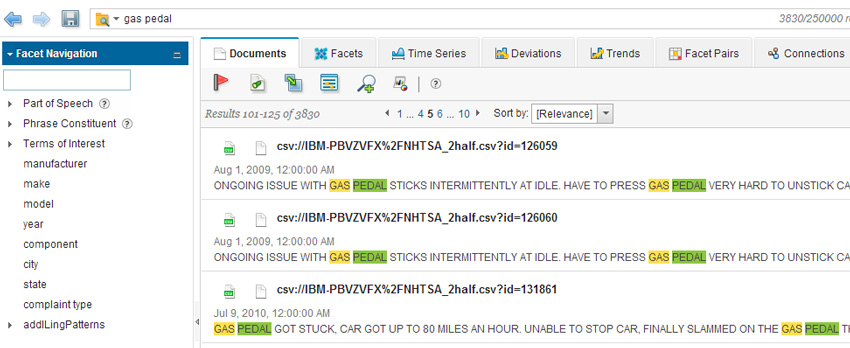
На рисунке 2 показано экранное представление вкладки Documents (Документы) в Content Analytics Miner, аналитическом приложении, которое поставляется вместе с WCA. Список фасетов располагается в левой части окна приложения, а сводки различных записей - в правой части окна. Запрашиваемые термины, введенные либо выбранные в списке фасетов, выделены в этих сводках цветом:
Рисунок 2. Окно вкладки документов в приложении Content Analytics Miner
Использование лингвистических фасетов для определения терминологии предметной области
Теперь давайте посмотрим, как лингвистические фасеты, предоставляемые IBM Watson Content Analytics, могут помочь в составлении словаря предметной области
Практическое применение лингвистических фасетов WCA
WCA предоставляет готовые к использованию фасеты для информации о частях речи по отдельным словам (имя существительное, глагол или прилагательное) и по словосочетаниям/фразам (именная группа или последовательность имен существительных). Вкладка Facets (Фасеты) в приложении Content Analytics Miner отображает значения, которые может принимать конкретный фасет в наборе документов, выбранных по текущему запросу. Эти значения можно отсортировать по частоте - т.е. по количеству документов, содержащих указанное значение фасета - или по показателю корреляции. Показатель корреляции определяет, насколько релевантно значение фасета для набора документов, выбранных по текущему запросу, в сравнении с другими документами в собрании (collection).
Для того чтобы лучше понять разницу между частотой и корреляцией, посмотрите на отсортированный по частоте список имен существительных, найденных во всем собрании документов. Выберите вкладку Facets и фасет Part of speech (Часть речи) > Noun (Имя существительное) > General Noun (Общее имя существительное) в структурном дереве Facet Navigation. (Структурный элемент General Noun представляет слова, которые определены как имена существительные в словаре общей лексики, тогда как раздел Others (Другое) представляет неизвестные слова.)
Рисунок 3. Значения для лингвистического фасета "noun" ("имя существительное"), попавшие в верхнюю часть списка
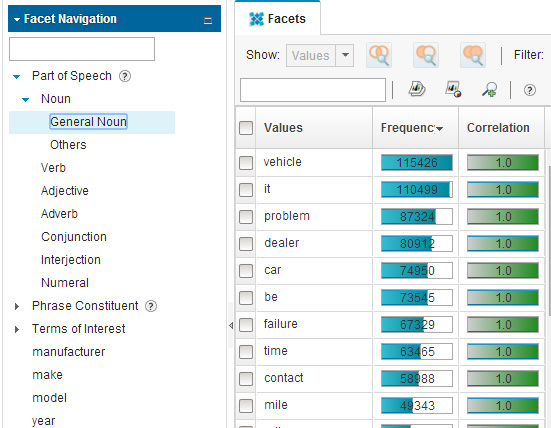
На рисунке 3 показаны имена существительные, наиболее часто встречающиеся во всем собрании документов. Как и следовало ожидать, пользователи, составившие эти документы, говорят о своей проблеме ( problem ) с транспортным средством ( vehicle ), дилером ( dealer ) или автомобилем ( car ).
Примечание: Поскольку данные NHTSA указаны заглавными буквами (в верхнем регистре), они были ошибочно определены в приводимом списке значений фасета как имена существительные в определенных контекстах.
Теперь введите поисковый запрос "storm" ("буря"). По этому запросу в собрании документов находится 634 документа. Вы можете видеть, как динамически меняется список выбранных имен существительных:
Рисунок 4. Наиболее частые имена существительные в документах, извлекаемых по запросу "storm" ("буря")
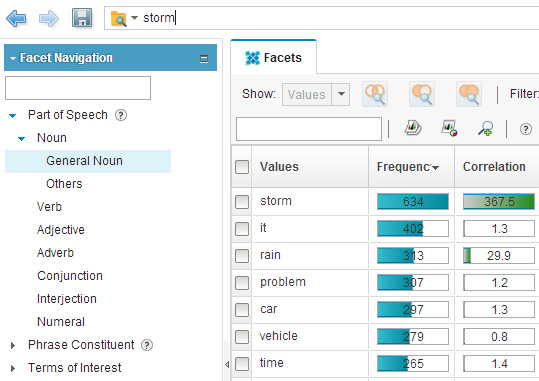
Помимо собственно слов "storm" ("буря") и "rain" ("дождь"), здесь по-прежнему появляются часто встречающиеся слова, не связанные с понятием "буря", такие как "problem" ("проблема"), "car" ("автомобиль"), "vehicle" ("транспортное средство", "time" ("время"). Они часто встречаются во всем корпусе текстов и поэтому также появляются и в документах, связанных со словом "буря".
Сортировка результатов по показателю корреляции дает иную картину:
Рисунок 5. Верхняя часть списка имен существительных по запросу "storm" ("буря"), отсортированного по показателю корреляции
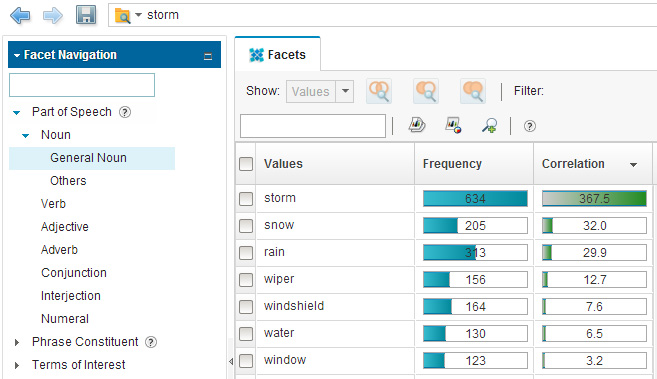
Здесь становится интуитивно понятна близость между бурей и снегом ( snow ), дождем ( rain ) и водой ( water ), а также вы узнаете, что буря может иметь некоторое отношение к стеклоочистителю ( wiper ), ветровому стеклу ( windshield ) или окну ( window ). Вы видите семейства слов, семантически связанных между собой. Очевидно, что корреляция является лучшим признаком, чем частота появления в документах, для указания семантической схожести между значениями фасетов имен существительных и условиями запроса.
Теперь посмотрим на структурный элемент Noun Phrase (Словосочетание имен существительных) и его подчиненный элемент Noun Sequence (Последовательность имен существительных), отсортированные по показателю корреляции. Выберите эти лингвистические фасеты в разделе Phrase Constituent (Составная фраза) структурного дерева фасетов:
Рисунок 6. Последовательности имен существительных по запросу "storm" ("буря"), попавшие в верхнюю часть списка
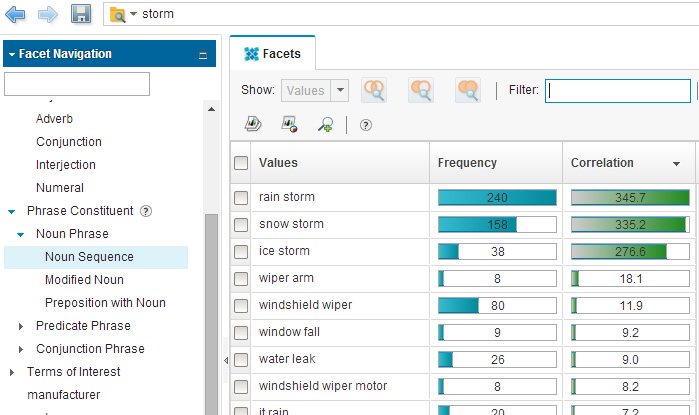
Список, показанный на рисунке 6, имеет смысл в контексте слова "storm" ("шторм"). Последовательности имен существительных в верхней части списка состоят в основном из слов, которые появляются в верхней части списка имен существительных, что представляется логичным.
Еще одним интересным фразеологическим фасетом, представленным в структурном дереве фасетов, является Modified noun (Модифицированное имя существительное) - как правило, сочетание прилагательного с существительным:
Рисунок 7. Верхняя часть списка модифицированных имен существительных по запросу "storm" ("буря")
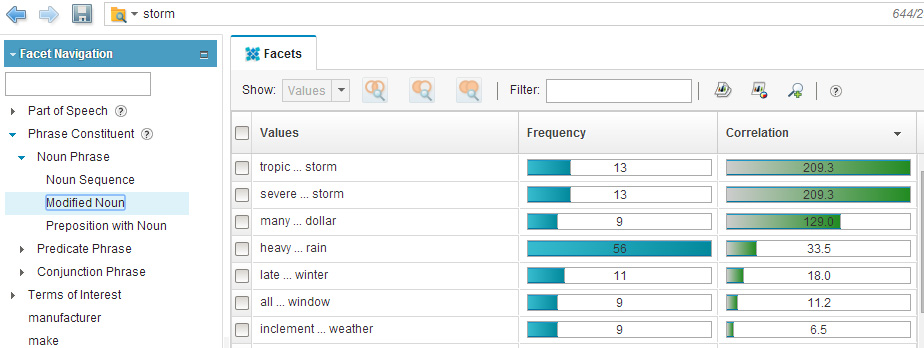
И вновь вы находите словосочетания, содержащие слово "storm" ("буря") или связанные с неблагоприятными погодными условиями, такие как "heavy ... rain" ("сильный ... дождь"), "late ... winter" ("поздняя ... зима") или "inclement ... weather" ("ненастная ... погода").
Поиск слов или словосочетаний, связанных с определенным понятием
Если у вас уже есть ряд фасетов, которые определяют общие понятия в контексте вашего бизнеса, вы можете их использовать вместо простых поисковых запросов. Рассмотрим, например, конкретные компоненты (детали/узлы) автомобиля и связанную с ними терминологию. Для этого выберите фасет Component (Компонент) в "проводнике" фасетов, перейдите в окно вкладки Facets (Фасеты) и выберите одно или несколько значений.
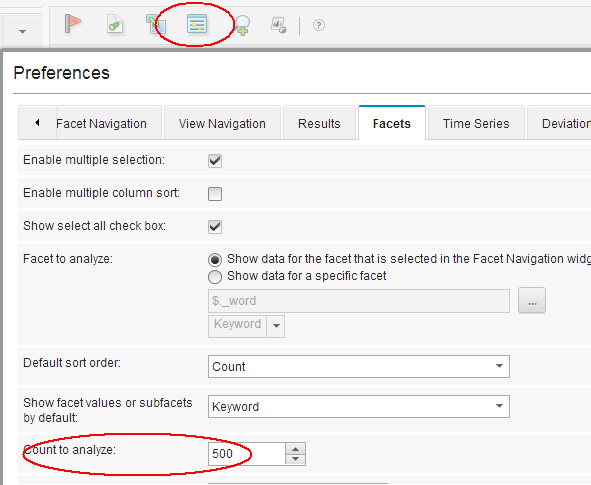
Перед этим следует максимально увеличить количество отображаемых в списке значений фасета (100 по умолчанию), поскольку значений может оказаться гораздо больше, чем установлено в WCA по умолчанию. Для этого щелкните по пиктограмме Preferences (Параметры), откройте вкладку Facets (Фасеты) и в поле Count to analyze (Кол-во для анализа) укажите 500:
Рисунок 8. Установка количество отображаемых значений фасета
Теперь посмотрим на возможные значения для фасета Component (Компонент) в собрании документов. Отфильтруйте эти значения по определенному компоненту, для чего введите в поле Filter (Фильтр), например, "wheel" ("колесо"), и затем выберите значение "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ") и добавьте его в текущий запрос, как показано на рисунке 9:
Рисунок 9. Выбор документов, связанных с Компонентом "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ")
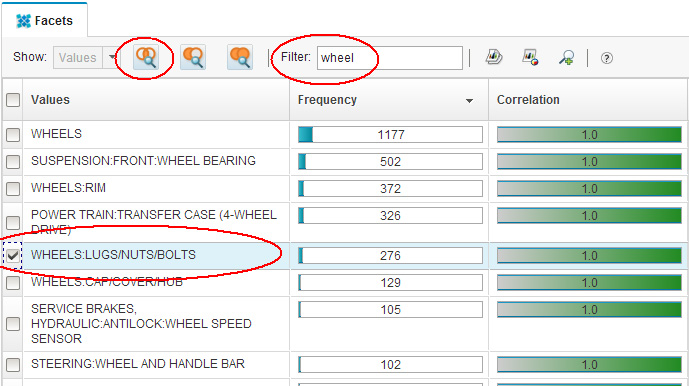
Эта операция поиска дает 276 найденных документов, которые помечены NHTSA как связанные с компонентом WHEELS:LUGS/NUTS/BOLTS ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ"). Хотите знать, как именно пользователи ссылаются на эти узлы/детали в своих заявлениях? Вернитесь в окно лингвистических фасетов и проверьте, какие имена существительные наиболее тесно коррелируют с набором документов, отображенных в окне Documents (Документы) после вашего ввода/выбора в структурном дереве Facet Navigation:
Рисунок 10. Верхняя часть списка имен существительных, связанных с компонентом "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ")
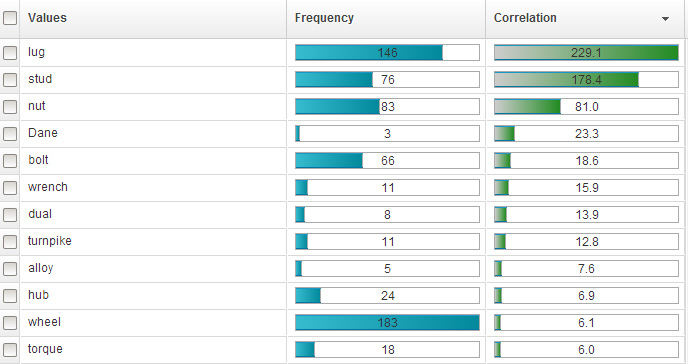
Здесь вы найдете слова из названия фасета ( lug , nut , bolt , wheel - грунтозацеп шины, гайка, болт, колесо), а также другие тематически связанные слова, такие как слово "stud", которое описывает стержневые детали с резьбой (шпильки), на которые навинчиваются гайки крепления колеса, или слово "hub", обозначающее ступицу колеса wheel hub , в отверстия которой вкручиваются болты крепления колеса. Подобные слова отражают тот факт, что пользователи, описывая свою проблему в свободной форме, могут использовать различную терминологию. Иными словами, пользователи не обязательно применяют стандартную терминологию и могут предпочесть связанные термины, синонимы или словосочетания (фразы) - как, например, в этом фрагменте заявления на рекламацию:
"[...] ПОСТАВИЛ НЕОРИГИНАЛЬНЫЕ КОЛЕСНЫЕ ДИСКИ И ШИНЫ, КОТОРЫЕ ЛУЧШЕ СМОТРЕЛИСЬ. ГОД СПУСТЯ ПРИШЛОСЬ ЗАМЕНИТЬ ШПИЛЬКУ КРЕПЛЕНИЯ КОЛЕСА ("STUD"). ДИЛЕР ВЫСТАВИЛ МНЕ СЧЕТ, УКАЗАВ НА НЕГАРАНТИЙНЫЙ СЛУЧАЙ ИЗ-ЗА ЗАМЕНЫ ДИСКОВ И ШИН. ВЧЕРА ТАКАЯ ЖЕ ПОЛОМКА ПРОИЗОШЛА СНОВА. ТОЛЬКО В ЭТОТ РАЗ НУЖНО МЕНЯТЬ УЖЕ ДВЕ ШПИЛЬКИ".
Допустим, вы хотите автоматически классифицировать рекламационные документы путем сопоставления использованных в них слов с ключевыми словами, содержащимися в названиях категорий. В приведенном примере вы не видите слов "lug", "nut" или "bolt" ("грунтозацеп шины", "гайка" или "болт"), которые позволили бы вам выбрать категорию WHEELS:LUGS/NUTS/BOLTS ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ"). Вместо этого вам нужно добавить такие ключевые слова, как "stud" ("шпилька") или "hub" ("ступица") в список ключевых слов, которые характеризуют эту категорию.
В процессе исследования понятия Component (Компонент) с помощью лингвистических фасетов WCA можно с легкостью найти и другие наглядные примеры:
- Набор слов, связанных с компонентом "COMMUNICATIONS:HORN ASSEMBLY" ("СРЕДСТВА ОПОВЕЩЕНИЯ:БЛОК ЗВУКОВОГО СИГНАЛА"), включает глагол "honk" ("сигналить"), интуитивно очевидный (близкий по смыслу).
- Результаты поиска по компоненту "STRUCTURE:BODY:DOOR" ("КОНСТРУКЦИЯ:КУЗОВ:ДВЕРЬ") включают имена существительные, такие как "slide" ("подвижный узел"), "door" ("дверь"), "handle" ("ручка"), "opening" ("открывание"), и глаголы, такие как "slide" ("раздвинуть"), "close" ("закрыть"), "open" ("открыть"), "latch" ("запереть"), "snap" ("защелкнуть"). Опять-таки эти слова интуитивно относятся к лексическому полю слова "дверь" - либо в качестве частей двери (например, "ручка"), либо в качестве функций (например, "закрыть").
Теперь вы знаете, как WCA может помочь вам составить словарь, который ассоциируется - согласно терминологии пользователей, отраженной в их заявлениях - с конкретной предметной областью. Позже, в процессе изучения настоящего пособия, мы используем это свойство при тегировании (сопровождении тегами) категорий данных NHTSA, но перед этим давайте рассмотрим другие аспекты выявления терминологии с помощью WCA.
Известные слова, которые явились неожиданностью, и неизвестные слова, которые заслуживают того, чтобы о них знали
Список слов на рис. 10 также содержит слова, которые не имеют прямого отношения к выбранной вами категории компонента. Так, одно косвенно связанное слово - "turnpike" ("скоростная автострада"/"платная автодорога") - является распространенным автодорожным термином в Североамериканском регионе, однако наличие в списке другого слова - "Dane" ("Датчанин") - удивляет. Что здесь делает слово "Датчанин"? Watson Content Analytics версии 3.5, в числе многих новых функций, предлагает возможность, позволяющую с легкостью менять режимы и опции аналитического приложения. В частности, режим расширенного анализа (Advanced analytics) позволяет просматривать сводки релевантных документов совместно с другим окном обзора и менять выбор и подсветку ключевых слов в документах, когда что-то выбирается в этом другом окне обзора. Например, если вы щелкните по строке "Dane" ("Датчанин") в окне с активной вкладкой Facets (Фасеты), то в окне сводки документов будут показаны релевантные документы с выделенным словом "Dane". И вы сразу же поймете, что слово "Dane" является частью фирменного наименования трейлера (тягача с прицепом):
Рисунок 11. Поиск слова "Dane" ("Датчанин") в документах
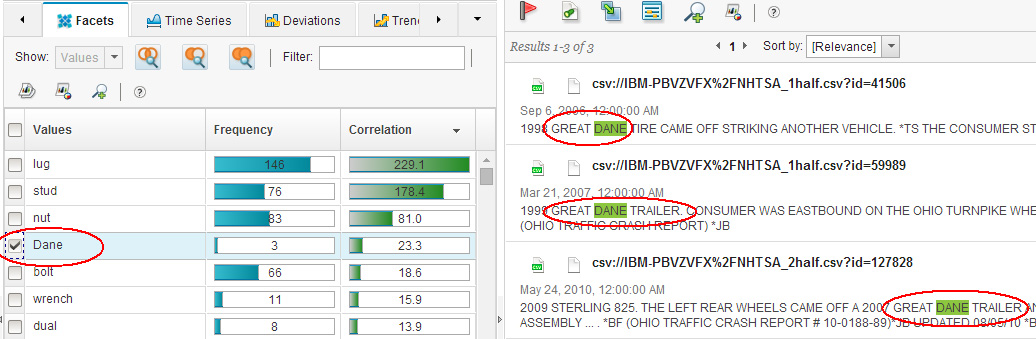
Эта возможность особенно полезна, когда вам нужно сравнить свои терминологические знания, основанные на интуиции, с терминологией реальных текстов.
Наряду с установлением терминов предметной области ("rain storm" - "ливень с грозой"), связанных терминов ("windshield wiper" - "стеклоочиститель лобового стекла"; "hub" - "ступица") и косвенно связанных терминов или "лингвистического шума" ("turnpike" - "скоростная автострада"/"платная автодорога", "Dane" - "датчанин"), лингвистические фасеты WCA также могут помочь в установлении других терминов, представляющих интерес. До сих пор вы использовали раздел General Noun (Общее имя существительное) в структурном дереве фасета Part of speech (Часть речи) > Noun (Имя существительное). Теперь посмотрите на раздел Noun (Имя существительное) > Others (Другое), содержащий лексемы, которые не встречаются в словарях WCA. Вы по-прежнему находитесь в категории "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ"):
Рисунок 12. Исследование внесловарных слов
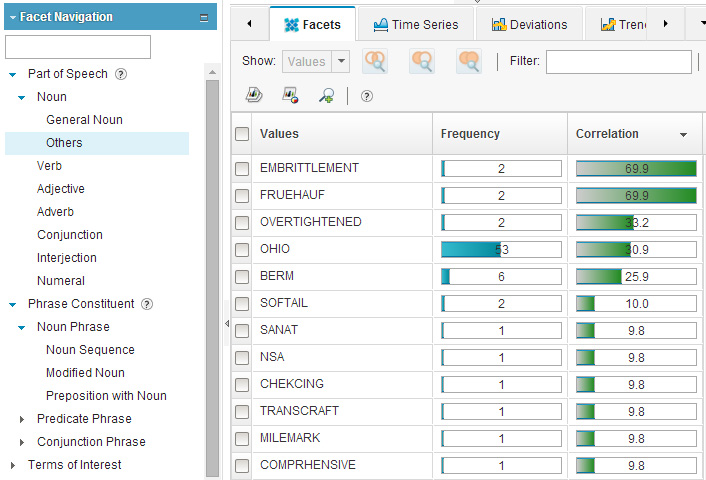
Результаты поиска содержат целый ряд слов с орфографическими ошибками/опечатками (например: "chekcing" , "comprhensive") , акронимов или аббревиатур (например, "NSA" ), редких или недавно появившихся слов (например, "overtightened" - "перетянул [гайку/болт]"), имена собственные или специальные технические термины, которые отсутствуют в словаре общей лексики WCA (например, "Ohio" , "embrittlement" - "охрупчивание"). В других случаях могут встречаться допустимые варианты формы слова или морфологические разновидности слова (например, McPherson и MacPherson - элементы подвески Макферсона). Все эти результаты поиска могут представлять определенный интерес с точки зрения терминологии - так, например, часто встречающиеся орфографические ошибки или акронимы, которые используются для сокращения технического термина, могут быть внесены в ваши словари в качестве альтернативных форм.
Использование дополнительных лингвистических фасетов
В процессе вашего исследования технических данных может оказаться, что некоторые релевантные термины для класса компонентов не были идентифицированы с помощью лингвистических фасетов WCA. Это может иметь место в случае таких терминов как, например, "right front wheel" ("правое переднее колесо"), "main drive pulley" ("шкив главной передачи") или "independent repair shop" ("независимая ремонтная мастерская"), которые представляют собой грамматические структуры прилагательное-существительное-существительное или прилагательное-прилагательное-существительное . Эти структуры не идентифицируются лингвистическим фасетом Modified Noun (Модифицированное имя существительное), который ограничен лишь структурой прилагательное-существительное.
Чтобы расширить спектр встроенных фасетов WCA, автор использовал WCA Studio для создания аннотатора, который находит подобные грамматические структуры. После развертывания в конвейере WCA этот аннотатор реализует созданный автором фасет AdjNP (Adj-Noun-Phrase - Словосочетание прилагательное-существительное ) под разделом Additional Linguistic Patterns (Дополнительные лингвистические структуры).
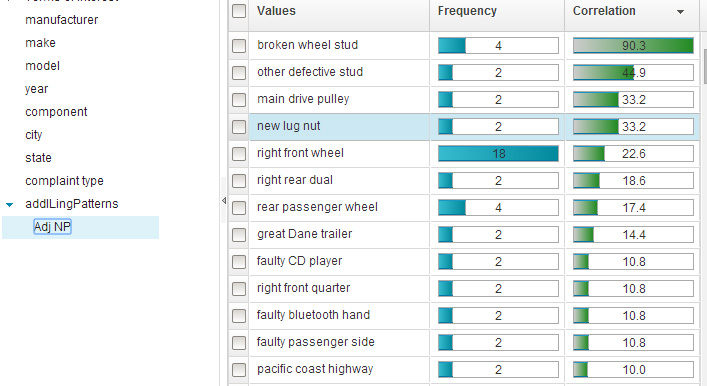
На рисунке 13 показан новый фасет Adj NP (Adj-Noun-Phrase - Словосочетание прилагательное-существительное ) в вашей конфигурации WCA, а также примеры словосочетаний, найденных для категории "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ"):
Рисунок 13. Рисунок 13. Реализация нового лингвистического фасета Adj-Noun-Phrase (Словосочетание прилагательное-существительное )
Итак, в первой части настоящего учебного пособия мы рассмотрели использование аналитических возможностей WCA для установления слов или словосочетаний (фраз), которые имеют отношение к определенным классам компонентов. Некоторые из этих слов являются терминами, которые относятся к семантической области компонента (такие как синонимы); другие являются вариациями (акронимы, орфографические ошибки/опечатки, альтернативные формы). В следующей части будет продемонстрировано применение этих возможностей для создания словарей предметной области, которые в дальнейшем могут использоваться для таких задач, как автоматическое тегирование новых документов.
Создание словаря предметной области
Вы уже обладаете достаточными знаниями для того, чтобы создавать свои собственные словари предметной области с релевантной терминологией. В дальнейшем вы сможете использовать эти словари в разных целях. Сначала рассмотрим, как создавать такие словари предметной области "вручную" с помощью функций Content Analytics Miner, а затем - как автоматизировать создание словарей с помощью API-интерфейса WCA.
Ручной способ создания словаря
Экспорт значений фасета
Значения фасета, которые отображаются в окне вкладки Facets (Фасеты), можно сохранить в формате текстового файла *.csv (Comma Separated Values - значения полей таблицы, разделенные запятыми). Щелкните по кнопке Report (Отчет) и выберите соответствующую опцию. Каждое значение фасета выводится со своими показателями частоты появления в документах и корреляции. Так, например, после того как вы выберете компонент "WHEELS:..." ("КОЛЕСА:..."), вы получите следующий результат для значений лингвистического фасета "последовательность имен существительных", загруженных в приложение электронных таблиц и отсортированных по частоте (см. рисунок 14) или по показателю корреляции (см. рисунок 15):
Рисунок 14. Экспорт значений фасета "Noun Sequence" (Последовательность имен существительных), отсортированных по частоте
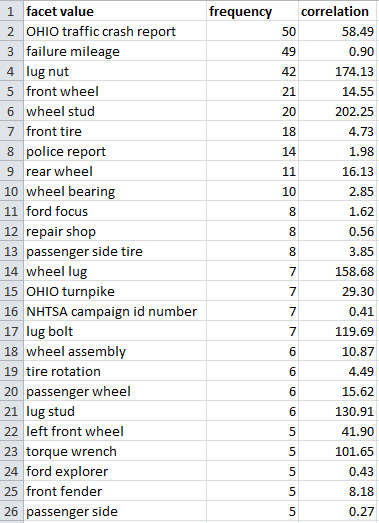
Рисунок 15. Экспорт значений фасета "Noun Sequence" (Последовательность имен существительных), отсортированных по показателю корреляции
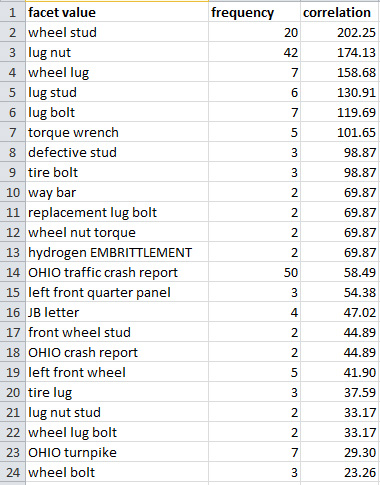
В электронной таблице можно сортировать и фильтровать список по различным критериям. Например, вы можете оставить в списке только термины, показатель корреляции которых выше заданного порогового значения, что позволит гарантировать высокую релевантность результатов.
Повторите операции, которые вы проделали с последовательностями имен существительных, для других "терминологически продуктивных" частей речи, таких как простые имена существительные, модифицированные имена существительные или расширенные структуры, подобные словосочетаниям "прилагательное-существительное". На рисунке 16 показана верхняя часть списка терминов, полученного с помощью таких структур и отсортированного по показателю корреляции для категории компонента "FUEL SYSTEM, GASOLINE" ("ТОПЛИВНАЯ СИСТЕМА, БЕНЗИН"). Весь процесс создания списка занял всего несколько минут:
Рисунок 16. Экспорт всех значений лингвистического фасета для категории компонента "FUEL SYSTEM, GASOLINE" ("ТОПЛИВНАЯ СИСТЕМА, БЕНЗИН"), отсортированных по показателю корреляции
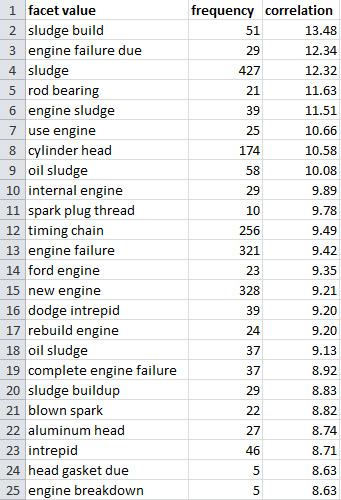
На рисунке 16 вы видите слова и словосочетания, которые в большинстве случаев, являются релевантными терминами для предметной области "engine" ("двигатель"). В этом списке попадается и "лингвистический шум", главным образом связанный с названиями автомобильных брендов или моделей. Некоторые термины представляются неполными или, наоборот, слишком расширенными. Так, например, беглое изучение значений "sludge build" в документах показывает, что конечным термином является сочетание слов "sludge" ("нагар") и "build up" ("накапливаться"). Аналогичным образом фраза "engine failure due" должна быть сокращена до "engine failure" ("отказ двигателя"), поскольку "due" является частью "due to..." ("из-за..."). Режим расширенного анализа (Advanced analytics) в WCA Content Analytics Miner является хорошим подспорьем для этого процесса - щелчок по значению фасета инициирует поиск по соответствующему термину в документах с отображением всех вхождений этого ключевого слова/фразы:
Рисунок 17. Поиск по значению фасета "sludge build" в документах
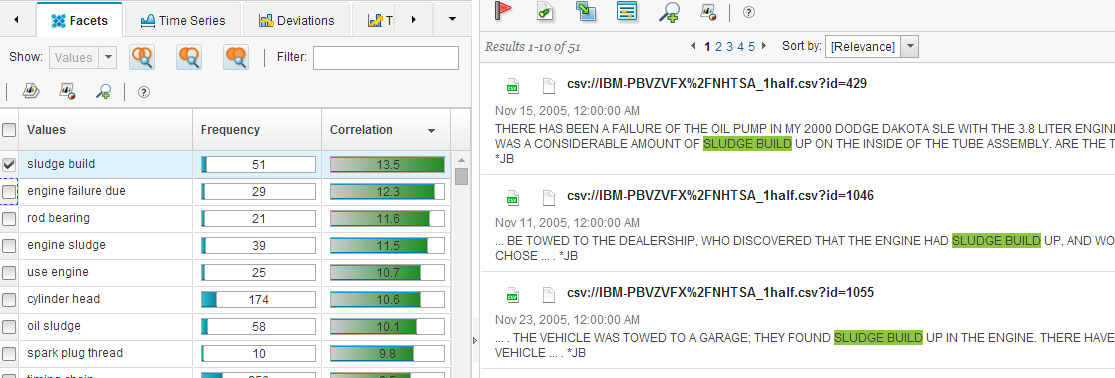
Такая фильтрация позволяет специалистам в данной предметной области, которые принимают или отклоняют "кандидатов" в словарные термины, быстро проверить список, руководствуясь собственным знанием предмета, а также признаками, фактами и доводами, приводимыми в документах.
Вы можете использовать полученный список терминов для дальнейшего анализа - этот список импортируется в словарь WCA Studio. В этом случае вам нужно добавить информацию о частях речи для каждого термина. Поскольку вы имеете дело с последовательностями имен существительных, итоговой частью речи должно быть "имя существительное". Эту информацию можно с легкостью добавить для всех (или части) записей с помощью простых команд электронной таблицы.
Использование словаря в WCA Studio
Импорт словаря в WCA Studio с помощью программы-мастера импорта словарей не вызывает никаких затруднений. Процессы создания и импорта словаря в WCA Studio подробно описаны в статье "Chemical Dictionaries in ICA Studio ("Химические словари в ICA Studio"), опубликованной на портале developerWorks.
Итоговый словарь можно использовать для поддержки подчиненного фасета (subfacet) "ENGINE..." ("ДВИГАТЕЛЬ..."), значениями которого будут являться узлы/детали двигателя, такие как "rod bearing" ("вкладыш шатунного подшипника"), "cylinder head" ("головка блока цилиндров"), "oil pump" ("масляный насос"), "spark plug" ("свеча зажигания")... Словарь также может быть частью правила более высокого уровня, которое объединяет детали/узлы двигателя с другим типом понятия для формирования новой аннотации. Аннотации, созданные из словарей и правил, могут быть размещены в рабочей среде WCA, где они будут реализовать новые фасеты в WCA Miner.
Оптимизация создания словарей
В предыдущей части пособия было показано, как экспортировать "кандидатов в термины" из WCA в WCA Studio для одного лингвистического фасета (имя существительное). Этот процесс необходимо повторить для каждого лингвистического фасета, который представляет интерес с терминологической точки зрения: имя существительное, глагол, словосочетание имен существительных (в среде WCA Miner - "noun sequence" - "последовательность имен существительных").
Для оптимизации данного процесса можно выполнить массовое извлечение всех этих фасетов, используя API-интерфейс WCA REST API. Воспользуйтесь справочной системой WCA IBM Knowledge Center, чтобы узнать, как получить доступ к документации REST API.
Прежде всего попытайтесь получить список фасетов, связанных с полным собранием документов, для чего введите соответствующий вызов REST в поле адреса вашего браузера:
Результат будет приблизительно таким (рисунок представлен в усеченном виде):
Рисунок 18. Список фасетов, полученный через WCA REST API
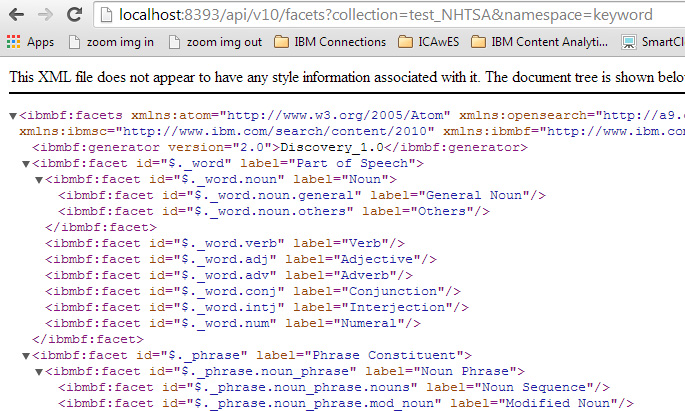
В XML-файле элементу фасет назначен атрибут метки (label), который дает отображаемое имя фасета (например, "Noun" - "Имя существительное"), и атрибут идентификатора (id) для "внутреннего" имени (например, "$._word.noun"), которое используется в вызовах API. Теперь вы можете выполнять поиск возможных значений фасета "Noun" ("Имя существительное") с помощью вызова REST:
который возвращает следующие значения (рисунок представлен в усеченном виде):
Рисунок 19. Список значений для лингвистического фасета "Noun" ("Имя существительное"), полученный через WCA REST API

Поисковый/фасетный вызов REST возвращает возможные значения для фасета "Noun" ("Имя существительное"), а также связанную статистическую информацию. Здесь все значения фасета имеют показатель корреляции, равный 1, поскольку параметр запроса возвращает все документы в собрании (наборе). Параметр запроса использует тот же самый синтаксис, что и простые запросы WCA. Отредактируйте ваш вызов REST для поиска документов, содержащих слово "engine" ("двигатель"), и получите 500 возможных значений фасета:
Если извлечь значения фасета и показатели корреляции из итогового XML-файла и отсортировать список по убыванию показателя корреляции, то верхняя часть полученного списка имен существительных будет выглядеть, как показано в Таблице 1:
Таблица 1. Верхняя часть списка имен существительных, полученного по запросу "engine" ("двигатель")
| Имя существительное | Корреляция |
|---|---|
| engine | 5,945369512024206 |
| sludge | 5,083791128653582 |
| check | 4,5708567925714405 |
| misfire | 4,434578339511516 |
| liter | 4,100485492528164 |
| compartment | 3,8341929699503408 |
| cool | 3,8088538657369537 |
| timing | 3,6459742040763126 |
| crankshaft | 3,529813794496392 |
| oxygen | 3,4589095714483973 |
| piston | 3,2950541462145404 |
| coolant | 3,2595967667044956 |
| spark | 3,2328246789720247 |
| cam | 3,1382332433086573 |
Пусть теперь вы, например, хотите выполнить ту же операцию с помощью запроса по "компонентному" фасету NHTSA "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ"), но как представить его в виде запроса WCA? Вернитесь в приложение Content Analytics Miner и в окне вкладки Facets (Фасеты) выберите это значение фасета и щелкните по кнопке "Add to query..." ("Добавить в запрос..."). Поле запроса в WCA теперь отображает точный синтаксис, который вам нужен для добавления в ваш вызов REST:
В таблице 2 показана верхняя часть итогового списка имен существительных (отсортированных по показателю корреляции), содержащая знакомые значения:
Таблица 2. Верхняя часть списка имен существительных, которые связаны с компонентом "WHEELS:LUGS/NUTS/BOLTS" ("КОЛЕСА:ГРУНТОЗАЦЕПЫ ШИНЫ/ГАЙКИ/БОЛТЫ")
| Имя существительное | Корреляция |
|---|---|
| lug | 229,0527407353 |
| stud | 178,3998666573 |
| nut | 81,0483078168 |
| OHIO | 30,8503584036 |
| BERM | 25,8579292585 |
| Dane | 23,2626241945 |
| bolt | 18,5593450909 |
| wrench | 15,8542751694 |
| dual | 13,9362582749 |
| turnpike | 12,7908656193 |
Если вы хотите автоматически создать словарь, связанный с различными компонентами, то в листинге 1 приводится типовой псевдокод, который вы можете для этого использовать:
Листинг 1. Псевдокод, позволяющий извлекать значения лингвистических фасетов для разных компонентов
Этот базовый код можно модифицировать, добавив в него фильтры, - например, чтобы отклонить "кандидатов" в термины, находящихся за пределами заданных пороговых показателей корреляции - или сопоставив каждому слову несколько подходящих компонентов.
В качестве примера автор запустил скрипт в Microsoft Powershell, который выполняет такую операцию извлечения. Для каждого кандидата в термины он подбирает два связанных компонента с наибольшими показателями корреляции. На рисунке 20 показана верхняя часть списка результатов. (Результаты отсортированы по показателю корреляции. Некоторые наименования компонентов отображаются в усеченном виде.):
Рисунок 20. Автоматически извлеченные из документов термины и связанные с ними коды компонентов
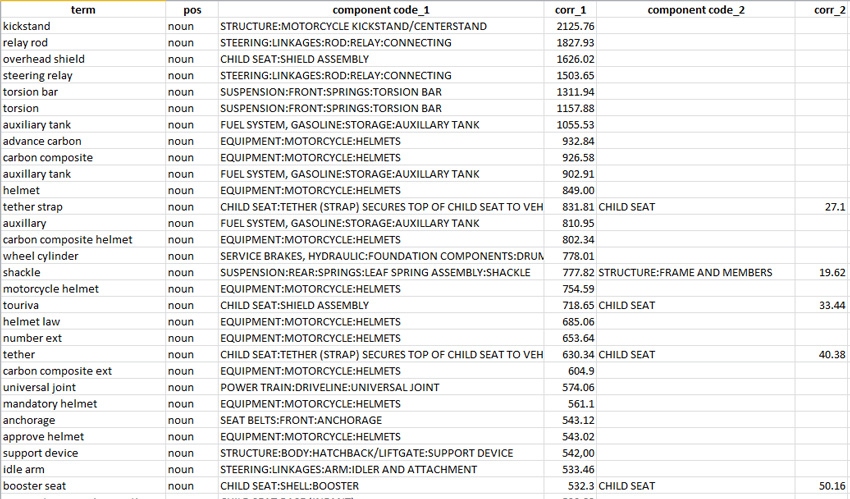
Как видно из примера, некоторым кандидатам в термины сопоставлено более одного кода связанного компонента: так, кандидату в термины "shackle" ("хомут") присвоено два кода компонента - SUSPENSION:REAR....:SHACKLE (ПОДВЕСКА:ЗАДНЯЯ.....:ХОМУТ) и STRUCTURE:FRAME AND MEMBERS (КОНСТРУКЦИЯ:РАМА И ЭЛЕМЕНТЫ КОНСТРУКЦИИ).
В других случаях могут быть взаимосвязаны коды компонентов: например, слова "tether" ("страховочная привязь") или "tether strap" ("страховочный ремень/лямка") достаточно часто встречаются в рекламационных документах NHTSA, имеющих отношение к CHILD SEAT (ДЕТСКОЕ СИДЕНЬЕ), но еще чаще в документах, снабженных тегом CHILD SEAT:TETHER (STRAP). Второй тег является детальным кодом компонента, расположенным глубже в иерархической структуре компонентов.
Среди значений с низким показателем корреляции часто встречается "лингвистический шум", что неудивительно:
Рисунок 21. Автоматически извлеченные (из документов) термины с низким показателем корреляции
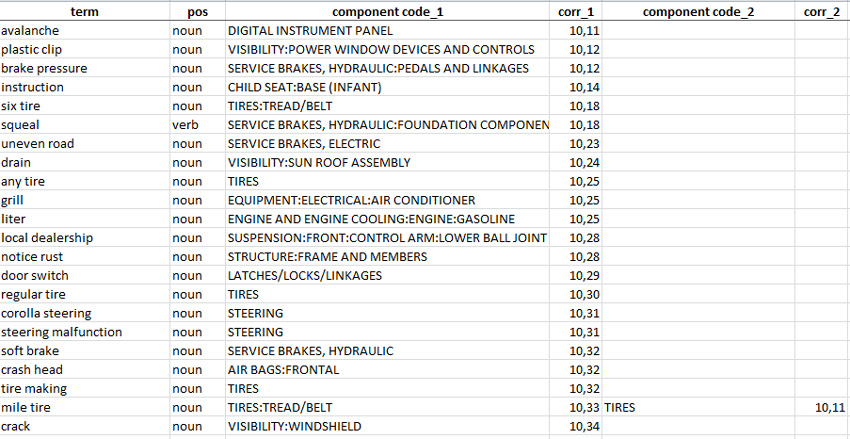
Взаимосвязь между словом/словосочетанием "brake pressure" ("тормозное давление") или, даже, "squeal" ("визг/писк/скрежет" [при резком торможении]) и компонентом "SERVICE BRAKES:..." ("РАБОЧИЕ ТОРМОЗА:...") понятна. В то же время не совсем ясно, как "неровная дорога" ("uneven road") может привести к проблеме с РАБОЧИМИ ТОРМОЗАМИ (SERVICE BRAKES), или какое отношение "местный дилер" ("local dealership") имеет к проблемам ПОДВЕСКИ (SUSPENSION).
Аналогичным образом, несмотря на то, что у некоторых моделей автомобиля в прошлом были проблемы с рулевым управлением, ситуация может измениться после того, как производитель устранил конструктивный дефект. Вы же вряд ли захотите засорять ваши словари названиями многочисленных моделей и даже терминами периферийных областей, такими как "местный дилер" ("local dealership"), если у вас нет такой цели.
Процесс создания словарей можно оптимизировать с помощью Watson Content Analytics / WCA Studio, однако полученные словари необходимо тщательно проверять и "подчищать".
Возможное применение: Тегирование документов NHTSA, связанных с эксплуатационной безопасностью
Словари, процесс формирования которых описан в предыдущем разделе настоящего пособия, можно импортировать в WCA Studio для создания аннотаторов, которые позволяют извлечь больше полезной информации из исходных текстов благодаря использованию аналитических фасетов WCA.
Ваша цель: автоматизировать тегирование (снабжение тегами) документов NHTSA на основе релевантной информации о компонентах. Для решения этой задачи попытайтесь найти фрагменты текста, которые помогут определить, какие компоненты транспортного средства являются ключевыми в данном конкретном рекламационном документе (заявлении, жалобе, претензии). Для этого мы используем словарь терминов, составленный автоматически согласно описанию в предыдущем разделе пособия, вместе со связанной информацией - кодами компонентов и показателями корреляции.
Для импорта в базу данных словарей WCA Studio, процесс которого здесь детально не описан, выполните следующие шаги:
- Сохраните список терминов в формате текста с разделителями, включающий столбцы кодов компонента и показателей корреляции.
- Создайте базу данных словарей WCA Studio Dictionary Database.
- В программе-мастере создания базы данных словарей создайте колонки для ассоциативных значений: Код компонента и Корреляция.
- Импортируйте терминологический список с разделителями в базу данных словарей Dictionary Database. Программа-мастер импорта обеспечивает соответствие между наименованиями колонок в файле с разделителями и наименованиями в базе данных. Предусмотрена возможность переопределения названий колонок.
- Скомпилируйте базу данных.
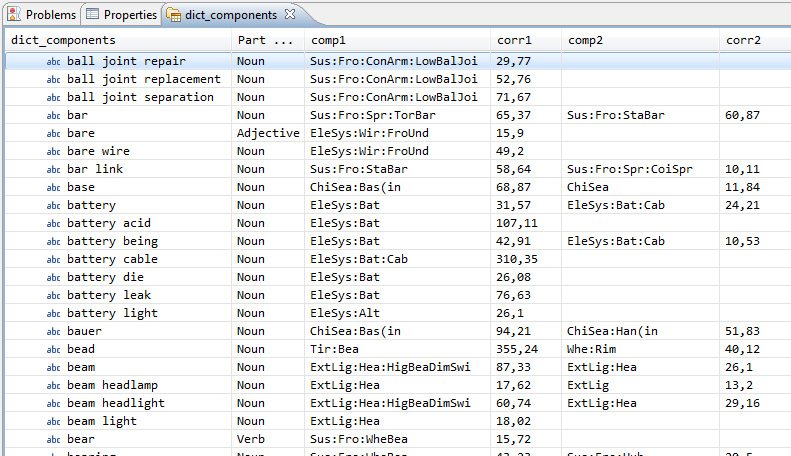
Этот процесс достаточно прост и выполняется за несколько минут. На рисунке 22 показан фрагмент такой базы данных, полученной путем импорта сырого (необработанного) словаря (без удаления названий автомобильных брендов, моделей и другого лингвистического шума). Коды компонентов представлены в сокращенном виде для облегчения процесса:
Рисунок 22. Пример базы данных словаря в WCA Studio, полученной с помощью автоматического извлечения терминов
После завершения создания базы данных словаря ее можно использовать на этапе лексического анализа в профиле аннотации UIMA. Шаблоны текстов, проанализированных с помощью этого профиля, показывают, какое содержание этих тестов соответствует словарным статьям:
Рисунок 23. Общий вид WCA Studio с найденными словарными аннотациями
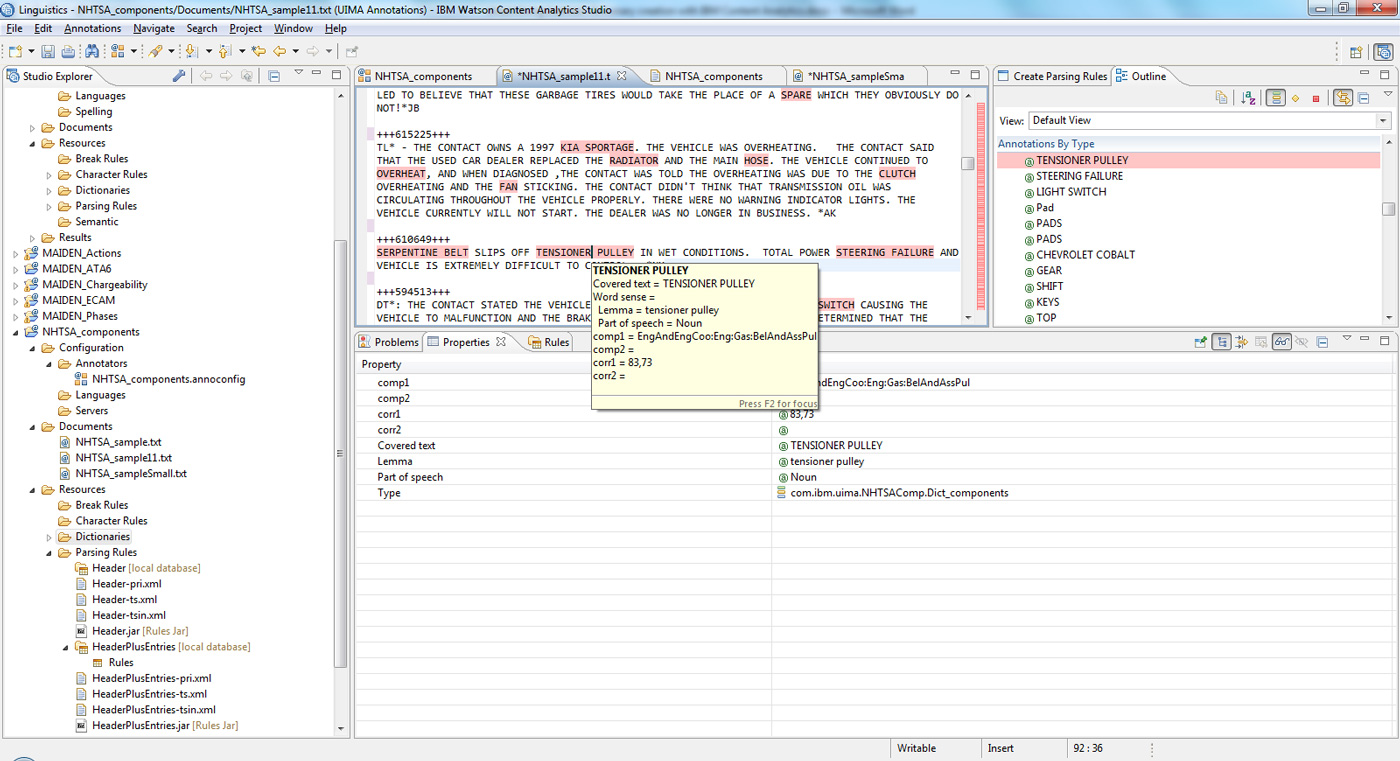
На рисунке 23 в правой части общего окна отображаются "экземпляры" (instances) отдельной аннотации словаря - в данном случае словаря компонентов. В текстовом файле эти экземпляры подсвечены, и наведение курсора мыши на один такой экземпляр выводит в контурном всплывающем окне подробную информацию о словарной статье: "tensioner pulley" ("натяжной шкив") коррелируется (с показателем 83,73) с кодом компонента ENGINE AND ENGINE COOLING:ENGINE:GASOLINE:BELTS AND ASSOCIATED PULLEYS (ДВИГАТЕЛЬ И СИСТЕМА ОХЛАЖДЕНИЯ ДВИГАТЕЛЯ:ДВИГАТЕЛЬ:БЕНЗИНОВЫЙ:РЕМНИ И СВЯЗАННЫЕ С НИМ ШКИВЫ). Если вы исследуете другие фрагменты этого текста, то вы увидите, что "serpentine belt" ("поликлиновой ремень") также коррелируется с этим же кодом компонента (с показателем 108,3), тогда как словосочетание "steering failure" ("отказ рулевого управления") связано с кодами компонента STEERING (РУЛЕВОЕ УПРАВЛЕНИЕ) (с показателем корреляции 12,67) и STEERING:HYDRAULIC POWER ASSIST SYSTEM (РУЛЕВОЕ УПРАВЛЕНИЕ:ГИДРОУСИЛИТЕЛЬ) (с показателем корреляции 11,68). Таким образом, если следовать подобной логике, данный конкретный документ следует снабдить тегом ENGINE AND ENGINE COOLING:ENGINE:GASOLINE:BELTS AND ASSOCIATED PULLEYS - и такое тегирование действительно имеет место в оригинальных данных NHTSA.
Руководствуясь приведенным ниже коротким примером, вы можете с легкостью выстроить процесс сопоставления кодов компонентов новому документу. Сначала систематизируйте все текстовые фрагменты документа путем аннотирования с помощью терминологического словаря, как описано выше. Затем выведите совокупный показатель корреляции для каждого значения кода компонента, найденного в разных фрагментах текста, основываясь на отдельных показателях корреляции.
В этом примере используется простой агрегированный показатель корреляции, суммирующий отдельные (индивидуальные) показатели. В описанном выше примере рекламационного документа:
- код компонента ENGINE AND ENGINE COOLING:ENGINE:GASOLINE:BELTS AND ASSOCIATED PULLEYS займет первую позицию с суммарным показателем корреляции 192,03 (83,73 + 108,3);
- за ним следует код компонента STEERING с показателем 12,67; и затем
- код компонента STEERING:HYDRAULIC POWER ASSIST SYSTEM с показателем 11,68.
Данный показатель, полученный простым суммированием или рассчитанный по более сложной формуле, можно вычислить с помощью кода Java на отдельном этапе в конвейере UIMA. Этот код будет использовать показатели корреляции, извлеченные с помощью словарных аннотаций на предшествующем этапе аннотирования.
Заключение
Из этого учебного пособия вы узнали, как исследовать специальную терминологию определенной предметной области с помощью аналитических возможностей IBM Watson Content Analytics, в частности, лингвистических фасетов WCA. Эти термины можно автоматически извлекать из собраний (наборов) документов благодаря API-интерфейсу WCA REST API и импортировать в WCA Studio для создания простых словарных аннотаций или аннотаторов более высокого уровня. Следует иметь в виду, что результаты такого автоматического извлечения могут содержать также неполные или нерелевантные термины и поэтому требуют тщательной проверки и корректировки в соответствии с назначением составленных словарей.