Автор: Аруп Нанда, член-директор Oracle ACE
В этой статье рассказано, каким образом база данных при использовании переменных подстановки каждый раз выбирает правильные планы выполнения; как удостовериться, что новые планы выполнения, еще до их использования, являются лучшими.
До сих пор ходили сплетни и слухи, каким образом использование переменных подстановки улучшает производительность. Если это все же новость, я попробую объяснить основные концепции настолько просто, насколько смогу. (Также рекомендую посетить сайт Тома Кайта http://asktom.oracle.com, где можно узнать, насколько важно использовать переменные подстановки для увеличения производительности SQL-предложений, а также каким образом использовать их на том или ином языке программирования).
Представим, есть таблица CUSTOMERS, у которой, кроме всех прочих, есть столбец STATE_CODE, содержащий двухсимвольное обозначение американских штатов, где находятся клиенты - CT, NY и т.д. Если требуется найти всех клиентов, которые более трех раз совершали покупки и при этом они из штата Коннектикут ("CT"), скорее всего, будет использовано предложнение:
select count(1) from customers where state_code = 'CT' and times_purchased > 3
После его ввода Oracle выполнит действие, называемое разборкой (parsing - парсинг), которое сгенерирует план выполнения для только что выданного SQL-предложения. После парсинга-разборки запрос готов к выполнению. Концептуально парсинг похож на процесс компиляции исходного кода в программах: когда что-то написано на C++, сразу же запустить это в операционной системе нельзя - сначала нужно этот код скомпилировать и сделать запускаемым. Парсинг делает SQL-предложение запускаемым.
Теперь представим, что другой пользователь запустил предложение:
select count(1) from customers where state_code = 'NY' and times_purchased > 3;
Это предложение практически идентичено предыдущему за одним исключением: в STATE_CODE ищется значение NY, а не CT. В идеальной случае разобранный код будет таким же, и значение литералов будет подставлено в момент исполнения. Однако то, каким образом запросы написаны, заставляет Oracle интерпретировать их как разные и выполнять повторный парсинг для второго запроса.
Теперь представим, что вместо предыдущих предложений будет написано следующее:
select count(1) from customers where state_code =and times_purchased > 3;
В первый запрос будет передано NY, как значение для
where state_code = :state_code
Если используемый код не содержит переменных подстановки и вместо этого содержит ссылки на литеральные значения, как например "where state_code = 'CT"'", можно принудительно сделать так, чтобы все литералы конвертировались в переменные подстановки путем указания параметра инициализации:
cursor_sharing = force
Установка этого параметра вызовет перезапись запроса с "state_code = 'CT'" в "state_code = ":SYS_0001"", где SYS_0001 - генерируемое системой имя переменной. Этот прием сделает оба рассматриваемых запроса идентичными.
Проблемы с переменными подстановки
Хорошо. Если переменные подстановки так полезны, то почему бы не использовать их везде, где только можно? Ведь у нас есть "волшебная палочка" - параметр cursor_sharing - который преобразовывает любой неудачный код (all the bad code) в разделяемые (shared) SQL-предложения. (Те, кто уже знаком с причинами этого и концепцией bind-peeking, могут сразу перейти к разделу "Настраиваемые курсоры").
Представим, что на столбце STATE_CODE есть индекс. Значения столбца показаны ниже:
select state_code, count(1) from customers group by state_code; ST COUNT(1) -- ---------- NY 994901 CT 5099
Как видно, данные сильно перекошены (skewed): только 5% строк содержат значение "CT", а остальные - "NY". Такое распределение по штатам не является сюрпризом. Теперь посмотрим, какой тип плана исполнения генерируется для показанного выше запроса:
SQL> set autot traceonly explain
SQL> select * from customers where state_code = 'NY' and times_purchased > 3
2 /
Execution Plan
----------------------------------------------------------
Plan hash value: 2008213504
-------------------------------------------------------------------------------
/ Id / Operation / Name / Rows / Bytes / Cost (%CPU)/ Time /
-------------------------------------------------------------------------------
/ 0 / SELECT STATEMENT / / 895K/ 26M/ 1532 (9)/ 00:00:19 /
/* 1 / TABLE ACCESS FULL/ CUSTOMERS / 895K/ 26M/ 1532 (9)/ 00:00:19 /
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("TIMES_PURCHASED">3 AND "STATE_CODE"='NY')
Запрос использует полный просмотр таблицы (full scan) - ожидаемое поведение, ведь 95% строк возвращаются запросом и использование индекса будет очень дорогостоящим. Теперь выполним запрос со значением "CT":
SQL> c/NY/CT
1* select * from customers where state_code = 'CT' and times_purchased > 3
SQL> /
Execution Plan
----------------------------------------------------------
Plan hash value: 4876992
---------------------------------------------------------------------------------------------
/ Id / Operation / Name / Rows / Bytes / Cost (%CPU)/ Time /
---------------------------------------------------------------------------------------------
/ 0 / SELECT STATEMENT / / 4589 / 138K/ 56 (2)/ 00:00:01 /
/* 1 / TABLE ACCESS BY INDEX ROWID/ CUSTOMERS / 4589 / 138K/ 56 (2)/ 00:00:01 /
/* 2 / INDEX RANGE SCAN / IN_CUST_STATE / 5099 / / 12 (0)/ 00:00:01 /
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("TIMES_PURCHASED">3)
2 - access("STATE_CODE"='CT')
Этот запрос использует индекс. Что ожидаемо: лишь 5% строк содержат "CT" и использование индекса наиболее выгодно.
Теперь посмотрим на поведение при использовании переменных подстановки. Вот как это делает Oracle Database 10g:
SQL> var state_code varchar2(2)
SQL> exec :state_code := 'CT'
PL/SQL procedure successfully completed.
SQL> select max(times_purchased) from customers where state_code = :state_code
2 /
Execution Plan
----------------------------------------------------------
Plan hash value: 296924608
--------------------------------------------------------------------------------
/ Id / Operation / Name / Rows / Bytes / Cost (%CPU)/ Time /
--------------------------------------------------------------------------------
/ 0 / SELECT STATEMENT / / 1 / 6 / 1511 (8)/ 00:00:19 /
/ 1 / SORT AGGREGATE / / 1 / 6 / / /
/* 2 / TABLE ACCESS FULL/ CUSTOMERS / 500K/ 2929K/ 1511 (8)/ 00:00:19 /
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("STATE_CODE"=:STATE_CODE)
Оптимизатор выбрал полное сканирование таблицы CUSTOMERS. Должен ли был быть использован индекс из-за того, что мы ищем только значения "CT", содержащиеся примерно в 5% всего набора строк? Что заставило оптимизатор выбрать полное сканирование вместо использования индекса?
Ответом является феномен, называемый bind peeking. Раньше, когда запускался запрос со значением переменной подстановки, равной "NY", оптимизатору требовалось выполнить жесткий разбор (hard parse) первого исполнения. При этом оптимизатор считывает переменную подстановки, чтобы увидеть, какое значение ей присвоено. Значение равно "NY". Т.к. строк со значением "NY" примерно 95% от всего количества, оптимизатор выбирает полное сканирование (как и ожидалось). Дополнительно он также фиксирует план запроса. Дальше, когда запускается тот же запрос, но для значения "CT", план выполнения не перерасчитывается, и оптимизатор использует тот же план, что и раньше, даже несмотря, что он не является лучшим в этом случае. Если же вместо переменной подстановки использовать какое-либо значение (например, "CT"), оптимизатор выберет правильный план выполнения.
Таким образом, переменные подстановки, несмотря на свои в большинстве случаев преимущества, в действительности проигрывают, когда селективность значений радикально влияет на планы выполнения, как в приведенном примере, когда селективность значений "CT" и "NY" была 5% и 95% соответственно. В случаях, когда распределение данных таково, что селективность примерно одинакова для всех значений, план выполнения может оставаться одним и тем же. Таким образом, умные SQL-кодеры знают, когда стоит прекратить пользоваться основным правилом применения переменных подстановки и вместо этого использовать литералы.
Что делать, если имеет место нехватка хороших кодеров или времени на переписывание предложений? Предоставляет ли Oracle какие-либо интеллектуальные альтернативы?
Да, предоставляет. Начиная с Oracle 11g, курсоры неожиданно стали качественно интеллигентнее. Вместо слепого использования закешированного плана выполнения при любом исполнении запроса, они решают, нужно ли перерасчитать план выполнения, когда меняется значение переменной подстановки. Если курсор содержит в себе переменную подстановки, через некоторое время база данных рассматривает его на предмет передаваемых значений переменной, а также нуждается ли план выполнения в перерасчете. Если перерасчет требуется, курсор помечается как "чувствительный к значениям переменных" ("Bind-Sensitive").
Показанный ранее пример запроса является идеальным кандидатом. Корректный план оптимизатора будет использован на основании значения переменной подстановки. Самому делать ничего не нужно - все произойдет автоматически.
Представление словаря данных V$SQL было модифицировано, добавились два столбца: IS_BIND_SENSITIVE (чувствительность к значениям переменных подстановки) и IS_BIND_AWARE (изменяемость из-за значения переменной подстановки). Посмотрим, как они используются:
select is_bind_sensitive, is_bind_aware, sql_id, child_number from v$sql where sql_text = 'select count(1) from customers where state_code = :state_code and times_purchased > 3' I I SQL_ID CHILD_NUMBER - - ------------- ------------ Y Y 7cv5271zx2ttg 0 Y N 7cv5271zx2ttg 1
Посмотрим, что же содержат столбцы. В течение некоторого времени Oracle смотрит за курсором и видит, как изменяются значения. Если различные значения потенциально могут изменить план, курсор помечается как "Bind-Sensitive", а столбец IS_BIND_SENSITIVE содержит "Y". После нескольких исполнений база данных знает намного больше о курсорах и значениях переменных и принимает решение, перерасчитать ли этому курсору план выполнения, так как его план зависит от значений переменных. В этом случае курсор называется "Bind-Aware" и столбец IS_BIND_AWARE содержит "Y". Итог: Bind-Sensitive-курсоры являются потенциальными кандидатами на изменение планов, а у Bind-Aware-курсоров планы действительно меняются.
Новое представление V$SQL_CS_HISTOGRAM отображает, сколько раз SQL-предложение было исполнено; оно организовано по трем категориям (bucket) для каждого подчиненного курсора, как показано ниже:
select * from v$sql_cs_histogram where sql_id = '7cv5271zx2ttg' / ADDRESS HASH_VALUE SQL_ID CHILD_NUMBER BUCKET_ID COUNT -------- ---------- ------------- ------------ ---------- ---------- 45C8218C 2144429871 7cv5271zx2ttg 5 0 0 45C8218C 2144429871 7cv5271zx2ttg 5 1 2 45C8218C 2144429871 7cv5271zx2ttg 5 2 0 45C8218C 2144429871 7cv5271zx2ttg 4 0 8 ... и так далее ... 45C8218C 2144429871 7cv5271zx2ttg 0 2 0
А так как корректный план, основанный на значении переменой подстановки, применяет возможность совместного использования адаптивного курсора, база данных должна где-то хранить эту информацию. Она сохраняет эти сведения в еще одном новом представлении V$SQL_CS_SELECTIVITY, в котором показывается селективность различных значений, переданных в переменную подстановки.
select * from v$sql_cs_selectivity where sql_id = '7cv5271zx2ttg' / ADDRESS HASH_VALUE SQL_ID CHILD_NUMBE PREDICATE R LOW HIGH -------- ---------- ------------- ----------- ----------- - -------- ---------- 45C8218C 2144429871 7cv5271zx2ttg 5 =STATE_CODE 0 0.895410 1.094391 45C8218C 2144429871 7cv5271zx2ttg 4 =STATE_CODE 0 0.004589 0.005609 45C8218C 2144429871 7cv5271zx2ttg 4 =STATE_CODE 1 0.002295 0.002804 45C8218C 2144429871 7cv5271zx2ttg 3 =STATE_CODE 0 0.002295 0.002804 45C8218C 2144429871 7cv5271zx2ttg 0 =STATE_CODE 0 0.004589 0.005609
Это представление содержит изобилие информации. Столбец PREDICATE отображает различные использованные пользователями предикаты (условия WHERE). Значения LOW и HIGH отображают диапазон переданных значений.
Наконец, третье новое представление V$SQL_CS_STATISTICS информирует о действиях над курсорами, помеченными как Bind-Aware и Bind-Sensitive.
select child_number,
bind_set_hash_value,
peeked,
executions,
rows_processed,
buffer_gets,
cpu_time
from v$sql_cs_statistics
where sql_id = '7cv5271zx2ttg';
CHILD_NUMBER BIND_SET_HASH_VALUE P EXECUTIONS ROWS_PROCESSED BUFFER_GETS CPU_TIME
------------ ------------------- - ---------- -------------- ----------- ----------
1 22981142 Y 1 9592 3219 0
0 22981142 Y 1 9592 3281 0
Представление отображает статистику исполнений, зафиксированную базой данных. Столбец EXECUTIONS показывает, сколько раз запрос был выполнен с различными значениями переменной подстановки. Столбец PEEKED, озаглавленный в листинге как "P", показывает, обращался ли оптимизатор к переменной подстановки для создания хорошего плана.
Это представление несет дополнительную информацию, неявляющуюся необходимой для понимания, как работает эта функциональность базы данных. Адаптивные Курсоры активизируются и используются автоматически.
Управление SQL-планами
Сколько раз имела место ситуация: запрос имеет самый лучший из возможных планов выполнения, но неожиданно происходит что-то, после чего этого плана больше нет. Этим "что-то" может быть, например, что кто-то еще раз проанализировал таблицу или какой-либо влияющий на оптимизатор параметр (например, star_transformation) был изменен - список возможных причин безграничен. Превентивной мерой со стороны администратора может быть запрет на любые изменения в базе данных, например, сбор статистики, изменение параметров и т.д.
Однако, сказать это легче, чем сделать. Что произойдет, если изменится шаблон данных (data pattern)? Напомним пример из раздела Адаптивные Курсоры. Сейчас таблица CUSTOMERS наполнена сведениями о клиентах из Нью-Йорка - STATE_CODE в основном содержит "NY". В этой ситуации при запросе с предикатом:
where state_code = 'NY'
не будет использования индекса, вместо этого система выполнит полное сканирование таблицы. Когда же предикат будет таким:
where state_code = 'CT'
… индекс будет использован, т.к. запрос вернет всего лишь несколько строк. Однако, что произойдет, если изменится шаблон данных? Скажем, в один момент неожиданно вольется большое число клиентов из Коннектикута (state_code = 'CT'). Настолько больше, что процент CT подскочит до значения в 70%. В этом случае запросы на CT должны использовать полное табличное сканирование. Но из-за того, что в базе данных запрещен сбор статистики, оптимизатор не знает об изменении в шаблоне данных и продолжает доспуп по индексу, который теперь не эффективен. Что делать?
Вот если бы Oracle использовал оптимальный план и пересчитывал бы его, если изменяются такие определяющие факторы, как совокупность статистики или параметры базы данных. И с этого момента он использовал бы новый план, но только при условии, что этот новый план лучше. Это было бы очень хорошо, не так ли? Так вот, в Oracle Database 11g это возможно! Давайте посмотрим, как.
Одобренные SQL-планы
В Oracle Database 11g, когда уже рассчитанному плану оптимизатора необходимо обновление из-за изменения определяющих факторов, это не происходит немедленно. Oracle оценивает и применяет новый план только тогда и только в том случае, если новый план улучшает уже существующий. К тому же существуют инструменты и интерфейсы для обзора истории и сравнения сгенерированных планов для каждого запроса.
Цикл начинается с того, что Oracle находит запрос, выполнявшийся более одного раза, т.е. "повторяющийся". Как только повторяющийся запрос найден, его план фиксируется и сохраняется, как одобренный (baseline) SQL -план , в структуре базы данных, известной как SQL Management Base (SMB). Когда по любой причине для этого запроса генерируется новый план, он также сохраняется в SMB. Тем самым SMB хранит все планы запросов, информацию об их создании и так далее.
Сами по себе планы запросов в SMB не загружаются. Иначе SMB хранила бы планы для запросов всех типов и стала бы очень большой. Вместо этого можно и нужно контролировать, сколько запросов попадает в SMB. Существует два способа сделать это: автоматически считать одобренными все повторяющиеся запросы в SMB или вручную загрузить только те запросы, которые считаются одобренными.
Для начала рассмотрим простой пример. Чтобы автоматически захватывать все повторяющиеся запросы и обрабатывать их функцией SQL Plan Baselines, необходимо с FALSE (по-умолчанию) на TRUE изменить параметр базы данных optimizer_capture_sql_plan_baselines. Напомним, что изменение этого параметра можно выполнить в динамике:
SQL> alter system optimizer_capture_sql_plan_baselines = true;
После выполнения этой команды все планы выполнения повторяющихся запросов сохраняются как SQL Plan Baselines (одобренные в SQL-планы) в SMB. Все SQL Plan Baselines хранятся в представлении DBA_SQL_PLAN_BASELINES. Также их можно видеть через Enterprise Manager. Они находятся на закладке Server, как показано на скриншоте:
Выбираем в разделе Query Optimizer опцию SQL Plan Control и попадаем на главную страницу SPM:
Выбираем закладку SQL Plan Baseline и видим страницу, похожу на эту:

Это главное окно SQL Plan Baseline. В левом верхнем углу находятся конфигурационные параметры. Значение Capture SQL Plan Baselines установлено в TRUE, это результат выданной ранее команды ALTER SYSTEM. Ниже - Use SQL Plan Baselines также в TRUE (по умолчанию). Это говорит о необходимости использовании SQL Plan Baselines в случае, если доступен хотя бы один из планов.
В случае, если создается новый план для запроса, старый будет сохранен в SMB для истории. Из этого следует, что SMB разрастается [по мере наполнения] историями планов. В окне Plan Retention (Weeks) показывается, сколько недель будут храниться планы. На скриншоте видно, что сейчас это время составляет 53 недели. Если SQL Plan Baseline не будет использован в течение 53 недель, он будет удален автоматически.
Посередине экрана находится поле для поиска SQL-предложений. Введя строку поиска и нажав Go, отображаются SQL-предложения и соответствующие им планы выполнения, как показано на скриншоте выше. Каждый одобренный (baselined) план несет много статистической информации, а именно:
- Enabled (Включен) - одобренный план будет рассмотрен
- Accepted (Принят) - одобренный план рассмотрен и принят для запроса
- Fixed (Исправлен) - если план помечен как FIXED, оптимизатор будет рассматривать только этот план, как лучший. Таким образом, если для запроса пять планов помечены как "одобренные" (baselined) и три из них отмечены как "Fixed", оптимизатор будет рассматривать только эти три при выборе лучшего.
- Auto purge (Автоматическая очистка) - должен ли план быть автоматически удален.
Та же информация, как и множество других подробностей, доступна в представлении DBA_SQL_PLAN_BASELINES:
SQL> desc DBA_SQL_PLAN_BASELINES Name Null? Type ----------------------------------------- -------- --------------- SIGNATURE NOT NULL NUMBER SQL_HANDLE NOT NULL VARCHAR2(30) SQL_TEXT NOT NULL CLOB PLAN_NAME NOT NULL VARCHAR2(30) CREATOR VARCHAR2(30) ORIGIN VARCHAR2(14) PARSING_SCHEMA_NAME VARCHAR2(30) DESCRIPTION VARCHAR2(500) VERSION VARCHAR2(64) CREATED NOT NULL TIMESTAMP(6) LAST_MODIFIED TIMESTAMP(6) LAST_EXECUTED TIMESTAMP(6) LAST_VERIFIED TIMESTAMP(6) ENABLED VARCHAR2(3) ACCEPTED VARCHAR2(3) FIXED VARCHAR2(3) AUTOPURGE VARCHAR2(3) OPTIMIZER_COST NUMBER MODULE VARCHAR2(48) ACTION VARCHAR2(32) EXECUTIONS NUMBER ELAPSED_TIME NUMBER CPU_TIME NUMBER BUFFER_GETS NUMBER DISK_READS NUMBER DIRECT_WRITES NUMBER ROWS_PROCESSED NUMBER FETCHES NUMBER END_OF_FETCH_COUNT NUMBER
Кликнув на имени плана, будут отображены подробности:

Среди деталей показаны: план запроса, рассмотрен ли план, принят ли как наилучший, помечен ли как исправленный и т.д. Другой не менее важный атрибут - "Источник" ("Origin"), показывающий AUTO-CAPTURE, что означает, план запроса был захвачен системой автоматически, т.к. значение параметра optimizer_capture_sql_plan_baselines установлено в TRUE.
Нажав кнопку Return, возвращаемся к предыдущему скриншоту. Теперь выберем план, который не принят, и, нажав кнопку Evolve, посмотрим, требует ли этот план повторного рассмотрения для получения потенциально более лучшего плана. Соответствующий экран показан ниже:
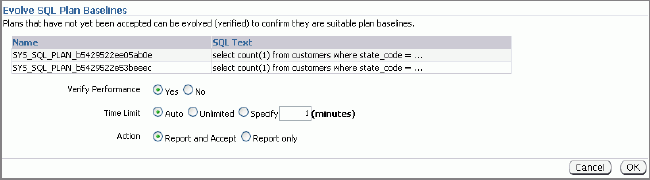
Важным моментом на этом экране является радио-кнопка Verify Performance. Ее следует использовать, если требуется проанализировать план и сравнить его с уже существующим SQL Plan Baseline для запроса. Ниже приведен отчет о таком сравнении:
-------------------------------------------------------------------------------
Evolve SQL Plan Baseline Report
-------------------------------------------------------------------------------
Inputs:
-------
PLAN_LIST = SYS_SQL_PLAN_b5429522ee05ab0e
SYS_SQL_PLAN_b5429522e53beeec
TIME_LIMIT = DBMS_SPM.AUTO_LIMIT
VERIFY = YES
COMMIT = YES
Plan: SYS_SQL_PLAN_b5429522e53beeec
-----------------------------------
It is already an accepted plan.
Plan: SYS_SQL_PLAN_b5429522ee05ab0e
-----------------------------------
Plan was verified: Time used 3.9 seconds.
Failed performance criterion: Compound improvement ratio <= 1.4.
Baseline Plan Test Plan Improv. Ratio
------------- --------- -------------
Execution Status: COMPLETE COMPLETE
Rows Processed: 1 1
Elapsed Time(ms): 3396 440 7.72
CPU Time(ms): 1990 408 4.88
Buffer Gets: 7048 5140 1.37
Disk Reads: 4732 53 89.28
Direct Writes: 0 0
Fetches: 4732 25 189.28
Executions: 1 1
Это очень хороший пример отчета, как сравниваются планы. Если конкретный план выглядит лучше с точки зрения производительности, оптимизатор будет использовать его. Если же новый план не показывает ощутимого улучшения производительности, он не будет принят и использован. В первую очередь SQL Performance Management показывает, как планы сравниваются и как используются те, которые действительно лучше.
С помощью пакета DBMS_SPM можно вручную изменить план выполнения на принятый:
declare
ctr binary_integer;
begin
ctr := dbms_spm.alter_sql_plan_baseline (
sql_handle => 'SYS_SQL_e0b19f65b5429522',
plan_name => 'SYS_SQL_PLAN_b5429522ee05ab0e',
attribute_name => 'ACCEPTED',
attribute_value => 'NO'
);
end;
Можно выключить SQL Plan Baseline, чтобы он не учитывался оптимизатором. Позже этот механизм можно включить снова. Для выключения используется:
declare
ctr binary_integer;
begin
ctr := dbms_spm.alter_sql_plan_baseline (
sql_handle => 'SYS_SQL_e0b19f65b5429522',
plan_name => 'SYS_SQL_PLAN_b5429522ee05ab0e',
attribute_name => 'ENABLED',
attribute_value => 'NO'
);
end;
Когда план конкретного SQL-предложения зафиксирован как baseline (одобренный), это четко показывает план выполнения (explain plan). В конце этого плана появляется строка, подтверждающая, что план был исправлен с помощью baseline.
Полученные и хранящиеся планы (Differences vs. Stored Outlines)
Если вы хорошо знакомы с функциональностью Stored Outlines (хранящиеся планы), сразу же возникает вопрос, в чем же отличие SQL Plan Management? Как будто бы они делают одно и то же: заставляют запрос использовать конкретный план выполнения. Однако у них есть одно существенное отличие - SQL Plan Baseline может оценить лучший план и активизировать вместо оригинального именно его в случае необходимости. В свою очередь хранящиеся планы (Stored Outlines) ограничены в возможностях и не могут быть отклонены, кроме случая, если будут выключены или заменены на другие. В дополнение функциональность SQL Plan Baseline обладает историей и возможностью оценить, каким образом планы изменялись в разрезе времени.
Логично звучит вопрос: что произойдет, если для запроса существует Stored Outline, а SQL Plan Baseline найдет лучший план? Будет конфликт, не так ли? Не совсем. Когда происходит парсинг запроса, план которого сохранен в Stored Outline, подставляемый план захватывается SQL Plan Baseline. Если оптимизатор находит другой план для этого запроса, он так же будет сохранен в SMB, но применен не будет. Прежде чем он начнет использоваться, необходимо запустить процесс Evolve, чтобы подтвердить, что новый план лучше чем тот, который уже сохранен в SQL Plan Baseline (т.е. старый сохраненный план из Stored Outline).
Полученные и хранящиеся профили (Differences vs. Stored Profiles)
Профили (Profiles) - это не "планы", это метаданные, сохраненные как часть планов исполнения, основанных на данных. Поэтому план запроса, основанный на предикатах, может изменяться при применении профилей. Однако, в случае SQL Plan Baseline план может быть одним и тем же, не зависимо от значения предиката.
Когда использовать
В каких случаях использовать эту возможность? Лучшим примером являются обновления системы или изменения параметров. Один из путей, когда можно использовать получение набора запросов - это использование SQL Tuning Set и загрузка предложений из STS в SPM. Т.е. можно сгенерировать STS в базе данных Oracle Database 10g, экспортировать, импортировать в базу данных Oracle Database 11g и запустить пакет DBMS_SPM.UNPACK_STGTAB_BASELINE для импорта планов выполнения, как SQL Plan Baselines. Позже, когда оптимизатор найдет лучшие планы и добавит их в SMB, появится возможность их сравнить.
Заключение
Адаптивные Курсоры и Управление SQL-планами - это просто два примера того, какой интеллигентной база данных стала в отношении типа запросов, которые она получает, и как реагировать на них. Обе функциональности позволяют получить лучшее из двух миров - с Адаптивными Курсорами можно использовать переменные подстановки, не рискуя получить неоптимальный план, а с SQL Plan Management - план выполнения не зафиксирован навечно, а может меняться в течение времени, оставаясь стабильным в короткосрочной перспективе.