| СТАТЬЯ |
30.06.03
|
© Алексей Стариков, BaseGroup
Labs.
© Статья была опубликована на сайте Лаборатория
BaseGroup
В предыдущей статье была рассмотрена архитектура и взаимодействие компонентов, которые могут быть использованы для построения OLAP машины. Теперь рассмотрим подробнее внутреннее устройство компонентов.
Первым этапом работы системы будет загрузка данных и преобразование их во внутренний формат. Закономерным будет вопрос – а зачем это надо, ведь можно просто использовать данные из плоской таблицы, просматривая ее при построении среза куба. Для того чтобы ответить на этот вопрос, рассмотрим структуру таблицы с точки зрения OLAP машины.
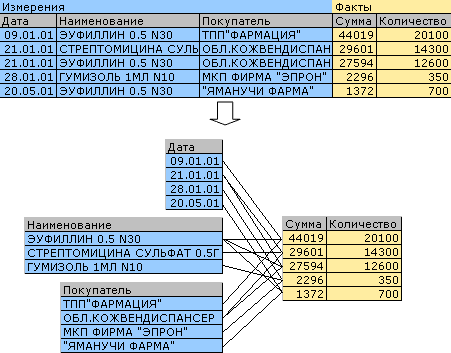
Для OLAP системы колонки таблицы могут быть либо фактами, либо измерениями. При этом логика работы с этими колонками будет разная. В гиперкубе измерения фактически являются осями, а значения измерений – координатами на этих осях. При этом куб будет заполнен сильно неравномерно – будут сочетания координат, которым не будут соответствовать никакие записи и будут сочетания, которым соответствует несколько записей в исходной таблице, причем первая ситуация встречается чаще, то есть куб будет похож на вселенную – пустое пространство, в отдельных местах которого встречаются скопления точек (фактов). Таким образом, если мы при начальной загрузке данных произведем преагрегирование данных, то есть объединим записи, которые имеют одинаковые значения измерений, рассчитав при этом предварительные агрегированные значения фактов, то в дальнейшем нам придется работать с меньшим количеством записей, что повысит скорость работы и уменьшит требования к объему оперативной памяти.
Для построения срезов гиперкуба нам необходимы следующие возможности – определение координат (фактически значения измерений) для записей таблицы, а также определение записей, имеющих конкретные координаты (значения измерений). Рассмотрим каким образом можно реализовать эти возможности.
Для хранения гиперкуба проще всего использовать базу данных своего внутреннего формата. Схематически преобразования можно представить следующим образом:
То есть вместо одной таблицы мы получили нормализованную базу данных. Вообще–то нормализация снижает скорость работы системы, – могут сказать специалисты по базам данных, и в этом они будут безусловно правы, в случае когда нам надо получить значения для элементов словарей (в нашем случае значения измерений). Но все дело в том, что нам эти значения на этапе построения среза вообще не нужны. Как уже было сказано выше, нас интересуют только координаты в нашем гиперкубе, поэтому определим координаты для значений измерений. Самым простым будет перенумеровать значения элементов. Для того, чтобы в пределах одного измерения нумерация была однозначной, предварительно отсортируем списки значений измерений (словари, выражаясь терминами БД) в алфавитном порядке. Кроме того, перенумеруем и факты, причем факты преагрегированные. Получим следующую схему:

Теперь осталось только связать элементы разных таблиц между собой. В теории реляционных баз данных это осуществляется при помощи специальных промежуточных таблиц. Нам достаточно каждой записи в таблицах измерений поставить в соответствие список, элементами которого будут номера фактов, при формировании которых использовались эти измерения (то есть определить все факты, имеющие одинаковое значение координаты, описываемой этим измерением). Для фактов соответственно каждой записи поставим в соответствие значения координат, по которым она расположена в гиперкубе. В дальнейшем везде под координатами записи в гиперкубе будут пониматься номера соответствующих записей в таблицах значений измерений. Тогда для нашего гипотетического примера получим следующий набор, определяющий внутреннее представление гиперкуба:
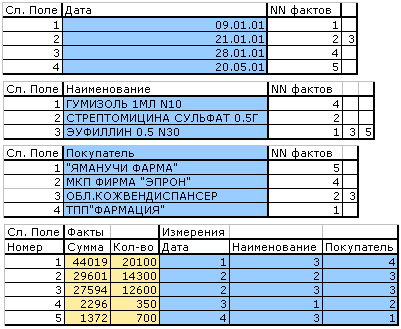
Такое будет у нас внутреннее представление гиперкуба. Так как мы делаем его не для реляционной базы данных, то в качестве полей связи значений измерений используются просто поля переменной длины (в РБД такое сделать мы бы не смогли, так как там количество колонок таблицы определено заранее).
Можно было бы попытаться использовать для реализации гиперкуба набор временных таблиц, но этот метод обеспечит слишком низкое быстродействие (пример – набор компонент Decision Cube), поэтому будем использовать свои структуры хранения данных.
Для реализации гиперкуба нам необходимо использовать структуры данных, которые обеспечат максимальное быстродействие и минимальные расходы оперативной памяти. Очевидно, что основными у нас будут структуры для хранения словарей и таблицы фактов. Рассмотрим задачи, которые должен выполнять словарь с максимальной скоростью:
Для реализации этих требований можно использовать различные типы и структуры данных. Например, можно использовать массивы структур. В реальном случае к этим массивам необходимы дополнительные механизмы индексации, которые позволят повысить скорость загрузки данных и получения информации.
Для оптимизации работы гиперкуба необходимо определить то, какие задачи необходимо решать в первоочередном порядке, и по каким критериям нам надо добиваться повышения качества работы. Главным для нас является повышение скорости работы программы, при этом желательно, чтобы требовался не очень большой объем оперативной памяти. Повышение быстродействия возможно за счет введения дополнительных механизмов доступа к данным, например, введение индексирования. К сожалению, это повышает накладные расходы оперативной памяти. Поэтому определим, какие операции нам необходимо выполнять с наибольшей скоростью. Для этого рассмотрим отдельные компоненты, реализующие гиперкуб. Эти компоненты имеют два основных типа – измерение и таблица фактов. Для измерения типовой задачей будет:
При добавлении нового значения элемента нам необходимо проверить, есть ли у нас уже такое значение, и если есть, то не добавлять новое, а использовать имеющуюся координату, в противном случае необходимо добавить новый элемент и определить его координату. Для этого необходим способ быстрого поиска наличия нужного элемента (кроме того, такая задача возникает и при определении координаты по значению элемента). Для этого оптимальным будет использование хеширование. При этом оптимальной структурой будет использование хеш-деревьев, в которых будем хранить ссылки на элементы. При этом элементами будут строки словаря измерения. Тогда структуру значения измерения можно представить следующим образом:
PFactLink = ^TFactLink;
TFactLink = record
FactNo: integer; // индекс факта в таблице
Next: PFactLink; // ссылка на следующий элемент
End;
TDimensionRecord = record
Value: string; // значение измерения
Index: integer; // значение координаты
FactLink: PFactLink; // указатель на начало списка элементов таблицы фактов
End;
И в хеш-дереве будем хранить ссылки на уникальные элементы. Кроме того, нам необходимо решить задачу обратного преобразования – по координате определить значение измерения. Для обеспечения максимальной производительности надо использовать прямую адресацию. Поэтому можно использовать еще один массив, индекс в котором является координатой измерения, а значение – ссылка на соответствующую запись в словаре. Однако можно поступить проще (и сэкономить при этом на памяти), если соответствующим образом упорядочить массив элементов так, чтобы индекс элемента и был его координатой.
Организация же массива, реализующего список фактов, не представляет особых проблем ввиду его простой структуры. Единственное замечание будет такое, что желательно рассчитывать все способы агрегации, которые могут понадобиться, и которые можно рассчитывать инкрементно (например, сумма).
Дополнительная информация
За дополнительной информацией обращайтесь в компанию Interface Ltd.
| INTERFACE Ltd. |
| ||||