Машинные данные могут поступать во множестве различных форматов и в разных объемах. Метеодатчики, фитнес-трекеры и даже системы кондиционирования воздуха производят огромные объемы данных, что обуславливает потребность в решении для работы с большими данными. Но как определить, какие данные важны и какая доля этой информации является достоверной, подлежит включению в отчеты или имеет ценность с точки зрения обнаружения аварийных ситуаций? В этой статье рассматриваются некоторые проблемы и решения для поддержания потреблениМашинные данные могут поступать во множестве различных форматов и в разных объемах. Метеодатчики, фитнес-трекеры и даже системы кондиционирования воздуха производят огромные объемы данных, что обуславливает потребность в решении для работы с большими данными. Но как определить, какие данные важны и какая доля этой информации является достоверной, подлежит включению в отчеты или имеет ценность с точки зрения обнаружения аварийных ситуаций? В этой статье рассматриваются некоторые проблемы и решения для поддержания потребления огромных наборов машинных данных. В решениях применяются технологии для работы с большими данными, а также платформа Hadoop.я огромных наборов машинных данных. В решениях применяются технологии для работы с большими данными, а также платформа Hadoop.
Хранение и потребление данных
Прежде чем исследовать базовые механизмы хранения и потребления данных, рассмотрим, какую информацию мы храним, каким образом мы ее храним и как долго.
Одна из больших, но не часто озвучиваемых проблем Hadoop состоит в том, что это решение предоставляет только пополняемое (append-only) хранилище данных для большого количества информации. Этот подход выглядит идеальным для хранения машинных данных, однако он вводит в искушение хранить огромные объемы информации на протяжении длительных промежутков времени. Эта ситуация становится проблемой, не потому что платформа Hadoop неспособна к хранению данных, а потому что объем данных создает ненужную нагрузку на среду, целью которой является оперативное и эффективное получение информации.
Вследствие этого использование Hadoop для хранения машинных данных требует тщательного управления. Вместо сохранения всех данных в предположении, что впоследствии мы сможем извлечь из них все необходимое, нам следует придерживаться определенного плана. Например, чтобы использовать данные для оперативных предупреждений, не нужно просеивать информационные отсчеты за многие годы с целью отбора последних сведений. После того как проблема идентифицирована, а соответствующее предупреждение отправлено, маловероятно, что данные двухгодичной или даже шестимесячной давности окажутся полезными (помимо того, что они могут пригодиться для выявления тенденций и построения базисов).
InfoSphere BigInsights Quick Start Edition
InfoSphere® BigInsights™ Quick Start Edition - это доступная для загрузки бесплатная версия платформы IBM InfoSphere BigInsights на базе Hadoop. Эта версия позволяет ознакомиться со всеми возможностями (такими как Big SQL, текстовый анализ и BigSheets), которые корпорация IBM разработала для расширения функциональности проекта с открытым кодом Hadoop. Получить максимальную пользу от работы с Hadoop вам помогут специальные обучающие материалы, в том числе пошаговые руководства для самостоятельной подготовки и видеоуроки. Вы сможете работать с большими объемами данных без ограничений по времени или объему.
Отбор данных для хранения
Выбор состава сохраняемой информации должен быть осознанным. Задайте себе следующие вопросы и создайте план того, какие данные следует хранить и как долго.
Сколько данных мы намереваемся хранить?
Чтобы определить это количество, оцените размеры своих записей и интервалы времени, через которые поступают данные. Это позволит получить адекватное представление о том, сколько данных создается, сколько информационных отсчетов сохраняется и какая часть этой информации используется на ежедневной или еженедельной основе. Например, элемент данных с тремя полями (дата, время и информация) имеет небольшие размеры, но при записи каждые 15 секунд порождает приблизительно 46 КБ данных в день. При двух тысячах машин суммарный объем данных составит 92 МБ в день. Если мы записываем несколько информационных точек, то суммарный объем данных будет еще больше.
За какой период времени мы хотели бы хранить информацию?
Задайте себе два вопроса: насколько далеко по времени мы хотели бы иметь возможность просматривать все информационные точки и насколько далеко по времени мы хотели бы иметь возможность определять только тенденции. Отдельные поминутные данные не слишком полезны по истечении недели, поскольку после устранения проблемы потребность в этой информации невелика.
С учетом этих обстоятельств нам необходимо определить т. н. базис (baseline). В данном случае базис - это информационная точка или матрица, служащая индикатором нормального функционирования. Наличие базиса упрощает выявление аномальных тенденций и выбросов.
Каким образом мы хотим определять базисы?
Применительно к предыдущим вопросам базисы - это значения для сравнения, которые хранятся для выявления отклонений новых значений от нормального уровня. Например, можно записать объем дискового пространства и установить порог в виде определенного относительного или абсолютного показателя, превышение которого будет служить индикатором недостатка свободного дискового пространства.
Базисы могут относиться к одному из трех основных типов.
- Уже существующие базисы. Если мы осуществляем мониторинг машинных данных, то базисы для сравнения с ними уже могут быть известны. Например, вентилятор, работающий с оборотами 2000 об./мин., имеет фиксированный базис, который не корректируется с течением времени.
- Управляемые базисы. Для управляемых компонентов и систем, которые подвергаются последующему мониторингу, базис задается посредством сравнения управляемого значения с "сообщаемым" (получаемым в отчете) значением. Например, у управляемой по температуре системы имеется заданная температура и сообщаемая температура. Если в системе управления микроклиматом заданная температура составляет 5°C, а сообщаемая температура составляет 4,8°C, то эта заданная (требуемая) температура и является базисом, с которым сравнивается фактический показатель.
- Исторические базисы. Этот тип базиса применяется к системам, для которых базис вычисляется на основе существующих значений. Например, мониторинг высоты уровня воды в реке или объем ее стока базируются на данных, выявленных или полученных ранее.
Очевидно, исторические базисы изменяются с течением времени. И действительно, за исключением редких случаев, они никогда не задаются в виде абсолютных показателей. Вместо этого исторический базис должен быть переменной, которая задается на основе имеющейся информации о датчике и измеряемом значении.
Например, с течением времени мы можем добавить дисковое пространство или приложения могут изменить свои потребности относительно времени получения информации и ее характера. Применение относительных показателей при сравнении с базисом может быть неудачным выбором. Применение относительного показателя прекрасно работает до тех пор, пока 5% от 10 ТБ считается низким показателем. Если объем нашего хранилища составляет 50 ТБ, то 5% - это уже 2,5 ТБ, а такой большой объем может оказаться непригодным в качестве порога предупреждения.
Базисы вычисляются на основании прошлых значений. Поэтому нам необходимо определить, сколько данных мы хотим сравнивать и за какой исторический период. С чем мы сравниваем новые данные - с прошлой неделей, с прошлым месяцем или с прошлым полугодием?
Хотим ли мы представлять в графическом виде и включать в отчеты исторические данные?
Мы можем хранить и представлять информацию в графическом виде, однако - как и в случае базового хранения - маловероятно, что мы захотим вернуться к определенной минуте или секунде. Тем не менее мы можем записывать минимальные, максимальные и средние значения каждые 15 минут на протяжении дня с целью генерации графической информации.
С учетом ответов на вышеперечисленные вопросы определите, как решать базовые проблемы хранения данных, как выявлять исключения, которые инициируют предупреждения и уведомления, и как обрабатывать весь объем информации, которая генерируется в ходе этого процесса.
Хранение данных в среде Hadoop
Первая проблема состоит в том, как хранить данные в среде Hadoop.
Вообще говоря, Hadoop не является подходящей оперативной базой данных и хранилищем для информации такого типа. Хотя Hadoop является практичным решением для добавления данных в систему методом пополнения, более удачным выбором является функционирующая в близком к реальному времени база данных SQL.
Тем не менее это ограничение - не повод отказываться от Hadoop. Практичный способ загрузки данных в базу данных состоит в использовании непрерывной записи в HDFS (Hadoop Distributed File System) посредством пополнения существующего открытого файла. Для записи пакетов данных в журнал можно также использовать формат CSV, который по своей природе поддерживает только пополнение информации. Платформа Hadoop может служить концентратором.
Один из приемов состоит в записи всей разнообразной информации за некоторый период времени в единственный файл и в копировании этой информации в HDFS для обработки. Можно также осуществлять запись непосредственно в файл HDFS, доступный из Hive или из HBase.
В рамках Hadoop наличие большого количества малых файлов менее эффективно и менее полезно, чем меньшее количество файлов более крупного размера. Большие файлы распределяются по кластеру более эффективно. В результате данные лучше распределяются между разными узлами кластера. Такое распределение повышает эффективность обработки информации посредством MapReduce, поскольку блоки данных присутствуют на большем количестве узлов.
Эффективнее объединять и группировать информацию от множества информационных точек в несколько больших файлов, охватывающих более длительные периоды времени (например, целый день) либо несколько хостов, машин или других крупных "сборщиков" данных.
При использовании этого подхода создается файл, имя которого соответствует сборщику, машине и, возможно, дате. Этот файл содержит разные строки для каждого элемента данных. Примеры: siteid,collectorid,datetime,settemp,reportedtemp.
Важно обеспечить широкое распределение данных в масштабах системы. Например, в случае Hadoop-кластера с 30 узлами необходимо эффективно распределить данные по всему кластеру, чтобы в ходе обработки избежать непроизводительных потерь процессорных ресурсов и ресурсов дискового ввода/вывода. Такое распределение обеспечивает самую быструю обработку и самое малое время отклика, что имеет большое значение при использовании данных для мониторинга и генерации предупреждений.
Пополнение таких файлов может производиться через единственный концентратор, собирающий данные от множества хостов и записывающий информацию в эти большие файлы.
Разделение данных подобным способом также позволяет эффективно секционировать их согласно хостам и/или датам. Такое распределение повышает эффективность синтаксического разбора и обработки информации, поскольку такие инструменты, как Hive, способны ограничивать объем своей работы определенными данными из этих разделов.
Применение Hive для генерации базисов
Если у нас еще нет фиксированных или управляемых базисов, то наша первая задача состоит в создании базовых показателей и статистических данных для определения границ "нормальности".
Эта информация с большой вероятностью будет меняться с течением времени, поэтому нам потребуется возможность для определения изменений базиса за это время посредством анализа существующей информации. Эту информацию можно анализировать в рамках Hive с помощью подходящего запроса для генерации минимальных, максимальных и средних статистических показателей в зависимости от времени.
Как показано в листинге 1, вычисляемая информация базируется на данных от датчиков температуры (для множества датчиков и хостов). Эти данные обобщаются по дате.
Листинг 1. Применение Hive для генерации минимальных, максимальных и средних статистических показателей за промежуток времени
Этот код предоставляет нам некоторые опорные данные для сравнения. К примеру, показания всех датчиков находятся в диапазоне от 2°C до 14°C, но средний показатель составляет от 7°C до 8°C. Эти данные предоставляют нам важные числовые показатели, на которых можно основывать принятие решений относительно генерации предупреждающих уведомлений в ходе нормального функционирования.
В этом примере производится обобщение зарегистрированных данных для отдельных информационных точек, но можно производить также обобщение данных по часам или минутам, если записи в журнале делаются с более высокой частотой. Можно также группировать данные по различным элементам - в этом примере предполагается, что все датчики и хосты являются независимыми, однако в некоторых случаях датчики могут снимать различные показания с одного и того же статического элемента, и их показания нужно рассматривать совместно.
Чтобы не пересчитывать эти данные при каждом вызове, можно записать их в новую таблицу, которая будет служить базисом для сравнения при выявлении каких-либо проблем во входящем потоке данных. Это можно сделать посредством оператора INSERT INTO с использованием выходной информации запроса (см. листинг 2).
Листинг 2. Применение оператора INSERT INTO
Для регулярных проверок вычисляйте последнее значение текущей величины. Исследуйте всю таблицу и вычислите значение, которое является корректным для всего набора данных от соответствующих датчиков и хостов. Можно удалить базисы на определенную дату (см. листинг 3).
Листинг 3. Удаление базисов на определенную дату
Можно вычислить и другие значения, например, стандартное отклонение или расчетную процентную долю. Можно вычислить конкретные точки за пределами этих значений с целью создания нужных базисов.
Теперь у нас есть базисы для использования. Попробуем научиться выявлять проблемы.
Оперативная идентификация проблем
Если наш базис встроен в данные, то для определения элемента, выходящего за пределы сконфигурированного параметра, необходимо сравнить между собой два значения: select * from temp where temp.setval != temp.reportval;.
Если имеется интервал или допуск, сравнение осуществляется посредством выполнения более сложного запроса (см. листинг 4).
Листинг 4. Сложный запрос
Если у нас есть базисные данные, используйте эту информацию посредством выполнения объединения на основе среднего значения за день для хоста и для машины (см. листинг 5).
Листинг 5. Выполнение объединения
В этой выходной информации содержатся все строки записей из первичного источника данных, находящиеся за пределами вычисленных базисов, для каждой машины, для каждого датчика температуры и для каждой соответствующей даты. Выборочные значения оказались больше, чем мы предполагали. Вычислите фактические значения на основе более строгой версии, например, исходя из превышения в 10% над вычисленным значением.
В листинге 6 производится сравнение со всеми базисами.
Листинг 6. Сравнение со всеми базисами
Для формирования предупреждений на основании данных реализуйте проверку, которая в случае ошибки будет выводить определенное сообщение (см. листинг 7).
Листинг 7. Данные для предупреждений
Теперь к этой таблице можно обращаться с запросами, определять записи категории Overtemp и осуществлять углубленный анализ данных.
Теперь мы можем запрашивать оперативную информацию. Инициирование предупреждений можно осуществлять на основе ранее идентифицированных границ и точек исключения. Поскольку эта информация включает только запросы Hive, она доступна для обширного набора сред и приложений в качестве элемента, поддерживающего отчетность и отслеживание.
Архивирование старой информации и создание обобщенных данных
Чтобы заархивировать информацию (необходимый шаг для выполнения сравнений и для генерирования базисов), необходимо сжать соответствующие данные. После сжатия данных они содержат только критически важную статическую информацию (то есть усредненное текущее состояние) после ее сравнения с записями, отклоняющимися от среднего уровня. После этого мы можем пометить сжатые данные соответствующим образом.
Этот подход требует генерации модифицированной формы запроса базиса, который обобщает информацию с использованием минимального и максимального значений базиса, а также включает отклонения, выпадающие за эти границы.
Мы сами определяем, какой объем данных нужно хранить и с какой частотой осуществлять сохранение данных. Проследите за тем, чтобы сохраняемые данные были пригодна для обобщения; это позволит нам генерировать информацию и значения за границами нормальных данных.
Пример графика на рис. 1 построен по данным от датчика, которые подобны данным из предыдущего примера.
Рисунок 1. Пример графика
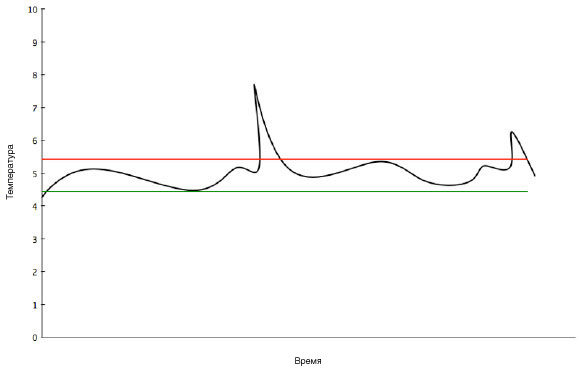
Данные, соответствующие точкам между двумя линиями (верхней красной и нижней зеленой), нас больше не интересуют. Они полезны постольку, поскольку позволяют определить среднее значение, в сравнении с которым можно исследовать два выброса температуры. Однако для продолжительного промежутка времени можно среднее значение по этому промежутку и далее исходить из предположения, что это среднее практически не изменяется.
При обобщении данных мы извлекаем сводку, игнорируя информационные точки, находящиеся за установленными нами границами, а затем создаем таблицу, которая обобщает данные, которые находятся за этими пределами.
Эта операция выполняется посредством вставки, которая обобщает только данные, которые попадают между этими элементами (см. листинг 8).
Листинг 8. Вставка
Этот код создает таблицу с данными, обобщенными сначала по времени, а затем по машине и по датчику. Таблица содержит сообщенные показания, а ее заключительный столбец всегда содержит нули. Эта таблица говорит нам о том, что эти данные безопасны для использования в качестве базиса, поскольку вычисленное значение не выходит за рамки ранее вычисленных базисов. Мы указываем только простую разность значений в пределах 1°C от базового среднего.
Можно осуществить противоположное действие, найдя значения, выходящие за пределами ранее вычисленных базисов для конкретного сочетания даты, машины и датчика. В этом случае мы сможем извлечь все значения, а не только обобщенную информацию (см. листинг 9).
Листинг 9. Извлечение всех значений
Эти записи представляют собой сырые данные за рамками базового среднего; они помечены единицами в последнем столбце. Благодаря этому мы сможем по желанию исключать или включать эти значения при вычислении долгосрочных базовых данных на основании обобщенной и заархивированной журнальной информации.
Заключение
При потреблении и обработке сырых машинных данных получение информации и ее сохранение в среде Hadoop - на самом деле не самое сложное. Более сложной задачей является определение того, что представляет собой наша информация и как мы хотим обобщать и представлять эти данные.
Получив сырые данные и научившись выполнять запросы к ним через Hive, нам необходимо вычислить базисы (если они не являются фиксированными). Затем мы выполняем запрос, который сначала определяет базисные значения, а потом на их основании отыскивает данные, выходящие за рамки этого базиса. Статья описывает несколько простых методик обработки, идентификации и оперативного выявления исключений, указывающих на ошибки, которые необходимо включать в отчеты или в предупреждения либо представлять в графическом виде, а затем направлять в приложение для управления системой.