Принципы техники и анализа повышения производительности IBM Rational ClearCase
Предидущая часть
Часть II: Повышение производительности
© Том Милли (Tom Millie), Джек Уилбер (Jack Wilber), IBM Rational
В первой части статьи
был дан обзор принципов оценки производительности среды IBM  Rational ClearCase.
Там описан
подход, хорошо зарекомендовавший себя при диагностике проблем производительности.
Этот подход основан на методичном анализе стека производительности – начиная
с уровня операционной системы / аппаратуры, затем проверяя и настраивая параметры
Rational ClearCase, а в конце – анализируя и оптимизируя прикладной уровень.
Теперь же, во второй части этой серии, будет рассказано, как использовать определенные
инструменты и практики для каждого слоя стека производительности, что необходимо
для оценки функционирования и повышения эффективности работы IBM Rational ClearCase
как на платформе Windows, так и под UNIX.
Rational ClearCase.
Там описан
подход, хорошо зарекомендовавший себя при диагностике проблем производительности.
Этот подход основан на методичном анализе стека производительности – начиная
с уровня операционной системы / аппаратуры, затем проверяя и настраивая параметры
Rational ClearCase, а в конце – анализируя и оптимизируя прикладной уровень.
Теперь же, во второй части этой серии, будет рассказано, как использовать определенные
инструменты и практики для каждого слоя стека производительности, что необходимо
для оценки функционирования и повышения эффективности работы IBM Rational ClearCase
как на платформе Windows, так и под UNIX.
Аппаратный / операционный уровень стека производительности
Как уже было описано в первой части, я приступаю к анализу проблем производительности,
начиная с нижнего уровня стека — аппаратного / операционного уровня (см. Рисунок
1).

Рис. 1. Стек производительности IBM Rational ClearCase
На этом уровне проверяется:
- Наличие ситуаций возникновения нехватки памяти.
- Проблемы с дисковым вводом/выводом.
- Пропускную способность сети и проблемы с задержками.
Далее эти вопросы обсуждаются подробно.
Проверка на ситуации возникновения нехватки памяти
Для повышения производительности IBM Rational ClearCase использует ряд кэшей.
Оперативная память используется для кэширования данных на view-серверах и VOB-серверах.
Кроме того, имеются кэши MVFS, а также кэш для каждого представления для процесса
view-сервера. Для эффективной работы все эти кэши нуждаются в наличии соответствующего
объема памяти, и именно в этом кроется причина чрезвычайной важности памяти
для производительности Rational ClearCase.
Память также влияет на производительность процессора и операций дискового
ввода/вывода. Система, испытывающая недостаток оперативной памяти, может также
иметь высокий уровень использования процессора, так как процессор вынужден
чаще обмениваться с диском страницами виртуальной памяти.
В системах под UNIX для проверки утилизации памяти и загрузки процессора я
использую такие UNIX-утилиты, как vmstat, sar и glance. Тем не менее, эти утилиты
присутствуют не во всех версиях UNIX. В системы Linux и Solaris, скорее всего,
включен vmstat, а в HP-UX присутствует glance.
На рисунке 2 показана информация, выводимая vmstat в системе со значительной
утечкой памяти; каждая строка, выводимая vmstat, является мгновенным снимком
состояния системы в определенный интервал времени.
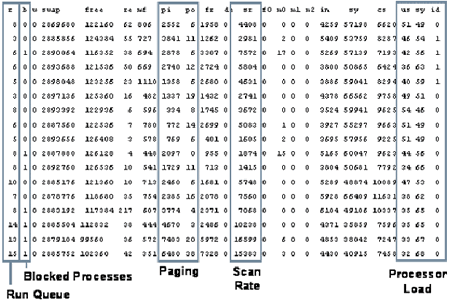
Рис. 2. Информация, выводимая утилитой vmstat, показывает статистику по виртуальной
памяти
Основным индикатором нехватки памяти является частота сканирования. Когда
система обнаруживает необходимость в оперативной памяти, начинается сканирование
страниц виртуальной памяти, которые были сброшены на диск. Частота сканирования
указывает, как много страниц памяти система ищет в секунду. До появления восьмой
версии операционной системы Solaris, непрерывная частота сканирования более
200 страниц в секунду указывала на нехватку памяти. Начиная с восьмой версии
Solaris и выше, любое ненулевое значение частоты сканирования означает, что
системе не хватает памяти.
Также стоит обратить внимание на столбец "run queue" (очередь выполнения)
- это важно, так как показывает количество процессов в очереди, ждущих выполнения
процессором. Очередь выполнения не должна быть больше числа имеющихся в системе
процессоров минус 1, но, как правило, я обращаю внимание на любое ненулевое
значение.
Метрики на рисунке 2 указывают на нехватку памяти, которая, скорее всего,
вызвана недостаточно мощным процессором. Время ожидания центрального процессора,
указанное в последнем столбце, является нулевым. Очередь на выполнение также
состоит из 15 процессов, перечисленных в последнем столбце. Если вы посмотрите
только на эти два последних столбца, у вас может возникнуть мысль, что более
мощный процессор сможет решить эту проблему; но фактически процессор оказывается
занят исключительно подкачкой страниц памяти, что перекрывает выполнение системных
задач, а на выполнение других процессов практически не остается времени.
Следует учесть, что величина частоты обмена страниц не всегда так важна, как
частота сканирования. В некоторых операционных системах, ввод / вывод производится
через отображение на страницы памяти, поэтому высокая частота обмена страниц
может быть вызвана интенсивными операциями ввода/вывода. Подобная ситуация
особенно характерна для компьютеров, работающих в качестве серверов NFS.
Если в вашей системе не доступна утилита vmstat, большинство подобной информации
можно получить от sar, хотя в этом случае информация менее наглядна. На рисунке
За показан вывод sar в системе, имеющей достаточное количество памяти, а на
рисунке 3b - выводимая информация для системы с малым объемом памяти.
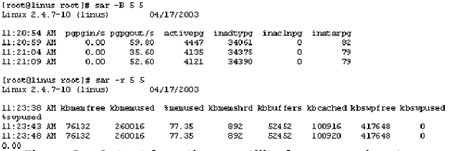
Рис. 3а. Выводимая утилитой sar информация для системы с достаточным количеством
оперативной памяти

Рис. 3b. Выводимая утилитой sar информация для системы с нехваткой оперативной
памяти
Видно, что объем используемой памяти, составляет лишь 77 процентов в нормальной
системе, и 94 процента в системе с нехваткой памяти; в нормальной системе частота
обмена страниц равна нулю, а в системе с нехваткой памяти составляет сотни
страниц в секунду. Для последней системы — и для систем, показанных на рисунке
2, — добавление большего количества памяти является хорошим первоначальным
шагом к повышению производительности.
Альтернативно можно просмотреть выполняющиеся в системе процессы с помощью
утилит ps или top, с целью анализа, не могут ли некоторые интенсивно использующие
память задачи выполняться на других компьютерах.
На платформе Windows есть еще более простой способ проверки памяти и загрузки
процессора – с помощью менеджера задач Windows (taskmgr.exe). Монитор производительности
(Performance Monitor_ (perfmon.exe) является еще одним хорошим инструментом
анализа систем Windows. Кроме того, можно найти свободно доступные, распространяемые
в исходных кодах, Windows-версии vmstat, sar и других утилит UNIX для проверки
системных ресурсов.
Проверка наличия проблем с дисковым вводом/выводом
Так же, как и утилита vmstat выводит статистику по виртуальной памяти, UNIX-утилита
iostat выводит статистику по операциям ввода/вывода. На рисунке 4 показан образец
статистики, выводимой iostat, что можно использовать для идентификации узких
мест с дисковой производительностью и проблем с балансировкой загрузки.
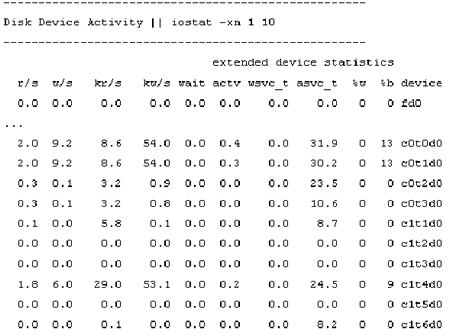
Рис. 4. Утилита iostat показывает дисковую активность
При анализе вывода iostat, я смотрю, прежде всего, на столбец %w, в котором
указывается процент времени существования транзакций, ждущих выполнения. Другими
словами, это процент времени, для которого очередь устройства не является пустой.
Приведенное в этом столбце число должно быть нулем. Устранить ненулевые значения
в столбце %w можно с помощью перераспределения дисков, чтобы интенсивно используемые
диски были распределены среди нескольких дисковых контроллеров. Альтернативно,
вы можете перераспределить данные таким образом, чтобы часто используемые данные
размещались на дисках, работающих с различными контроллерами, или установить
более быстрые дисковые контроллеры.
Обратим внимание на столбец %b, в котором приводится процент времени нахождения
устройства в занятом состоянии. Этот столбец поможет идентифицировать проблемы
с балансировкой загрузки. Например, вы можете отметить, что практически все
ваши устройства имеют низкие значения %b — скажем менее 5% — и что один диск
занят на 30%. В этом случае перед вами действительно проблемный диск, и возможно
стоит распределить данные по остальным дискам.
Для работы в среде Windows была написана небольшую утилиту на Visual Basic
(см. рисунок 5 и Приложение A), которая поможет идентифицировать как узкие
места с дисковой производительностью, так и ситуации нехватки памяти1.
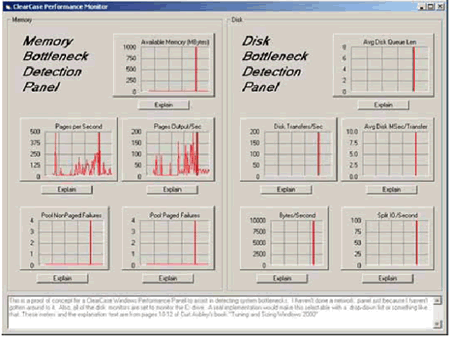
Рис. 5. Приложение на Visual Basic для мониторинга дисков и отслеживания использования
памяти
Проверка на пропускную способность сети и наличие задержек
Если не обнаружено какой-либо нехватки ресурсов после проверки памяти, дисков
и уровня загрузки процессора на VOB-хосте IBM Rational ClearCase, view-хосте,
и соответствующих клиентских машинах Rational ClearCase, то следующим шагом
будет поиск ситуаций сетевых задержек. Находясь на клиентской машине, надо
использовать утилиту ping, имеющуюся как в UNIX, так и в Windows, и измерить
время прохождения сетевых пакетов между VOB- и view-хостами. В качестве главного
правила можно использовать следующее: если наблюдаемые времена прохождения
пакетов превышают 10 мс, то пропускная способность сети может влиять на производительность
IBM Rational ClearCase. Факты утери пакетов также должны привлечь внимание,
так как в таком случае пакеты передаются повторно, что фактически удваивает
время передачи.
Если результаты, выдаваемые утилитой ping, указывают на существование проблемы,
я запускаю утилиту traceroute (на платформе Windows, это tracert.exe) для того,
чтобы получить более подробную информацию о пути, который проходят пакеты по
дороге к серверу. В идеальном случае мне хотелось бы видеть, что путь к серверу
занимает лишь один сетевой сегмент (или вообще без сегментов, но в большинстве
сетей такая ситуация маловероятна). Каждый сегмент характеризуется своей задержкой,
так как пакет маршрутизируется сетевым оборудованием — поэтому чем меньше сегментов,
тем лучше. По информации, выводимой утилитой traceroute, также можно точно
определить, какой сетевой сегмент вызывает наибольшую задержку прохождения
пакетов. Сетевые администраторы могут использовать эту информацию для улучшения
пропускной способности сети, и в свою очередь, для сокращения времени отклика
IBM Rational ClearCase.
Двумя другими утилитами, которые могут полезны для идентификации сетевых проблем,
являются strace и truss2. В частности, эти утилиты можно применять при отслеживании
воспроизводимых проблем, связанных с командами, так как они идентифицируют
каждый системный вызов, выполняемый программой. Например, если обновление snapshot-представления
занимает значительное количество времени, то можно запустить strace во время
проведения одного из обновлений. При анализе выводимой информации видны длительные
паузы между производимыми системными вызовами. Если обнаруживается длительная
задержка вызова, относящегося к сетевым операциям - например, определение имени
хоста или открытия файла на сетевом сервере, то можно использовать эту информацию
для изоляции и выяснения причины возникновения торможения.
Если возникает подозрение, что в низкой производительности виновата сеть,
но при этом не возможно определить, в чем именно заключается проблема, используется
анализатор пакетов, такой как snoop или ethereal3. Обычно используются эти
утилиты лишь, в крайнем случае, для того, чтобы точно определить, что происходит
на уровне пакетов. Необходимо помнить, что важные данные часто проходят по
сети в незашифрованной форме, и ПО для анализа сетевых пакетов может сделать
эти данные видимыми для пользователя. По этой причине многие компании отрицательно
относятся к проведению неавторизованного анализа пакетов в их внутренних сетях,
поэтому в таком случае рекомендуется привлекать сетевого администратора, если
подобный сбор данных действительно необходим.
Иногда обнаруживается, что бывает очень полезно поработать с подобными утилитами.
Например, не так давно я был удивлен тем, что может случиться, если перестает
работать мой сервер регистрации. Я сконфигурировал свою сеть, запустил ethereal,
а затем отсоединил сетевой кабель от компьютера, на котором выполнялся сервер
регистрации. Затем, чтобы посмотреть на VOB, я попробовал использовать cieartooi,
запускаемую из командной строки утилиту IBM Rational ClearCase. Я увидел ушедший
пакет с запросом на поиск сервера регистрации, а затем зависание, вызванное
ожиданием отклика. В командной строке cieartooi была также заблокирована и
находилась в состоянии ожидания. После того, как я снова подключил кабель,
пакеты снова начали проходить по сети, и cieartooi продолжила свою работу.
Когда я отслеживаю проблемы производительности, и наблюдаю блокировку выполнения
определенной команды IBM Rational ClearCase, я могу использовать утилиту ethereal
для просмотра того, что именно происходит с пакетами, когда команда наконец
начинает свою работу. Подобные приемы часто помогают мне идентифицировать ситуацию,
когда сетевой ресурс оказывается либо недоступен, либо отклик от него слишком
замедлен.
Уровни стека производительности IBM Rational ClearCase
После устранения любых проблем, обнаруженных на нижнем уровне стека производительности,
я двигаюсь вверх и приступаю к изучению настраиваемых параметров Rational ClearCase.
На этом уровне я смотрю на три принципиально важные области улучшения производительности,
причем все они включают динамические представления:
- Кэши MVFS. В IBM Rational ClearCase файловая система MVFS (файловая система
с поддержкой множественных версий) поддерживает динамические представления.
Динамические представления используют MVFS для отображения выбранных комбинаций
локальных и удаленных файлов в таком виде, как если бы они хранились в собственной
файловой системе. Особенно важным является то, что MVFS позволяет пользователям
просматривать VOB как наборы файлов и каталогов. Для повышения производительности
MVFS поддерживает несколько кэшей.
- Индивидуальные view-кэши. В дополнение к кэшам MVFS, каждое индивидуальное
представление имеет свой собственный кэш. Динамические представления требуют
частых проверок на обновления, что делает их довольно "болтливыми" в
смысле выполняемого ими количества RPC (удаленных вызовов процедур). View-сервер
поддерживает несколько кэшей, состоящих главным образом из данных VOB, и
необходимых для обеспечения быстрого отклика на запрошенные клиентом RPC.
- Экспресс-сборки. В моей практике, лишь небольшое количество людей осведомлены
о существовании экспресс-сборок. С технической точки зрения они не являются
настраиваемыми параметрами, но могут быть использованы для значительного
увеличения производительности при использовании динамических представлений.
Давайте внимательнее посмотрим на каждую из этих областей.
Кэши MVFS.
Я использую два инструмента IBM Rational ClearCase для доступа к кэшу производительности
MVFS: cleartool и mfvsstat.
Используя команду cleartool getcache - mvf s, я могу видеть, насколько полны
различные кэши MFVS.
Как показано на рисунке 6, команда cleartool getcache -mvfs также предоставляет
рекомендации по настройке параметров кэша MVFS. В Руководстве администратора
IBM Rational ClearCase4 предоставлена более подробная информация по операциям,
выполняемым каждым кэшем.

Рис. 6. Информация, выводимая командой cleartool getcache – mfvs
Если кэш почти заполнен, то это еще не говорит о проблеме. Фактически такая
ситуация часто наблюдается в хорошо работающей системе. Тем не менее, если
вы наблюдаете, что кэш заполнен, а частота успешных обращений низка, то вероятно
кэш имеет слишком маленький размер. Частота успешных обращений указывает, насколько
часто IBM Rational ClearCase находит информацию, за которой обращается в кэш.
Для определения частоты успешных обращений для кэшей MVFS я использую команду
mvf sstat -ci, как показано на Рисунке 7:

Рис. 7. Информация, выводимая утилитой
IBM Rational ClearCase mvfsstat
Я смотрю на общий вид полных кэшей, а также на частоту успешных обращений,
и пытаюсь определить кэш, работу которого можно улучшить путем увеличения его
размера. В общем случае мне хотелось бы видеть частоту успешных обращений выше
90 процентов. Если я отмечаю частоту успешных обращений ниже 80 процентов,
и при этом кэш является почти заполненным, тогда я увеличиваю размер кэша.
И одно дополнительное замечание: кэш enoent or name not found является очень
важным, так как запросы на получение отсутствующей в таком кэше информации
приводят к значительным затратам времени. Если вы обнаруживаете, что кэш заполнен,
а частота успешных обращений низка, то увеличение размера кэша должно значительно
увеличить производительность. На многопроцессорных компьютерах вам следует
быть осторожным, чтобы не сделать размер кэша слишком большим. Слишком большой
размер кэша фактически может вызвать некоторое снижение производительности
для систем, имеющих несколько процессоров, так как процессы IBM Rational ClearCase
управляют блокировками памяти кэшей, и, кроме того, на поиск в кэшах большего
размера требуется дополнительное время.
Вы также можете измерить эффективность работы кэшей MVFS с помощью одиночной
команды, такой как mvfstime -ci <command>, где <command> должна
быть ciearmake или другой утилитой IBM Rational ClearCase. Это может пригодиться
для доступа к информации о производительности кэшей во время выполнения определенных
операций, таких как сборка (build). После того, как команда закончит работу,
mvfstime выведет информацию о частоте успешных обращений во время выполнения
команды.
Корректировка размера кэшей MVFS довольно проста. На платформе Windows можно
использовать апплет из панели управления IBM Rational ClearCase (см. рисунок
8). Во многих случаях предпочтительным методом является использование коэффициента
масштабирования, с помощью которого увеличивается размер всех кэшей. Альтернативно
вы можете установить размеры индивидуальных кэшей, щелкнув по флаговой кнопке "override" ("переопределить").
Тем не менее, изменение индивидуальных размеров кэшей может отрицательно повлиять
на производительность. Обычно я просто увеличиваю фактор масштабирования на
некоторую величину, и затем повторно проверяю производительность кэша, причем
повторяю это до тех пор, пока частота успешных обращений к кэшу не поднимется
до приемлемого уровня.
На платформе UNIX, я использую команду cleartool setcache -mvfs -persistent
–scalefactor для корректировки размеров кэшей. Опция -persistent нужна для
того, чтобы изменения вступили в силу после рестарта системы MVFS. Без указания
этой опции, размеры кэшей будут возвращены к их исходной величине после того,
как MVFS будет еще раз запущена. Подробное обсуждение деталей находится за
пределами этой статьи, но в Руководстве администратора IBM Rational ClearCase,
в разделе Проверка и корректировка размера кэша MVFS даны исчерпывающие указания.
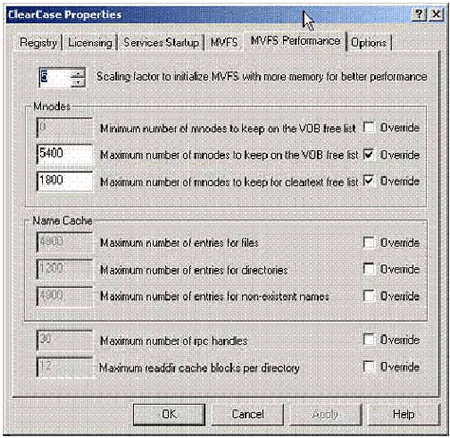
Рис. 8. Корректировка размеров кэшей MVFS с помощью апплета IBM Rational ClearCase
Индивидуальные view-кэши
Шаги, необходимые для выполнения анализа и корректировки индивидуальных view-кэшей,
сходны с шагами при анализе кэшей MVFS. Для проверки эффективности кэша, используйте
команду cleartool getcache -view viewname в Windows и в системах UNIX.
Как и в случае с кэшами MVFS, я обращаю внимание на заполненные кэши с низкой
частотой успешных обращений. Например, на рисунке 9 показан кэш просмотра,
который заполнен только на шесть процентов, с частотой успешных обращений 59
процентов. Если заполнение кэша просмотра близко к 100 процентам, я мог бы
сделать корректировку, но в данном случае не о чем беспокоиться. Также важным
является то, что статистику кэша следует проверить несколько раз и убедиться
в том, что вы наблюдаете реальные результаты, а не переходные значения, вызванные
недавним рестартом сервера.

Рис. 9. Проверка эффективности индивидуальных view-кэшей
На рисунке 10 показано, как настраивать индивидуальные размеры view-кэшей
с использованием утилиты cieartooi setcache -view. В этом примере, опция -cview
указывает, что я установил текущее представление. Опция -cachesize IM указывает
общее количество памяти, доступной для использования всеми кэшами. Значениями
по умолчанию для общего размера кэшей являются 512 КБайт на 32-разрядных платформах
и 1 МБайт на 64-разрядных. Корректировка общего размера кэшей не изменяет отношения,
выделенного для дополнительных кэшей; если я увеличиваю общий размер кэшей,
то и дополнительные кэши станут соответственно больше. Я могу также установить
значение по умолчанию размеров кэшей для всей локальной сети, используя команду
cieartooi setsite.

Рис. 10. Установка размеров индивидуальных view-кэшей
1 Мое предложение основано на двух книгах Курта Убли (Curt Aubley): Tuning & Sizing
NT Server (Настройка и масштабирование NT сервера) и Tuning and Sizing Windows
2000 for Maximum Performance (Настройка и масштабирование Windows 2000 для
получения максимальной производительности), обе книги опубликованы издательством
Prentice Hall. В этих книгах приведена более подробная информация по использованию
встроенных утилит Windows, таких как Task Manager (диспетчер задач) и Performance
Monitor (монитор производительности), для выявления узких мест производительности
системы Windows. Дополнительная информация доступна в он-лайновом режиме по
адресу http://www.tuningandsizingnt.com.
2 truss является утилитой, специфичной для Solaris (AIX теперь эмулирует ее
в версии 5.x, но эта версия не так усложнена, как Solaris 5.7 и выше). MKS
предоставляет версию для Windows, truss.exe. Существуют, по меньшей мере, два
типа strace для Windows, причем лучшей из них является та, которая устанавливается
вместе с Cygwin.
strace от Cygwin предоставляет информацию по промежуткам времени, в то время
как доступный для загрузки стандартный вариант этой утилиты такой информации
не дает. Cygwin особо указывается, что strace была разработана главным образом
для отладки dll-библиотек Cygwin. Аналогичная утилита в HP 11.x называется
tusc, и она предоставляет выводимую информацию и функциональность, сравнимую
с truss для старших версий Solaris. В AIX имеется несколько более сложная в
использовании утилита 'trace', которая предоставляет подробный анализ отслеживания
системных вызовов.
3 snoop является утилитой Solaris. Netmon от Microsoft доступен на платформе
Windows; утилита ethereal доступна для ряда операционных систем. Кроме того,
tcpdump предоставляет сходную функциональность для версий UNIX, отличных
от Solaris (включая Linux).
4 Это руководство поставляется вместе с продуктом IBM Rational ClearCase
Следущая часть
За дополнительной информацией обращайтесь в компанию Interface Ltd.
Обсудить на форуме