 |
| СТАТЬЯ |
22.09.00
|
Эта
статья впервые была размещена
на сайте www.oramag.ru
Ричард Дж. Нимик
Во второй статье серии, посвященной настройке базы данных для электронного бизнеса, рассматриваются проблемы обработки запросов, что приводит к незамедлительному увеличению производительность базы.
В первой статье (“Основные направления настройки …”) я предложил несколько рекомендаций по выделению правильного объема памяти для базы данных Oracle, кэшированию в памяти данных, к которым наиболее часто бывают обращения, и выделению проблемных запросов, причем каждый из этих вопросов существенно влияет на настройку производительности. В этой статье я хочу уделить внимание именно проблемным запросам, то есть, тем запросам, для выполнения которых требуется наибольшее количество операций физического или логического чтения диска, и решению вопроса о том, что с ними можно сделать, чтобы увеличить производительность базы данных.
Знайте свою систему
Прежде, чем начать корректировать запросы, убедитесь, что вы хорошо знаете свою систему. Ни один из методов настройки запросов не может быть одинаково успешно применен во всех ситуациях, и для того, чтобы выбрать наилучший подход, вы должны хорошо знать систему. Так, например, следует хорошо представлять себе объем данных, содержащихся в вашей базе данных, и их распределение. Кроме того, нужно знать “узкие места” вашей системы, а также понимать, почему предпринятая вами настройка не достигла своей цели, принимая во внимание факторы из предыдущей статьи. Вспомним,что запрос к v$sqlarea – это наиболее важный запрос, который Вы можете использовать для оценки производительности приложения Oracle. Всего один индекс или запрос могут застопорить всю систему. И запрос к v$sqlarea, предназначенный для того, чтобы определить число обращений к диску (disk_reads), выполняемых при работе вашего приложения (содержимое столбца sql_text таблицы v$sqlarea), покажет, где сфокусировать усилия по настройке. (Помните, что для того, чтобы увидеть полный текст конкретного запроса, может понадобиться объединить v$sqlarea с представлением v$sqltext в том случае, если этот текст превышает установленный для v$sqlarea лимит в 2000 символов).
Даже если имеется целая гора аналитических данных, следует опросить пользователей приложения, чтобы выяснить, какие запросы они считают медленными или неэффективными. Иногда подобная информация может поддержать ваши собственные заключения или, напротив, заставить вас переосмыслить их. В этой статье мы рассмотрим следующие подходы к тонкой настройке запросов:
Использование подсказок, чтобы перехитрить оптимизатор
Oracle предоставляет два мехпнизма оптимизации: стоимостная и стинаксическая оптимизация. До появления Oracle7 единственным выбором был синтаксический оптимизатор, который для разработки плана выполнения запроса использовал стандартные правила синтаксического анализа. Более поздние выпуски Oracle Database Server поддерживают этот оптимизатор для обеспечения обратной совместимости.
Стоимостной оптимизатор (cost-based optimizer – CBO) оценивает стоимость различных путей выполнения каждого конкретного запроса и затем выбирает путь с самой низкой стоимостью. Многие новые усовершенствования производительности для хранилищ данных и систем поддержки принятия решений в Oracle Database Server, например, хешированные соединения, улучшенная обработка запросов типа звезды и гистограммы, становятся доступными только при применении стоимостной оптимизации.
Для того, чтобы применять стоимостную оптимизацию, надо в файле init.ora параметру OPTIMIZER_MODE установить значение CHOOSE, а также собрать статистику по таблицам, для которых вы желаете использовать CBO, используя для этого оператор ANALYZE. CBO был разработан для того, чтобы избавить вас от необходимости “играть” с вашими запросами, но Вы можете определять подсказки (hints) для управления работой CBO в процессе оценки запроса и создания плана его выполнения. Только в том случае, если CBO не дает того результата, который вы ожидаете, вы должны посредством подсказок отменить его использование. Это следует делать только после того, как вы исчерпали все другие возможные проблемные области. Например, если оптимизатор находит, что запрос отбирает меньше чем 4 - 7 процентов от числа строк конкретной таблицы, он выберет способ управления запросом при помощи индекса, если, конечно, индекс существует. Но если таблица невелика, вы можете не захотеть использовать индекс. Тогда вы можете использовать подсказку, чтобы с ее помощью подавить использование индекса и применить альтернативный метод, например, сканирование полной таблицы.
Отметим, что если статистика не собрана и не добавлены подсказки в SQL-предложениях, для построения плана выполнения таких предложений используется синтаксический оптимизатор. А если статистика своевременно не актуализируется, стоимостной оптимизатор может для конкретного запроса сработать неэффективно.
Если вам прежде уже приходилось использовать подсказки, вы знаете, что подсказка начинается с /*+ и заканчивается */. Подсказка применяется только в предложении, в котором она находится; вложенные предложения обрабатываются, как полностью независимые, и для них требуются собственные подсказки. Кроме того, в настоящее время подсказка не может иметь размер, превышающий 255 символов (так же, как и комментарий, которым, по сути, и является подсказка).
Наиболее эффективными для использования со CBO являются следующие подсказки:
Full
Подсказка FULL управляет запросом с тем, чтобы отменить оптимизатор
и выполнить полное сканирование для указанной в подсказке таблицы:
Select /*+ FULL(table_name) */ column1, сolumn2 ...
Вы можете использовать подсказку FULL для принудительного полного сканирования таблицы в том случае, когда вы хотите задать запросить значительную часть таблицы, или когда стоимость поиска по индексу и выборки соответствующих строк может оказаться больше стоимости полного просмотра таблицы. (Подсказка FULL может требоваться вместе с некоторыми другими подсказками, например, CACHE, которая в этой статье не рассматривается).
Index
Подсказка INDEX сообщает оптимизатору, что для выполнения данного запроса
необходимо использовать один или несколько индексов:
select /*+ INDEX(table_name index_name1 index_name2 ...) */ column1, column2 ...
Обычно CBO использует наиболее ограничивающий (restrictive) индекс таблицы — индекс, который возвращает самый малый процент значений столбцов. Однако в том случае, когда для данной таблицы имеется несколько индекс, то в зависимости от накопленных статистических данных, Oracle может вообще не задействовать индекс (если это приводит к близкой к оптимальной обработке). Вместо этого может быть выполнено полное сканирование таблицы. Если имеется несколько индексов, а вы хотите обеспечить, что независимо от накопленной статистики или других факторов запрос должен использовать определенный индекс, следует использовать подсказку INDEX для задействования индекса. Или же, если надо гарантировать, что CBO не будет для выполнения запроса использовать полное сканирование таблицы, следует использовать подсказку INDEX без упоминания названия индекса. В этом случае CBO будет использовать наиболее ограничивающий индекс.
Заметьте, что если в подсказке INDEX вы используете несколько индексов, оптимизатор выберет из всего списка тот, который он считает наилучшим. При использовании подсказки AND_EQUAL (или INDEX_COMBINE - для двоичных (bitmap) индексов) будет принудительно использовано несколько индексов.
Ordered
Подсказка ORDERED заставляет оптимизатор обращаться к таблицам в специфическом
порядке, основанном на порядке в статье запроса from (о которой часто говорят
как об управляющей порядком для запроса):
select/*+ ORDERED */ column1, column2 ... from table1, table2
Если вы не используете подсказку ORDERED, оптимизатор может сделать ведущей не ту таблицу, которая указана в операторе первой. (Чтобы видеть, к какой из таблиц осуществляется обращение, вы можете использовать предложение EXPLAIN PLAN). Поскольку при использовании подсказки ORDERED имеется довольно много сложных возможностей, я посвятил ее описанию большую часть одной из глав моей книги Oracle Performance Tuning Tips & Techniques. Для получения дополнительной информации обратитесь к этой книге.
All_rows
Эта подсказка заставляет CBO выбрать самый быстрый путь для выборки
всех строк запроса, даже если при этом поиск одной строки будет идти более
медленно:
Select /*+ ALL_ROWS */ column1, column2 ...
select tabA.col_1, tabB.col2
from tabA, tabb
where tabB.col2 = ‘an1’;
Используя подсказку ORDERED и изменяя порядок таблиц в статье запроса from, вы можете выяснить, использование какой из таблиц в качестве ведущей предпочтительнее с точки зрения производительности запроса. Чтобы преодолеть выбор, сделанный оптимизатором, вы можете следующим образом использовать подсказку ORDERED:
select /*+ ordered */
TabA.col_1,tabB.col2
from tabA, tabB
where tabB.col2 = ‘an1’;
В соединени с вложенными циклами (nested-loops join) ведущей таблицей запроса является tabA (та, которая при использовании подсказки ORDERED названа первой в фразе from). В соединении сортировка-слияние (sort-merge join) порядок таблиц не является существенным, так как перед слиянием каждая таблица должна быть отсортирована.
Подсказка ALL_ROWS лучше всего подходит для работы в пакетном режиме, например, для производства полного отчета. Однако она будет плохим помошником в тяжелых Oracle Forms, где пользователям надо увидеть на экране отдельные записи. Подсказка ALL_ROWS может подавлять использование индексов, которые оптимизатор использовал бы в нормальных обстоятельствах.
First_rows
Эта подсказка сообщает CBO, что следует выбрать подход, при котором
как можно быстрее возвращаются пользователю первая строка ответа:
select /*+ FIRST_ROWS */ column1, column2 ...
Оптимизатор игнорирует подсказку FIRST_ROWS в delete- и update- предложениях, а также в select-предложениях, которые содержат что-либо из ниже перечисленного: операторы set, фразы group by и for update, групповые функции и операторы distinct.
Подсказка FIRST_ROWS полезна в интерактивных средах типа электронной торговли, где не желательно, чтобы пользователи системы какое-то время сидели перед пустыми экранами, ожидая хоть что-то в ответ. Обычно при этом в принудительном порядке используются индексы, которые оптимизатор, возможно, не стал бы использовать в нормальных обстоятельствах.
Use_nl
Эта подсказка вынуждает оптимизатор использовать вложенные циклы. Он
использует перечисленные в подсказке таблицы, как внутренние (не ведущие)
таблицы вложенного цикла. Это что означает, что если должны быть соединены
только две таблицы, в качестве ведущей будет выбрана не указанная в подсказке
таблица:
select /*+ USE_NL (tableA tableB) */ column1, column2 ...
Использование подсказки USE_NL – это обычно самый быстрый способ возвратить одну строку и, следовательно, более медленный способ для возвращения всех строк. Если вы используете в операторе псевдоним для таблицы, в подсказке должно появиться именно имя псевдонима, а не имя таблицы, иначе оптимизатор проигнорирует подсказку.
Использование соединений
После того, как оптимизатор определит наиболее эффективный способ выполнения SQL-предложения, он передает план выполнения на генератор исходных строк (row source generator), который выводит план выполнения SQL-предложения в виде ряда исходных строк — итерационных управляющих структур, которые поочередно обрабатывают набор строк (set of rows), вырабатывая массив строк (row set). Начиная с Oracle6, Oracle использует для соединения исходных строк три способа — соединение с вложенными циклами, соединение сортировкой-слиянием и кластерное соединение (cluster join). В Oracle7.3 появилось так называемое хешированное соединение (hash join), а в Oracle8i – индексное cоединение (index join), так что в последнем релизе пользователю доступно уже пять основных методов cоединениq.
Объединение с вложенными циклами
В соединении с вложенными циклами Oracle читает первую строку из первого источника строк (так называемой внешней, или ведущей таблицы), а затем проверяет второй источник строк (внутренняя таблица) на предмет совпадений. Все совпадения размещаются в выходной набор (результирующий набор), а затем происходит переход к следующей строке первого источника строк, и цикл повторяется.
Использование соединения с вложенными циклами является идеальным в тех случаях, когда ведущий источник строк (записей, которые вы ищете) невелик, а столбцы соединения внутреннего источника строк уникально проиндексированы или имеют высоко селективный (highly selective) неуникальный индекс. Соединения с вложенными циклами имеют преимущество перед другими методами соединения в том смысле, что в этом случае можно быстро отыскать первые несколько строк набора результатов и не надо ждать, пока будут получены остальные строки.
Соединение сортировкой-слиянием
При таком соединении Oracle сортирует первый источник строк по его столбцам соединения, затем сортирует второй источник строк по его столбцам соединения, а затем "сливает" отсортированные источники строк. По мере того, как находятся совпадающие пары, он помещает их в результирующий набор.
Использование соединения сортировкой-слиянием эффективно в тех случаях, когда недостаточна селективность данных или отсутствие полезных индексов делает использование соединений с вложенными циклами неэффективным, или когда оба источника строк являются весьма большими (более 5 процентов от числа записей). Однако вы можете использовать соединение сортировкой-слиянием только для соединения по равенству (WHERE D.deptno = E.deptno, но не WHERE D.deptno >= E.deptno). Кроме того, при соединении сортировкой-слиянием требуется временный сегмент для сортировки (если значение параметра SORT_AREA_SIZE слишком мало), что может привести к дополнительному расходованию памяти и/или дополнительному дисковому вводу/выводу во временном табличном пространстве.
Кластерное соединение
Кластерное соединение является одним из типов объединения с вложенными циклами. Если два соединяемые источника строк являются таблицами, которые составляют часть кластера, и если соединение является соединением по равенству между кластерными ключами этих двух таблиц, то Oracle может использовать кластерное соединение. В этом случае он читает каждую строку первого источника строк и находит все совпадения во втором источнике строк, используя индекс кластера.
Хешированное соединение (Для Oracle7.3 и далее)
При хешированном соединении Oracle читает все значения столбцов соединения из второго источника строк, формирует хеш-таблицу (в памяти, если параметр HASH_AREA_SIZE достаточно велик), а затем исследует хеш-таблицу для каждого из значений столбцов объединения первого источника строк. Если вы используете подсказку ORDERED, первая таблица в фразе from будет ведущей, но только после того, как вторая таблица будет загружена в хеш-таблицу. Если имеется достаточно памяти (параметры HASH_AREA_SIZE для хеш-таблицы и DB_BLOCK_BUFFERS для другой таблицы), то Oracle реализует соединение полностью в памяти.
Индексное соединение (Oracle8i)
До появления Oracle8i, в тех случаях, когда одиночный индекс не содержал всю необходимую информацию, серверу Oracle для выполнения запроса было необходимо обратиться к таблице. С появлением Oracle8i, если вся необходимая информация для выполнения запроса содержится в наборе индексов, оптимизатор может сгенерировать последовательность хешированных соединений между индексами.
Этот подход чрезвычайно эффективен, если таблица имеет большое количество столбцов, но Вы хотите обратиться только к ограниченному их числу. В Oracle8i оптимизатор рассмотрит этот подход как опцию при поиске оптимального пути выполнения. Вы должны создать индексы для соответствующих столбцов (тех, что удовлетворяют полному запросу), чтобы гарантировать, что индексное соединение доступно оптимизатору в качестве опции по выбору.
Опция Parallel Query Option
Опция Parallel Query Option, которая впервые появилась в Oracle7.1, дает возможность серверу базы данных параллельно выполнять полное сканирование таблицы. По сути дела, опция разбивает одиночный последовательный запрос на несколько процессов, которые могут работать одновременно. Затем различные результирующие наборы для каждого такого процесса сливаются перед возвращением пользователю. Oracle8 распространил параллельное выполнение на предложения языка манипулирования данными (DML) и параллельную работу с секциями таблиц/индексов. Параллельный режим работы дает возможность нескольким процессам (и, потенциально, нескольким процессорам) одновременно работать совместно, чтобы разрешить одиночный запрос SQL. Если ваша система завалена нерегламентированными запросами или долго выполняющимися отчетами, запущенными SQL-предложениями, которые сканируют блоки таблиц или секции данных/индексов, использование опции Parallel Query Option может решить многие проблемы. Вы используете опцию Parallel Query Option, как подсказку, например:
select/*+ FULL (cust) PARALLEL (cust, 4) */
ename, job from cust where table_name = 'emp';
Как показывает этот пример, подсказка PARALLEL использует параметр "parallel degree" (степень параллелизма, в нашем случае, – 4), который определяет число процессов, на которое следует разбить запрос. Для этой операции Oracle должен использовать пять процессов — один для расщепления запроса и четыре для выполнения обработки. Хотя режим параллельного выполнения запросов имеет дело с процессами, а не с процессорами, если системе доступно большое число процессоров, Oracle будет использовать дополнительные процессоры для параллельного выполнения запросов, что еще более увеличивает производительность. Возможность использования дополнительных процессоров зависит от установок вашей операционной системы.
Предсказание производительности
Не всегда просто предвидеть, как будет выполняться конкретный запрос при различных уровнях загрузки. Было бы великолепно, если бы администраторы базы данных имели неограниченные ресурсы для испытаний, так чтобы они могли, например, загружать “впрок” таблицы с сотнями тысяч записей и наблюдать, как все это будет работать. К сожалению, так бывает далеко не всегда. Однако, Джозеф Холмс, работающий на правительство Канады, разработал метод использования некоторых основных алгебраических уравнений, которые любой может использовать для предсказания результатов обработки запроса и тонкой настройки запросов.
Метод подразумевает выделение и тестирование SQL-предложений в идеальных условиях, построение графика зависимости времени выполнения от числа обработанных строк, получение уравнения с использованием простых методов (без регрессии), предсказание производительности, а также интерпретацию и применение модели производительности непосредственно к настройке SQL- кода. Этот подход включает следующие шаги:
Выделение SQL-кода
Сначала выделите SQL-запрос, который Вы хотите оценить, определив его
как автономный скрипт SQL*PLUS или PL/SQL.
Выполнение теста
В идеале вы должны выполнить этот скрипт на выделенной машине с определенной
вычислительной мощностью. Следует выполнить испытание несколько раз с разными
объемами данных. Соберите достаточно данных, чтобы можно было построить
график результатов испытаний, оценить его форму и получить представление,
линеен ли рост времени выполнения запроса при увеличении загрузки, или
нет.
Наблюдение графика производительности
Используя полученные результаты испытаний, постройте для каждого SQL-предложения
график зависимости времени выполнения (y) от числа обрабатываемых строк
(x) как процесс в координатных осях x,y. При идеальных условиях оптимизатор
построит четко определенную, предсказуемую линию тренда. Практически, линия
может быть более случайна, но ее основная форма может предоставить ключи
к пониманию основных причин возникновения проблем с производительностью.
Использование простых уравнений
По нанесенным на график точкам вы можете составить представление о
форме кривой, которая и будет диктовать, использовать ли вам для предсказания
производительности при намного более высоких загрузках, чем вы способны
проверить, линейное или квадратное уравнение. Вам следует использовать
простое линейное уравнение (уравнение прямой, проходящей через две заданные
точки: y = a1x + a0), если линия прямая, и квадратное уравнение (y = a0
+ a1x + a2x2) если она изогнута вверх, где a0, a1 и a2 – константы, значения
которых вы можете вычислить. Вам стоит использовать линейное уравнение
для предсказания производительности запроса, для которого получается график
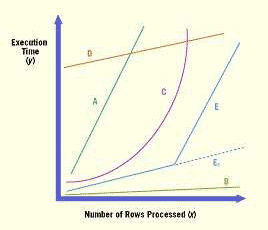
типа B, D или A на рисунке 1, а для графика типа C – квадратное уравнение.
Вот пример того, как следует использовать линейное уравнение:
Сначала найдите наклон линии (a1), выбрав две точки — (x1, y1) и (x2, y2) — и используя уравнение a1 = (y2 - y1)/(x2 - x1)
Затем найдите точку (a0), в которой прямая пересекает ось y (то есть, значение y при x = 0): a0 = y1 - a1x1
Чтобы предсказывать время выполнения (y) для данной загрузки x, подставьте полученные значения a1 и a0 в уравнение y = a1x + a0
К примеру, если для обработки 1000 строк требуется 2 секунды, а обработка 2000 строк занимает 3 секунды, то, подставив эти значения в приведенное выше уравнение, вы увидите, что выполнение запроса для 100000 строк займет одну минуту 41 секунду.
Интерпретация графика производительности
Форма графика производительности и характер уравнений могут дать вам
ключи для понимания основных причин возникновения проблем. Экспериментируйте
с SQL-кодом, улучшайте процесс, тестируйте его снова и снова, наносите
новые результаты на график и сравнивайте их с результатами для первоначального
процесса. В конечном счете, вы боретесь за график, который будет линейным
и достаточно пологим, наподобие линии B на рисунке 1. В таблице
1 приводятся возможные проблемы и пути их решения для других типов
линий.
Ведение “бухгалтерии” эксперимента
Убедитесь, что вы сохранили графики производительности “до” и “после”
изменений и замечания относительно причин возникновения проблем производительности
и их возможных решений. Экспериментируйте с индексами, временными таблицами
и подсказками оптимизатора.
Резюме настройки
Всего один неудачный запрос или индекс или плохие значения установок параметров в файле init.ora могут “поставить систему на колени”. Вы должны исследовать как выделение памяти базе данных, так и одиночные проблемные запросы. Для того, чтобы обеспечить эффективную настройку, вы должны хорошо знать свои данные, потому что каждая система уникальна. И, наконец, получше используйте v$sqlarea!
Ричард Дж. Нимик – ответственный и исполнительный вице-президент TUSC. Он работает с программным обеспечением баз данных Oracle более десяти лет и является автором нескольких книг, опубликованных издательством Oracle Press, в том числе, книги Performance Tuning Tips & Techniques (1999; ISBN: 0-07-882434-6). Выражаем благодарность Джозефу А. Холмсу (Joseph A. Holmes), Рэнди Свенсону (Randy Swanson), Брэду Брауну (Brad Brown), Джо Треззо (Joe Trezzo), Бурку Шерва (Burk Sherva), Джейку Ван дер Ворту (Jake Van der Vort), Грэгу Пука (Greg Pucka) и команде АБД удаленного доступа компании TUSC за их содействие в написании этой статьи.
Возможные варианты кривых производительности запроса
|
РИСУНОК 1: Линия B представляет идеальную линейную рабочую характеристику; D и A также линейны, но крутой подъем линии A, возможно, означает отсутствие требующегося индекса или избыточно проиндексированную таблицу с большим количеством вставок. Для объяснений см. Таблицу 1.
ТАБЛИЦА 1: Интерпретация кривых производительности запроса по результатам
тестов
| Кривая | Возможная проблема | Возможное решение |
| A | Отсутствие индекса в запросе, который ВЫБИРАЕТ (SELECTing) значения | Создать индекс или восстановить подавленный индекс. |
| A | Слишком много индексов таблицы при выполнении вставок (оператор INSERT). | Удалить некоторые из индексов, или индексировать меньшее число или меньшие по размеру столбцы для текущих индексов |
| B | Никаких проблем | И слава богу! |
| C | Отсутствие индекса в запросе, который ВЫБИРАЕТ (SELECTing) значения | Создать индекс или восстановить подавленный индекс |
| C | Слишком много индексов таблицы при выполнении вставок (оператор INSERT). | Удалить некоторые из индексов, или индексировать меньшее число или меньшие по размеру столбцы для текущих индексов |
| D | Выполнение полного сканирования таблицы или использование подсказки ALL_ROWS, когда не следует это делать | Попробуйте делать индексированный поиск, или использовать подсказку FIRST_ROWS для принудительного использования индексов |
| E | С запросом все было прекрасно, пока он не столкнулся с нарушением некоторого ограничения (типа количества операций дискового ввода/вывода или выделения памяти) | Найдите нарушенное ограничение. Увеличение SGA может решить проблему, но у нее может быть много причин. |
За дополнительной информацией обращайтесь в Interface Ltd.
Interface Ltd.Отправить E-Mail http://www.interface.ru |
|
| Ваши замечания и предложения отправляйте вебмастеру |