| СТАТЬЯ | 19.07.01 |
Структуризированный язык запросов (SQL)
Почему SQL?
Все языки манипулирования данными (ЯМД), созданные до появления реляционных баз данных и разработанные для многих систем управления базами данных (СУБД) персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их.
Рассматриваемый же ниже непроцедурный язык SQL (Structured Query Language - структуризованный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Для иллюстрации различий между ЯМД рассмотрим следующую ситуацию. Пусть, например, вы собираетесь посмотреть кинофильм и хотите воспользоваться для поездки в кинотеатр услугами такси. Одному шоферу такси достаточно сказать название фильма - и он сам найдет вам кинотеатр, в котором показывают нужный фильм. (Подобным же образом, самостоятельно, отыскивает запрошенные данные SQL.)
Для другого шофера такси вам, возможно, потребуется самому узнать, где демонстрируется нужный фильм и назвать кинотеатр. Тогда водитель должен найти адрес этого кинотеатра. Может случиться и так, что вам придется самому узнать адрес кинотеатра и предложить водителю проехать к нему по таким-то и таким-то улицам. В самом худшем случае вам, может быть, даже придется по дороге давать указания: "Повернуть налево... проехать пять кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.)
Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам:
Разработка, в основном, шла в отделениях фирмы IBM (языки ISBL, SQL, QBE) и университетах США (PIQUE, QUEL) [3]. Последний создавался для СУБД INGRES (Interactive Graphics and Retrieval System), которая была разработана в начале 70-х годов в Университете шт. Калифорния и сегодня входит в пятерку лучших профессиональных СУБД. Сегодня из всех этих языков полностью сохранились и развиваются QBE (Query-By-Example - запрос по образцу) и SQL, а из остальных взяты в расширение внутренних языков СУБД только наиболее интересные конструкции.
В начале 80-х годов SQL "победил" другие языки запросов и стал фактическим стандартом таких языков для профессиональных реляционных СУБД. В 1987 году он стал международным стандартом языка баз данных и начал внедряться во все распро-страненные СУБД персональных компьютеров. Почему же это произошло?
Непрерывный рост быстродействия, а также снижение энергопотребления, размеров и стоимости компьютеров привели к резкому расширению возможных рынков их сбыта, круга пользователей, разнообразия типов и цен. Естественно, что расширился спрос на разнообразное программное обеспечение.
Борясь за покупателя, фирмы, производящие программное обеспечение, стали выпускать на рынок все более и более интеллектуальные и, следовательно, объемные программные комплексы. Приобретая (желая приобрести) такие комплексы, многие организации и отдельные пользователи часто не могли разместить их на собственных ЭВМ, однако не хотели и отказываться от нового сервиса. Для обмена информацией и ее обобществления были созданы сети ЭВМ, где обобществляемые программы и данные стали размещать на специальных обслуживающих устройствах - файловых серверах.
СУБД, работающие с файловыми серверами, позволяют множеству пользователей разных ЭВМ (иногда расположенных достаточно далеко друг от друга) получать доступ к одним и тем же базам данных. При этом упрощается разработка различных автоматизированных систем управления организациями, учебных комплексов, информационных и других систем, где множество сотрудников (учащихся) должны использовать общие данные и обмениваться создаваемыми в процессе работы (обучения). Однако при такой идеологии вся обработка запросов из программ или с терминалов пользовательских ЭВМ выполняется на этих же ЭВМ. Поэтому для реализации даже простого запроса ЭВМ часто должна считывать из файлового сервера и (или) записывать на сервер целые файлы, что ведет к конфликтным ситуациям и перегрузке сети.
Для исключения указанных и некоторых других недостатков была предложена технология "Клиент-Сервер", по которой запросы пользовательских ЭВМ (Клиент) обрабатываются на специальных серверах баз данных (Сервер), а на ЭВМ возвращаются лишь результаты обработки запроса. При этом, естественно, нужен единый язык общения с Сервером и в качестве такого языка выбран SQL. Поэтому все современные версии профессиональных реляционных СУБД (DB2, Oracle, Ingres, Informix, Sybase, Progress, Rdb) и даже нереляционных СУБД (например, Adabas) используют технологию "Клиент-Сервер" и язык SQL. К тому же приходят разработчики СУБД персональных ЭВМ, многие из которых уже сегодня снабжены языком SQL.
Бытует мнение: Поскольку большая часть запросов формулируется на SQL, практически безразлично, что это за СУБД - был бы SQL.
Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволило создать компактный язык с небольшим (менее 30) набором предложений. SQL может использоваться как интерактивный (для выполнения запросов) и как встроенный (для построения прикладных программ). В нем существуют:
В SQL используются следующие основные типы данных, форматы которых могут несколько различаться для разных СУБД:
В некоторых СУБД еще существует тип данных LOGICAL, DOUBLE и ряд других. СУБД INGRES предоставляет пользователю возможность самостоятельного определения новых типов данных, например, плоскостные или пространственные координаты, единицы различных метрик, пяти- или шестидневные недели (рабочая неделя, где сразу после пятницы или субботы следует понедельник), дроби, графика, большие целые числа (что стало очень актуальным для российских банков) и т.п.
Ориентированный на работу с таблицами SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому в разных СУБД он либо используется вместе с языками программирования высокого уровня (например, такими как Си или Паскаль), либо включен в состав команд специально разработанного языка СУБД (язык систем dBASE, R:BASE и т.п.). Унификация полных языков современных профессиональных СУБД достигается за счет внедрения объектно-ориентированного языка четвертого поколения 4GL. Последний позволяет организовывать циклы, условные предложения, меню, экранные формы, сложные запросы к базам данных с интерфейсом, ориентированным как на алфавитно-цифровые терминалы, так и на оконный графический интерфейс (X-Windows, MS-Windows).
Таблицы SQL
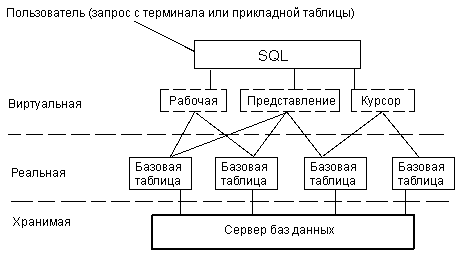
До сих пор понятие "таблица", как правило, связывалось с реальной или базовой таблицей, т.е. c таблицей, для каждой строки которой в действительности имеется некоторый двойник, хранящийся в физической памяти машины (рис.1.2). Однако SQL использует и создает ряд виртуальных (как будто существующих) таблиц: представлений, курсоров и неименованных рабочих таблиц, в которых формируются результаты запросов на получение данных из базовых таблиц и, возможно, представлений. Это таблицы, которые не существуют в базе данных, но как бы существуют с точки зрения пользователя.
Базовые таблицы создаются с помощью предложения CREATE TABLE (создать таблицу), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания описания таблицы Блюда:
Рис. 1.2. База данных в восприятии пользователя
CREATE TABLE Блюда (БЛ SMALLINT, Блюдо CHAR (70), В CHAR (1), Основа CHAR (10), Выход FLOAT, Труд SMALLINT);
Предложение CREAT TABLE специфицирует имя базовой таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером). CREAT TABLE - выполняемое предложение. Если его ввести с терминала, система тотчас построит таблицу Блюда, которая сначала будет пустой: она будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Однако можно немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT и создать таблицу, аналогичную таблице Блюда.
Если теперь потребовалось узнать какие овощные блюда может приготовить повар пансионата, то можно набрать на терминале следующий текст запроса:
SELECT БЛ,Блюдо FROM Блюда WHERE Основа = 'Овощи';и мгновенно получить на экране следующий результат его реализации:
| БЛ | Блюдо |
|---|---|
| 1 | Салат летний |
| 3 | Салат витаминный |
| 17 | Морковь с рисом |
| 23 | Помидоры с луком |
Для выполнения этого предложения SELECT (выбрать), подробное описание которого будет дано в главах 2 и 3, СУБД должна сначала сформировать пустую рабочую таблицу, состоящую из столбцов БЛ и Блюдо, тип данных которых должен совпадать с типом данных аналогичных столбцов базовой таблицы Блюда. Затем она должна выбрать из таблицы Блюда все строки, у которых в столбце Основа хранится слово Овощи, выделить из этих строк столбцы БЛ и Блюдо и загрузить укороченные строки в рабочую таблицу. Наконец, СУБД должна выполнить процедуры по организации вывода содержимого рабочей таблицы на экран терминала (при этом если в рабочей таблице содержится более 20-24 строк, она должна использовать процедуры постраничного вывода и т.п.). После выполнения запроса СУБД должна уничтожить рабочую таблицу.
Если, например, надо получить значение калорийности всех овощей, включенных в таблицу Продукты, то можно набрать на терминале запрос
SELECT Продукт, Белки, Жиры, Углев,
((Белки+Углев)*4.1+Жиры*9.3)
FROM Продукты
WHERE Продукт IN ('Морковь','Лук','Помидоры','Зелень');
и получить на экране следующий результат его реализации:
| Продукт | Белки | Жиры | Углев | ((Белки+Углев)*4.1+Жиры*9.3) |
|---|---|---|---|---|
| Морковь | 13. | 1. | 70. | 349.6 |
| Лук | 17. | 0. | 95. | 459.2 |
| Помидоры | 6. | 0. | 42. | 196.8 |
| Зелень | 9. | 0. | 20. | 118.9 |
В последнем столбце этой рабочей таблицы приведены данные о калорийности продуктов, отсутствующие в явном виде в базовой таблице Продукты. Эти данные вычислены по хранимым значениям основных питательных веществ продуктов, помещены в рабочую таблицу и будут существовать до момента смены изображения на экране. Однако если необходимо сохранить эти данные в какой-либо базовой таблице, то существует предложение (INSERT), позволяющее переписать содержимое рабочей таблицы в указанные столбцы базовой таблицы (реляционная операция присваивания).
Часто пользователя не устраивает как способ описания нужного набора выводимых строк, так и результат выполнения запроса, сформированного из данных одной таблицы. Ему хотелось бы уточнить выводимые (запрашиваемые) данные сведениями из других таблиц.
Например, в запросе на получение состава овощных блюд
SELECT БЛ,ПР,Вес FROM Состав WHERE БЛ IN (1,3,17,23);
пришлось перечислять номера этих блюд, так как в таблице Состав нет данных об основных продуктах блюда (они есть в таблице Блюда). Полученный состав овощных блюд (рис.1.3,а) оказался "слепым": в нем и блюда и продукты представлены номерами, а не именами. Удобнее и нагляднее (рис.1.3,б)
| а) | б) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Рис. 1.3. Состав овощных блюд базы данных ПАНСИОН
запрос сформированный по трем таблицам:SELECT Блюдо, Продукт, Вес FROM Состав,Б люда, Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР AND Основа = 'Овощи';
В нем для получения рабочей таблицы выполняется естественное соединение таблиц Блюда, Продукты и Состав (условие соединения - равенство значений номеров блюд и значений номеров продуктов). Затем выделяются строки, у которых в столбце Основа хранится слово Овощи, и из этих строк - столбцы Блюдо, Продукт и Вес.
Если пользователи достаточно часто интересуются составом различных блюд, то для упрощения формирования запросов целесообразно создать представление.
Представление - это пустая именованная таблица, определяемая перечнем тех столбцов таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. Представление является как бы "окном" в одну или несколько базовых таблиц. Оно создается с помощью предложения CREATE VIEW (создать представление), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания представления Состав_блюд:
CREATE VIEW Состав_блюд AS SELECT Блюдо, Продукт, Вес FROM Состав,Блюда,Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР;
Оно описывает пустую таблицу, в которую при реализации запроса будут загружаться данные из столбцов Блюдо, Продукт и Вес таблиц Блюда, Продукты и Состав, соответственно. Теперь для получения состава овощных блюд можно дать запрос
SELECT Блюдо,Продукт,Вес FROM Состав_блюд WHERE Основа = 'Овощи';
и получить на экране терминала данные, которые представлены на рис. 1.3,б. А для получения состава супа Харчо можно дать запрос
SELECT Блюдо, Продукт, Вес FROM Состав_блюд WHERE Блюдо = 'Суп харчо';
О целесообразности создания представлений будет рассказано ниже, а здесь лишь отметим, что они позволяют повысить уровень логической независимости данных, упростить их восприятие и "скрыть" от некоторых пользователей те или иные данные, например, данные о новых ценах на продукты первой необходимости или из какой рыбы приготавливается "Судак по-польски".
Наконец, еще об одних виртуальных таблицах - курсорах. Курсор - это пустая именованная таблица, определяемая перечнем тех столбцов базовых таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. В чем же различие между курсором и представлением?
Для пользователя представления почти не отличаются от базовых таблиц (есть лишь некоторые ограничения при выполнении различных операций манипулирования данными). Они могут использоваться как в интерактивном режиме, так и в прикладных программах. Курсоры же созданы для процедурной работы с таблицей в прикладных программах. Например, после объявления курсора
DECLARE Блюд_состав CURSOR FOR SELECT Блюдо,Продукт,Вес FROM Состав,Блюда,Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР AND Блюдо = 'Суп харчо';
и его активизации (OPEN Блюд_состав) будет создана временная таблица с составом блюда "Суп харчо" и специальным указателем, определяющим в качестве текущей первую строку этой таблицы. С помощью предложения FETCH (выбрать), которое обычно исполняется в программном цикле, можно присвоить определенным переменным значения указанных столбцов этой строки. Одновременно курсор будет передвинут к следующей строке таблицы. После обработки в программе полученных значений переменных выполняется следующее предложение FETCH и т.д. до окончания перебора всех продуктов Харчо.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Отправить ссылку на страницу по e-mail
Обсудить на форуме Oracle
| Interface Ltd. Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 19.07.01 |