1. Примерный алгоритм определения релевантности документа запросу.
Довольно часто, особенно от людей, недавно занявшихся поисковой оптимизацией, приходится слышать просьбу раскрыть "волшебную формулу", с помощью которой можно добиться хороших позиций в поисковых системах. Как частный случай можно привести также вопрос о плотности ключевых слов на странице (с точностью до сотых долей процента), необходимый для попадания на первые строчки выдачи. Сразу же хочу предупредить вас - таких формул и магических цифр нет.
Не правы и те, кто считает алгоритмы поисковых систем абсолютно недоступными "простым смертным". Да, действительно, эти алгоритмы никогда не будут раскрыты во всех тонкостях, потому как слишком много желающих делать "идеальные" странички и занимать первые места в поисковиках, зачастую ухудшая тем самым качество поиска, т.е. выдаваемой пользователю информации.
Однако, основные принципы работы алгоритмов ранжирования документов всё же известны, и прежде чем начать рассказывать о каждом из факторов, оказывающем влияние на релевантность документов запросам, мне хотелось бы ознакомить вас с обобщенной формулой, аппроксимирующей формулы ранжирования, используемые четверкой наиболее популярных в Рунете поисковых машин (Яндекс, Рамблер, Апорт и Google). Повторяю, что это не есть конкретная формула, используемая в поисковых машинах, это лишь сильно укрупненная формула, приближенно описывающая процесс определения релевантности документа запросу. Вот она:
где:
Rа(x) - итоговое соответствие документа а запросу x,
Tа(x) - релевантность текста (кода) документа а запросу x,
Lа(x) - релевантность текста ссылок с других документов на документ а запросу x,
PRа - показатель авторитетности страницы а, константа относительно х,
F(PRa) - монотонно неубывающая функция, причем F(0)=1, можно допустить, что F(PRa) = (1+q*PRа),
m, p, q - некие коэффициенты.
Конечно же, эта формула даёт очень общее представление об алгоритмах ранжирования документов в результатах поиска и даже может вызвать недоумённый вопрос - "почему же, если все поисковики пользуются подобным алгоритмом, результаты в них зачастую сильно различаются?". Как говорится, "дело в деталях". Любой из этих показателей является функцией от других, которые могут учитываться или нет поисковой системой, причём каждый из этих показателей имеет свой "вес", а точнее коэффициент, различный для каждого конкретного поисковика. Также влияние могут оказывать собственные ресурсы поисковых систем, прежде всего их каталоги.
Обо всём этом мы и будем говорить далее, а сейчас хочу обратить внимание лишь на то, что итоговое положение сайта в результатах поиска зависит от 3-х основных составляющих:
- Релевантность кода страницы запросу Tа(x);
- Релевантность запросу ссылок на страницу с других страниц (или ссылочное ранжирование) Lа(x);
- Показатель авторитетности страницы PRа - коэффициент, не зависящий от поискового запроса и оказывающий влияние на эффект от обеих предыдущих составляющих.
Вот с этого "показателя авторитетности" мы и начнём более подробно рассматривать факторы, влияющие на релевантность документов запросам.
2. Факторы, не зависящие от запроса (статические).
Если выразиться точнее - фактор, который в общем случае имеет название показатель авторитетности или ранг документа. В нашей формуле он обозначается как PRa. В рассматриваемых поисковых машинах он именуется по-разному, однако все они при его расчете используют алгоритмы, учитывающие гиперссылки между документами. Эти алгоритмы являются, по сути, модификациями алгоритма PageRank, придуманного в свое время двумя американскими аспирантами Сергеем Брином и Ларри Пейджем, основавшими в последствии поисковую машину Google.
PageRank в Google
С ростом объёма информации в интернете вообще и информации, индексируемой поисковыми системами в частности, перед разработчиками поисковиков встала серьёзная проблема - количество одинаково релевантных запросу документов было велико, и корректно ранжировать их в результатах поиска становилось всё сложнее. К тому же алгоритмы ранжирования, разработанные для контролируемых коллекций документов, оказались беззащитны перед простейшими способами воздействия на них, когда для обеспечения хорошего результата достаточно было просто скопировать структуру расположения ключевых слов из текста хорошо ранжируемого по этому запросу документа. Появилась необходимость разделять информацию на более и менее достоверную, учитывать "важность" или "авторитетность" ресурсов, предоставляющих её. Как это сделать? Лучше всего на основе данных о популярности страницы у пользователей, например посещаемости. Но тогда потребуется устанавливать какой-либо счётчик на каждую страницу. Такой вариант для глобального поиска не подходит. Тогда в качестве критерия была выбрана теоретическая посещаемость страницы.
Была разработана модель, эмулирующая движение пользователя по документам сети путем перехода по ссылкам с документа на документ, подразумевающая, что пользователь с равной долей вероятности перейдет по любой из ссылок, содержащихся в документе, который он в данный момент просматривает. Следовательно, вероятность пользователя попасть на конкретный документ будет зависит от количества ссылок на него с других документов и от того, насколько вероятно нахождение пользователя на одном из ссылающихся документов и сколько исходящих ссылок содержит этот ссылающийся документ. Эта вероятность и была принята за показатель авторитетности или ранг страницы (PageRank):
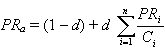
где
PRa - PageRank рассматриваемой страницы,
d - коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не прекратит путешествие по сети, обычно устанавливается равным 0,85),
PRi - PageRank i-й страницы, ссылающейся на страницу а,
Ci - общее число ссылок на i-й странице.
Одним из распространенных заблуждение является то, что можно вычислить PageRank по этой формуле для отдельно взятого документа, используя известные значения PageRank для ссылающихся на него документов. Так делать нельзя. Чтобы вычислить PageRank какого-либо документа надо составить систему N линейных уравнений данного вида для каждого из документа из поисковой базы, где N - количество документов в поисковой базе. Причем, для выполнения условия, что сумма значений PageRank для всех документов (т.е. вероятность того, что пользователь находится на любой из страниц) равна 1, к свободный члену (1 - d) в каждом уравнении добавляют множитель 1/N. Эта система будет содержать N неизвестных. Решив ее, получим значения PageRank для каждого документа, известного поисковой машине. В поисковой базе крупнейших поисковых машин содержится огромное количество документов. Несмотря на то, что матрица, соответствующая системе уравнений будет сильно разрежена, численное решение этой системы требует огромных вычислительных мощностей. Поэтому поисковая система должна постараться максимально упростить процесс расчета, вводя некоторые допущения. Вот эти конкретные особенности реализации классической формулы PageRank, увы, составляют коммерческую тайну поисковых машин.
Нормированное значение PageRank для конкретного документа, загруженного в браузер, можно узнать, скачав и установив Google ToolBar - специальную панель инструментов для работы с этим поисковиком.
ВИЦ в Яндексе
В Яндексе аналогичная PageRank величина, обозначающая количественное представление "авторитетности" страницы и называемая "взвешенный индекс цитирования" - ВИЦ, была введена весной 2001 года. Как говорили сами представители Яндекса, ВИЦ высчитывается на основе классического алгоритма PageRank "с точностью до деталей реализации".
До осени 2002 года ВИЦ можно было посмотреть с помощью Яндекс-Бара, специальной панели инструментов. В нем отражался ВИЦ главной страницы с точностью до сотых. Теперь в этом индикаторе отображается значение тИЦ, совсем другого показателя, использующегося для ранжирования ресурсов в каталоге Яндекса, и узнать значение ВИЦ не представляется возможным.
ИЦ в Апорте
Апорт в 1999 г. первым из отечественных поисковых систем стал использовать для ранжирования документов модификацию классического алгоритма PageRank. Показатель авторитетности документа имеет название "Индекс Цитирования" - ИЦ (также представители Апорта называют его в своих документах как Page Rank, так и взвешенный индекс цитирования). Самым кардинальным отличием от классического PageRank в Апорте является то, что пре расчёте ИЦ документа им учитывается всего одна, "лучшая" ссылка со всех страниц домена второго уровня. "Лучшей" считается та ссылка, которая передаёт наибольший вес документу.
Индексом цитирования сайта (он же Site Rank), использующегося для ранжирования сайтов в каталоге Апорта, считается наибольший индекс цитирования из всех страниц сайта. Значение ИЦ можно узнать только для сайтов, зарегистрированных в каталоге, в соответствующей ему категории.
Коэффициент популярности в Рамблере.
С осени 2002 года поисковая машина стала рассчитывать для каждого документа коэффициент популярности. Вот что сказано на сайте Рамблера об этом коэффициенте: "Данный коэффициент, как и алгоритм PageRank, основан на учете гиперссылок между страницами сети, однако наша реализация дополнительно использует данные о реальной посещаемости страниц, полученные от счетчика Top100. Дело в том, что "классические" ссылочные алгоритмы фактически учитывают мнение только одной категории пользователей сети - web-мастеров. Действительно, если большому количеству web-мастеров нравится тот или иной ресурс, они размещают на него ссылки. Обычные пользователи, как правило, созданием страниц и сайтов не занимаются, и поэтому учесть их мнение оказывается невозможно. Счетчик Top100 как раз и предназначен для того, чтобы сделать коэффициент популярности более справедливым".
Однако, судя по всему, в последнее время данные о посещаемости документов, полученные от счетчика Top100, оказывают все меньшее и меньшее влияние на коэффициент популярности, так как счетчик не в состоянии противостоять массовым накруткам, практикуемым владельцами некоторых сайтов. Соответственно, все большее значение приобретает составляющая, вычисляемая на основе учета гиперссылок между страницами сети.
Необходимо, заметить, что некоторые документы и даже целые сайты в поисковых машинах могут по той или иной причине исключаться из процесса расчета ранга документа, на который они ссылаются. Так, например, в Яндексе для этих целей существует так называемый "непот-фильтр", который накладывается на ресурсы, находящиеся на бесплатных хостингах, но не описанные в Яндекс-каталоге, ресурсы со свободным размещением ссылок (например, гостевые книги, доски объявлений), сайты, размещающие на своих страницах ссылки, невидимые пользователю и т.п.
Резюмируя вышесказанное, можно сказать, что для повышения ранга страницы необходимо работать над тем, чтобы как можно большее количество документов сети ссылалось на него. Делать это можно различными способами - с помощью обмена ссылками с другими сайтами, регистраций в каталогах и различных тематических ресурсах и т.д. Идеальный способ - сделать свой сайт настолько уникальным и интересным, чтобы владельцы других ресурсов сами считали необходимым поставить ссылку на него. Не следует также забывать, что при расчете ранга документа учитываются как внешние, так и внутренние ссылки. Поэтому грамотная перелинковка документов внутри сайта позволяет повысить ранг самых важных из них с точки зрения содержащейся информации. Наиболее важные в этом смысле документы обязательно должны иметь ссылку с главной страницы сайта, которая, как правило, имеет максимальный ранг среди всех страниц сайта вследствие того, что на нее указывает большинство внешних ссылок на сайт.
3. Факторы, зависящие от запроса (динамические).
Внутренние динамические факторы.
Внутренние динамические факторы (в нашей формуле они используются при вычислении составляющей Tа(x)) гораздо более легки в понимании, чем показатели авторитетности, хотя бы потому, что доступны для просмотра любому пользователю. Они легко могут быть изменены владельцем ресурса с целью достижения нужных позиций в результатах поиска. Именно поэтому в настоящее время соответствие кода страницы запросу является, пожалуй, наименее слабым фактором в алгоритмах ранжирования поисковых систем, и достичь хороших результатов в ранжировании по серьезным запросам, основываясь только на работе с внутренними факторами, практически невозможно.
Я не случайно сказал именно "кода страницы" потому, что помимо собственно текста к внутренним факторам относятся также элементы форматирования текста и служебные тэги. Итак, по порядку.
Непосредственно текст страницы оценивается поисковой системой по двум основным характеристикам: расположение искомого текста на странице и частота встречаемости слова из запроса в документе по сравнению с другими словами. Что касается расположения текста на странице, то больший вес имеют слова, расположенные ближе к началу документа и предложения. Ведь считается, что в начале чаще располагается важная информация. Также особенно ценится поисковиками "точное вхождение" искомой фразы в текст документа для запросов из нескольких слов, т.е. текст, идентичный запросу, с сохранением порядка слов в запросе. В этой связи хочется отметить вот ещё что. Несмотря на то, что поиск по стоп-словам, к которым относятся, в основном, предлоги, союзы, частицы и междометия, не производится, при ранжировании документов они всё же используются, что может очень серьёзно повлиять на выдачу. Сравните запросы из 2-х слов с союзом "и" между ними, например "бумага и картон" и "бумага картон".
Тоже можно сказать и о морфологии запроса, предпочтительно, чтобы слова из запроса в тексте были в той же форме, что и в самом запросе. Особенно это касается Рамблера. Для Google это имеет принципиальное значение, так как русской морфологии он не поддерживает.
Кстати, у Рамблера есть ещё одна интересная особенность - этот поисковик считает знаки пунктуации словами. Запятая между двумя словами становится третьим словом.
Относительно частоты употребления слов в документе сказано немало. Часто от новичков приходится слышать вопрос об "идеальной" плотности ключевых слов с точностью до сотых процента. Существуют рекомендации об использовании ключевого слова на странице в пределах 3-7%. Однако, точные цифры не известны. Считается что, страница со слишком часто встречающимся словом запроса может посчитаться спамом, и ее позиция в результатах поиска может быть автоматически понижена. Это утверждение довольно спорно. Ведь если на странице всего 3 слова и запрос содержит эти же 3, то плотность составит 100% - однако такие страницы прекрасно находятся в поиске. Гораздо более вероятно, что существуют некие пороговые значения, после достижения которых дальнейшее увеличение частоты не влияет на релевантность документа. Представители Апорта, например, определенно говорили о наличии в их поисковой системе подобного порогового значения. Лично я при употреблении слов на странице руководствуюсь, прежде всего, понятием разумности - пользователю должно быть удобно читать текст - и ни разу не высчитывал эту величину для своих сайтов и сайтов конкурентов.
Кстати, не следует забывать и о том, что поисковые машины накладывают ограничения на индексируемый объем документа. Так, Google индексирует только первые 101 килобайт, Рамблер - 200 килобат, Апорт - 128 килобайт. По Яндексу у меня такой информации, к сожалению, нет, но, я думаю, что и у него имеется ограничение на индексируемый объем документа примерно в пределах 100-200 килобайт.
Элементы форматирования текста. К таковым относятся заголовки(<h1>, ..., <h6>), а также тэги <strong>, <em>, <b>, <i>. Если некоторая часть текста выделяется, значит, с точки зрения поисковой системы, в этой части содержится более важная информация, следовательно, документ посвящён этой теме и более релевантен запросу, если слова из него, содержатся в выделенном тексте. Поэтому использование этих тэгов в документе желательно, но в разумных количествах. Не стоит забывать, что они используются именно для выделения в пределах одного документа, и слишком частое их использование для различных слов уже не даст такого эффекта. Если весь текст страницы представить заголовком, <h1> например, то это будет равносильно не использованию этого тэга вообще.
Добавлю, что Апортом тэги <i> и <em> игнорируются.
Служебные тэги. Ранее мета-тэги keywords и description активно использовались многими поисковыми машинами. Но в связи с тем, что их содержимое не видно пользователю, они стали действенным инструментом для обмана поисковых систем, что привело к тому, что в настоящее время эти мета-тэги либо вообще не учитываются поисковыми системами, либо влияние их мизерно по сравнению с другими факторами.
Рамблер и Google при ранжировании документов их игнорируют вообще. Однако, Google использует содержимое мета-тега description при построении сниппетов - фрагментов текста, содержащих слова из запроса, выдаваемых рядом со ссылкой на документ в результатах поиска. Апорт единственный использует мета-тег description, но, судя по всему, он имеет очень небольшой вес по сравнению с другими внутренними факторами. Из тега keywords берутся, по словам представителей Апорта, только 16 слов, причём учитывается только одно вхождение слова, даже если его нет в тексте страницы. На сайте Яндекса указано, что он учитывает первые 50 слов из тега keywords при условии что это слово присутствует в тексте страницы но, повторюсь, эффект от его использования крайне мал. Мета-тег description в расчёте релевантности страницы запросу в Яндексе не участвует, но до двухсот первых символов из него в некоторых случаях может выводиться в результатах поиска как первая часть аннотации к ссылке. Поэтому я бы рекомендовал использовать в теге description текст, описывающий краткое содержание документа - это может стать дополнительным аргументом для принятия пользователем решения перейти на ваш сайт по ссылке с результатов поиска.
Пожалуй, наибольший эффект из страничных факторов даёт применение тэга title - заголовка страницы. Причём использовать в нём можно даже слова, которые не содержатся в тексте страницы - это тоже даёт эффект, хотя и меньший, но в некоторых случаях это оправдано. К тексту внутри этого тэга применимы те же понятия, что и для текста документа вообще: больший вес имеют слова, расположенные ближе к началу, очень эффективно точное вхождение искомой фразы. Судя по информации представленной на сайтах Яндекса и Апорта, эти поисковые машины не учитывают частоту вхождения слов из запроса в этом теге, а только факт их присутствия. Следует иметь в виду, что нецелесообразно делать очень длинные теги title, так как поисковые машины могут накладывать ограничение на длину индексируемой части этого тега. Старайтесь использовать не более 20-25 слов.
Атрибут alt тега img. Необходимо упомянуть ещё об одном атрибуте, используемом некоторыми поисковыми системами при ранжировании. Это атрибут alt тэга img - текстовый комментарий к изображениям. Rambler учитывает не более 8 слов из него при ранжировании, возможно, приравнивая по значимости к тексту страницы. Этим свойством можно пользоваться при оптимизации страниц. Для Яндекса и Апорта же этот атрибут имеет значение только при поиске по картинкам, а при ранжировании документов в основном поиске не используется. Нами ставились некоторые эксперименты по продвижению через картинки сайтов и их результаты, мягко говоря, нас не удовлетворили - переходов на сайты по картинкам практически не наблюдалось. Google учитывает содержимое этого атрибута только для изображений, являющихся ссылками.
Часто приходится слышать вопросы о том, учитывается ли при ранжировании содержимое атрибута title тега а. Так вот, на данный момент, ни одной из четырех рассматриваемых в этой статье поисковых машин при ранжировании содержимое этого атрибута не учитывается.
Таким образом, общие рекомендации по оптимизации кода страницы можно свести к следующим мероприятиям:
- Постарайтесь разместить наиболее важные ключевые фразы как можно ближе к началу текста страницы. Обязательно используйте точное следование ключевых слов в фразе друг за другом. По возможности, старайтесь использовать наиболее популярные словоформы.
- Разбивайте текст на логические фрагменты, для которых используйте заголовки и подзаголовки, выделенные с помощью тегов <h1>, ..., <h6>, причем старайтесь по возможности, использовать в них наиболее важные ключевые фразы.
- Выделяйте в тексте наиболее важные ключевые фразы тегами <strong>, <em>, <b>, <i>, если идеология представления информации на сайте позволяет это делать.
- Разместите наиболее важные ключевые фразы в теге title. При этом он должен представлять собой вполне читабельный связный текст длиной не более 20-25 слов, а не просто набор ключевых фраз.
- Разместите ключевые фразы в атрибуте alt тегов img.
- Разместите не более 50 ключевых слов, встречающихся в тексте страницы, в теге keywords.
- Поместите краткую привлекательную для пользователя аннотацию содержимого страницы в тег description.
Однако, используя эти рекомендации, не забывайте, что текст документа должен быть удобен для чтения и восприятия пользователем. Не стоит чрезмерно пичкать его ключевыми фразами в надежде повысить их концентрацию. Эффект, который это может принести, несоизмеримо мал по сравнению с риском потерять пользователя, пришедшего на страницу, из-за того, что ему неудобно или неприятно воспринимать ее содержимое. Зачастую, бывает достаточно того, чтобы конкретная ключевая фраза хотя бы один раз встречалась в тексте документа. Дальнейшее повышение релевантности документа этому запросу можно проводить за счет воздействия на внешние факторы, влияющие на ранжирование.
Внешние динамические факторы (ссылочное ранжирование).
Ссылочное ранжирование, или поиск по лексике ссылок, является, пожалуй, самым интересным из критериев, оказывающих влияние на ранжирование документов в результатах поиска. Именно ссылочное ранжирование является причиной многих скандалов вокруг поисковых систем, связанных с выдачей поисковыми системами известных сайтов в ответ на запросы по оскорбительным, нецензурным или близким к таковым выражениям. Среди "пострадавших", например, сайты Microsoft, Александра Лукашенко и "Союза Правых Сил". Именно результаты действия ссылочного ранжирования вызывают у людей, далёких от оптимизации, стандартный вопрос: "почему мне выдаётся страница, на которой нет ни одного слова из запроса?" Итак, давайте разберёмся.
Ссылочное ранжирование - влияние текста ссылок на документ на релевантность этого документа запросу. То есть если слова из запроса встречаются в тексте ссылки на документ с друго документа, то это повышает его релевантность данному запросу.
При введении этого фактора ранжирования в алгоритм поисковой системы разработчики руководствовались тем соображением, что если кто-то ссылается на страницу каким-либо текстом, то значит с большой долей вероятности можно быть уверенным, что эта информация содержится на странице и чем больше таких ссылок, тем выше эта вероятность. А если страница, на которую ссылаются, популярна у многих пользователей, т.е. "авторитетна"? Тогда соответствие содержания страницы тексту ссылки должно быть ещё более вероятным - авторитетный сайт "плохого" не порекомендует. Значит, логично ввести зависимость от показателей "авторитетности" страницы. Рассмотрим переменную Lа(x) из первой формулы:
где
PRi - показатель авторитетности страницы i, константа относительно запроса х,
f(PRi) - некая неубывающая функция от PRi, для простоты можно принять ее линейной, т.е. f(PRi) = k*PRi, где k - некий коэффициент,
Lаi(x) - релевантность запросу x ссылок со страницы i на страницу а, если в тексте ссылки нет ни одного слова из запроса, то Lаi(x) = 0. Максимальное значение функция Lаi(x) принимает, если в тексте ссылки встречается точное вхождение поисковой фразы.
Вернёмся к нашей первой формуле:
Из неё видно, что на величину итогового соответствия кода страницы запросу Rа(x) оказывает влияние произведение величин Lа(x) и F(PRa).
Таким образом, величина эффекта от ссылочного ранжирования на релевантность страницы запросу напрямую зависит от 3-х параметров:
- релевантности текста ссылок запросу;
- "авторитетности" страницы;
- "авторитетности" ссылающейся страницы.
Зачастую, при анализе позиций сайта в выдаче бывает трудно выделить влияние именно ссылочного ранжирования. Однако хорошо виден его эффект в "крайних" случаях, т.е. когда влияние остальных факторов крайне мало.
Случай первый, примеры которого я приводил, начиная рассказывать о ссылочном ранжировании (случаи с сайтами Microsoft, Лукашенко, Союза Правых Сил). Тогда эти ресурсы появились на высоких позициях по определенным запросам в поиске за счёт нескольких текстовых ссылок с форумов, домашних страничек или гостевых книг. В данном случае подобного текста не было на страницах, влияние внутренние динамические факторы не могли оказать, т.е. Tа(x) = 0; ранг ссылающихся страниц с релевантным запросу текстами ссылок был близок к нулю, т.е. значение Lа(x) довольно мало; однако, за счет довольно высокого собственного ранга документа, на которую ведёт ссылка, а, следовательно, довольно высокого значения функции F(PRa), получившееся в итоге значение Rа(x) было достаточно для того, чтобы данный документ был лидером выдачи. Соответственно, несколько ссылок с искомым текстом, ведущие на страницу с большим собственным рангом, могут дать очень существенный эффект. Для борьбы с подобным эффектом поисковые машины вводят ограничение на функцию f(PRi):
где М - константа, некое пороговое значение. То есть ссылки с документом с довольно низким рангом не учитываются при ссылочном ранжировании. Подобное ограничение, вполне возможно, действует во всех рассматриваемых в данной статье поисковиках. Также поисковые машины могут накладывать по той или иной причине ограничения на отдельные документы и даже сайты и вовсе не учитывать ссылки с них при ссылочном ранжировании, также как и при расчете ранга документов, на которые они ссылаются ("непот-фильтр" в Яндексе, "PR-пенальти" в Google)
Другой крайний случай - это когда на страницу без искомого текста и небольшим рангом ссылается текстом страница с рангом высоким. В этом случае внутренние динамические факторы влияния не оказывают, т.е. Tа(x) = 0; "авторитетность" страницы, на которую ссылаются, мала, поэтому влияния практически не оказывает, т.е. F(PRa) имеет значение близкое к 1; ранг документа ссылающегося на данный документ текстом, релевантным запросу, очень высока, т.е. значение Lа(x) довольно велико. В итоге страница, получившая такую ссылку может получить неплохое значение Rа(x) и занять высокие позиции в результатах поиска по запросам запросам, слова из которых содержатся в тексте ссылки.
Особо хочу пояснить один момент, из-за которого ссылочное ранжирование в плане повышения релевантности документа запросу намного привлекательнее внутренних факторов. Дело в том, что функция Tа(x), зависящая от внутренних факторов имеет максимум, достигаемый при некотором "идеальном" наборе своих параметров (каждый из которых у конкретного поисковика свой).
Функция ссылочного ранжирования Lа(x), в отличие от фунции Tа(x), такого экстремума не имеет, так как любое появление новой содержащей ключевую фразу ссылки на страницу, будет увеличивать ее значение.
Поэтому время и силы, которые можно затратить для нахождения идеального набора значений для внутренних факторов (который, кстати, может довольно часто изменяться вследствие действий администраций поисковых машин, постоянно работающих над "улучшением качества поиска"), что по сути является сложной задачей многокритериальной оптимизации, лучше с гораздо большей эффективностью потратить на организацию новых ссылок на страницы сайта с текстами, содержащим необходимые ключевые слова.
Очень важным моментом, о котором, однако, часто забывают, является то, что ссылочное ранжирование работает и внутри одного домена. Хотя, возможно, и с некоторыми понижающими коэффициентами. Иногда приходиться сталкиваться с заблуждением, что ссылочное ранжирование должно поднимать релевантность любой из страниц сайта в выдаче по запросу, текст которого содержится в запросе. Это не так. Ссылочное ранжирование действует на конкретные страницы - те, на которые указывают ссылки.
Это была общая теория. Рассмотрим особенности реализации ссылочного ранжирования в конкретных поисковых машинах.
Рамблер был последней из рассматриваемых нами поисковых машин, которая ввела учет ссылочного ранжирования. Это произошло весной 2003 года, и механизм его реализации пока мало изучен.
Апорт, как мы уже говорили, учитывает не более одной ссылки с каждого домена второго уровня. Особенностью является тот факт, что в зависимости от запроса алгоритм может использовать различные ссылки.
Google учитывает не более 8 первых слов из текста ссылки, причём предлоги и междометия тоже будут считаться словами. Также хочу напомнить, что Google не учитывает морфологию. Вторая же отличительная особенность Google состоит в использовании им атрибута alt тэга img в качестве текста ссылки, если таковой является картинка. Хочу сразу предупредить вас о последствиях использования однопиксельных картинок с непустым значением атрибута alt для воздействия на ссылочное ранжирование - это считается поисковым спамом и наказывается.
Яндекс ограничения на длину ссылки, по нашим наблюдениям, не накладывает, но у него есть другие ограничения по учету текста ссылок при ссылочном ранжировании. Во-первых, как я уже говорил, существует "непот-фильтр", ссылки со страниц, на которые он установлен, учитываться не будут. Во-вторых, кроме порога, накладываемого на ранг документа, существует ещё один, не менее интересный порог, о котором говорил руководитель отдела поисковых систем Яндекса Илья Сегалович. При вычислении релевантности ссылок на страницу запросу вычисляется соотношение между количеством ссылок с релевантным запросу текстом к общему количеству ссылок на страницу. И если это соотношение ниже определённого порогового значения, то эти ссылки не учитываются. Подобная ситуация исправляется обычно небольшим количеством новых ссылок с точным вхождением текста запроса. Причины введения этого ограничения понятны. Если из 100 опрошенных 99 человек сказали, что видят на картинке морковку, а 1 - арбуз, то вряд ли стоит доверять его мнению.
И последнее. Документы, найденные за счёт лексики ссылок и не имеющие на странице слов запроса, в результатах поиска вместо обычной подписи "строгое соответствие" обозначаются "найдено по ссылке". И если при этом не выводится описание из Яндекс-Каталога, то тут же вы увидите и надпись "текст ссылок:" со сниппетами (выдержками) из текста ссылок на страницу.
Остаётся добавить, что для того, чтобы добиться хороших результатов в ранжировании по средне- и высококонкурентным запросам использование ссылочного ранжирования обязательно. И основная проблема для оптимизатора - при работе по установке внешних ссылок на страницы своего сайта, о которой говорилось в разделе, посвященном статическим факторам, договориться с владельцами других ресурсов об установке текстовых ссылок с текстом, релевантным целевым запросам, по которым продвигается сайт, или найти ресурсы, позволяющие свободно добавлять свои ссылки.
4. Влияние собственных ресурсов поисковых машин.
Под собственными ресурсами подразумеваются самостоятельные сервисы поисковых систем, оказывающие влияние на ранжирование сайтов в результатах поиска. Для рассматриваемых нами поисковых систем Яндекс, Апорт и Google - это их каталоги, и рейтинг Rambler Top100 для Рамблера. Появление этих ресурсов было обусловлено, прежде всего, необходимостью повысить качество поиска. Описания для сайтов в этих каталогах составляются профессиональными модераторами, заинтересованными в предоставлении максимально точной информации. В случае с Top100, хотя авторство описаний и принадлежит владельцам ресурсов, за них, по замыслу, голосуют сами пользователи своими посещениями ресурса. Исходя из этого, у поисковых систем имеется высокая степень доверия к собственным ресурсам и, как следствие, влияние их на ранжирование очень высоко.
Яндекс-Каталог (http://yaca.yandex.ru)
Сразу хочу заметить, что влияние каталога на результаты поиска Яндекса очень велико, что делает попадание на первые страницы по наиболее конкурентным запросам практически невозможным, если в каталожном описании документа нет точного вхождения поисковой фразы.
В Яндекс-Каталоге ресурсы описываются достаточно большим количеством характеристик:
- название ресурса;
- его описание;
- тема, т.е. основная категория каталога, в которой он находится;
- регион;
- сектор экономики;
- степень достоверности (источник) информации;
- потенциальная аудитория (адресат информации);
- жанр (художественная литература, научно-техническая литература);
- цель ресурса (предложение товаров и услуг, интернет-представительство).
Большинство этих характеристик служат лишь для организации навигации в каталоге. Каталог имеет фасетную структуру, т.е. описание сайта может располагаться одновременно в нескольких местах - прежде всего в своей категории, а также в уточняющих подкатегориях (регион, сектор экономики, степень достоверности информации, адресат информации, жанр и цель ресурса).
На результаты же поиска влияние оказывают только название ресурса и его описание. Действуют они по схеме ссылочного ранжирования, только в качестве ранга (в данном случае - ВИЦ) ссылающейся страницы используется установленный для каталога коэффициент. Вполне возможно, что этот коэффициент может зависеть от рубрики каталога, от положения сайта в своей рубрике, или даже вручную выставляться документу модератором каталога. При расчете ВИЦ документа, судя по всему, факт наличия его в каталоге, не учитывается. Особое внимание я хочу обратить на тот факт, что хотя описание ресурса в каталоге Яндекса ссылкой не является, учитывается оно именно как ссылка при ссылочном ранжировании. Правда, гораздо меньше, чем ссылка-название: видимо, для описания существует некий понижающий коэффициент.
В случае, если слова из поисковой фразы отсутствуют в тексте документа, но присутствует в названии или описании его в Яндекс-каталоге, в выдаче по этому запросу приводятся каталожное название и описание документа.
Существуют два варианта регистрации в каталоге (http://www.yandex.ru/advertising/catalog.html): бесплатная и платная "ускоренная", стоимость которой составляет $149 для коммерческих и $49 для некоммерческих сайтов (без учета НДС). При ускоренной регистрации ваш сайт может быть внесён в каталог в течение 3-х дней, при бесплатной - может, никогда и не будет. Модераторы каталога самостоятельно отбирают ресурсы, и даже если заявка не подавалась, ресурс может оказаться в каталоге. Как утверждают представители Яндекса, ресурсы отбираются по принципу интересности и уникальности информации, а также по цитируемости другими сайтами. В случае бесплатного добавления данные из формы бесплатной заявки являются не более чем рекомендацией модераторам. В случае, если описание вашего ресурса, сделанное модераторами каталога, вас по каким-либо причинам не устраивает, то вы можете подать заявку на изменение описание. Эта услуга платная и стоит $40 для любого ресурса. Этот способ можно использовать для того, чтобы добиться появления в заголовке или описании нужных вам ключевых фраз, а следовательно, улучшить ранжирование ресурса в основном поиске по этим фразам. Однако пользоваться этой возможностью надо весьма осторожно, и при этом надо суметь аргументированно убедить модераторов каталога в том, что эти изменения действительно необходимы.
Апорт-Каталог
Во многом схож с каталогом Яндекса, но, пожалуй, в несколько меньшей степени оказывает влияние на результаты поиска. Действие каталожного листинга также происходит по схеме ссылочного ранжирования, однако помимо названия и описания, учитывается и список ключевых слов, задающийся при регистрации, но не отображаемый в каталоге.
Ресурсы могут заноситься одновременно в несколько категорий каталога, при условии соответствия их содержанию.
Ещё одной особенностью можно назвать тот факт, что в результатах поиска Апорта для главных страниц сайтов, присутствующих в каталоге, всегда выводится название и описание ресурса именно из каталога.
Регистрационные данные для каталога подаются одновременно с регистрацией в поисковой системе (http://catalog.aport.ru/rus/reg/add.ple). При включении ресурса в каталог на указанный при регистрации почтовый адрес высылается уведомление.
Rambler Top100 (http://top100.rambler.ru)
Из всех собственных ресурсов поисковых систем, рассматриваемых нами, в рейтинг Top100 изначально попасть легче всего - регистрируетесь, размещаете код счётчика на странице - и вот вы в рейтинге. Правда, если регистрируется первый счётчик для данного домена, вполне возможно, что придётся пройти модераторскую проверку. Сам по себе рейтинг может дать неплохой трафик, но только при условии, что у страницы, для которой зарегистрирован счётчик, достаточно высокая посещаемость, позволяющая занять высокие места на первой странице популярной рубрики рейтинга. Ещё немного посетителей можно получить с поиска по самому Top100. Но нас интересует возможность попадания документа, зарегистрированного в Top100, в результаты поиска по основной базе. Это возможно благодаря так называемой "примеси".
Примесь - это несколько позиций в результатах поиска Рамблера по определенному запросу, ссылки для которых выбираются из заголовков и описаний ресурса, данных при регистрации в рейтинге Rambler Top100, релевантных этому запросу (т.е. содержащих слова из запроса). Сайты из примеси в результатах поиска можно отличить по свежей дате индексации (чаще всего это текущая дата) и отсутствию ссылки "Восстановить текст". Причем, один и тот же документ может присутствовать в выдаче дважды, если текст самого документа релевантен запросу и если его заголовок или описание в Top100 релевантно запросу, и этот документ, благодаря этому, попал в примесь, и оба этих результата никак не связаны между собой.
В работе с примесью есть очень приятный момент - изменения в описании вступают в силу уже на следующий день. Если быть точнее, то не всегда на следующий (это можно определить по дате индексации), но в любом случае несоизмеримо быстрее, чем обычно при индексации. Вы меняете описание вечером, а уже после полуночи ваш сайт может оказаться в основной выдаче Рамблера.
Одно время примесь играла исключительно важную роль в ранжировании результатов поиска Рамблера, так как ей было отведено до 5 первых мест в результатах поиска. Так как на попадание в примесь довольно сильное влияние оказывала посещаемость ресурса, то это привело к тому, что многие владельцы стали "накручивать" посещаемость своих сайтов, ведь это, зачастую, это был очень эффективный путь попасть в первую пятерку результатов поиска по нужному запросу. Однако, с июня 2003 года жесткое закрепление за примесью первых пяти позиций было снято и она "размазалась" по всей выдаче, причем таким образом, что встретить на первой странице результатов поиска по довольно конкурентным запросам документ из примеси теперь очень сложно. Поэтому позиционирование ресурса в Рамблере через примесь практически потеряло свое прежнее значение.
Каталог Google (http://www.google.com/dirhp)
Построен на основе каталога ODP - Open Directory Project (http://dmoz.org) Это крупнейший модерируемый каталог в интернете и практически единственный путь для попадания в каталог Google. ODP интересен ещё и тем, что редакторами в нём являются волонтёры, т.е. люди, для которых это занятие является хобби. При желании редакторами в этом каталоге можете стать и вы.
Ресурсы в каталоге Google сортируются по PageRank и имеют название и описание, причём название является текстовой ссылкой. По сравнению с влиянием каталогов Яндекса и Апорта, влияние каталога Google можно назвать менее значительным. Влияет лишь заголовок ресурса, который собственно и является обычной текстовой ссылкой, и влияние это целиком укладывается в схему ссылочного ранжирования.
Ещё одним небольшим аргументом за регистрацию в каталоге служит наличие в результатах поиска под ссылкой на ресурс ссылки на категорию каталога и части каталожного описания, что, может положительно повлиять на решение пользователя перейти по этой ссылке.
Я не привожу ссылки на форму добавления в каталог, потому что ресурсы добавляются именно в том разделе, в котором им предстоит находиться. Найдите подходящую для вас категорию и перейдите по ссылке "Submit a Site" внизу документа.
В заключение темы о факторах, влияющих на ранжирование документов в поисковых системах, хочется добавить, что на практике для достижения хороших результатов при позиционировании по низкоконкурентным запросам бывает достаточно влияния хотя бы одного из них, например, релевантного текста даже при невысоких показателях "авторитетности" страницы. По самым же конкурентным запросам может потребоваться "массированное" применение всего "арсенала" оптимизатора в течение большого временного отрезка, и не факт, что результат будет достигнут. Поэтому изначально при работе над проектом необходимо определиться с направлениями, т.е. запросами, которым будет отдано приоритетное значение.