 |
| СТАТЬЯ |
22.09.00
|
Десять главных рекомендаций по настройке приложений
Я надеюсь, что по мере повышения уровня понимания проблем функционирования приложений и Oracle, читатели смогут оценить возможный эффект от модификаций системы, влияние изменений параметров, а также преимущества и недостатки различных аппаратных настроек, и не останутся в неведении относительно причин возникновения этих эффектов.
Обычно веское слово "настройка" означает вид ремонта, который можно попросить выполнить автомеханика, чтобы продлить жизнь старого драндулета. Покупатель машины не собирается платить дополнительно за настройку своей новой машины, чтобы она смогла выехать из гаража перед домом. Настройка не сможет превратить фургон для развозки молока в гоночную машину для Формулы1.
Производительность часто игнорируется потому, что с этой проблемой не сталкиваются в среде разработки. Однако, проблема производительности быстро становится очевидной в реальном мире, в среде эксплуатации. Различия между этими средами может оказывать огромное влияние на производительность системы.
| Типичная среда разработки | Типичная среда эксплуатации |
| Быстрая локальная сеть | Медленная глобальная сеть |
| Малое количество пользователей на сильных процессорах | Большое количество пользователей на слабых процессорах |
| 10 - 100 строк в таблице EMP | 5 - 10 миллионов записей о клиентах |
Рекомендация1: Тестирование и оценка производительности всегда должны производиться в условиях реальной эксплуатации задач.
|
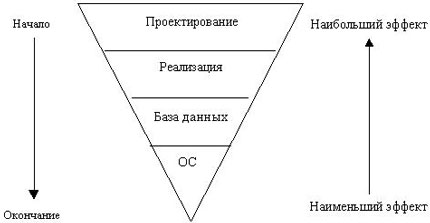
Существует две причины для того, чтобы начать работу с верха этой диаграммы и спускаться вниз.
Уровень базы данных состоит из настройки ядра Oracle, установки соответствующих параметров в файле init.ora, что приведет к более эффективному использованию памяти (например, оценка размеров кеша буфера (buffer cache) и разделяемого пула (shared pool)) и сокращению конфликтов между процессами (например, соответствующее количество сегментов отката). Правильная настройка может повысить производительность на 20-25% .
На уровене реализации рассматриваются SQL-предложения, пути доступа к данным, использование соответствующих индексов и т.д. Оптимизация в этой области в отдельных случаях может сократить время реакции от часов до секунд.
Уровень проектирования, как правило, находится вне границ рассмотрения к моменту выполнения настройки, так как обычно считается, что слишком дорого пересматривать весь проект и вносить существенные изменения. Однако, на этом уровне, польза от изменений поистине огромна. Приведем в пример систему, которая запускает пакет заданий, работающих по 3 часа каждую ночь для согласования финансовых показателей, которые на самом деле требуются раз в месяц, или, возможно, вообще не используются!
В любой большой организации за каждый из рассмотренных выше уровней обычно ответственны различные отделы. Если проблема производительности не обсуждалась до ввода системы в промышленную эксплуатацию, то именно администратору базы данных приходится заниматься настройкой системы. На рынке существует большое количество инструментов мониторинга и настройки, предназначенных для АБД (DBA). Но даже при использовании самых лучших инструментов, результат, которого может добиться администратор баз данных, очень мал по сравнению с выгодой от работ по настройке, предпринятых ранее, в период разработки.
Обычно разработчики стремятся сконцентрироваться на реализации в установленный срок всех функциональных требований к системе, а не на том, чтобы гарантировать удовлетворительную ее производительность. Большинство доступных инструментов настройки не могут улучшить ситуацию, поскольку они либо не используются совсем, будучи плохо изучены, либо имеют бедный интерфейс, который не может соперничать с привлекательным видом инструментария в стиле Developer/2000.
Идеальная команда настройки должна включать специалистов всех стадий жизненного цикла системы, использовать и согласовывать их индивидуальное мастерство, добиваясь целостного подхода к проблеме.
Рекомендация2: С самого начала надо избрать правильное направление своих действий.
При необходимости исследования проблемы производительности, выгодно использовать метод "до и после" для демонстрации эффекта от различных системных изменений. Это может быть сделано для того, чтобы убедить клиента, что настройщик действительно знаком с темой, что он обеспечит некоторое улучшение производительности, и, на самом деле, заслуживает того большого количества денег, которые были заплачены за его услуги :-).
К сожалению, большинство встречающихся систем не имеет какого-либо заданного критерия производительности или запланированного времени реакции, к достижению которых можно было бы направить усилия по настройке. Цель обычно формулируется, как "заставить ее работать быстрее". Гораздо хуже дела обстоят в той организации, где проблема выросла до таких размеров, что никакая форма явного мониторинга не представляется возможной, поскольку это может вызвать во время выполнения настройки ухудшение и без того плохой производительности. В тех случаях, когда систему нельзя трогать, а клиент требует точно сказать, какие значения должны быть изменены, для оптимального выполнения, рекомендуется надежный магический кристалл...
Использование прогрессивного научного подхода, который документирует собранные факты, может быть проводником не только в максимальном улучшении системной производительности, но также помогает значительно лучше понять, как система функционирует в действительности. При этом возможно определение потенциальных узких мест, которые проявятся, когда система начнет расширяться для приспособления к большему количеству пользователей, большим объемам данных или изменению бизнес-требований.
С этой целью, в системе, для которой можно подготовить повторяющиеся "контрольные примеры" прохода по приложению, должно выполняться одновременно только небольшое количество изменений. Таким контрольным примером, например, может быть отдельная пользовательская сессия, для которой сохраняется и может быть проиграна повторно последовательность нажатых клавиш, либо документ, в котором точно записана последовательность вводимых экранов. Пользователи же обычно предоставляют такие входные данные, экраны и транзакции, которые являются одновременно, и медленными, и ключевыми для их бизнеса: они выполняются много тысяч раз за день. Как правило, нет необходимости выполнять многопользовательский тест, кроме случаев, когда проблемой является конкуренция между пользователями, поскольку большинство SQL-настроек могут быть выполнены с неменьшим успехом на отдельной маленькой пользовательской сессии. А в этом случае гораздо легче выполнять повторяющийся контрольный тест.
При запуске, по крайней мере, дважды контрольного примера или любого SQL-предложения в качестве теста будет достигнуто устойчивое состояние, при котором SQL-предложения уже разобраны и помещены в разделяемый пул, и все необходимые данные содержатся в буферном кеше. Для реальной эксплуатации это может быть не типичным, но позволяет сделать научные сравнения с известными базовыми значениями и быстро определять разницу в результате системных изменений.
При использовании одного из многих SQL-скриптов, предназначенных для наблюдения за внутренней производительностью ядра Oracle, следует сосредоточиться на разделах, оказывающих реальное влияние на выполнение. Например, если элемент имеет частоту успешных попаданий (hit rate) в кеш около 50 %, но обращение к нему происходит лишь дважды в день, то он, вероятно, не заслуживает того времени, которым необходимо пожертвовать для увеличения его частоты успешных попаданий.
Рекомендация3: При разработке приложений следует использовать научную методологию.
Начиная с Developer/2000 и Oracle7 версии 7.3, среда разработки обогатилась многими новыми возможностями, но стала более сложной. PL/SQL на стороне клиента, логика на стороне сервера, процедуры, триггеры, каналы, сигналы, таймеры, серверы OLE2 и т. д. - существует много способов для выполнения одной и той же задачи. Некоторые из этих способов более эффективны, чем другие. Можно написать сложную PL/SQL процедуру для проверки правильности данных, но Forms сделает это проще. Некоторые спецы, начмнавшие еще с Forms 2, не будут даже рассматривать написание кода для выполнения такой функции, но таких опытных разработчиков слишком мало, в то время как количество пользователей растет с фантастической скоростью, и затраты на обучение и время на разработку часто становятся первыми жертвами сокращений. Мало используются такие возможности, как зеркальные элементы (mirror items) в Forms. При этом разработчики проводят много часов, воспроизводя аналогичную функциональность самостоятельно, со значительно большими издержками.
Рекомендация4: Использование каждого инструментального средства должно соответстовать его возможностям и назначению.
Сети обычно измеряются в терминах производительности, т.е. пропускной способности. Это, возможно, имеет смысл для сетей, сконфигурированных для передачи данных или файлов, например файловых серверов, но не для приложений клиент/сервер, использующих SQL*Net. Измерение пропускной способности аналогично сидению на обочине автострады и подсчитыванию количества проезжающих мимо машин за одну секунду. Эти цифры ничего не скажут о том, сколько времени потребуется конкретному автомобилю, чтобы доехать до пункта назначения и вернуться назад. Это время прохождения является важным измерением, поскольку каждый пакет должен быть квитирован перед тем, как следующий пакет будет отправлен.
Очевидно, что если автострада/сеть занята и возникает значительное количество конфликтных ситуаций, то пропускная способность существенно снижается.
Время ответа удаленного узла обычно может быть измерено с помощью утилиты, называемой ping. Типичным временем для LAN является 2-3 микросекунды, в то время как типичным временем для WAN может быть 50-100 микросекунд или больше. В зависимости от инструмента, использованного для разработки клиентской части приложения, каждое SQL-предложение может в действительности генерировать много пакетов, каждый из которых перед тем как сервер сможет начать выполнение транзакции должен быть передан по сети и квитирован. Это создает значительную задержку в сети, признаком чего является большое количество маленьких пакетов (20-30 байт), которые можно увидеть, используя "sniffer" (сетевой анализатор пакетов). Когда данные выбираются по одной строке, то порождается большое количество пакетов. При использовании эффективного массива выборки (array fetch), извлекающего нескольких записей за один прием, порождается меньшее количество больших по размеру пакетов. Это выгодно, так как время прохождения не зависит от размера пакета.
Очень сложно улучшить время прохождения по сети без значительных капиталовложений в инфраструктуру. Следовательно, наибольшие усилия по улучшению сетевого выполнения должны быть направлены на уменьшение количества генерируемых пакетов.
Старые инструменты, такие как Forms 3, не предназначены для работы в режиме клиент/сервер через WAN, поскольку они порождают большой сетевой трафик. Например, каждый столбец, перечисленный в SQL -предложении, будет описан в отдельном пакете для определения его типа данных, каждый параметр будет отдельно связан со значением, каждое предложение where будет передано отдельно. Таким образом, сложное SQL-предложение может генерировать несколько дюжин пакетов. Это существенно отличается от способа, при котором приложение в блочном режиме передает серверу только измененные байты на экране и получает ответ в режиме обработки транзакции. Время реакции этих двух режимов сравнивать бессмысленно.
Oracle Forms 4 и сервер Oracle 7 гораздо эффективнее используют сетевой трафик и откладывают связывание до фактического выполнения SQL-предложения, в котором указатель на SQL и значения переменных могут быть переданы в отдельном пакете (предполагается, что SQL-предложения уже разобраны и хранятся в разделяемом пуле).
Заметим, что эффективное использование сети не зависит от того, какая используется версия SQL*Net. Как версия 1, так и версия 2 SQL*Net может быть использована эффективно или неэффективно. Ни одна из версий не имеет параметров настройки, способных существенно улучшить сетевое выполнение.
Единственным реальным вариантом настройки плохо выполняющейся системы клиент/сервер является перенос как можно большего количества SQL-кода с клиентской стороны в хранимые процедуры, которые могут вызываться значительно эффективнее, а также изменение интерфейса пользователя для работы в "блочном режиме", ликвидируя ту часть взаимодействий с базой данных, которые вызваются для навигации между полями. Оба эти подхода поглощают очень много времени и могут быть классифицированы скорее как перепроектирование, чем как тонкая настройка.
Рекомендация5: Плохая вычислительная сеть сводит на нет все усилия по настройке.
Исследования показывают, что при среднем времени реакции в одну секунду, 90% ответов укладываются в интервал 2.3 сек. При стремлении объять до 100% ответов, разница между вероятностным и средним временем реакции возрастет еще больше: 99.9% ответов занимают интервал уже в 6,9 секунд (при том же среднем - 1 сек).
Следовательно, если техническими условиями контракта обусловлено, что время реакция на запрос с вероятностью 99.9% не должно превышать 5 секунд, то среднее ее время должно быть около 0.7 сек!
Существует также прямая зависимость между степенью использования ресурса (например, процессора, диска) процессом, обслуживающим запрос, и создаваемой при этом очередью, приводящей к ухудшению производительности системы. Во избежание создания очередей, медленные устройства, такие как диски, следует использовать не более, чем на 40%. Центральные процессоры в интерактивной обработке следует загружать до 70-75% . Тогда лишь при очень большей загрузке начнут создаваться очереди. В реальном мире время реакции и время процесса не настолько случайны, как в теории, поэтому описанный эффект может оказаться не таким сильным, как здесь предполагалось. Однако теоретические значения следует использовать как оценки в наихудших обстоятельствах.
Рекомендация6: Нельзя изменить законы физики (и математики).
1. Проверяется синтаксис SQL-предложения.
2. Проверяются права доступа, чтобы убедиться, что пользователь имеет достаточно привилегий для выполнения этого SQL-предложения.
3. Выполняется проверка: имеется ли в разделяемом пуле идентичное предложение, которое обращается к тем же объектам.
3.1. Если предложение найдено, то осуществляется переход к шагу 7.
4. По словарю данных проверяются на достоверность имена таблиц, столбцов и других объектов.
4.1. Если эта информация еще не содержится в словарном кэше, то должны выполниться
дополнительные SQL-предложения (рекурсивные SQL-запросы), запрашивающие
информацию об объектах из словаря данных Oracle.
5. Встроенный оптимизатор вычисляет наилучший план выполнения.
6. Текст SQL-предложения и план выполнения сохраняются в разделяемом пуле.
7. Входные переменные связываются с их реальными значениями.
8. SQL-предложение выполняется.
9. Если предложение является запросом, то выполняются операции по извлечению строк.
Исходя из порядока перечисленных выше действий, видно, что для повышения производительности системы очень важна эффективность операций, выполняемых в разделяемом пуле. Разделяемый пул содержит не только библиотечный кэш SQL-предложений и PL\SQL-блоков, но и словарный кэш, хранящий необходимую информацию об объектах базы данных.
После запуска экземпляра базы данных, когда разделяемый пул пуст, каждое SQL-предложение будет вызывать какое-то число рекурсивных SQL-запросов к словарю данных. Через некоторое время после запуска экземпляра, когда к большинству объектов базы данных, хотя бы один раз, было обращение, количество рекурсивных SQL-предложений стремится к нулю. Если этого не происходит, то ваш разделяемый пул слишком мал и его необходимо существенно увеличить.
С другой стороны, если предполагается выполнение запросов свободного формата или же использование инструментария и/или приложений, не использующих связанных переменных, то крайне нежелательно использование SQL-предложений, выполненных ранее другим пользователем. В этом случае сводятся на нет все достоинства библиотечного кэша, созданного для того, чтобы позволить разделять SQL-предложения между многими пользователями. Частота успешных обращений к кэшу и набор SQL-предложений, содержащихся в разделяемом пуле, связаны напрямую. Принципы, применимые к настройке библиотечного кэша, применимы и к настройке буферного кэша. По закону сокращающихся доходов, добавление дополнительной памяти к разделяемому пулу может принести очень мало пользы или вообще ничего не изменит.
Рекомендация7. Понимание, как работает приложение, является первым шагом к повышению его производительности.
Рассмотрим случай, когда каждый блок данных содержит большое число небольших строк, например номера отделов и их еженедельный доход. Новые данные в каждый блок вставляются один раз в неделю. Распределение данных таково, что каждый блок содержит информацию о каждом отделе. При вычислении общего дохода для отдела 10, может быть придется обратиться только к 1% значений, но при этом необходимо просмотреть каждый блок данных, поэтому полное сканирование таблицы будет более эффективным. В слабо связанных системах (Lightly loaded systems), использующих опцию параллельных запросов (Oracle Parallel Query), сканирование огромных объемов данных может осуществляться быстрее, чем поиск по индексам даже небольших фрагментов информации.
Потенциальное использование индекса следует учитывать при его создании. Индексы на столбцы с низкой селективностью не выполняют никаких функций, занимают память и являются причиной ухудшения производительности из-за их модификации после каждого изменения в таблице. Составные индексы позволяют получить значения требуемых столбцов без просмотра блоков данных таблицы. Поэтому их особенно полезно использовать при сложном плане выполнения предложения или в том случае, когда в результате просмотра таблицы большинство строк отвергается. Преимущества составных индексов должны быть сравнимы со стоимостью их создания и поддержки.
Оптимизатор Oracle, основанный на стоимости (или статистике), теперь значительно улучшен, и в версии Oracle7 Release7.3 может выбирать план выполнения, о котором нельзя было и подумать в старом оптимизаторе, основанном на правилах синтакса. Синтаксический оптимизатор всегда использует индекс, если он существует, тогда как стоимостной оптимизатор не сделает этого, если он вычислит, что полное сканирование таблицы обойдется дешевле. Это решение основывается на количестве блоков, которые необходимо просмотреть, и на числе чтений диска, которые необходимо выполнить. Поэтому есть опасность, что неоправданно высокое значение параметра db_file_multiblock_read_count , установленное в файле настройки init.ora, может заставить оптимизатор поверить, что обращение к диску намного выгоднее, чем это есть на самом деле, что вызовет неоправданное число полных просмотров таблицы.
Стоимостной оптимизатор еще не умеет определять, что вы хотите сделать. Он может реагировать только на то, что его просят сделать, используя ту небольшую информацию, которая ему доступна. Для обеспечения оптимальной производительности во время тестирования на реальном объеме данных разработчикам следует использовать свои знания о требованиях, предъявляемых приложением, и о его данных, чтобы суметь выдать правильные подсказки оптимизатору.
Рекомендация8. Даже небольшая настройка SQL-предложений может значительно улучшить их производительность.
RAID-устройства.
Вообще-то, Oracle использует все, что находится под управлением операционной системы, и поэтому невидимо для программного обеспечения Oracle. Это, например, - разделение дисков (disk striping), зеркалирование/затенение (mirroring/shadowing), а также RAID-устройства. Каждый из этих механизмов следует рассматривать в контексте общей функциональности и не считать их применение ответом на все возможные проблемы. Функциональность этих устройств можно рассматривать в двух аспектах - устойчивость, то есть защита от сбоев, и производительность.
Пример: пользователь с 4 дисковыми устройствами хочет защититься от сбоев на каждом из них. Одним из вариантов решения этой задачи является зеркальное отражение (RAID 0). В этом случае операции с каждым диском полностью дублируются другим носителем, но приобретение 4 добавочных дисков стоит дорого. С точки зрения организации работы, Oracle не ждет полного завершения каждой операции записи на оба диска. Поэтому возможно, что система с зеркальными дисками будет работать немного лучше, чем без зеркалирования, поскольку теперь при каждой операции любая их двух головок может считывать с диска данные, и одна из них обычно ближе к требуемой позиции, что уменьшает время доступа.
RAID уровня 1 - это простое распределение данных по всем дискам, отказоустойчивость при этом не обеспечивается. Потенциальная возможность полного отказа повышается, так как все данные теперь разбросаны по всем дискам и, независимо от того, какой диск поврежден, информация теряется.
RAID уровня 2 и 4 очень редко используются.
RAID уровня 3 позволяют 4 дискам из вышеописанного примера полностью защититься с помощью отдельного специального диска. Этот специальный диск содержит результат вычисления четности, считанной с 4 дисков данных, поэтому восстановление любого отказавшего диска и его информации можно осуществить с помощью оставшихся дисков данных и диска четности. С точки зрения устойчивости, этот уровень обеспечивает надежность без необходимости зеркального отражения каждого диска.
RAID уровня 5 похож на RAID уровня 3, но значение четности теперь содержится на каждом диске вместе с данными, а не на специальном диске для хранения четности. Добавочный диск все же требуется для хранения имеющегося на данный момент объема данных и значений четности.
Основные проблемы производительности можно увидеть, сравнивая работу системы из 4 дисков рассмотренного выше примера с 5 дисками, работающими под RAID уровней 3 и 5. Операция записи на каждый диск выполняется теперь по одному из двух вариантов: запись на диск данных и диск для хранения четности или запись на все диски для обновления четности. В результате все диски становятся также загружены, как самый загруженный диск в исходной системе из 4 дисков.
Некоторые поставщики теперь предлагают вариант RAID 5+, который использует большой кэш памяти для устранения некоторых узких мест, возникающих при записи.
Иногда достоинствами разделения дисков RAID-устройств невозможно воспользоваться. Вспомните, что Oracle выполняет операции чтения/записи в файлы базы данных блоками, имеющими обычно размер по 2К или 4К. Даже если есть возможность чтения нескольких блоков, все равно нельзя запросить более 64К данных за один раз. В результате, обычная RAID-система с полосой (stripe) размером 1МВ, будет направлять все операции чтения на первый диск за несколько минут, затем на второй диск и так далее. Для оптимальной производительности Oracle рекомендует размер полосы от 32К до 64К.
С нереляционными системами, имеющими доступ к очень большим файлам, RAID-устройства работают намного лучше, запрашивая мегабайты данных за раз. Системы, которые выполняют мало обновлений или вообще их не делают, также предпочтительнее, так как данные четности не так часто перезаписываются.
Файлы журналов (redo logs) создаются как последовательные файлы и никогда не должны записываться или храниться на RAID-устройствах.
Рекомендация9. Вложение разумных средств в повышение производительности всегда оправдано.
Небуферируемые (raw) устройства на UNIX.
Использование небуферируемых (raw - сырые) устройств, то есть на которых нет файловых систем UNIX, может привести к хорошей производительности в системах с интенсивной записью. Системы, в которых число операций чтения большее, чем операций записи, имеют больше преимуществ за счет добавочного кэширования, поддерживаемого файловой системой UNIX. Главный недостаток небуферируемых устройств - это отсутствие имеющихся в файловых системах механизмов по управлению файлами, резервного копирования, восстановления и так далее, что делает управление системой более громоздким. Как правило, следует использовать небуферируемые устройства только при необходимости.
Размер блока базы данных.
Часто задают вопрос «Повысит ли мою производительность изменение размера блока ?». Ответ, как всегда, звучит: «Это зависит от …». Обычно это зависит от конфигурации системы.
Oracle записывает данные в файлы базы данных и считывает их блоками. Следовательно, размер блока данных Oracle всегда должен быть кратным размеру блока операционной системы. Если в большинстве обращений к БД происходит полное сканирование таблицы или операции по обработке большей части записей выполняются внутри каждого блока, то число обращений к диску уменьшится за счет большого размера блока, и производительность слегка улучшится. Однако, при выполнении операций по чтению или изменению небольшой части блока, например, единственной строки, производительность системы снизится из-за затрат Oracle на считывание большого блока данных в память, в то время, как требуется только эта строка. Размер блока базы данных - это не счастливый билет, и изменение его размера не превратит плохо работающие системы в хорошие.
Фрагментация и размер объекта.
Существует мнение, что разброс объектов по нескольким экстентам понижает производительность, поэтому объекты должны находиться в одном экстенте. Это неправда. Фрагментация строк, в результате которой происходит связывание блоков, действительно наносит серьезный ущерб производительности, но тот факт, что таблица состоит из десяти экстентов вместо одного, не имеет особого значения. Время, затраченное на дефрагментацию объекта, не сможет компенсировать потерю производительности.
Другие считают, что следует избегать динамического расширения объектов, так как оно приводит к потере производительности. Так стоит вопрос более с точки зрения планирования и подготовки, чем производительности, так как обычный объект не будет динамически расширяться много раз в день. Расширение объектов можно отследить, корректно изменить размер следующего экстента и даже перераспределить время, на которое было рассчитано ранее.
Основное достоинство небольшого количества экстентов заключается в том, что в этом случае становится легче распределять и конфигурировать пространство внутри базы данных, создавать новые объекты и перемещать существующие объекты. Обдуманное и последовательное использование параметров, определяющих размер объекта, может помочь в этом отношении.
Во избежание конфликтной ситуации и ограничения числа динамических расширений, сегменты отката должны располагаться в нескольких экстентах. Oracle рекомендует создавать сегменты отката в 20 экстентах.
Фрагментация строк возникает в случае их изменения. Например, после начальной вставки строки некоторые столбцы имели непустое значение, а остальные - null. В дальнейшем эти строки изменились. В результате может образоваться цепочка связанных блоков, ухудшающая производительность. Цепочку блоков можно уменьшить, установив параметр pctfree так, чтобы зарезервировать место в каждом блоке для предстоящих изменений.
Когда известно, что данные только вставляются, удаляются или читаются, но никогда не изменяются, то значение pctfree может быть 0. При этом каждый блок данных заполняется до максимального значения и затраты памяти уменьшаются на 10% по сравнению со случаем, когда значение pctfree установлено по-умолчанию. Кроме того, повышается производительность, так как в процессе полного сканирования таблицы должно быть прочитано на 10% блоков меньше.
Параметр pctincrease всегда должен быть установлен в 0, так как это позволяет DBA лучше управлять размером последующих экстентов (объект с initial экстентом 10К и pctincrease 50% затребует 31-ый экстент размером 1GB). Значение maxextents должно быть установлено ниже физического ограничения, что даст возможность DBA управлять непредсказуемым ростом объекта и делать соответствующие действия до того, как он натолкнется на какое-либо реальное ограничение.
Следует изучить рекомендации Oracle's OFA (Oracle's Optimal Flexible Architecture - Оптимальная Гибкая Архитектура Oracle), которые позволяют разобраться в построении области базы данных на дисках, задают методологические правила для создания оптимально сконфигурированной базы данных.
Рекомендация10. Не следует верить мифам и магическим заклинаниям.
За дополнительной информацией обращайтесь в Interface Ltd.
Interface Ltd.Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
вебмастеру
|