Предлагаемое решение проблем виртуализации
Виртуализация - это абстракция, скрывающая фоновые процессы. Пользователи ничего не знают о хост-машине, других пользователях и их средах. Каждая виртуальная машина может независимо взаимодействовать с другими устройствами, приложениями, данными и пользователями, как если бы это был отдельный физический ресурс.
Говоря о виртуализации, надо помнить, что ее можно реализовать не единственным способом. На практике есть много способов достижения одного и того же результата посредством разных уровней абстракции.
Рассматриваемый в статье пример основан на полной виртуализации, которая является практически полной имитацией реального оборудования и обеспечивает бесперебойную работу программного обеспечения, которое обычно представляет собой гостевую операционную систему.
Рисунок 1. Пример полной виртуализации
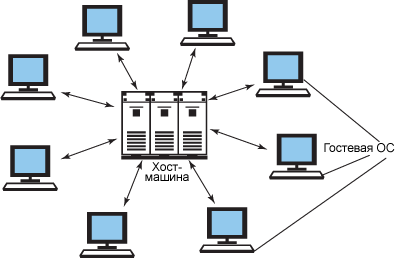
Проблемы виртуализации
Массовое развертывание виртуальных машин является очень обременительной и утомительной работой. Это кошмар для администраторов. Развертывание виртуальной машины в центре данных состоит из ряда задач, таких как установка операционной системы, подготовка машины для системы (sysprep), добавление системы в домен и предоставление пользователям соответствующего доступа.
Одной из ключевых проблем является планирование развертывания, особенно если речь идет о массовом развертывании. Это одна из главных проблем консолидации клиентских систем. Двумя словами проблему можно описать так: что разворачивать и где.
Решение
В статье предлагается оптимальное, простое и эффективное решение проблемы - алгоритм Virtual Machine Deployment Map (план развертывания виртуальных машин). Принимая во внимание наличие различных серверов и ресурсов хранения данных, алгоритм пытается распределить группы виртуальных машин на доступные серверы пропорционально имеющимся ресурсам. Алгоритм также минимизирует число базовых виртуальных машин в каждой группе, тем самым существенно уменьшая память, необходимую для развертывания.
Память тоже распределяется пропорционально доступным устройствам хранения. Результатом является план, который показывает, сколько виртуальных машин каждой группы нужно создать на каждом сервере и сколько логических устройств и какого размера нужно создать на каждом устройстве хранения.
Кроме того, алгоритм управляет распределением нагрузки групп виртуальных машин ("золотых образов") между серверами и устройствами хранения, пытаясь минимизировать число "золотых образов". Таким образом, он предоставляет эффективную методику оптимизации ресурсов групп "золотых образов" между различными серверами и устройствами хранения, которая зависит от конфигурируемого коэффициента распределения. Он даже обеспечивает высокую готовность при развертывании виртуальных машин.
Наш алгоритм создает план архитектуры развертывания и отображение развертывания между виртуальными клиентами, серверами и устройствами хранения (отображение виртуальных клиентов на серверы и виртуальных дисков на устройства хранения). Это позволяет инженеру по развертыванию и системному администратору знать, какая будет создана виртуальная машина и на каком сервере. Он также предлагает способ разделения памяти в соответствии с требованиями к памяти всех виртуальных машин.
В зависимости от бизнес-требований этот план может быть представлен либо в графическом, либо в XML-формате.
Блок-схема алгоритма
Алгоритм делится на две части:
- План Server-VM
- План Storage-VM
План Server-VM
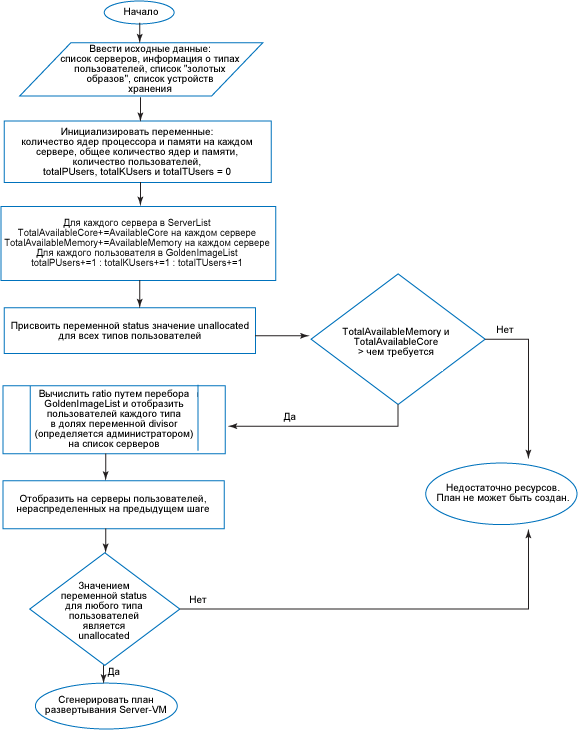
Он выполняет отображение Server-VM (сервер на виртуальную машину). На рисунке 2 показано отображение Server-VM.
Рисунок 2. Блок-схема отображения Server-VM
План Storage-VM
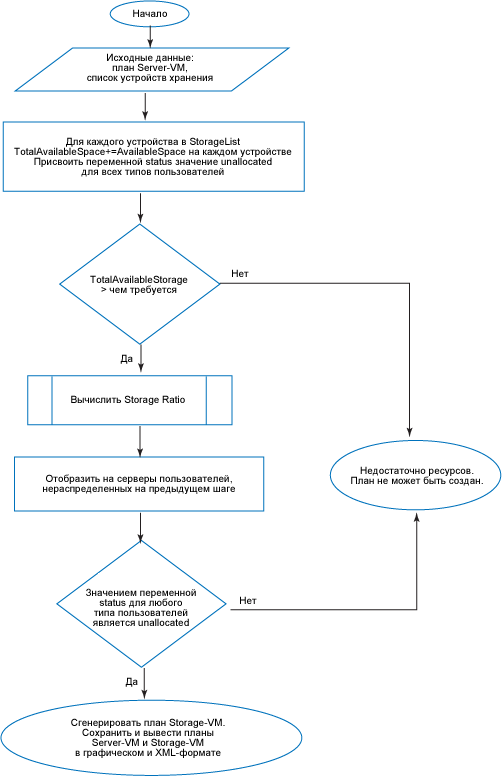
Это план, основываясь на выходных данных плана Server-VM, отображает виртуальные машины на логические устройства. Эти логические устройства должны быть созданы на соответствующих устройствах хранения и отображены на серверы, указанные в выходных данных плана Storage-VM (устройство хранения на виртуальную машину).
Рисунок 3. Блок-схема отображения Storage-VM
Подробности алгоритма
Предполагается, что администратор имеет приведенные ниже исходные данные для алгоритма.
Исходные данные
Список серверов
Каждый сервер характеризуется количеством ядер процессора, сокетов, памяти и т.д.
Тип пользователя
Каждая группа пользователей имеет свои требования к оборудованию. Как правило, в организации есть три типа пользователей:
- Пользователи Power. Это те, кто предъявляет максимальные требования к ресурсам (процессор, память) - например, разработчики.
- Пользователи Knowledge. Это те, кто в своей повседневной деятельности предъявляет средние требования к ресурсам - например, тестировщики.
- Пользователи Task. Это те, кто в повседневной работе не имеет слишком высоких требований к ресурсам - например, менеджеры.
Список "золотых образов"
Этот список содержит информацию о количестве и типах пользователей каждого "золотого образа". В каждой организации есть различные проекты и наборы ПО и оборудования для каждого из них. Каждый проект имеет собственные требования к памяти и типам пользователей (Power, Knowledge или Task). Например, организация имеет два "золотых образа" (проекта) следующих конфигураций:
- Проекту Golden Image 1 требуются 5 пользователей Power, 3 пользователя Knowledge и 1 пользователь Task.
- Проекту Golden Image 2 требуются 4 пользователя Power, 0 пользователей Knowledge и 1 пользователь Task.
Список устройств хранения
Каждая запись содержит информацию об общем размере памяти, доступной на данном устройстве.
Алгоритм использует коэффициент (ratio) и пропорцию для отображения пользователей на серверы.
План Server-VM
- Инициализация
- Задать количество ядер процессора и памяти на каждом сервере.
- Установить переменные TotalAvailableCore и TotalAvailableMemory, суммируя ядра и память из списка серверов.
- Задать число пользователей на каждом сервере равным нулю.
- Просмотреть список "золотых образов" и подсчитать общее число пользователей Power (totalPUsers), Knowledge (totalKUsers) и Task (totalTUsers).
- Отсортировать список серверов в порядке убывания числа ядер, доступных для распределения ресурсов. Это необходимо для распределения нагрузки.
- Создать переменную status (см. листинг 1) и для всех типов пользователей присвоить ей значение unallocated. Эта переменная будет проверяться в процессе выполнения алгоритма, чтобы гарантировать отображение на серверы всех пользователей.
Листинг 1. Фрагмент кода назначения переменной status
status.setPUnallocated(totalPUsers); status.setKUnallocated(totalKUsers); status.setTUnallocated(totalTUsers);
- Выполнить первоначальную проверку (см. листинг 2). Этот шаг позволяет убедиться, что общие ресурсы серверов превышают ресурсы, необходимые для отображения пользователей на системы.
Листинг 2. Фрагмент кода первоначальной проверки
performInitialValidation()
{
tCoresRequired = totalTUsers * coreTUsage
kCoresRequired = totalKUsers * coreKUsage
pCoresRequired = totalPUsers * corePUsage
totalCoresRequired = tCoresRequired + kCoresRequired + pCoresRequired;
tMemoryRequired = totalTUsers * memoryTUsage
kMemoryRequired = totalKUsers * memoryKUsage
pMemoryRequired = totalPUsers * memoryPUsage
totalMemoryRequired = tMemoryRequired + kMemoryRequired + pMemoryRequired;
If(totalAvailableMemory >= totalMemoryRequired && totalAvailableCores >=
totalCoresRequired)
Перейти на шаг 6 (описан ниже);
else
Вывести сообщение "недостаточно ресурсов";
}Здесь:
- coreTUsage, coreKUsage, corePUsage - это число ядер, необходимое для пользователей Task, Knowledge и Power соответственно;
- memoryTUsage, memoryKUsage и memoryPUsage - это количество памяти, необходимое для пользователей Task, Knowledge и Power соответственно.
- Вычислить ratio (коэффициент). Данный модуль пытается во время отображения распределить нагрузку, сбалансировать "золотые образы" (GI) и оптимизировать базовую виртуальную машину в долях переменной divisor. Если всех пользователей можно распределить на все серверы в долях divisor (divisor - конфигурируемая переменная, которую администратор устанавливает в зависимости от потребностей), этот модуль возвращает true. Тем самым гарантируется одновременное отображение на сервер только данного множества пользователей. Это позволяет оптимизировать клонирование GI и гарантировать, что таких образов будет не слишком много.
- Добавить образы на серверы и установить соответствующие значения Power, Knowledge и Тask в ноль; также установить в ноль значение необходимой серверу памяти.
- Просмотреть все GI, распределяемые на серверы в соответствии с ratio.
Листинг 3. Фрагмент кода назначения оставшихся пользователей
for(k = 0;k<goldenImageList.size();k++) { pUsersRemaining = goldenImageList.get(k).getPUserCount(); kUsersRemaining = goldenImageList.get(k).getKUserCount(); tUsersRemaining = goldenImageList.get(k).getTUserCount();- Вычислить доли пользователей Power, Knowledge и Task, распределяемых одновременно.
Листинг 4. Фрагмент кода инициализации доли divisor для каждого типа пользователей
pUnit = pUsersRemaining / divisor ; kUnit = kUsersRemaining / divisor ; tUnit = tUsersRemaining / divisor totalUsersUnit = 128 / divisor; //максимальное число пользователей сервера = 128 - Вычислить pratio, tratio и kratio:
Просмотреть список серверов.
{- pratio на i-ом сервере = (ядер на i-ом сервере/всего ядер) * (pUnit)
- Если ratio больше числа оставшихся пользователей Power:
pratio на i-ом сервере и Golden Image k = pUnit-(GiPCount/divisor); - Если доля divisor не может быть распределена:
pratio на i-ом сервере и Golden Image k = 0; - Если общее число пользователей на данном сервере больше 128:
pratio = totalUsersUnit - число пользователей на i-ом сервере; - // Проверить возможность размещения pratio на данном сервере
// Величина приращения равна 0.1, поскольку pratio вычисляется с точностью
// до одного десятичного знака
for (j =1 ;j <= pratio на i-ом сервере и Golden Image k ;j = j + 0.1)
{
Вычислить фактическое число pusers,
которое можно разместить на i-ом сервере
} - Если размещение невозможно:
pratio = 0
иначе
pratio = числу пользователей, которое нельзя разместить. - Обновить информацию сервера: уменьшить ресурсы процессора и памяти и увеличить количество внешней памяти в зависимости от pratio.
- Изменить число пользователей Golden Image, которое можно распределить на этот сервер.
- Выполнить те же действия для пользователей Knowledge и Task.
- Отобразить нераспределенных пользователей:
- Указать число пользователей, которые не были распределены в соответствии с ratio (выполнить для пользователей p, k и t).
pUnallocated+=pUnit - (GiPCount /divisor);
- Пройти по отсортированному методом пузырька списку серверов и отобразить оставшихся пользователей Power, Knowledge и Task на данный GI, основываясь на divisor.
- Указать число пользователей, которые не были распределены в соответствии с ratio (выполнить для пользователей p, k и t).
- Вывести предупреждение, если какой-либо пользователь не может быть распределен ни на один сервер.
} // Конец шага b
- Вычислить доли пользователей Power, Knowledge и Task, распределяемых одновременно.
- Проверить переменную status. Если какой-либо пользователь остался нераспределенным, вывести предупреждение "недостаточно ресурсов". В противном случае перейти к плану Storage-VM.
План Storage-VM
Исходные данные
В качестве исходных данных для списка устройств хранения используется план Server-VM, сгенерированный в результате выполнения приведенного выше алгоритма.
- Задать TotalStorage, суммируя объем доступной памяти из storageList. Создать переменную status и для всех типов пользователей присвоить ей значение unallocated. Эта переменная будет проверяться в процессе выполнения алгоритма, чтобы гарантировать отображение на серверы всех пользователей (см. листинг 1).
- Выполнить первоначальную проверку. Проверить, не превышает ли память, необходимая для всех виртуальных машин, общий объем доступной внешней памяти.
- Вычислить Storage Ratio (коэффициент устройства хранения). Здесь вычисляется число пользователей Power, Knowledge и Task, распределяемое на каждое устройство хранения согласно доступной памяти.
- Просмотреть StorageList.
For i = 0 to StorageList size- Вычислить ratio для пользователей Power, Knowledge и Task на данном устройстве хранения.
- Просмотреть StorageList.
Листинг 5. Фрагмент кода инициализации ratio на устройствах хранения
pratio устройства i = объем i/общий объем * totalPUsers
kratio устройства i = объем i/общий объем * totalKUsers
tratio устройства i = объем i/общий объемy * totalTUsers- Округлить вычисленные ratio и проверить, можно ли распределить пользователей на устройство хранения.
Листинг 6. Фрагмент кода проверки распределения ratio
For (j = 1; j <= Storage (i).getPCount (); j++)
{
if((j * PUserStorageRequired) <= Storage i.getAvailableStorage())
{
// продолжить;
}
else
{
Storage(i).PCount = (j - 1);
break;
}
}// Конец for j- Обновить: доступную внешнюю память на i-ом сервере и переменную status для отображенных пользователей p.
- Повторить те же действия для пользователей Knowledge и Task.
//Конец шага a
- Отобразить нераспределенных пользователей: Проверить переменную status для нераспределенных пользователей. Если таковые имеются, отсортировать список устройств хранения в порядке убывания доступной памяти и отобразить на них пользователей.
- Отобразить VM2Lun. Если какой-либо пользователь все-таки остался нераспределенным, вывести предупреждение "недостаточно ресурсов". В противном случае создать логические устройства и отобразить на них виртуальную машину.
- Просмотреть serverVMMap и выполнить итерацию по каждому GI, который должен быть отображен на этот сервер.
- Задать pRemaining = числу пользователей p для GI, который должен быть распределен на сервер (i).
- Задать объем логического устройства и число пользователей на этом устройстве равными нулю.
- For p = 1 to p<= pRemaining:
- Увеличить объем логического устройства для pUser, которые могу быть размещены, принимая во внимание приведенные ниже соображения.
- Объем логического устройства меньше 500 ГБ.
- Число пользователей на логическом устройстве не превышает 30.
- Число пользователей р не превышает числа пользователей, распределенных на устройство хранения на шаге 3.
- Обновить ресурсы после каждого уменьшения р.
- Если объем логического устройства = 500 или количество пользователей устройства = 30, отобразить логическое устройство на сервер и создать новое устройство.
Примечание.
Повторить те же действия для пользователей Knowledge и Task.
- Вывести планы Server-VM и Storage-VM в графическом или XML-формате.
Пример выходных данных
На рисунке 4 представлен пример выходных данных алгоритма Virtual Machine Deployment Map в XML-формате.
Входные данные: Server1 и Server2
"Золотой образ" (GI):
- GI1 имеет 20 пользователей Power, 30 пользователей Knowledge и 12 пользователей Task.
- GI2 имеет 7 пользователей Power, 1 пользователя Knowledge и 2 пользователей Task.
Устройство хранения: Storage1
Рисунок 4. Пример выходных данных алгоритма Virtual Machine Deployment Map в XML-формате

Выходные данные:
- Для Server1 нужны 2 логических устройства. На Lun1 распределены 10 P, 15 K и 7 T пользователей с GI1, а на Lun2 - 7 P, 1 K и 2 T пользователей с GI2.
- Для Server2 нужно 1 логическое устройство. На Lun3 распределены 10 P, 15 K и 5 T пользователей с GI1.
- На Storage1 создано 3 логических устройства - Lun1, Lun2 и Lun3 объемом 120, 75 и 100 ГБ соответственно.