В этой статье я хочу поделиться опытом создания инфраструктуры для интеграционного тестирования веб приложения. Приложение построено на платформе .Net и состоит из ASP.NET MVC приложения и базы данных на MSSQL
Задача интеграционного тестирования формулировалась следующим образом: автоматизировать развёртывание приложения и выполнение тестов пользовательского интерфейса, чтобы можно было быстро убедиться в том, что устанавливаемая версия приложения успешно отрабатывает все необходимые тестовые сценарии.
Другими словами надо быстро проверить, что будет, когда мы установим новую версию заказчику и начнём с ней работать. Поскольку, результат выполнения этих тестов является показателем качества создаваемого приложения, мы всегда будем знать качество нашего приложения, а значит и ситуацию в которой мы находимся.
Поскольку интеграционное тестирование позволят имитировать действия пользователя можно сказать, что оно позволят проверять факт того, что такой-то пункт ТЗ успешно выполнен. Если создать тесты для каждого пункта ТЗ (то получим программу и методику испытаний - ПМИ :) и автоматизировать их, то количество успешно выполненных тестов будет означать реальную информацию о том, на сколько процентов исполнено ТЗ. Иначе оценка состояния системы будет выглядеть следующим образом:
- Ну как у нас сегодня система, если одним словом?
- Если одним словом, то… работает.
- А если в двух словах?
- А если в двух словах, то не работает.
Что должно проверяться при таком тестировании:
- Компиляция и сборка приложения
- Процедура установки или обновления приложения:
- Установка новой или обновление существующей базы данных
- Установка нового ASP.NET приложения
- Выполнение тестовых сценариев в каждом из которых:
- Система подготавливается для выполнения сценария. Поскольку каждый сценарий имеет предусловия надо подогнать систему под эти условия. Например если для сценария надо чтобы в системе бы пользователь создавший три заказа, надо как-то получить в базе денных пользователя и три его заказа.
- Выполняется тестовый сценарий через эмуляцию действий пользователя в браузере.
- Система возвращается в состояние, которое было перед выполнением сценария, фактически в состояние сразу после установки приложения
- Составление отчёта о качестве приложения
- Сборка инсталяционного пакета, содержащего приложения с известным качеством.
Этот процесс показан на диаграмме ниже.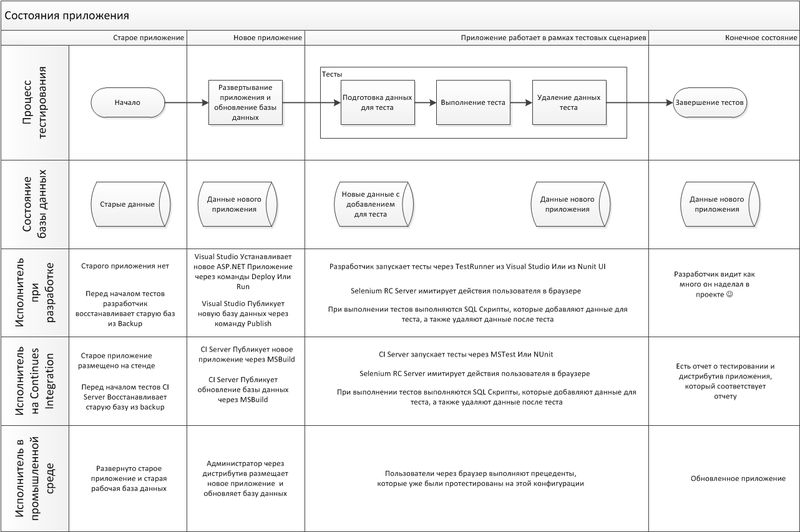
Хочу обратить внимание, что указанная схема позволяет воспроизвести на машине разработчика и на Continues Integration Server те же действия, которые будут производится на промышленной среде во время и после установки туда обновлённого приложения.
Основные конфигурации
Ниже представлено, как должны быть развёрнуты конфигурации на разных средах при интеграционном тестировании и промышленном использовании. Хочу сразу обратить внимание, что взаимодействие с приложением во всех средах происходит одинаково. Взаимодействие с приложением происходит через браузер, обновление базы данных происходит в виде выполнения скрипта обновления БД, обновление ASP.NET приложения происходит через стандартный Deployment.
Конфигурация на машине разработчика
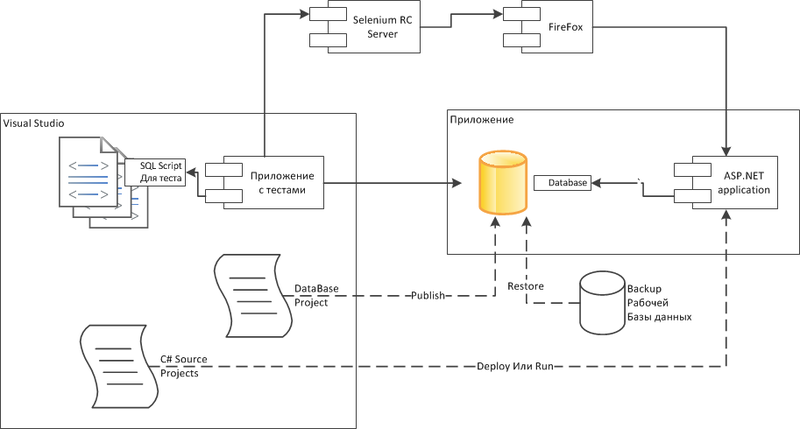
В конфигурации разработчика, в качестве основного инструмента используется Visual Studio.
В этой конфигурации предполагается использовать СУБД на машине разработчика. Я считаю этот вариант лучше варианта, когда все разработчики используют одну общую базу данных. С одной стороны общая база данных дешевле в поддержке и у каждого разработчика всегда последняя версия базы данных. Но с другой стороны в таких базах данных можно легко получить нарушение целостности данных, например можно ввести несколько неправильных заказов, потому, что разработчик забыл сделать какую-то проверку. Проверку он, конечно, потом сделает и больше неправильных заказов в системе создаваться не будет. Но другой разработчик может продолжить отлаживать свой функционал на неправильных заказах и наделать много скрытых ошибок.
В случае персональной базы данных, задача создания целостных данных становится явной и проще решаемой. Об этом написано ниже в разделе "Маленькие хитрости"
Перед интеграционным тестом разработчик должен восстановить рабочую базу данных с промышленного сервера на СУБД интеграционного тестирования. Конечно, рабочую базу получить с промышленного стенда нереально, но все равно должна быть какая-то база данных максимально близкая к ней, чтобы правильно проверить процесс обновления базы данных. В качестве варианта может быть обезличивание рабочей базы данных, то есть делается копия рабочей базы данных, а потом в ней меняются имена заказчиков и суммы контрактов, так чтобы коммерческая информация не попала к разработчикам и тестировщикам.
Первым этапом тестов будет проверка развёртывания базы, то есть разработчик будет выполнять публикацию базы данных. Для этого разработчик публикует Database Project в целевую базу данных. Во время сборки проекта Visual Studio залезет в целевую базу, сравнит её со скриптами текущего проекта и сделает разностный скрипт, который и будет выполняться. Уже здесь могут возникнуть ошибки, например, забыли создать поле, на которое ссылается вторичный ключ, или при вставке начальных данных произошёл конфликт первичных ключей. Получается, что разработчик обнаружит и исправит все эти ошибки ещё на этапе тестирования а не на этапе внедрения, думаю все знают сколько это нервов экономит.
Следующим шагом разработчик запускает тесты через Visual Studio Test Runner. Интеграционные тесты при выполнении наполняют базу данных требуемыми для теста данными, и тем самым удовлетворяют предварительным требованиям тестов, потом тест, через Selenium RC Server вызывает браузер и имитирует действия пользователя. Результат выполнения теста проверяется опять таки через браузер, так же можно получить данные из БД для сравнения с эталонными.
После выполнения теста база данных возвращается в исходное состояние.
В результате, после прогона тестов, видно общее состояние системы.
Конфигурация на сервере Continues integration
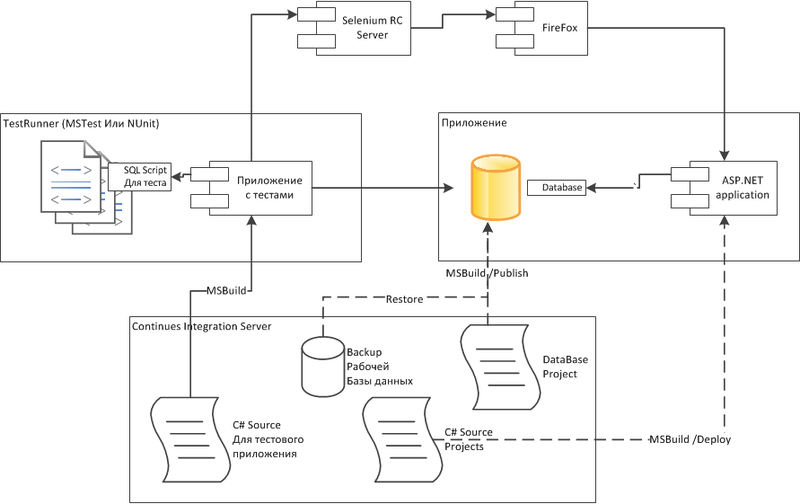
Здесь вместо Visual Studio используется Continues integration сервер, но все действия аналогичны действиям на машине разработчика
Конфигурация на промышленной среде
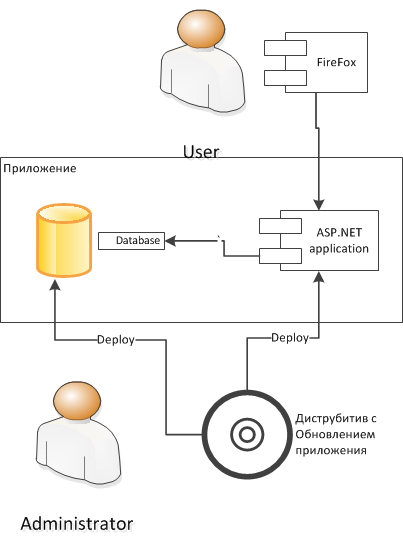
На промышленной среде обновление устанавливается через инсталятор, который работает с промышленной средой так же как это было в интеграционных тестах. Пользователи тоже работают с системой так же как это было проверено в тестах. Никаких неприятных сюрпризов уже быть не должно.
Необходимые инструменты
Для создания необходимой инфраструктуры нужны следующие инструменты:
Visual Studio Solution, который содержит несколько проектов:
- Проект "SQL Server Database Project". Как известно такой проект позволяет хранить все DDL и SQL скрипты, которые нужны чтобы разрабатывать структуру и первоначальное наполнение базы данных. Главное достоинство этого проекта в том, что он может сгеренировать разностный скрипт для обновления существующей базы данных до последней версии. Это позволяет устанавливать обновления не удаляя существующие данные. Более того эту операцию можно автоматизировать через MSBuild и выполнять на Continues Integration сервере.
- Проект с ASP.NET приложением. Содержит само приложение. Так же проект используется для того, чтобы проверять развёртывание веб приложение на сервер, опять таки автоматически с использованием MSBuild.
- Проект содержащий интеграционные тесты. Это MSTest или NUnit проект. Этот проект будет использоваться для прогона тестов и создания отчёта о тестировании.
Это минимальный набор проектов, который необходим для организации автоматизированного интеграционного тестирования.
Конечно, Solution хранится в системе контроля версий, например SVN.
Помимо этого solution содержит nuGet пакет "Selenuim Remote Contol". К сожалению Selenim IDE не полностью поддерживает новый "Selenium WebDriver", поэтому экспортировать тестовые сценарии из Selenim IDE в C# код можно только для Remote Contol. В противном случае часть шагов не будет экспортирована в C# и их придётся писать руками, что заметно медленнее чем через экспорт из Selenim IDE.
Для "Selenuim Remote Contol" нужно java приложение "selenium-server-standalone-x.x.x.jar"
Для быстрой и удобной записи тестов понадобится FireFox с установленным дополнением Selenim IDE.
Так же нужен Continues Integration сервер, для постоянного получения последней версии из SVN и выполнения тестов.
Настройка среды
Покажу как устанавливать и конфигурировать описанные выше продукты на различных стендах.
проект базы данных
Начнем с проекта базы данных. Database project может иметь несколько publish.xml файлов в каждом из которых описано куда и как будет публиковаться база данных. Поскольку база данных у каждого разработчика находится по своему адресу, эти файлы должны быть вынесены из системы контроля версий и настраиваться у каждого разработчика отдельно.
Чтобы опубликовать базу данных надо кликнуть правой кнопкой на этом файле в Visual Studio и выбрать "Publish". Публикация аналогична развёртыванию (Deploy) за исключением того, что параметры развёртывания хранятся в свойствах проекта, а параметры публикации в publish.xml.
Чтобы опубликовать БД из командной строки надо вызвать такую команду:
> MSBuild /t:Publish /p:SqlPublishProfilePath="mypublishfile.publish.xml" DBProject.sqlproj
Веб приложение
ASP.NET приложение в Visual Studio можно запускать по команде "Run" или же развёртывать стандартными средствами Visual Studio. На Continues Integration Server-е это можно сделать тоже различными способами, например, через xCopy. Я не буду останавливаться на этом подробнее, потому что это, с одной стороны достаточно большой материал, а с другой стороны его легко найти в интернете.
Selenium Server
Так же понадобится Selenium RC сервер, который можно скачать здесь: docs.seleniumhq.org/download/
Запускает сервер командой
> java -jar c:\selenium\selenium-server.jar -multiwindow
Когда сервер запущен можно прогонять тесты.
Тестовый проект с интеграционными тестами
Это может быть MSTest проект или NUnit проект.
Сначала надо установить в него nuGet пакет Selenium.RC
Как уже говорилось в начале каждого теста надо прогнать SQL скрипт, который наполнит БД данными для теста. Поскольку я часто работаю со скриптам созданными в SQL Server Management Studio, то в них постоянно встречается команда "GO". Чтобы выполнять такие скрипты используется библиотека smo, это несколько сборок, которые можно установить в составе MSSQL Server SDK и найти например в "C:\Program Files (x86)\Microsoft SQL Server\110\SDK\Assemblies", но надо учесть, что они собраны для .Net 2.0 и просто так заставить их работать в .Net 4.0 и старше не получиться. Поэтому тестовое приложение, я обычно конфигурирую для .Net 3.5
После этого можно сделать такой вспомогательный класс, в тестовом проекте:
public class TestDBHelper { public static void ExecScript(String scriptName) { string sqlConnectionString = System.Configuration.ConfigurationManager.ConnectionStrings["TestDBConnection"].ConnectionString; FileInfo file = new FileInfo(Path.Combine("SQL", scriptName)); string script = file.OpenText().ReadToEnd(); SqlConnection conn = new SqlConnection(sqlConnectionString); Server server = new Server(new ServerConnection(conn)); server.ConnectionContext.ExecuteNonQuery(script); } public static void BackupBeforeTest() { TestDBHelper.ExecScript("BackupBeforeTest.sql"); } public static void RestoreAfterTest() { TestDBHelper.ExecScript("RestoreAfterTest.sql"); } }
Все SQL скрипты лежат у меня в этом же тестовом проекте в папке "SQL", и для каждого скрипта свойство "Copy to Output directory" выставлено в "Copy if newer"
Что находится в скриптах "BackupBeforeTest.sql" и "RestoreAfterTest.sql" написано ниже.
В результате тест выглядит примерно следующим образом:
[TestClass] public class SimpleTest { private ISelenium selenium; private StringBuilder verificationErrors; [TestInitialize] public void Init() { TestDBHelper.BackupBeforeTest(); TestDBHelper.ExecScript("CreateTestUser.sql"); selenium = new DefaultSelenium("localhost", 4444, "*chrome", "http://localhost:12945/"); selenium.Start(); verificationErrors = new StringBuilder(); } [TestCleanup] public void CleanUp() { selenium.Stop(); TestDBHelper.RestoreAfterTest(); } [TestMethod] public void TestLogin() { if (selenium.IsElementPresent("link=Тестовый пользователь [Выход]")) { selenium.Click("link=Тестовый пользователь [Выход]"); selenium.WaitForPageToLoad("30000"); } selenium.Open("/"); selenium.Click("link=Вход"); selenium.WaitForPageToLoad("30000"); selenium.Type("id=UserName", "TestUser"); selenium.Type("id=Password", "123456"); selenium.Click("css=input.btn"); selenium.WaitForPageToLoad("30000"); Assert.IsFalse(selenium.IsElementPresent("css=div.validation-summary-errors > ul > li"), "Пользователь не найден"); Assert.IsTrue(selenium.IsElementPresent("link=Тестовый пользователь [Выход]"), "Нет кнопки выхода"); } }
Этот простой тест проверяет вход пользователя в систему.
Перед выполнением теста делается Backup базы данных и выполняется скрипт "CreateTestUser.sql", который как раз и создаёт пользователя с необходимыми параметрами.
После выполнения теста делается восстановление БД из backup-а, чтобы очистить базу данных от оставшихся после теста данных.
К сожалению не получается полностью изолировать друг от друга интеграционные тесты, в частности средствами Seleniun нельзя удалить "ASP.NET_Session" cookie из бразузера, потому что она помечена как HTTPOnly. Из-за этого приходится проверять остался пользователь залогинен с прошлого теста или нет, и если остался то приходится имитировать выход пользователя из системы, и таким образом сбрасывать состояние сессии.
Остальной ход теста достаточно очевиден. Вводится логин и пароль и проверяется, что сообщения об ошибке нет, и появилась ссылка для выхода из системы. Как написать такой тест с помощью Selenium IDE смотри ниже.
FireFox и Selenium IDE. Создание тестов
Selenium позволяет прогонять тесты на многих браузерах, но для быстрого создания надо использовать FireFox с установленным дополнением "Selenium IDE".
Чем же так хороша эта "Selenium IDE"?
Во-первых она очень удобна для быстрого написания тестов. Можно включить режим записи и начать работу с веб приложением, а selenium запишет все ваши действия. Но сразу скажу, что в случае AJAX приложения это не получиться потому что надо постоянно дожидаться ответа сервера, а это "Selenium IDE" автоматически не делает. Тем не менее даже в этом случае можно в процесс теста добавить такое ожидание.
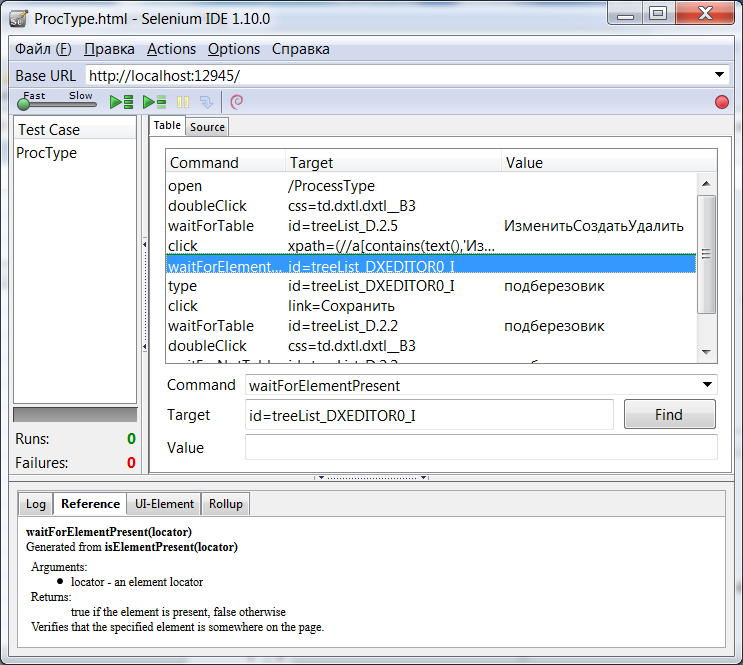
На рисунке показан примет теста, который проверят изменение записи в справочнике. Эта страница реализована с помощью DevExpress MVC Extension и содержит много AJAX кода поэтому добавлены шаги вроде "WaitFor...", которые как раз и ожидают появления в браузере необходимых обновлений.
Так же большим достоинством является то, что тест можно быстро отлаживать через "Selenium IDE". Достаточно нажать кнопку "Run Test" и проверить, что все работает.
После того как тест отлажен его можно сохранить в c# файл, командой "Export Test Sute As" / "C# / NUnit / Remote Control", и скопировать содержимое тестовых методов в тестовый проект. Все это значительно повышает скорость создания тестов по сравнению с вариантом, когда вы сразу пишете тест в C#, и отлаживаете его прогоняя через MSTest или NUnit.
А самым замечательным свойством "Selenium IDE" я считаю тот факт, что эти тесты могут писать тестировщики для своих целей и если какой-то тест очень важен, то его можно передать разработчикам и они добавят его в список интеграционных тестов. В результате получается, что тестировщики помогают писать тесты, хотя конечно не стоит забывать, что тестировщики не могут писать SQL скрипты, которые подготовят базу данных для теста, а это существенная часть теста.
Маленькие хитрости
Создание и загрузка данных теста в БД
Данные для теста нужны что бы привести систему к состоянию описанному в предусловии к тесту. Например, должен быть покупатель разместивший три заказа. Легче всего создать покупателя и заказы через пользовательский интерфейс. Дальше надо выгрузить данные из требуемых таблиц в SQL скрипты в виде SQL Dump-а. И этот скрипт потом использовать при прогоне теста.
Пример такого скрипта:
SET IDENTITY_INSERT [dbo].[User] ON INSERT [dbo].[User] ([UserId], [Login], [Password], [DisplayName]) VALUES (1000001, N'TestUser', N'7dHZDOYgwADlGdinx9u/c4Cmhtc=', N'Тестовый пользователь') SET IDENTITY_INSERT [dbo].[User] OFF SET IDENTITY_INSERT [dbo].[Order] ON INSERT [dbo].[Order] ([OrderId], [UserId], [Description], [Price]) VALUES (1000001, 1000001, N'Заказ №1', 100.0) INSERT [dbo].[Order] ([OrderId], [UserId], [Description], [Price]) VALUES (1000002, 1000001, N'Заказ №2', 200.0) INSERT [dbo].[Order] ([OrderId], [UserId], [Description], [Price]) VALUES (1000003, 1000001, N'Заказ №3', 300.0) SET IDENTITY_INSERT [dbo].[Order] OFF
Данный скрипт можно получить через программы вроде "SQL Dumper" или через SQL Server Management Studio, у которого есть хороший мастер для генерации скриптов по объектам БД, включая данные таблиц.
-[Управление идентификаторами записей в БД]-
Думаю вы уже обратили внимание, что идентификаторы, в скриптах создания данных, начинаются с 1000000, а не с 1.
Это связано с тем, что когда у вас есть боевая база данных, то наверняка идентификаторы со малыми значениями уже использованы и если попытаться вставлять эти значения в через скрипт, то получим нарушение уникальности идентификаторов.
Чтобы этого избежать надо в разработческих и тестовых базах данных сразу поставить начальное значение для генератора идентификаторов в миллион или даже в миллиард.
Очистка базы данных после теста
Самым простым и эффективным способом могло бы быть использование транзакций, но в нашей конфигурации тест и приложение выполняются в разных процессах и не получается легко использовать одну транзакции в обоих процессах.
Тем не менее можно использовать простой и быстрый механизм DataBase backup-ов. Но надо помнить, что создание и восстановление обычного backup-а сравнительно долгий процесс, зато есть Snapshot backup-ом, он как раз и создан для быстрого создания и восстановления базы данных.
поэтому перед каждым тестом я создаю backup скриптом из файла "BackupBeforeTest.sql"
USE [master] GO IF EXISTS (SELECT name FROM sys.databases WHERE name = N'MyDataBase_Spanpshot') DROP DATABASE MyDataBase_Spanpshot GO CREATE DATABASE MyDataBase_Spanpshot ON (NAME = 'DataBase_data_File', FILENAME = 'C:\MyDataBase_TestBU.SNP') AS SNAPSHOT OF MyDataBase;
а после теста восстанавливаю следующим скриптом из "RestoreAfterTest.sql":
USE master; DECLARE @DatabaseName nvarchar(50) SET @DatabaseName = N'MyDataBase' DECLARE @SQL varchar(max) SELECT @SQL = COALESCE(@SQL,'') + ' BEGIN TRY Kill ' + Convert(varchar, SPId) + '; END TRY BEGIN CATCH END CATCH;' FROM MASTER..SysProcesses WHERE DBId = DB_ID(@DatabaseName) AND SPId <> @@SPId EXEC(@SQL) RESTORE DATABASE MyDataBase_Spanpshot from DATABASE_SNAPSHOT = 'MyDataBase_Spanpshot'; GO IF EXISTS (SELECT name FROM sys.databases WHERE name = N'MyDataBase_Spanpshot') DROP DATABASE MyDataBase_Spanpshot GO
Как видно перед восстановлением надо отключить всех пользователей, которые остались подключены после выполнение теста. Иначе не получиться восстановить базу данных.
Организация SQL скриптов для инкрементного наполнения БД перед тестом
Я несколько раз упоминал, что перед выполнением скрипта надо подготовить базу данных для него. Но если копнуть поглубже, то будет видно, что эти скрипты имеют зависимости друг от друга.
Начнём с нулевого уровня: справочные данные создаются ещё в рамках первоначального развёртывания базы данных, на эти справочные данные ссылаются многие сущности в системе. Дальше идут пользователи, на них тоже много кто ссылается. В качестве дальнейших примеров, можно взять каталог товаров, и заказы, которые ссылаются на товары, пользователей и справочники.
Очевидно, что подготавливая тестовые данные для заказа разумно воспользоваться уже существующими данным для создания пользователей и каталога товаров, это как минимум сэкономит время.
Но на самом деле здесь есть ещё больше достоинств. Вспомним пример, который я упоминал выше, когда один разработчик, например работающий над каталогом товаров, забыл реализовать какое-то правило, и насоздавал несколько неправильных данных, в том числе и тестовых. Другой разработчик, который занимается заказами, сделал свой код используя неправильные данные о товарах.
В случае зависимых тестовых данных, как только первый разработчик поправит свой код и свои тестовые данные, у второго разработчика упадут его тесты, если для них важно это правило. Таким образом, первый разработчик, отлаживая тестовые данные для каталога товаром, на самом деле ещё и отлаживает тестовые данные для заказов, тем самым ошибки в заказах обнаруживаются быстрее.
Этот принцип работает и в другую сторону. Если разработчику заказов понадобились новые тестовые данные для товаров, которых ещё нет, то он должен сам подготовить для себя такие данные и прогнать свой тест заказа на этом новом товаре. Но это так же значит, что этот новый товар должен успешно пройти все тесты, связанные с каталогом товаров. Если какой-то тест, в каталоге товаров, не проходит с новым товаром, это значит, что разработчик заказа обнаружил ошибку в коде разработчика каталога товаров. Опять, таки получается, что ошибки в каталоге товаров обнаруживаются раньше, по сравнению с тем случаем, когда каждый разработчик готовит себе все тестовые данные.
Заключение
Описанный способ организации автоматизированного интеграционного тестирования, позволяет автоматически оценивать качество создаваемого Веб приложения на всем этапе разработки, а не только на этапе стабилизации. Чем раньше обнаружены ошибки, тем дешевле их исправить, а главное сразу, а не только на стабилизации, виден объем оставшихся работ, что позволяет менеджерам проектов точнее планировать работы.
Конечно, поддержание описанной инфраструктуры требует определённых затрат, но я считаю, то эти затраты окупаются за счёт меньших затрат на ручное тестирование.