
Теория
Для начала надо сказать, что из себя представляют эти самые генетические алгоритмы. Подробно описывать их не буду, т.к. вы можете найти много хороших статей по ним и интернете. А если в двух словах, то генетический алгоритм - это такой алгоритм с помощью которого можно искать минимум (или максимум) целевой функции, зависящей от многих переменных. Такой алгоритм применяют, когда целевая функция сложная и не понятно как еще можно найти ее экстремум. Для примера, целевой функцией может быть ошибка между полученными данными и расчетными с параметрами, которые надо установить. Например, в исходниках, которые вы можете скачать по ссылке в конце статьи, алгоритм вычисляет коэффициенты перед переменными.
Идея генетических алгоритмов взята из теории Дарвина о эволюции. Мы создаем виды (решения), которые скрещиваются между собой, мутируют, самый неудачные умирают. Суть алгоритма в том, что изначально мы имеем набор произвольных видов. Каждый вид содержит в себе набор хромосом (переменных, значение которых надо найти), которые и надо рассчитать. Сначала мы имеем в популяции виды, у которых все хромосомы случайны. После этого происходит скрещивание видов и, возможно, мутирование. После этого отбираются самые лучшие виды (у которых минимальна целевая функция), а самые плохие (с максимальными целевыми функциями и с хромосомами, которые не попадают в заданный интервал) удаляются из популяции. На следующей итерации скрещивание, мутирование и отбор повторяется. Благодаря этому у нас постепенно остаются только те, у которых целевая функция близка к минимуму. И так повторяется до тех пор пока не будет найдено решение, удовлетворяющее нас с точки зрения погрешности. Также часто алгоритм останавливают, если в течение заданного числа поколений (итераций) не удается найти еще лучший вид, чем тот, что у нас есть.
Реализация
Реализация алгоритма была сделана на языке C# для .NET Framework 2.0.
Базовый класс для видов
Все виды должны быть производными от базового класса BaseSpecies<TSpecies>, где TSpecies - конкретный тип для вида. TSpecies должен быть производным от класса BaseSpecies<TSpecies>.
/// <summary>
/// Базовый класс для вида
/// </summary>
abstract public class BaseSpecies<TSpecies>: IComparable
where TSpecies: BaseSpecies<TSpecies>
{
#region Статические функции для скрещивания хромосом базовых типов
/// <summary>
/// Скрестить две хромосомы типа double
/// </summary>
/// <param name="x">1-я хромосома</param>
/// <param name="y">2-я хромосома</param>
/// <returns>Новая хромосома</returns>
static protected double Cross (double x, double y)
{
...
}
static protected Int32 Cross (Int32 x, Int32 y)
{
...
}
static protected Int64 Cross (Int64 x, Int64 y)
{
...
}
#endregion
#region Методы для мутаций в базовых типах
/// <summary>
/// Мутация для типа double
/// </summary>
/// <param name="val">Мутируемое значение</param>
/// <returns>Промутирующее значение</returns>
static protected double Mutation (double val)
{
...
}
static protected Int32 Mutation (Int32 val)
{
...
}
static protected Int64 Mutation (Int64 val)
{
...
}
#endregion
/// <summary>
/// Мертв ли вид.
/// </summary>
/// <remarks>Например, когда хромосовы не попадают в заданные интервал</remarks>
protected Boolean m_Dead = false;
/// <summary>
/// Мертвый ли вид?
/// </summary>
public bool Dead
{
get { return m_Dead; }
}
/// <summary>
/// Проверяет, чтобы все хромосомы попали бы в заданные интервалы.
/// В противном случае помечает вид как "мертвый".
/// </summary>
abstract public void TestChromosomes();
/// <summary>
/// Метод для скрещивания себя с другим видом
/// </summary>
/// <param name="Species">Другой вид</param>
/// <returns>Полученный вид</returns>
abstract public TSpecies Cross (TSpecies Species);
/// <summary>
/// Произвести мутацию
/// </summary>
abstract public void Mutation();
/// <summary>
/// Целевая функция. Должна в случае удачного набора хромосом стремиться к своему минимуму
/// </summary>
/// <returns>Значение целевой функции</returns>
abstract public double FinalFunc
{
get;
}
#region IComparable Members
/// <summary>
/// Вид считается больше, если он мертв или у него больше целевая функция
/// </summary>
/// <param name="obj"></param>
/// <returns></returns>
public Int32 CompareTo(object obj)
{
...
}
#endregion
}
|
Как видно из кода, BaseSpecies - это абстрактный класс, который содержит статические protected-методы для скрещивания и мутации. Разберем некоторые методы поподробнее. Начнем с методов, которые необходимо реализовать в производных классах.
abstract public void TestChromosomes(); |
Этот методы должен устанавливать внутреннюю защищенную Булеву переменную m_Dead, которая показывает, подходят ли хромосомы по ограничениям, которые на них накладывают (например, в нашем примере, попадают ли значения хромосом в отрезок [-5.0; 5.0]). Если значения хромосом нас устраивают, то m_Dead надо установить в false, иначе в true. По этой переменной (получаемую через свойство Dead) популяция отбрасывает заведомо неудачные виды.
Следующий метод, который необходимо реализовать в производном классе, это
abstract public TSpecies Cross (TSpecies Species); |
Этот метод создает новый вид, скрещивая себя и другой вид, который передается как аргумент. Здесь надо сделать некоторые пояснения. Обычно, если вид содержит несколько хромосом, скрещивают хромосомы "одного вида", т.е. в нашем случае скрещиваем a0 себя (т.е. this) и a0 другого вида, анологично скрещиваем a1 и a1, т.е. нет смысла скрещивать a0 себя и a1 другого класса. Возможно, у вас будет задача, где это понадобится, но я так сходу ее придумать не смогу.
Смысл скрещивания состоит в том, что берем одну часть хромосомы себя и вторую часть другого вида и создаем из них новую хромосому, которая и будет содержаться в новом виде. Часто хромосомы скрещивают побайтово. Суть его состоит в том, что сначала случайно выбираем точку разрыва (скрещивания) хромосомы, потом создаем новую хромосому, которая состоит из левой части первой хромосомы и правой второй. Пусть например у нас есть две хромосомы (8-битовые для простоты): 10110111 и 01110010. Случайно выбираем точку разрыва (отмечена символом '/'):
101 / 10111
011 / 10010
Отсюда мы может сделать две разные хромосомы это 101 10010 и 011 10111. Какую из них выбрать - это также можно решить генератором случайных чисел. Также можно искать две и более точек пересечения. Таким образом, мы должны иметь конструктор, который создает вид из хромосом.
Для того, чтобы не надо было изобретать велосипед, в классе BaseSpecies есть публичные статические методы для скрещивания хромосом некоторых типов (Double, Int64 и Int32). Разберем поподробнее первые два метода. В данном случае по сути есть две точки перечечения - в середине слова и знак числа, т.е. сначала скрещиваются хромосомы побитово без учета знака, а потом также случайно берем знак от одной из хромосомы.
Рассмотрим код.
/// <summary>
/// Скрестить две хромосомы типа double
/// </summary>
/// <param name="x">1-я хромосома</param>
/// <param name="y">2-я хромосома</param>
/// <returns>Новая хромосома</returns>
static protected double Cross (double x, double y)
{
Int64 ix = BitConverter.DoubleToInt64Bits(x);
Int64 iy = BitConverter.DoubleToInt64Bits(y);
double res = BitConverter.Int64BitsToDouble(BitCross(ix, iy));
if (m_Rnd.Next() % 2 == 0)
{
if (x * res < 0)
{
res = -res;
}
}
else
{
if (y * res < 0)
{
res = -res;
}
}
return res;
} |
Работает этот метод следующим образом: сначала преобразуем хромосомы из типа Double в Int64. Это сделано для того, чтобы можно было бы без проблем скрещивать побитово. (Спасибо henson-у с форума RSDN за то, что подсказал, что есть метод DoubleToInt64Bits. Собственно все эта ветка форума находится здесь.) После скрещивания уже типов Int64 без учета знака (об этом чуть позже), переводим число обратно к Double, а потом берем знак одной из двух хромосом. Также я видел реализацию генетического алгоритма, где для скрещивания дробных хромосом просто брали их среднее арифметическое, однако в тех, примерах, которые я пробовал, такой метод работает лучше.
А теперь давайте посмотрим как происходит скрещивание типов Int64:
/// <summary>
/// Скрестить побитово без учета знака две хромосомы типа Int64
/// </summary>
/// <param name="x">1-я хромосома</param>
/// <param name="y">2-я хромосома</param>
/// <returns>Новая хромосома</returns>
static protected Int64 BitCross (Int64 x, Int64 y)
{
// Число бит, оставшиеся слева от точки пересечения хромосом
int Count = m_Rnd.Next(62) + 1;
Int64 mask = ~0;
mask = mask << (64 - Count);
return (x & mask) / (y & ~mask);
}
/// <summary>
/// Скрестить побитово с учетом знака две хромосомы типа Int64
/// </summary>
/// <param name="x">1-я хромосома</param>
/// <param name="y">2-я хромосома</param>
/// <returns>Новая хромосома</returns>
static protected Int64 Cross (Int64 x, Int64 y)
{
Int64 res = BitCross(x, y);
if (m_Rnd.Next() % 2 == 0)
{
if (x * res < 0)
{
res = -res;
}
}
else
{
if (y * res < 0)
{
res = -res;
}
}
return res;
} |
Как видно из кода, сначала скрещиваются хромосомы без учета знака, а потом (как и с типом Double) выбирается знак одной из хромосом. Точнее, это работает так, что сравнивают знак выбранной хромосомы с результатом, и, если знаки не совпали (произведение меньше нуля), то знак результата меняется на противоположный. Скрещивание без учета знаков - это просто игра с битами.
Если вас по каким-то причинам не устраивают эти методы для скрещивания, то вы можете сделать свои и использовать их, а мы переходим к следующему абстрактному методу, который надо реализовать.
public void Mutation(); Здесь все очень похоже на скрещивание. Мутация действует на одну хромосому. В теории при мутации могут происходить любые изменения. Но в данной реализации мутация меняет один бит в слове. Вот пример кода:
/// <summary>
/// Мутация для типа double
/// </summary>
/// <param name="val">Мутируемое значение</param>
/// <returns>Промутирующее значение</returns>
static protected double Mutation (double val)
{
UInt64 x = BitConverter.ToUInt64(BitConverter.GetBytes(val), 0);
UInt64 mask = 1;
mask <<= m_Rnd.Next(63);
x ^= mask;
double res = BitConverter.ToDouble(BitConverter.GetBytes(x), 0);
return res;
}
/// <summary>
/// Мутация для типа Int64
/// </summary>
/// <param name="val">Мутируемое значение</param>
/// <returns>Промутирующее значение</returns>
static protected Int64 Mutation (Int64 val)
{
Int64 mask = 1;
mask <<= m_Rnd.Next(63);
return val ^ mask;
} |
Мутации происходят сравнительно редко. Например, часто вероятность мутации делают 5-10%, но иногда стоит попробовать сделать ее побольше (примерно 30%). Также довольно часто в качестве мутации для дробных чисел лучше применять не написанную выше функцию, а просто генератор случайных чисел, который выдает случайное число в нужном нам интервале. В прилагаемом примере для дробных чисел так и сделано, а для целых хромосом используется мутация, описанная здесь.
Реализация популяции (класс Population)
А теперь рассмотрим класс популяции, где живут, размножаются и умирают виды. Вы будете добавлять свои виды в этот класс (точнее в массив видов, находящийся в этом классе).Класс Population объявлен как
public class Population<TSpecies> where TSpecies:BaseSpecies<TSpecies> |
Как видно, он имеет generic-параметр, который представляет собой вид, который должен быть производным от BaseSpecies<TSpecies>
Начнем со свойств, которые надо настроить перед началом работы алгоритма.
MaxSize (Int32) - максимальное число видов, которое может содержать популяция. Это тот размер, до которого "урезается" популяция после скрещивания. По умолчанию 500.
CrossPossibility (Double) - вероятность скрещивания. Она должна быть в интервале (0.0; 1.0]. Если это условие не выполняется, то бросается исключение ArgumentOutOfRangeException. По умолчанию это значение установлено в 0.95.
MutationPossibility (Double) - вероятность мутации. Она должна быть в интервале [0.0; 1.0). Если это условие не выполняется, то бросается исключение ArgumentOutOfRangeException.
Впринципе, можно было бы ввести еще вероятность отбора, но в данном случае она считается равной 1.0. В противном случае надо было бы удалять виды из популяции не все подряд самые плохие, а с некоторой вероятностью. Но мертвые виды (напомню, что это виды, у которых хромосомы не попадают в заданный интервал или не удовлетворяет другим условиям) надо удалять в любом случае.
А теперь рассмотрим публичные методы, которые необходимо вызывать.
public void Add (TSpecies species) - добавить новый вид в популяцию. Заметьте, что вы должны вручную добавлять необходимое число видов. Перед началом работы алгоритма надо, чтобы в популяции было хотя бы два вида. Число видов в популяции может быть меньше, чем установленное значение MaxSize. Если после скрещивания размер популяции меньше MaxSize, то просто не удаляются самые плохие виды (даже мертвые).
Чтобы получить следующую популяцию, необходимо вызвать метод void NextGeneration(). Работа этого метода может занимать достаточно много времени, поэтому лучше всего его вызывать из отдельного потока. Давайте посмотрим что он делает.
/// <summary>
/// Обновить популяцию (получить слудующее поколение)
/// </summary>
public void NextGeneration()
{
if (m_Generation == 0 && m_Species.Count == 0)
{
throw new ZeroSizePopulationException();
}
// Сначала скрестим
Cross();
// Промутируем и заодно проверим все хромосомы
foreach (BaseSpecies<TSpecies> species in m_Species)
{
// Если надо мутировать с учетом вероятности.
if (m_Rnd.NextDouble() <= m_MutationPossibility)
{
species.Mutation();
}
species.TestChromosomes();
}
// Отберем самые живучие виды
m_Species.Sort();
Selection();
m_Generation++;
} |
Сначала метод проверяет, чтобы при первом вызове метода (при нулевом поколении, о поколениях чуть позже) размер популяции был бы больше 2 (иначе некого скрещивать). Если это не так, то бросается исключение SmallSizePopulationException. После этого происходит скрещивание видов:
/// <summary>
/// Получить новые виды скрещиванием
/// </summary>
protected void Cross()
{
// Размер до начала пополнения популяции (чтобы не скрещивать новые виды,
// которые добавляются в конец списка)
Int32 OldSize = m_Species.Count;
// Номер пары для скрещиваемого вида
Int32 Count = m_Species.Count;
for (int i = 0; i < Count; ++i)
{
// Если надо скрещивать с учетом вероятности.
if (m_Rnd.NextDouble() <= m_CrossPossibility)
{
// Добавляем в список вид, полученный скрещиванием очередного вида и
// вида со случайным номером.
m_Species.Add (m_Species[i].Cross (m_Species[m_Rnd.Next (OldSize)] ) );
}
}
} |
При скрещивании перебираем все виды и скрещиваем их с установленной вероятностью скрещивания с другими видами, которые выбираются случайно.
После скрещивания происходит мутация видов также с заданной вероятностью, а после скрещивания идет тест хромосом. Затем сортируем виды по значению их целевой функции. Метод Sort определен в классе BaseSpecies, здесь я его приводить не буду, но скажу, что вид считается больше тот, который мертвый, а, если все виды живые, то с максимальной целевой функцией. Отбор видов также происходит просто:
/// <summary>
/// Произвести отбор самых "живучих" видов
/// </summary>
protected void Selection()
{
// Сколько видов надо удалить
Int32 Count = m_Species.Count - m_MaxSize;
for (Int32 i = 0; i < Count; ++i)
{
m_Species.RemoveAt (m_Species.Count - 1);
}
} |
Пример использования
Рассмотрим задачу, которая решается в примерах, которые прилагаются в исходниках.
Есть функция f = a5 * X05 + a4 * X14 + a3 * X23 + a2 * X32 + a1 * X4 + a0. Здесь X0...X4 - переменные функции, а a0...a5 - это коэффициенты, которые в принципе не меняются, но нам не известны и которые мы хотим найти. В проекте находятся два примера. Первый, когда значения коэффициентов a0...a5 являются дробными, а второй, когда они являются целыми значениями. Т.к. по сути эти примеры мало отличаются, то далее более подробно я буду рассматривать именно виды с дробными значениями хромосом.
Изначально a0 = 2.2, a1 = 1.32, a2 = -4.06, a3 = -3.1, a4 = 4.7, a5 = 0.2. Для расчетов мы знаем значения функции в некоторых точках (30 точек). Для увеличения точности и скорости ограничим интервал, в котором находятся коэффициенты, отрезком [-5.0; 5.0].
Реализация видов
Я не буду приводить здесь полностью код, т.к. он довольно большой, а только его части. Вкратце опишу его работу, т.к. базовый класс оставляет довольно большую свободу выбора способа представления хромосом и данных.
Для начала объявлен класс для представления точек функции:
public class DoubleFuncPoint
{
public const int FuncSize = 5;
/// <summary>
/// X1, X2, ..., X5
/// </summary>
private double[] m_X = new double[FuncSize];
public double[] X
{
get
{
return m_X;
}
}
/// <summary>
/// Значение функции
/// </summary>
private double m_Y;
public double Y
{
get
{
return m_Y;
}
}
public DoubleFuncPoint(double[] x, double y)
{
m_X = (double[])x.Clone();
m_Y = y;
}
} |
Здесь я думаю все понятно. Затем создадим класс вида:
public class DoubleSpecies: BaseSpecies<DoubleSpecies>
{...} |
В самом классе вида DoubleSpecies (причем как статический член, чтобы у всех видов были одинаковые данные и не надо было бы их лишний раз передавать) хранится List<DoubleFuncPoint>, в который заносятся экземпляры класса DoubleFuncPoint. Значение целевой функции (что она из себя представляет расскажу чуть позже) вычисляется только в двух случаях для каждого вида, когда он создается и когда мутирует, а потом сохраняется в приватном поле и извлекается оттуда, когда это необходимо.
А целевая функция представляет из себя сумму квадратов разности значения функции, у которой известен ее вид и значением такой же функции, где вместо коэффициентов подставлены хромосомы вида:
private void GetFunc()
{
m_FuncVal = 0.0;
foreach (DoubleFuncPoint point in m_FuncPoints)
{
double f = Func(point.X) - point.Y;
m_FuncVal += f * f;
}
} |
Также еще без комментариев приведу методы для скрещивания и теста хромосом:
public override DoubleSpecies Cross (DoubleSpecies Species)
{
if (this == Species)
{
return new DoubleSpecies ((double[])m_Chromosomes.Clone());
}
DoubleSpecies Other = (DoubleSpecies)Species;
//В данном конкретном случае лучше работает скрещивание сразу всех хромосом
double[] chromosomes = new double[m_Chromosomes.Length];
for (int i = 0; i < chromosomes.Length; ++i)
{
chromosomes[i] = Cross(m_Chromosomes[i], Other.Cromosomes[i]);
}
return new DoubleSpecies(chromosomes);
}
public override void TestChromosomes()
{
Boolean res = false;
foreach (double chromosome in m_Chromosomes)
{
if (Double.IsNaN(chromosome) // chromosome < m_MinVal // chromosome > m_MaxVal)
{
res = true;
break;
}
}
m_Dead = res;
} |
При скрещивании в нашем случае есть два варианта: скрещивать сразу все хромосомы или скрещивать по одной хромосоме за один раз. В данном примере лучше (быстрее находится минимум), если скрещивать сразу все хромосомы, а в другом случае, например, как в примере с целыми хромосомами лучше работает скрещивание по одной хромосоме. Здесь уже надо экспериментировать.
Работа примера
После компиляции примера, его запуска и выбора типа хромосом (дробные или целые) откроется окно, в котором можно установить параметры для генетического алгоритма и смотреть как изменяются значения хромосом лучшего вида, а также ошибка. Для простоты реализации весь расчет происходит в одном потоке. Пример работы генетического алгоритма с конкретными параметрами виден на рисунке. Напомню правильные значения: a0 = 2.2, a1 = 1.32, a2 = -4.06, a3 = -3.1, a4 = 4.7, a5 = 0.2.
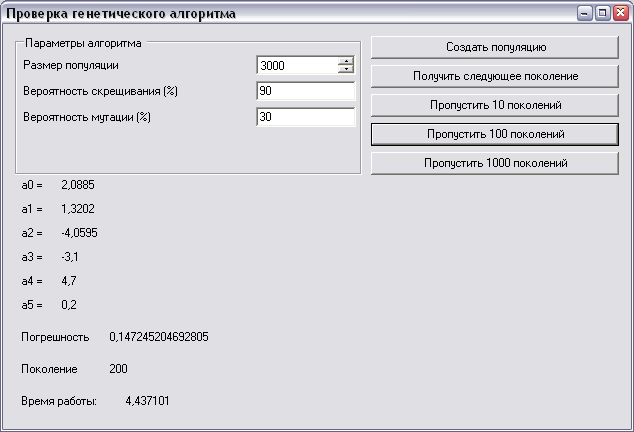
Общий план использования библиотеки
Чтобы подвести итог, рассмотрим общий план того, что необходимо сделать, чтобы использовать эту библиотеку:
- Создать класс вида, производный от BaseSpecies<TSpecies>, где в качетсве аргумента обобщения в BaseSpecies передается имя самого класса вида;
- Внутри класса вида создать набор хромосом необходимых типов;
- Перегрузить абстрактный метод public TSpecies Cross (TSpecies Species), который должен создать новый вид. В качетсве параметра метода выступает особь того же вида, с которым необходимо провести скрещивание;
- Перегрузить свойство (только get) public double FinalFunc(), которое возвращает значение целевой функции. Если целевая функция сложная, то удобно хранить значение целевой функции в отдельной переменной, значение которой и возвращает это свойство, а сам расчет целевой функции осуществлять в конструкторе вида;
- Перегрузить метод public void Mutation()
- Перегрузить метод public override void TestChromosomes(), который устанавливает значение переменной m_Dead в true, если данный вид нас заведомо не устраивает, например, е значения его хромосом не попадает в заданные пределы, и в false в противном случае;
- Создать популяцию Population<TSpecies>, которая будет хранить особей нужного вида;
- Вызвать метод Reset() популяции для удаления всех видов, если они уже были в популяции;
- Через свойство MaxSize популяции установить максимальный размер популяции;
- Установить вероятность мутации через свойство MutationPossibility. Значение этого свойство должно лежать в пределах от 0 до 1. Значение по умолчанию 0.1;
- Установить вероятность скрещивание через свойство CrossPossibility. Значение этого свойство должно лежать в пределах от 0 до 1, причем нулевая вероятность скрещивания не допускается. Значение по умолчанию 0.95;
- Добавить в популяцию необходимое число особей соответствующего вида через метод void Add (TSpecies)
- Вызывать метод void NextGeneration() популяции пока в этом будет необходимость, например, пока не будет достигнута нужная погрешность;
- Через свойство TSpecies BestSpecies можно получить лучшую на данной итерации (в данном поколении) особь вида, у которой целевая функция меньше, чем у остальных.
Вот, пожалуй, и все. Более подробно примеры использования смотрите в исходниках.
История версий
2.0.0
- Переписал библиотеку под .NET 2.0 с использованием обобщений (generics);
- В примере использования добавил возможность менять параметры алгоритма во время работы.
1.0.0
- Реализация под .NET 1.1.