
| СТАТЬЯ |
03.04.02
|
©
Владимир Бегун
Статья была опубликована в журнале
Oracle Magazine
Опубликовано с любезного разрешения Oracle
Magazine
Справочные таблицы [lookup tables] или просто справочники... кажется, и не стоит начинать разговор - сколько информации, посвященной этой теме, почерпнуто из книг и статей, сколько рабочих часов потрачено на встречах, за обсуждением дизайна сущностей и структур баз данных, сколько времени потрачено на разработку дополнительной функциональной поддержки для справочников... так стоит ли начинать?.. Я позволю себе попробовать...
Итак, что же такое справочник? Справочник - это таблица, в которой содержится
относительно небольшой объем справочных данных, и структура которой отражает
правила системы перевода "кода" в "значение", например:
SQL> SELECT * FROM payment_type;
P NAME
----- --------------------------
1 Входящий платеж
2 Исходящий платеж
3 Обратный платеж (возврат)
... ...
Таблица payment_type содержит коды платежей для некой системы ведения бухгалтерского учета. Обычно код представляет собой уникальное числовое или строковое значение небольшой длины, а значение - это более точная, уникальная, иногда "расшифрованная" информационная структура. В самом простом виде значение - это строка. Как пример использования справочника с применением строкового значения кода мы можем рассмотреть справочник кодов валют ("USD"-"US Dollar", "RUB"-"Russian Rouble" и т.д.) или справочник штатов или земель любого государства ("AL"-"Alabama", "CA"-"California" - штаты США).
На первый взгляд, в этом нет ничего сложного... но это только до тех пор, пока система оперирует с разумных числом справочников. Если число справочных таблиц превышает, положим, 50-100 - использовать их становится не очень удобно. И дело тут не только в сложностях связанных с программированием, но и с администрированием. Так как любой справочник - это объект базы данных, а очень часто и не один объект, то кроме участия программистов в разработке подсистемы управления справочниками, участие администратора в таких дизайнерских решениях также очень желательно (но это тема другого разговора), поскольку ему и придется разбираться со всем тем большим количеством объектов, выделять дисковые и прочие ресурсы для их хранения и работы. Для программиста выгода очевидна, имея унифицированный набор интерфейсов для работы с такого рода справочниками, он может позволить себе не тратить время на разработку и поддержку специальных форм для работы с новым справочником (особенно это утомляет, когда структура справочников одинакова). Унифицированная форма и унифицированная функциональная поддержка действительно могут сократить время на разработку и уменьшить затраты на поддержку системы.
Как же реализуются такие подсистемы управления справочниками? Итак, справочник - это:
Итого, мы получаем 3-4 объекта для администрирования. Если подсчитать, что для некоторых систем, число справочников может быть 50-100, то число объектов может возрасти и быть потенциальной причиной для беспокойства, как для программиста, так и для администратора.
Постараемся решить проблему роста числа справочников и предложить приемлемое и унифицированное решение и попытаемся достичь следующие цели:
Структура таблиц, на примере таблицы payment, такая:
P NAME
----- --------------------
1. Inpayment
2. Outpayment
3. Backpayment
где p - первичный ключ - код; name - столбец уникальных значений справочника. Я бы хотел остановится на этом моменте: значения являются уникальными, именно в этом случае мы можем говорить о концепции "справочника". Но в зависимости от ситуации это ограничение может быть отменено.
На рисунке 1 представлена ER-диаграмма:
На рисунке 2 представлена ER-диаграмма "Гибкой системы справочников":
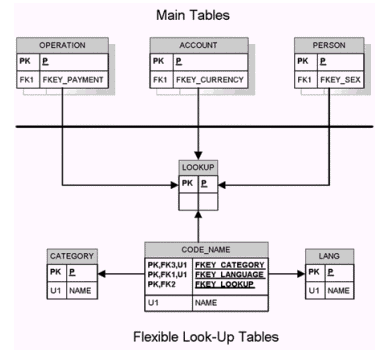
Система справочников представлена на нижней части рисунка:
SQL SELECT * FROM category;
P NAME
--------- ----------------
1 PAYMENT
2 CURRENCY
3 SEX
SQL SELECT * FROM lang;
P NAME
--------- --------------
1 Russian
2 English
3 German
Все, казалось бы, очень просто. Но, увы! Не всегда то, что просто - правильно. Итак, поговорим о "неправильностях", о тех, что имеются, и о тех которых нам удалось избежать:
Например:
SQL SELECT * FROM operation;
P FKEY_PAYMENT ...
--------- ------------ ----...
1 1
... ...SQL SELECT * FROM account;
P FKEY_CURRENCY ...
--------- ------------- ----...
17 1
... ...SQL SELECT account.p
2 , account.fkey_currency
3 , code_name.name
4 FROM account
5 , lookup
6 , code_name
7 , lang
8 , category
9 WHERE account.fkey_currency = lookup.p
10 AND code_name.fkey_lookup = lookup.p
11 AND code_name.fkey_category = category.p
12 AND category.name = 'CURRENCY'
13 AND fkey_language = lang.p
14 AND lang.name = 'English'
15 /no rows selected
Это НЕДОПУСТИМО! При правильных ссылках результат должен был быть, например, таким:
P FKEY_CURRENCY NAME
--------- ------------- ----------
17 4 USD
Как же обойти эту проблему? Это немного сложно, но все же разрешимо.
Итак, рассмотрим ситуацию несколько с другой точки зрения, а именно с точки зрения отношений между категориями и кодами. Что же мы видим из ER-диаграммы представленной на Рис. 1? Чтобы однозначно связать таблицу и справочник, мы используем два значения: код и связь между таблицей и справочником, названную нами категорией. Для организации гибкой структуры связей нам нужно использовать одно составное значение, которое и будет являться ключом справочника! Сразу хочу оговориться, подходов существует много. Мною, для иллюстрации концепций работы был выбран наиболее простой. Этот подход не очень хорош с точки зрения "чистоты" значений первичного ключа - в данном случае значение составное и несет в себе кроме простого идентификатора записи еще и принадлежность записи к категории.
Итак, ключевая фраза статьи сказана! Теперь дело за имплементацией!
Для генерации значений первичного ключа мы будем использовать последовательность (параметры последовательности могут варьироваться от системы к системе, в данный момент этому не следует уделять этому особого внимания):
CREATE SEQUENCE seq$lookup
START WITH 1
INCREMENT BY 1
MAXVALUE n
/
Теперь если применить следующую формулу для модификации значения первичного ключа в зависимости от категории:
lookup.pkey = category.p * n + seq$lookup.NEXTVAL,
где category.p - соответствующее значение из таблицы category для данной категории отношений, то мы получим искомое значение для первичного ключа таблицы lookup. Остается добавить ограничения:
CHECK (TRUNC(fkey_lookup / n) = fkey_category)
CHECK (TRUNC(fkey_payment / n) = соответствующее значение category.p)
CHECK (TRUNC(fkey_currency / n) = соответствующее значение category.p)
CHECK (TRUNC(fkey_sex / n) = соответствующее значение category.p)
Пример такой подсистемы управления справочниками представлен набором скриптов flookup.zip:
Основной файл для запуска flookup.sql. Для русского языка используется кодировка KOI8.
В случае отсутствия необходимости работы с несколькими языками, подсистему управления справочниками можно упростить, т.е. мы можем не использовать ссылку на язык. Это также приведет к тому, что нам не нужно будет использовать master-detail развязку для таблиц code_name и lookup. Если число справочников меньше 255 (и есть большая необходимость "экономить байты"), то мы можем использовать CHAR(1), как тип данных для хранения категории. В этом случае при расчете корректного значения для кода следует воспользоваться функцией ASCII. Вариаций много и все зависит от конкретного использования этого решения.
В большинстве случаев решение об использовании "Гибкой системы справочников" должно быть хорошо продумано. Это один из путей, далеко неидеальный, нахождения разумного компромисса при работе со справочниками.
Некоторые из вопросов, поднятых в этой статье, заслуживают более детального рассмотрения. Например, многоязыковая поддержка - как правильно и главное удобно реализовать данный механизм? Автор предлагает обсудить все возникшие вопросы на страницах любимого журнала. Давайте найдём разумный компромисс вместе!
Дополнительная информация:
Автор выражает благодарность Станиславу Шидловскому,
который в нужное время начал разговор о справочниках,
а также всем своим коллегам, проявившим интерес к теме статьи и высказавшим
свои замечания.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Обсудить на форуме
Oracle
Отправить ссылку на страницу по e-mail
|
Interface Ltd. Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 03.04.02 |