Предыстория
В нашей среде DB2 имелась база данных для лаборатории производительности. В этой базе данных содержались сведения по 2,5 млн. пользователей приложения, а ее размеры составляли 1,8 ТБ. Однако нашему клиенту потребовались результаты теста производительности при работе с базой данных, размеры которой соответствовали бы 1,2 млн. пользователей. С этой целью мы решили "вычистить" из этой, уже существующей базы данных пользователей сведения об 1,3 млн. пользователей.
Обзор
Мы опробовали несколько методик для удаления столь большого объема данных из базы данных. В конечном итоге мы выбрали наилучший метод и разработали алгоритм для его реализации. Вместо того чтобы удалять ненужные данные, мы экспортируем нужные данные и перезагружаем их в родительскую таблицу (корневой узел табличной иерархии). После этого мы с помощью команды SET INTEGRITY удаляем соответствующие ненужные данные из зависимых дочерних таблиц. Обратите внимание, что пока мы выполняем операцию удаления, эти таблицы остаются в офлайновом режиме.
Алгоритм
Прежде чем переходить к выполнению алгоритма удаления, может быть целесообразно изменить ряд конфигурационных параметров DB2. Не забывайте, что мы настраиваем эти параметры с целью достижения оптимальной производительности алгоритма удаления. После завершения удаления данных значения этих параметров можно вернуть к исходным значениям, чтобы обеспечить оптимальную производительность приложения. Показанные ниже значения параметров обеспечили наилучшую производительность в нашей среде. Вы можете попытаться подстроить их в соответствии с особенностями своей среды.
Конфигурация
Таблица 1. Настройка параметров реестра профиля для достижения оптимальной производительности
| Значение параметра | Влияние |
|---|---|
DB2_SKIPINSERTED = ON |
Пропускает незавершенные вставки в сканированиях таблиц, что уменьшает объем блокировок |
DB2_USE_ALTERNATE_PAGE_CLEANING = YES |
Использует для очистки страниц альтернативный метод вместо метода по умолчанию |
DB2_EVALUNCOMMITTED = ON |
Откладывает получение блокировок до тех пор, пока не станет известно, что строка удовлетворяет предикатам запроса |
DB2_SKIPDELETED = ON |
Пропускает удаленные строки и индексные ключи при сканированиях таблиц, что уменьшает объем блокировок |
DB2_PARALLEL_IO = * |
Осуществляет упреждающее извлечение экстентов в параллельном режиме |
Таблица 2. Настройка параметров конфигурации СУБД для достижения оптимальной производительности
| Значение параметра | Влияние |
|---|---|
DFT_MON_BUFPOOL = ON |
Дает СУБД указание собирать данные монитора буферного пула с целью анализа производительности |
DFT_MON_LOCK = ON |
Дает СУБД указание собирать информацию о блокировках с целью анализа производительности |
DFT_MON_SORT = ON |
Дает СУБД указание собирать информацию о сортировке с целью анализа производительности |
DFT_MON_STMT = ON |
Дает СУБД указание собирать информацию на уровне операторов с целью анализа производительности |
DFT_MON_TABLE = ON |
Дает СУБД указание собирать информацию на уровне таблиц с целью анализа производительности |
DFT_MON_UOW = ON |
Дает СУБД указание собирать информацию единицы работы (UOW) с целью анализа производительности |
ASLHEAPSZ = 32 |
Конфигурирует коммуникационный буфер между локальным приложением и ассоциированным с ним агентом с целью повышения производительности |
Таблица 3. Настройка параметров конфигурации базы данных для достижения оптимальной производительности
| Значение параметра | Влияние |
|---|---|
STMT_CONC = LITERALS |
Изменяет динамические SQL-операторы для повышения степени совместного использования кэша пакетов |
DFT_DEGREE = ANY |
Разрешает оптимизатору определять степень параллелизма внутри раздела |
PCKCACHESZ = AUTOMATIC |
Динамически изменяет размеры области памяти кэша пакетов с целью кэширования разделов для статических и динамических SQL-операторов |
CATALOGCACHE_SZ = 2000 |
Настраивает кэш каталогов с целью уменьшения издержек обращения к системным каталогам для получения информации, которая уже была извлечена ранее |
LOGBUFSZ = 2048 |
Буферизирует журнальные записи с целью более эффективного журналирования ввода/вывода файлов |
UTIL_HEAP_SZ = 524288 |
Настраивает максимальный объем памяти, который могут одновременно использовать утилиты BACKUP, RESTORE и LOAD |
LOGFILSIZ = 16384 |
Увеличивает количество транзакций обновления, удаления и вставки для уменьшения объема журнального ввода/вывода и повышения производительности |
SECTION_ACTUALS = BASE |
Обеспечивает сбор статистики на этапе исполнения раздела |
CUR_COMMIT = ON |
Возвращает только значения данных, которые уже зафиксированы на момент представления запроса |
Число строк
После завершения конфигурирования подсчитайте количество строк во всех таблицах базы данных и запомните ее первоначальный размер - это будет ваш исходный уровень. В каждом из показанных ниже запросов замените выделенный жирным шрифтом параметр соответствующими значениями для своей базы данных.
Листинг 1. Показатели базы данных (исходный уровень)
Большие дочерние таблицы
Команда SET INTEGRITY удалит соответствующие данные из дочерних таблиц нашей СУБД. Если дочерние таблицы имеют большие размеры, мы рискуем столкнуться с проблемами блокировки и проблемами журналирования транзакций. Чтобы избежать этих проблем, найдите таблицы, имеющие более 300 млн. записей, и прервите их отношения по внешнему ключу с родительскими таблицами. В результате большие дочерние таблицы не будут находиться в состоянии integrity pending, когда мы будем перезагружать полезные данные в родительские таблицы или в корневой узел. Мы выбрали число 300 млн. методом проб и ошибок. Выберите число, которое наилучшим образом соответствует вашей базе данных.
Листинг 2. Изоляция больших дочерних таблиц
Каждая изолированная таблица представляет собой псевдокорневой узел. Мы будем рекурсивно применять один и тот же алгоритм очистки, рассматривая одну изолированную таблицу в качестве корневого узла на каждой итерации рекурсивного исполнения. После успешного удаления данных из исходной и псевдокорневой табличных иерархий мы заново свяжем изолированные дочерние таблицы с их родительскими таблицами, чтобы восстановить первоначальную структуру базы данных.
Экспорт данных
Вместо того чтобы удалять ненужные данные, экспортируйте полезные данные из корневого узла. Чтобы повысить производительность ввода/вывода, обеспечьте размещение результатов экспорта в файловой системе, отдельной от контейнеров табличного пространства затрагиваемой таблицы. Прежде чем перезагружать полезные данные, удалите все индексы затрагиваемой таблицы и воссоздайте их после успешной перезагрузки данных (этот технический прием повысит производительность). Примечание. Ограничение первичного ключа необходимо убрать до удаления индекса, который используется для принудительного применения первичного ключа.
Листинг 3. Экспорт полезных данных и удаление индексов
Загрузка данных
После удаления индексов можно перезагрузить полезные данные, используя опцию REPLACE команды LOAD. Применение опции REPLACE команды LOAD гарантирует, что таблица будет усечена к моменту загрузки в нее полезных данных. Соответственно, усечение таблицы удалит ненужные данные. Кроме того, применение к таблице команды set integrity после перезагрузки полезных данных переведет все ее дочерние элементы в состояние integrity pending.
Листинг 4. Перезагрузка полезных данных
Создание таблиц исключений
Создайте таблицы исключений с двумя дополнительными столбцами типа TIMESTAMP и CLOB для всех таблиц, находящихся в состоянии integrity pending. Кроме того, воссоздайте ранее удаленные индексы и первичные ключи посредством обращения к результатам утилиты DB2LOOK, которую мы выполнили перед удалением индексов.
Листинг 5. Создание таблиц исключений
Рекурсивное применение операции set integrity к таблицам
Примените команду set integrity ко всем таблицам, находящимся в состоянии integrity pending, используя для этого соответствующие таблицы исключений. В результате этого ненужные данные будут вычищены из базовых таблиц и перемещены в таблицы исключений. Сохраните показанные ниже команды оболочки в виде скрипта оболочки (setIntegrity.sh) и примените его рекурсивно к таблицам, находящимся в состоянии integrity pending.
Листинг 6. Рекурсивное применение операции set integrity к дочерним таблицам
Выполните следующую команду:./setIntegrity.sh DBNAME SCHEMANAME
Воссоздание внешних ключей
Рекурсивным образом примените такой же процесс экспорта и перезагрузки полезных данных для всех псевдоузлов. После того как данные будут удалены из всех таблиц, воссоздайте отброшенные ограничения внешних ключей (посредством обращения к intitialDB2Look.ddl и alterTable.sql), чтобы снова связать псевдокорневые табличные иерархии с корневой таблицей и восстановить первоначальную структуру базы данных. Кроме того, удалите таблицы исключений, поскольку они нам больше не нужны.
Листинг 7. Удаление таблиц исключений
Итоговые показатели
Поскольку из таблиц было удалено значительное количество данных, выполните операцию reorg (по возможности используйте для операции reorg временное табличное пространство). Чтобы обновить статистические сведения, выполните утилиту runstats для всех таблиц. После этого зафиксируйте обновленные сведения по количеству строк, по размерам базы данных и по результатам работы утилиты DB2look с целью их сравнения с первоначальными сведениями (исходный уровень).
Листинг 8. Получение итоговых показателей для таблицы и базы данных
С помощью операции reorg мы сократили количество используемых страниц в табличном пространстве, однако верхняя отметка для размера табличного пространства может по-прежнему превышать количество реально используемых страниц, поэтому нам следует снизить эту отметку.
Листинг 9. Снижение верхней отметки размера табличного пространства
Если после снижения верхней отметки размер табличного пространства окажется больше, чем эта верхняя отметка, а вы выполняете резервное копирование/восстановление базы данных, эта база данных будет по-прежнему потреблять больше дискового пространства, чем требуется используемым в ней страницам. Чтобы свести к минимуму эти потребности к дисковому пространству, рассмотрите возможность изменения размеров табличного пространства и уменьшите эти размеры.
Мониторинг процесса удаления
При использовании описываемого алгоритма мы удаляем данные из дочерних таблиц с помощью команды SET INTEGRITY. Чтобы определить данные, подлежащие удалению, она обращается только к целевой таблице и к соответствующим родительским таблицам. Это означает, что в любой момент времени используются только буферные пулы целевой таблицы и ее родителей. Для оптимальной производительности следите за процессом с помощью утилиты DB2TOP и на каждом шаге процесса удаления настраивайте размеры активных буферных пулов.
Что следует запомнить
- Рассмотрите такую возможность, как изменение команд
EXPORTиLOADс целью размещения LOB-объектов в отдельной файловой системе. - Внимательно наблюдайте за круговыми зависимостями между таблицами в своей базе данных. Перед применением скрипта setintegrity.sh необходимо разорвать эти зависимости, иначе этот скрипт войдет в бесконечный цикл. Для нахождения круговых зависимостей между таблицами воспользуйтесь следующим запросом.
Заключение
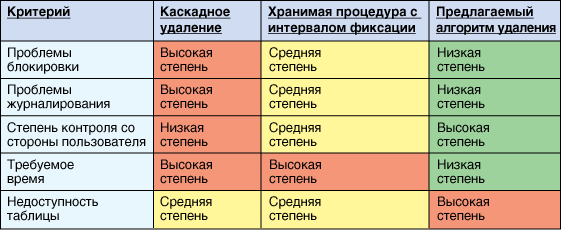
Как показано ниже, описываемый в этой статье алгоритм функционирует лучше, чем традиционные методы удаления данных, с минимальным количеством проблем с блокировками и с транзакционными журналами или вообще без таковых проблем. Он требует минимального времени и предоставляет пользователю улучшенные возможности контроля над процессом очистки. При использовании этого метода общая продолжительность работы состоит в большей степени из фазы SET INTEGRITY, чем из фазы LOAD, поэтому не следует надеяться, что эта продолжительность окажется небольшой. Кроме того, необходимо отметить, что при удалении данных с применением метода каскадного удаления или метода на основе хранимой процедуры таблицы остаются в онлайновом режиме, а вышеописанный алгоритм требует, чтобы таблицы находились в офлайновом режиме.
Рисунок 1. Сравнение методов удаления данных