Несколько слов от редактора
Бедный CASE! (То есть я хотел сказать: "Бедный Йорик!") С точки зрения правоверного Oracle'оида даже странно представить себе, что можно развивать системы приложений и баз данных Oracle, не используя какого-либо CASE-инструментария. По всем прочно усвоенным представлениям именно применение CASE обеспечивает отсутствие дублирования и непротиворечивость словаря данных сложного проекта при разработке многочисленных его приложений. И уж, конечно, невозможно предположить, что софтверная консалтинговая компания не применяет инструментарий CASE для текущей работы с постоянным заказчиком (а похоже о таком клиенте идет речь в статье М.Гохмана). Но тогда странно звучат слова, что разные команды разработчиков приложений могут спроектировать и внедрить разные таблицы EMP.
И все-таки эту статью стоит дочитать до конца. Слегка завуалировано, но очень близко к поверхности звучит мысль, что количество приложений, внедренных в системе управления корпорацией, вызывает качественные изменения структуры базы данных. При этом даже не рассматриваются такие нелишние, но вторичные в данной постановке, вопросы, как: одна ли база данных в корпорации, какова степень и структура ее/их распределения по нескольким/многим вычислительным установкам/филиалам, применяется ли механизм распределенных транзакций и так далее. Проблема скорее всего состоит в другом. Корпорация покупает приложения у разных разработчиков, а они не обязаны согласовывать между собой структуру таблиц EMP. Поэтому служба ли заказчика или привлекаемая им фирма сопровождения должна "соединить" приложения в интегрированной базе данных, и классический CASE здесь не при чем.
Тем самым, ручными действиями персонала администрации базы данных реализуются как бы некие функции CASE, а именно, доработка приложений на месте без метаинформации проектирования. (Я не профессионал в этой области, но мне представляется, что возможности CASE-реинжениринга пока еще не могут позволить полностью отказаться от человека.) Но в этом случае встают не менее насущные вопросы: кто, когда, в каких объемах, на какой базе осуществляется эта привязка.
Ответы на эти и другие вопросы во многом подскажут ранее опубликованные в Oracle-прессе статьи К. Люни "Роли системного уровня в ORACLE7" (ORACLE MAGAZINE, summer 1994, русский перевод в "Мир Oracle" 3/95) и Т. Кокса "Несколько мыслей о том, чем занимаются Архитекторы Данных, АБД и Администраторы Данных" (ORACLE INTEGRATOR, vol.7, No.2, 1996, русский перевод в ORACLE MAGAZINE/Русское Издание, номер 1, лето 1996). К. Люни помимо основных двух типов баз данных - Разработка (Development) и Эксплуатация (Production), называет и другие, например: Системное Тестирование (System Test) или Проверка при Внедрении (Acceptance Test). Вот на одной из баз данных этих типов М.Гохман, вероятно, и предполагает отлаживать ту или иную схему интеграции.
Другая важнейшая тема, поднимаемая М.Гохманом и Т.Коксом, - это "владение данными". В настоящее время так расширились понятия данных, управления и владения данными, что необходимо стало развести профессии администраторов. И коль скоро в современном мире данные составляют капитал в экономическом, юридическом, технологическом и других аспектах, становится чрезвычайно важной структура владения данными в недрах базы и, тем самым, обеспечение безопасности и ответственности использования данных (что неизбежно должно отражаться в организационной структуре корпорации). Поэтому наряду с уже известной должностью АБД возникают профессиональные категории администратора данных и администратора (группы) приложений.
И вот К.Люни определяет на системно-ролевом уровне структуру владения и использования данных, Т.Кокс рассматривает вопросы владения данными и деятельности различных администраторов в разных периодах жизненного цикла базы данных, а М.Гохман - классификацию и направления интеграции баз данных как объектов управления. Наши представления о внутренней информационной архитектуре приложений, о владении и предоставлении доступа к данным, о роли АБД существенно усложняются и обогащаются. Развитие проходит от базы данных одного приложения через базы слабо и сильно связанных (решения "нескольких схем" и "разделяемая схема" по М.Гохману) между собой приложений до единой интегрированной "корпоративной" базы данных.
Давайте, вслед за Шекспиром, помянем и старика Декарта: "Cogito ergo est!", что в данном случае рискну перевести достаточно вольно: "Усложняемся, значит, живем!"
Научный редактор "Мир Oracle"
Анатолий Бачин
To Share Or Not To Share! Вот в чем вопрос... Я часто задаю его нашим разработчикам, когда мы находимся в начале проектирования новой базы данных производственного назначения. Разумеется, этот вопрос не столь глубок, как тот, что принц Гамлет задал себе три столетия назад. И его решение не столь трагично, как в случае принца Датского. И все же ... Мы часто игнорируем или просто забываем, что одной из главных характеристик базы данных является разделяемость. Это значит, что у многих пользователей должна иметься возможность доступа к одним и тем же объектам базы данных без различения, какие инструменты или приложения они используют. Другими словами, объекты базы данных должны быть разделяемы. Вопрос лишь в том, до какой степени. Если два или более приложения используют информацию о служащих, должно ли каждое из приложений иметь свою собственную таблицу EMP, или они разделят одну общую? Мы каждый раз должны спросить себя: "Какие таблицы могут быть разделяемы несколькими приложениями, и как мы сможем обеспечить, что их целостность не будет нарушена?"
На ранней стадии разработки не всегда можно правильно определить границы проекта. Во многих случаях они устанавливаются произвольно, основываясь на таких соображениях, как запросы пользователей, бюджет, временные рамки проекта и так далее. Эти факторы, хотя и очень важны, все же не являются объективным критерием, необходимым для определения конкретной сферы деятельности нового приложения. Разрабатываемая система обычно прекрасно работает, если состоит даже из единственного приложения. Однако, чем больше внедряется приложений, тем более выявляется то обстоятельство, что одни и те же объекты данных используются многими различными приложениями.
Внедрение разделяемой среды базы данных в большой корпорации является очень трудной задачей. Обычно разные приложения проектируются одновременно разными командами разработчиков. Они не всегда имеют достаточно информации, какие объекты данных уже существуют, где они расположены, каковы форматы их данных, их имена и так далее.
Роль АБД в этом процессе двойственна. С одной стороны, он обеспечивает разработчиков всей необходимой информацией о существующих объектах данных и заставляет их использовать при разработке новых приложений. С другой стороны, АБД должен создать среду, которая была бы достаточно гибкой, чтобы у разработчиков имелась возможность создать и протестировать их программы без учета ограничений, накладываемых уже существующей базой данных. Для того, чтобы реализовать эти цели, АБД должен создать схему, которая позволит ему управлять использованием объектов базы данных различных приложений таким образом, что это негативно не скажется на будущих этапах жизненного цикла проекта.
В этой статье я излагаю три метода, используя которые можно обеспечить построение эффективной и надежной разделяемой базы данных. Их названия происходят из того, где располагаются разделяемые объекты базы данных. Я начну с наиболее простой схемы, которая названа решением "несколько схем" (multiple-schema approach). Используя этот метод, различные разделяемые объекты базы данных распределены по различных схемах. Второй метод, названный решением "разделяемая схема" (shared-schema approach) подразумевает, что некоторые, но не все, объекты находятся в одной разделяемой схеме. Наконец, я привожу решение "корпоративная схема" (corporate-schema approach), по которому все объекты базы данных принадлежат одной корпоративной схеме и разделяемы для всех приложений Oracle.
Решение "несколько схем" (Multiple schema approach)
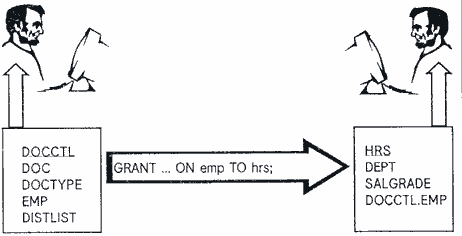 |
В случае базы данных с несколькими схемами (рис.1) каждое приложение использует свой собственный набор таблиц, последовательностей, представлений и других объектов. Обычно владение такими объектами отнесено некоему идентификатору (an user id) Oracle-пользователя, созданному исключительно с целью группирования объектов в одну схему приложения. Естественно, имя приложения как-то отражается в имени такого идентификатора. Например, для системы "Документооборот" (Document Control) в качестве идентификатора, или, другими словами, имени схемы, подойдет что-то вроде DOCCTL. Для того, чтобы разрешить пользователям обращаться к объектам этой схемы, Вы должны войти в базу Oracle как пользователь DOCCTL и выдать соответствующие привилегии (grants) на все ее объекты пользователем или их ролям.
Все программы приложений, которые обрабатывают объекты DOCCTL, должны обращаться к ним, используя имя схемы в качестве квалификатора. Или, как сделано в многих системах, чтобы спрятать имя схемы, используются общие синонимы. В этом случае должно установить применение общих синонимов как стандарт для всех приложений и установить очень строгие соглашения об их именовании, чтобы гарантировать уникальность имен синонимов.
Давайте предположим, что схема DOCCTL содержит следующие таблицы:
- DOC - записи о документах;
DOCTYPE - типы документов (руководства, чертежи, процедуры и так далее);
EMP - записи о служащих;
DISTLIST - связующая таблица между DOC и EMP, которая определяет, какие
документы распределяются среди служащих.
Давайте теперь представим, что мы собираемся разработать новую систему "Кадры" (Human Resources). Ее объекты в базе данных будут находиться в новой схеме, названной HRS. Следующие таблицы включаются в эту схему:
- EMP - записи о служащих;
DEPT - записи об отделах;
SALGRADE - должностные оклады.
Как не трудно заметить, оба приложения используют данные о служащих. Если эти приложения были разработаны двумя различными командами проектировщиков, очень вероятно, что обе таблицы EMP, используемые в приложениях DOCCTL и HRS, будут совершенно различны. Пусть, например, таблица EMP в схеме HRS представлена следующим образом:
- CREATE TABLE emp
(empno NUMBER(4),
first_name VARCHAR2(20),
last_name VARCHAR2(20),
address VARCHAR2(100),
phone_number NUMBER(10),
ss_no NUMBER(9),
degree VARCHAR2(10),
deptno NUMBER(5),
title VARCHAR2(10),
grade NUMBER(1),
mgr NUMBER(4));
а в схеме DOCCTL таблица EMP выглядит так:
- CREATE TABLE emp
(empno NUMBER(4),
first_name VARCHAR2(20),
deptno NUMBER(5),
last_name VARCHAR2(20),
title VARCHAR2(10),
mailstop NUMBER(4));
Замечание: естественно, эти иллюстративные приложения сильно упрощены.
Теперь мы имеем дилемму. Можно сохранить оба приложения отдельно друг от друга. Однако, это породит необходимость управления двумя версиями таблицы EMP, каждой для своего приложения. Следовательно, обновление данных о служащих должно быть выполнено в обеих таблицах. Альтернативой этому является интегрирование этих приложений так, чтобы они разделяли одну и ту же таблицу EMP.
Решение возникшей проблемы представляется очень простым. Коль скоро приложение DOCCTL было уже реализовано, Вы решаете использовать ее таблицу EMP для нового приложения HRS. В этом случае нужно модифицировать таблицу EMP в DOCCTL так, чтобы она содержала столбцы, используемые обоими приложениями. И поскольку общий синоним для этой таблицы уже создан, новые программы, написанные для приложения HRS, получат доступ к таблице EMP, используя этот же общий синоним. Теперь можно сказать, что Вы успешно интегрировали два приложения, "Документооборот" и "Кадры", в том смысле, что оба приложения разделяют таблицу EMP. Далее следует удалить таблицу EMP из схемы HRS, поскольку она более не нужна. Тем самым, Вы исключили необходимость хранить одни и те же записи о служащих в двух разных таблицах. Следовательно, исключен и избыточный доступ к базе данных для управления обеими таблицами. Для того, чтобы завершить работу, Вы должны предоставить пользователям соответствующие полномочия для доступа к новым таблицам. Для этого должно установить контакт с базой данных как пользователь HRS и выдать привилегии на его таблицы пользователям приложения HRS.
Пользователь HRS более не имеет таблицы EMP в своей схеме; следовательно, только пользователь DOCCTL может предоставить доступ к этой таблице. Очень вероятно, что со временем появятся новые пользователи, которые будут работать с системой "Кадры", но которым не потребуется обращение к системе "Документооборот". Вы же грантируете таких новых пользователей доступом к таблицам HRS, логинясь к базе данных как пользователь HRS. Но им также нужно обеспечить доступ к таблице EMP, что можно сделать только как пользователь DOCCTL.
А теперь представте себе, что случится, когда Вы внедряете десятки приложений? Как много времени надо потратить на контакты в качестве различных идентификаторов, чтобы обеспечить пользователям доступ к соответствующим таблицам, когда большее и большее число таблиц будет разделяться множеством приложений? Для того, чтобы сделать Вашу жизнь легче, следует авторизировать каждый идентификатор (user id), представляющий каждое приложение, чтобы предоставить им привилегии доступа не только к таблицам в их собственных схемах, но также и к тем таблицам, которые находятся в других схемах. В нашем примере Вы присоединяетесь к базе данных как пользователь DOCCTL и выполняете следующее предложение:
GRANT SELECT, INSERT, UPDATE, DELETE ON emp TO hrs WITH GRANT OPTION;
Теперь пользователь HRS также может передать привилегии на таблицу EMP пользователям своего приложения:
GRANT SELECT, INSERT, UPDATE, DELETE ON docctl.emp TO smith;
Как можно видеть, рассмотренный метод позволяет постепенно внедрять новые приложения, которые будут поставлять новые объекты базы данных, и, в добавок, разделять существующие объекты с другими приложениями.
Существуют достоинства и недостатки этого метода. В чем же его достоинства? Несомненно, решение "несколько схем" - простой путь интеграции каждого нового приложения с теми, что уже были внедрены до этого. Он позволяет должным образом управлять созданием новых объектов базы данных в схемах приложений. Применяя этот метод, можно изначально создать новую схему, включающую все объекты базы данных, которые потребуется новому приложению, не обращая внимания на то, что что-то из этого уже существует в других схемах. Позднее, как мы видели на примере, можно будет удалить их и, используя общие синонимы, перенаправить доступ новых программ к подобным таблицам в других схемах. Существуют, однако, несколько существенных недостатков при использовании решения "несколько схем". До сих пор мы не говорили о связях между таблицами в различных схемах. В нашем примере таблица EMP имеет внешний ключ, связывающий ее с таблицей DEPT. Если таблицы EMP и DEPT находятся в одной схеме, то чтобы определить это ограничение нужно присоединиться к базе данных как пользователь HRS и выполнить следующее предложение:
ALTER TABLE emp ADD CONSTRAINT fk_emp_in_dept
FOREIGN KEY (deptno) REFERENCES dept;
Следовательно, в рассматриваемом нами случае нужно будет квалифицировать таблицу DEPT посредством имени схемы HRS:
ALTER TABLE emp ADD CONSTRAINT fk_emp_in_dept
FOREIGN KEY (deptno) REFERENCES hrs.dept;
Как видите, возможно применение внутри- и вне- схемных связей. Но это может создать для Вас и довольно много неудобств. Предположим, что позднее станет ясно, что лучше было бы поместить таблицу EMP в схему HRS. Теперь Вы не только будете вынуждены переместить эту таблицу из одной схемы в другую, изменить ее гранты и общий синоним, но также изменить DDL-предложение, которое определяет ее связи с другими таблицами и переопределить ее ссылочные ограничения целостности. Это может потребовать значительных усилий с Вашей стороны. Другой недостаток этого метода имеет отношение к использованию утилит Export и Import. Время от времени нужно делать полный экспорт схемы. Однако, Вы не сможете сделать полный экспорт приложения HRS, если одна из используемых им таблиц, а именно EMP, находится в другой схеме. Недостатки решения "несколько схем", которую мы только что рассмотрели, можно избежать при соответствующем планировании схемы, правильном определении соглашений администрирования данными, некоторыми дополнительными координирующими усилиями с Вашей стороны.
Решение "разделяемая схема" (Shared schema approach)
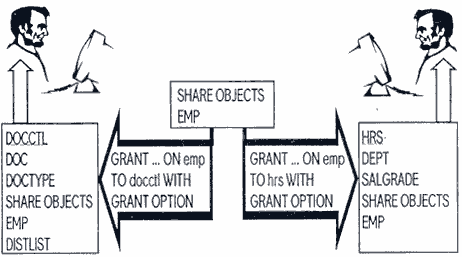 |
Это решение очень похоже на предыдущее решение "несколько схем". Здесь мы проектируем одну схему, которая содержит все объекты базы данных, разделяемые многими приложениями (рис.2). Объекты, специфичные для конкретных приложений, находятся в их собственных схемах. По мере того, как внедряется все большее и большее число приложений, мы переносим в разделяемую схему те таблицы, которые более не являются конкретизированными только для одного приложения. В нашем примере схема системы "Документооборот" изначально содержит все свои таблицы. Когда внедряется новое приложение "Кадры", таблица EMP переносится из схемы DOCCTL в разделяемую схему, которую следовало бы назвать SHARED_OBJECTS. Для того, чтобы выполнить это действие, нужно создать новую таблицу EMP в схеме SHARED_OBJECTS и скопировать в новую EMP записи из EMP схемы DOCCTL:
CREATE TABLE shared_objects.emp AS SELECT * FROM docctl.emp;
Когда новая EMP создана, мы должны определить ее первичный и внешние ключевые ограничения, поскольку на нее ссылаются другие таблицы. Затем требуется поменять старый общий синоним на новый:
DROP PUBLIC SYNONYM emp;
CREATE PUBLIC SYNONYM emp FOR shared_objects.emp;
И, наконец, можно удалить старую EMP из схемы DOCCTL.
DROP TABLE emp CASCADE CONSTRAINTS;
Если таблицы, которые надо переместить из одной схемы в другую, приемлемого размера, метод, который я только что изложил, не причинит никаких проблем. Однако, если имеет место большая таблица, может не хватить памяти сегмента отката, поскольку в течение операции "CREATE ... as SELECT ...", которую я показал выше, не производится фиксация (commit). Если Вы предвидите эту проблему, можно экспортировать EMP из DOCCTL и затем импортировать ее в схему SHARED_OBJECTS. При этом должно использовать соответствующие значения параметра BUFFER в утилите IMPORT и установить COMMIT=Y. Это заставит утилиту фиксировать изменения в базе данных после обработки каждого буфера включаемых записями. Или же можно написать простую программу на PL/SQL, чтобы читая старую таблицу, вставлять ее записи в новую, используя операцию COMMIT после каждых N записей.
При внедрении каждого нового приложения еще кое-какие таблицы будут перенесены из уже существующих схем приложений в схему SHARED_OBJECTS.
Решение "разделяемая схема" более здраво, чем первое, поскольку оно разделяет объекты базы данных на логические группы согласно тому, разделяемы ли они приложениями или строго специфичны только для одного их них. Так как мы внедряем все новые и новые приложения, все большее и большее число таблиц будет находить свое место в разделяемой схеме. В конечном счете в ней разместятся все таблицы, то есть будут разделяться многими приложениями. Однако, это решение не лишено недостатков первого метода. Действительно, оно предполагает много действий АБД при переносе таблиц из одной схемы в другую, при изменениях определений их связей с другими таблицами. Не говоря уже о том, что перенос записей из старых таблиц в новые может потребовать достаточно длительного времени. Если Вы, АБД, действуете в ограниченной среде, где пользователи требуют постоянного доступа к базе данных, при использовании этого метода Вам может встретиться довольно много трудных ситуаций.
Перед тем как я изложу третий метод интеграции приложений, давайте еще раз взглянем на два предыдущих. Общим их недостатком является то, что они оба не дают надлежащей поддержки понятию владельца данных. Противопоставляя владельца данных владельцу таблицы, я имею в виду авторизацию пользователя или группы пользователей, как имеющих право создавать и удалять записи в таблице. В нашем примере работники департамента "Кадры" являются владельцами записей таблицы EMP, поскольку они руководят наймом (и увольнением, к сожалению) служащих. Разумеется, я не имею в виду, что эти пользователи должны по настоящему владеть и таблицей EMP. Таким владельцем таблицы EMP должно быть приложение, которое создает и уничтожает записи о служащих в интересах этих пользователей. Другими словами, схема, представляющая приложение, в которой осуществляется создание и удаление записей таблицы, должна и быть владельцем этой таблицы. В нашем же примере таблицей EMP владеет схема DOCCTL, что не соответствует надлежащему понятию владения данными. Следовательно, АБД должен перенести таблицу EMP в схему HRS. Как можно видеть, первый метод поддерживает владение данными, но он требует некоторых дополнительных, а иногда и довольно значительных усилий с стороны АБД. Однако, второй метод не поддерживает понятия владения данными вовсе, поскольку его конечным результатом является принадлежность всех таблиц разделенной схеме.
Помимо подлинных владельцев таблиц, АБД должен выявить те приложения, которые обращаются к определенным таблицам по чтению и обновлению. Другими словами, АБД нужно отождествить все приложения, которые разделяют таблицы и другие объекты базы данных.
Ниже я хочу представить метод, который позволит Вам постепенно построить разделяемою среду базы данных, который поддерживает понятие владения данными и, в то же самое время, позволяет обеспечить связь всех приложений с таблицами, которыми они владеют, и с таблицами, которые они используют.
Решение "корпоративная схема" (Corporate schema approach)
В основе этого метода лежит идея, что все объекты базы данных без различия, какие приложения их используют, представляют собой элементы данных, важные для корпорации в целом. Мы знаем, что каждая таблица используется лишь немногими программами, реализующими определенные функции по обработке данных. В то же самое время существуют сложные зависимости между функциями обработки данных, и, если одна из них не выполнится (fail), то могут отказать и многие другие. Таблицы базы данных (сущности данных) имеют между собой сложные связи, которые представляются ссылочными ограничениями целостности. Все это приводит нас к заключению, что не существует легко определяемых границ, разделяющих одно приложение от другого.
Давайте на момент абстрагируемся от понятия приложение. Давайте сначала рассмотрим производственную модель данных и, основываясь на этой модели, создадим объекты нашей базы данных. Мы разместим все объекты этой базы данных, изначально таблицы, в одной схеме, которую можно было бы назвать CORPORATE_DATABASE. Все таблицы, используемые любым приложением или разделяемые несколькими приложениями, будут находиться в этой схеме. Мы можем определить все связи (relationships) этих таблиц, используя ссылочные [декларативные] ограничения целостности. Коль скоро все таблицы принадлежат одной схеме, наши DDL-предложения в части объявления ограничений целостности будут очень простыми. Нет нужды в ссылках на владельцев таблиц. Далее, мы избавлены от необходимости перемещения таблиц из одной схемы в другую. Следовательно, установленные ограничения не будут изменяться, пока не изменятся правила предметной области (busines rules - деловые, конструкционные правила). Таким образом, схема корпоративной базы данных представляет нашу модель базы данных. Все данные, требуемые пользователями для выполнения их функций по обработке данных, будут получены из таблиц корпоративной схемы. В нашем примере схема CORPORATE_DATABASE изначально будет состоять из следующих таблиц:
DOC
DOCTYPE
EMP
DISTLIST
Это - таблицы системы "Документооборот". В последствии в схему будут добавлены следующие таблицы:
EMP
DEPT
SALGRADE
а к таблице EMP будут добавлены новые поля.
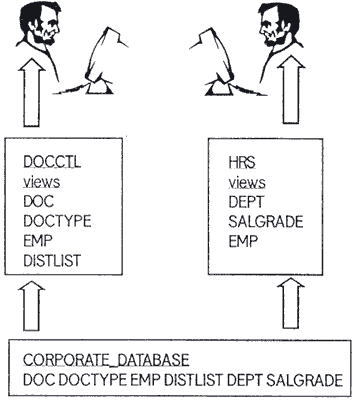 |
Следующий уровень нашей структуры составляют приложения или проекты. Все данные, которые требуются для некой функции приложения, будут получены из корпоративной базы данных; следовательно, для каждого приложения мы определяем представления базы данных, при помощи которых будут получены необходимые данные из таблиц корпоративной базы. Мы разместим эти представления в схемах приложений (рис. 3) [прим. редактора: это и есть изюминка предлагаемого решения]. Таким образом, схема каждого приложения включает свой собственный набор представлений. Некоторые из этих представлений могут обновлять таблицы; другие являются представлениями только_для_чтения. Для того, чтобы создать эти представления, пользователь CORPORATE_DATABASE должен предоставить соответствующие объектные привилегии на его таблицы идентификаторам (user ids) схем конкретных приложений. В нашем примере схема HRS состоит из следующих представлений:
CREATE VIEW emp AS SELECT * FROM corporate_database.emp;
CREATE VIEW dept AS SELECT * FROM corporate_database.dept;
CREATE VIEW salgrade AS SELECT * FROM corporate_database.salgrade;
А схема DOCCTL содержит такие представления:
CREATE VIEW emp AS SELECT * FROM corporate_database.emp;
CREATE VIEW doc AS SELECT * FROM corporate_database.doc;
CREATE VIEW doctype AS SELECT * FROM corporate_database.doctype;
CREATE VIEW distlist AS SELECT * FROM corporate_database.distlist;
Примечание автора: символ '*' в списке выборки используется только для экономии моего набора.
Перед созданием этих представлений АБД должен соединиться с базой данных как пользователь CORPORATE_DATABASE и выдать гранты на ее таблицы соответствующим пользовательским идентификаторам (user ids) схем приложений, используя фразу WITH GRANT OPTION:
GRANT SELECT, INSERT, UPDATE, DELETE ON emp TO hrs WITH GRANT OPTION;
GRANT SELECT, UPDATE ON emp TO docctl WITH GRANT OPTION;
Заметьте, что пользователю DOCCTL предоставлены права только выборки (SELECT) и обновления (UPDATE) на таблице EMP, тогда как пользователь HRS грантирован привилегиями SELECT, INSERT, UPDATE и DELETE на этой таблице. Это и означает, что владение записями о служащих представлено приложению HRS. Приложение DOCCTL сможет читать и обновлять записи о служащих, но не в состоянии создавать и удалять их. В последствии каждый пользовательский идентификатор, представляющий схему приложения, будет передавать гранты [администратор приложения] на эти представления пользователям своего приложения. Например, пользователь HRS передаст следующие права применения своих представлений:
GRANT SELECT, INSERT, UPDATE, DELETE ON emp TO scott;
GRANT SELECT, INSERT, UPDATE, DELETE ON dept TO scott;
GRANT SELECT, INSERT, UPDATE, DELETE ON salgrade TO scott;
По мере построения все новых и новых приложений, все большее и большее число таблиц будет создано в корпоративной схеме базы данных. В то же самое время будет создано все большее и большее число схем, состоящих из различных представлений, по которым данные извлекаются из корпоративной базы данных.
Заметим, что различные схемы приложений могут включать представления с одинаковыми именами. Для примера, мы находим представление по имени EMP в обоих схемах: HRS и DOCCTL. Тем не менее, зти представления различны, поскольку различны их списки выборки, хотя источником является одна и та же таблица EMP из корпоративной базы данных. Каждое приложение должно обращаться к представлениям базы данных, используя имя схемы в качестве квалификатора. Например, программах приложения "Кадры" мы обнаружим:
SELECT empno, first_name, last_name FROM hrs.emp;
В программах приложения Документооборот мы видим:
SELECT empno, first_name, last_name FROM docctl.emp;
Таким образом, мы реализовали структуру базы данных, которая состоит из двух свободно ассоциированных уровней:
- хранение данных в корпоративной схеме;
- получение данных в схемах приложений.
Каждый из этих уровней имеет свое назначение. Уровень хранения данных представляет действительные данные, которыми владеют различные деловые единицы корпорации. Уровень получения данных представляет различные деловые единицы, как те используют и разделяют данные, хранимые в корпоративной базы данных. Это можно представить себе в виде тематических (subject) областей базы данных, которые группируют сущности данных, основываясь на их предметных связях и не необходимо базируясь на способе, которым были определены границы приложений. И хотя тематические области не являются новым понятием в анализе данных, они становятся все более и более популярны при построении хранилищ данных (warehouses), в системах DDS (Decision Support System - система принятия решений) и EIS. Следовательно, уровень получения данных представляет модели данных каждого приложения и каждой тематической области. Теперь, для того, чтобы идентифицировать все приложения, разделяющие один и тот же объект базы данных, мы можем использовать следующее SQL-предложение:
SELECT owner, object_name
FROM all_objects ao, public_dependency pd
WHERE pd.object_id = ao.object_id
AND pd.referenced_object_id in
(SELECT object_id
FROM all_objects
WHERE owner = 'CORPORATE_DATABASE'
AND object_name = UPPER('&&1')
AND object_type = UPPER('&&2'));
Если укажем EMP в качестве первой подставляемой переменной &&1 и TABLE - в качестве второй переменной &&2, то получим следующий результат:
| OWNER | OBJECT_NAME | OBJECT_TYPE |
| ----- | ----------- | ----------- |
| HRS | EMP | VIEW |
| DOCCTL | EMP | VIEW |
Этот отчет говорит нам, что таблица EMP, находящаяся в схеме CORPORATE_DATABASE, использована в двух представлениях: HRS.EMP и DOCCTL.EMP. Другими словами, два приложения разделяют таблицу EMP.
Для того, чтобы идентифицировать приложение, которое владеет данными в конкретной таблице, мы найдем те идентификаторы (user ids), которым предоставлены привилегии вставки (INSERT) и удаления (DELETE) записей в этой таблице. Например:
SELECT grantee,privilege
FROM all_tab_privs_made
WHERE owner = 'CORPORATE_DATABASE'
AND privilege IN ('INSERT', 'DELETE')
AND table_name = UPPER('&&1'));
В случае таблицы EMP этот запрос возвращает следующий результат:
| GRANTEE | PRIVILEGE |
| ------- | --------- |
| HRS | INSERT |
| DOCCTL | DELETE |
Используя метод корпоративной схемы, мы можем построить новые приложения и постепенно интегрировать их в существующую среду базы данных. Новые объекты базы данных, приходящие с новым приложением, не необходимо должны быть созданы в корпоративной схеме с самого начала проекта. Изначально, все таблицы, используемые новым приложением, могут действительно быть созданы в отдельной схеме приложения. Все программы, написанные для этого нового приложения должны обрабатывать все таблицы, используя имя схемы в качестве квалификатора. Позднее эти таблицы могут быть перенесены в корпоративною схему с использованием именно тех же самых DDL-предложений, которые изначально применялись для их создания в схеме приложения. После этого в схеме приложения будут созданы представления, извлекающие данные из перенесенных таблиц. Все они будут прозрачны для программ, поскольку имена представлений будут теми же самыми, что и соответствующие таблицы. Все эти трансформации должны быть сделаны перед тем, как приложение внедряется в производственную базу данных; следовательно, Вы не будете иметь проблем с перенесенными таблицами из схемы приложения в корпоративную схему.
Как я говорил выше, различные новые схемы могут быть созданы и наполнены представлениями, которые получают данные из одних и тех же источников: таблиц схемы CORPORATE_DATABASE. Это значит, что кроме схем приложений, могут быть созданы схемы тематических областей, содержащие представления, отображающие основные группы сущностей данных. Эти представления тематических (subject) областей могут быть использованы сторонними (ad hoc - на конкретный случай) пользователями в их запросах и отчетах. Они могут также определены как источники данных для систем класса DDS и EIS.
Заключение
В этой статье мы рассмотрели три метода создания разделяемой среды базы данных. Давайте коротко охарактеризуем каждый из этих методов:
Несколько схем:
- каждое приложение представляется своей собственной схемой;
- объекты, чьи данные принадлежат конкретному приложению, размещаются в этой схеме приложения;
- владелец таблиц выдает права доступа на свои таблицы, используя фразу WITH GRANT OPTION для других схем приложений;
- идентификаторы (user ids) схем приложений предоставляют права доступа пользователям к их собственным таблицам и к таблицам, которые они разделяют;
- когда таблицы перемещаются из одной схемы в другую, их внутри- схемные ссылочные ограничения целостности должны быть переопределены;
- должны использоваться общие синонимы, чтобы избежать затруднений с применением квалификаторов имен объектов, когда объекты перемещаются из одной схемы в другую.
Разделяемая схема:
- каждое приложение представляется своей собственной схемой;
- объекты, используемые только в конкретной схеме, размещаются в схеме этого приложения;
- объекты, разделяемые несколькими приложениями, размещаются в схеме разделяемых объектов;
- когда объект изменяет свой статус от частного на разделяемый, он перемещается в разделяемую схему и его внутри- схемные ссылочные ограничения целостности переопределяются;
- управление правами доступа к объектам осуществляется тем же образом, что и в методе с несколькими схемами;
- должны использоваться общие синонимы, чтобы избежать затруднений с применением квалификаторов имен объектов, когда объекты перемещаются из одной схемы в другую.
Корпоративная схема:
- все таблицы размещаются в одной корпоративной схеме;
- каждое приложение или тематическая область представляется своей собственной схемой;
- каждая схема приложения содержит представления, по которым извлекаются данные из таблиц корпоративной схемы;
- каждой схеме приложения предоставлены права доступа к соответствующим корпоративным таблицам посредством использования фразы WITH GRANT OPTION;
- пользователям приложений предоставляются права доступа к представлениям, которые принадлежат схемам приложений;
- приложения, которые владеют и разделяют данные, могут быть идентифицированы запросом к словарю данных;
- таблицы никогда не перемещаются между схемами в производственной базе данных.
Когда я начинал писать эту статью, у меня были две задачи: подчеркнуть важность построения разделяемой среды базы данных и проиллюстрировать, какого рода препятствия могут встретиться на пути к полной интеграции приложений и обеспечения разделяемости среды базы данных. Как видите, успех в интеграции приложений в высшей степени зависит от принятой стратегии разделения.
Все мы помним, что цель принца Гамлета была благородной, но, к сожалению, он не выработал правильной стратегии, и ему пришлось дорого заплатить за свои ошибки.