
Одним из ключевых элементов, отвечающих за успешную работу любой BI-системы, является заложенная в него модель данных. Она может сделать систему быстрой, гибкой и функциональной, а может, наоборот, превратить ее в неповоротливый кусок программного кода, неспособный решить поставленные задачи. Большинство проектов внедрения BI-систем проваливаются из-за неоптимальной модели. Но предотвратить этот риск можно уже на начальном этапе внедрения.
В прошлой статье "Аналитический CRM: с чего начинать?" говорилось о том, что модель ACRM должна хранить информацию о клиентах и построенных сегментах, а сама информация должна быть агрегирована на уровне клиента - ключевого элемента хранилища. Т.е. модель должна быть клиенто-ориентированной. Но что же на самом деле представляет из себя клиенто-ориентированная модель ACRM, и какие условия могут обеспечить ее оптимальность? Постараемся ответить на эти вопросы в этой статье.
Уровни представления данных
Поскольку ACRM является прикладным примером BI-систем, то в ней есть все 3 уровня представления данных: физический уровень, уровень бизнес-логики и презентационный уровень.
Уровень бизнес-логики строится непосредственно в репозитории BI-системы и преобразует данные из структур физического уровня в структуры, предназначенные для решения конкретных бизнес-задач. Здесь происходит вычисление узкоспециализированных KPI’s (Key Performance Indicator), строятся иерархии, и для каждой бизнес-области связываются в схемы (mappings) используемые в ней таблицы фактов (facts) и измерений (dimensions).
Правильно построенная модель репозитория или модель бизнес-логики обеспечивает конечных пользователей полноценным для решения поставленных бизнес-задач набором показателей и измерений, а также позволяет быстро и безболезненно кастомизировать репозиторий, добавлять новые бизнес-области и описывать дополнительные бизнес-объекты.
Презентационный уровень содержит показатели, переведенные в понятия конкретной бизнес-области. На этом уровне подготовленные и рассчитанные на уровне бизнес-логики объекты проецируются в соответствующие отчеты и dashboards (панели отчетов, сгруппированных по бизнес-задачам) конечных пользователей.
Схема уровней представления данных
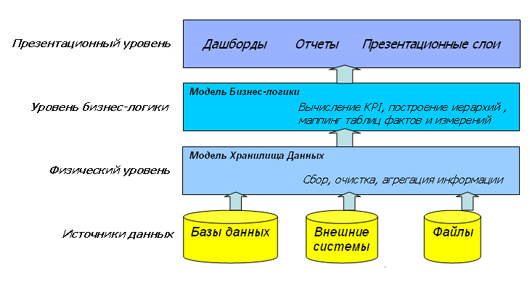
Следует отметить, что репозиторий системы содержит не только модель бизнес-логики, но и описание интерфейсов физического и презентационного уровней, т.е. является сердцем BI-системы, объединяя все три уровня представления данных.
Итак, в ACRM необходимо уделить внимание оптимальности, как минимум, двух моделей: модели хранилища данных (МХД) и модели бизнес-логики (МБЛ). Рассмотрим их более подробно.
Модель хранилища данных
Как уже было отмечено, МХД влияет на скорость выборки информации. Для того чтобы определить критерии оптимальности модели хранилища достаточно ответить на вопрос: "Какая информация в ACRM наиболее часто интересует бизнес-пользователей?".
В ACRM это может быть информация двух видов: текущее состояние клиента и история изменения состояния клиента, т.е. динамика его показателей за время взаимодействия с компанией.
Информация, указанная в первом случае, используется для быстрого сегментирования клиентской базы по актуальным критериям (например, по статусу клиента на текущий момент, по суммарному доходу за месяц, по текущей задолженности и т.д.). Второй случай позволяет выявлять типичные профили поведения клиентов (например, получить типичный профиль должника, профиль абонента, склонного к уходу и т.д.) Исходя из этого, можно определить рекомендации к модели хранилища ACRM.
Исходя из этого, можно определить рекомендации к модели хранилища ACRM:
1. Модель хранилища должна содержать таблицы с показателями клиентов и ссылками на измерения, рассчитанными на текущий момент времени (Текущие Профили).
2. Модель хранилища должна содержать таблицы, хранящие историю изменения этих показателей и ссылок на измерения (Исторические Профили).
3. На уровне хранилища данных рекомендуется производить расчет только тех показателей, алгоритм вычисления которых не изменится в дальнейшем, либо процесс их вычисления слишком ресурсоемок, чтобы выполнять его на уровне бизнес-логики.
Это позволит, с одной стороны, минимизировать объем возможных доработок хранилища данных в случае изменения бизнес-требований к расчету показателей, а с другой стороны, сократить риски возникновения интеграционных ошибок с другими уровнями представления данных при масштабировании и кастомизации системы.


Многие разработчики предлагают оптимизировать хранилище ACRM путем использования стандартного секционирования по времени. Этот подход может иметь положительный успех в BI-системах, предназначенных для управленческой отчетности, но вряд ли подойдет для ACRM. Поскольку критериев сегментации очень много, то лучше создать несколько таблиц-профилей, разделив клиентскую базу на непересекающиеся диапазоны клиентов, например, по региону или по методу взаиморасчетов. Каждую такую таблицу-профиль можно дополнительно секционировать по новым критериям. Для текущих профилей лучше использовать секционирование по быстро изменяющемуся критерию: категория надежности клиента, уровень лояльности и т.д. А для исторических профилей, напротив, по постоянному критерию: пол, регион, дата заключения договора и т.д. Такой способ оптимизации позволяет не только ускорить процесс доступа к данным, а также предоставляет гибкую возможность настройки разных способов секционирования для отдельных групп клиентов и разграничения доступа к ним на уровне БД. Созданные на уровне хранилища таблицы-профили теперь необходимо объединить в модели бизнес-логики.
Модель бизнес-логики
Она создается в репозитории и является, пожалуй, самым сложным и самым "живым" объектом всей системы. Бизнес не стоит на месте: цели, задачи и способы их достижения меняются каждый день. А значит, и сама МБЛ должна быстро адаптироваться под требования бизнеса, повышая в конечном итоге его успешность. Другими словами, модель должна позволять оперативно создавать и изменять показатели, измерения и уровни иерархии.
Чтобы определить рекомендации к МБЛ, необходимо ответить на вопрос: "На что больше тратит времени аналитик в процессе поиска сегмента?". Почти всегда слышен один и тот же ответ на этот вопрос: "На все!", но на практике получается несколько иначе.
Аналитик может достаточно быстро выбрать список необходимых показателей и затем очень долго подбирать набор условий (элементов измерений), которыми он хочет ограничить выборку и в разрезе которых рассчитать эти показатели. Причем сначала он использует одно условие, затем, увидев результат, накладывает дополнительное условие и т.д. Количество итераций может доходить до нескольких десятков, существенно затягивая процесс анализа.
Таким образом, оптимальность модели во многом зависит от того, насколько быстро аналитик сможет определить набор условий в виде списка элементов измерений, которыми он хочет ограничить целевую аудиторию. Поскольку модель бизнес-логики ориентирована в первую очередь на решение конкретных бизнес-задач, то и рекомендации к ней будут выглядеть так.
Для каждой бизнес-задачи рекомендуется создать отдельную схему (mapping) таблиц фактов и измерений, действительно необходимых для ее решения. Вместо использования больших измерений рекомендуется создать набор мини-измерений, содержащих подмножество действительно необходимых элементов, которые будут использоваться для решения конкретной бизнес-задачи. Все необходимые для бизнес-задачи показатели, должны быть представлены в рамках созданной схемы.
На уровне МБЛ рекомендуется проводить расчет показателей, алгоритм вычисления может измениться. Такой подход позволяет избежать проблем с показателями, которые в разных случаях должны рассчитываться по-разному, а также повысить скорость и удобство работы конечного пользователя, предоставляя ему действительно необходимый для решения набор элементов.

Еще одну важную роль в оптимизации МБЛ играют уровни иерархии измерений, поскольку именно они позволяют конечному пользователю выходить в отчетах на более детальный уровень (drill down) или, наоборот, "подниматься" к более общему (drill up). От того, сколько уровней иерархии содержит измерение и насколько грамотно они были созданы, будет в конечном итоге зависеть удобство и скорость работы с этим измерением. Поэтому еще одна важная рекомендация для создания оптимальной модели бизнес-логики: строить уровни иерархии надо исходя из группировки данных по бизнес-смыслу.
Эти рекомендации помогут понять, от чего следует отталкиваться для того, чтобы с самого начала заложить оптимальную модель данных, а значит, предотвратить еще один немаловажный риск проекта внедрения ACRM.