
|
ABBYY FineReader Engine 8.1 стал первым в мире продуктом, реализующим в рамках одного SDK распознавание печатных текстов (OCR) на 191 языке на базе латиницы, кириллицы, армянского, греческого, еврейского и тайского алфавитов, а также японских, корейских и китайских иероглифов, а также анализ и распознавание текстов написанных печатными буквами от руки (ICR) для 92 языков. В новую версию также добавлена поддержка формата PDF/A, который рекомендован в качестве стандартного (ISO 19005-1:2005) для задач длительного хранения документов. |
| |
 ABBYY FineReader Engine - наиболее мощный и универсальный инструментарий для разработчика, заинтересованного в эффективной реализации функций распознавания и обработки документов в своём приложении. Он обладает всеми основными функциями таких продуктов компании ABBYY, как ABBYY FineReader, ABBYY FormReader и ABBYY FlexiCapture Studio и является многофункциональным инструментом разработки, который позволяет создавать приложения любой архитектуры, начиная от рабочих станций и заканчивая серверными решениями.
ABBYY FineReader Engine - наиболее мощный и универсальный инструментарий для разработчика, заинтересованного в эффективной реализации функций распознавания и обработки документов в своём приложении. Он обладает всеми основными функциями таких продуктов компании ABBYY, как ABBYY FineReader, ABBYY FormReader и ABBYY FlexiCapture Studio и является многофункциональным инструментом разработки, который позволяет создавать приложения любой архитектуры, начиная от рабочих станций и заканчивая серверными решениями.Возможности
Операции с изображением, предварительная обработка изображения
В ABBYY FineReader Engine изображения могут быть получены тремя способами: со сканера через TWAIN -интерфейс (поддержаны как сканеры с автоматической подачей, так и с ручной подачей документов), непосредственно из памяти или из файлов. Программа поддерживает основные графические форматы, включая многостраничные TIFF и JPEG 2000 (part 1), и работает с чёрно-белыми, серыми и цветными изображениями. Программа также может открывать PDF-файлы и преобразовывать их в изображения с помощью Adobe PDF Library.
В ABBYY FineReader Engine есть возможность управлять следующими параметрами сканирования: яркость, цветность, разрешение, область сканирования, двустороннее сканирование, установка паузы между страницами, и др.
ABBYY FineReader Engine 8.1 позволяет сохранять как исходные, так и обработанные изображения в различных форматах.
ABBYY FineReader Engine способен выполнять следующие операции предварительной обработки изображений:
- Устранение перекосов.
Применяется для изображений, полученных со сканера. Для обработки не требуется наличие границ или других линий. При потоковом вводе форм величина перекоса может быть рассчитана с помощью информации о положении реперных блоков. - Разделение двойных страниц.
Применяется при распознавании отсканированных книг: изображение книжного разворота разделяется на два изображения, каждое из которых соответствует одной странице. Затем каждая страница распознаётся и выполняется её анализ, при этом также может быть устранён перекос изображения. Такая обработка значительно повышает качество распознавания. - Удаление "мусора" (очистка изображения).
При сканировании с низким или средним качеством на изображении может появиться большое количество излишних точек. Такие точки, расположенные вблизи границ символов, приводят к ухудшению качества распознавания. Данная функция предназначена для удаления подобного случайного "мусора". - Фильтрация текстуры и адаптивная бинаризация.
Технология фильтрации текстуры позволяет удалять с изображения фоновую текстуру и цветной фон. С помощью передовой технологии адаптивной бинаризации удаётся безошибочно распознавать тексты, расположенные на фоне изображений с переменной контрастностью. При распознавании подобных оригиналов параметры бинаризации подбираются индивидуально для каждого фрагмента изображения. Таким образом удаётся повысить точность распознавания трудночитаемых документов, таких как газеты, цветные документы, факсы и ксерокопии. - Масштабирование изображения.
Если документ был отсканирован с низким разрешением (менее 120 dpi), и в нём есть мелкий текст (менее 10 pt), для повышения качества распознавания можно выполнить цифровое увеличение изображения. - Автоматическое определение угла поворота страницы (90, 180, 270 градусов).
При сканировании возможно различное расположение страниц пакета на планшете сканера. Соответственно, их изображения могут быть повёрнуты на различный угол. FineReader автоматически определяет угол поворота страницы, и при необходимости исправляет ошибки, допущенные при подаче документов в сканер. - Адаптивная обработка изображений документов, снятых цифровым фотоаппаратом. Эта новая технология позволяет отличать отсканированные изображения документов от изображений, полученных при помощи цифрового фотоаппарата, и устранять искажения, типичные для цифровой фотосъёмки. Таким образом, удалось на 40% повысить точность распознавания сфотографированных документов.
- Очистка изображения в пределах текстового блока. При очистке предусмотрена возможность указывать размер чёрных и белых фракций "мусора".
- Изменение цветов текста и фона в прямоугольных областях.
Эта функция будет особенно полезна разработчикам систем управления данными. Типовой сценарий её применения в электронном архиве выглядит следующим образом. Распознанный документ сохранён в виде изображения и в виде текста. Притом в архивном индексе хранятся геометрические координаты каждого символа на изображении страницы. Используя функцию изменения цветов, можно реализовать подсветку ключевых слов в результатах поиска по архиву. При этом пользователь будет видеть фрагмент изображения, на котором искомые слова выделены цветом.
В ABBYY FineReader Engine также имеются такие функции предварительной обработки изображения, как кадрирование ("обрезка"), "создание preview", "поворот (90, 180, 270 градусов)", "зеркальное отображение" и "инвертирование".
Анализ документа необходим для автоматического преобразования документа с сохранением форматирования, распознавания отдельных зон документа с разметкой блоков вручную, а так же для обработки форм. Анализ документа позволяет:
- автоматически определить ориентацию страницы - 90, 180, 270 градусов (см. раздел "Операции с изображением, предварительная обработка изображения" выше);
- автоматически обнаружить текстовые блоки, таблицы, штрих-коды и картинки;
- автоматически обнаружить в ячейках таблиц текст с вертикальным направлением;
- размечать блоки (а также добавлять, удалять и редактировать их) вручную;
- автоматически накладывать шаблон при обработке форм
Также можно воспользоваться следующими возможностями ABBYY FineReader Engine, каждая из которых представляет собой индивидуальный тип анализа, предназначенный для решения конкретных задач пользователя:
Анализ документа для счетов.
Этот специализированный вид анализа предназначен для предварительной обработки документов, расположение элементов которых неодинаково для разных документов одного типа. К ним относятся, например, инвойсы, платёжные поручения, квитанции, денежные переводы, визитные карточки, договоры, заявление о выплате страхового возмещения, резюме и т.д. Данная функция позволяет обнаруживать максимальное количество текста, включая символы и цифры - даже если надписи выполнены мелким шрифтом и находятся на картинках, логотипах, и т.п.
В отличие от стандартного анализа, данный специализированный вид анализа предполагает, что вся печатная информация, содержащаяся на документе, является текстом. В частности, структура таблиц не анализируется, текст в ячейках выделяется в самостоятельные текстовые блоки. При таком подходе важная текстовая информация не будет интерпретирована как графические элементы, а числа в таблицах гарантировано не будут разделены на группы, состоящие из целой и дробной частей. В результате удастся получить максимальное количество информации о тексте, включая его координаты. Впоследствии эта информация может быть использована для анализа документа, обработки полей и разбора текста в других системах.
Анализ документа для полнотекстового индексирования.
В режиме анализ документа для полнотекстового индексирования на странице автоматически находится и распознаётся вся текстовая информация, в том числе и та, что находится внутри изображений, графиков, диаграмм и т.п. Это даёт разработчикам возможность строить полнотекстовые индексы для распознаваемых документов, что полезно для организации эффективного и удобного поиска по электронным архивам и другим массивам неструктурированной или слабо структурированной текстовой информации.
OCR
- Поддерживает до 191 языка распознавания печатного текста.
- 182 языка* с латинским, кириллическим, греческим и армянским алфавитами.
- 47 языков* со словарной (морфологической) поддержкой.
- Распознавание тайского языка и иврита
- Распознавание многоязычных документов.
- Распознавание документов, отпечатанных на матричном принтере.
- ABBYY FineReader Engine протестирован на тысячах образцов, напечатанных на различных принтерах, включая матричные, лепестковые, цепные и ленточные принтеры. Система уверенно распознаёт такие тексты, отпечатанные как в черновом режиме, так и с высоким качеством (режим Near Letter Quality, NLQ).
- Распознавание документов, напечатанных на пишущей машинке.
- Распознавание китайских, японских и корейских иероглифов
Режим быстрого распознавания.
- Предназначен для приложений, рассчитанных на обработку больших объёмов документов в условиях, когда скорость обработки является наиболее важным параметром системы. Данный режим увеличивает скорость обработки на 200-250%, что делает его пригодным для систем управления документооборотом и систем архивирования.
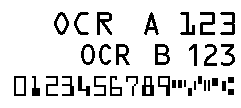 Распознавание текстов, напечатанных шрифтами OCR - A, OCR - B, MICR (E13B) и MICR (CMC7).
Распознавание текстов, напечатанных шрифтами OCR - A, OCR - B, MICR (E13B) и MICR (CMC7).
- Модуль FineReader XIX
- По всему миру имеется большое количество документов, книг, газет, опубликованных в 17-19 столетиях. Большинство из них раритетные, некоторые уникальны. Они хранятся в архивах библиотек, государственных учреждений и являются национальным наследием, которое необходимо сохранить. Лучшее решение - перевести их в цифровой формат. Набор функций, входящий в FineReader Engine 7.1 и называемый " FineReader XIX", предоставляет УНИКАЛЬНУЮ возможность распознавания текстов, напечатанных в период с 1600 по 1937 на английском, французском, итальянском и испанском языках. FineReader XIX поддерживает такие специальные шрифты, как Fraktur, Schwabacher и большинство готических шрифтов.
 ICR
ICR
- Поддерживает до 92 языков распознавания текста, написанного печатными буквами от руки.
- 22 языка* с латинским алфавитом, греческий язык и 3 языка* с кириллическим алфавитом (модули распознавания кириллических языков поставляются по отдельному заказу) с морфологической/словарной поддержкой
- 70 языков* с латинским алфавитом без словарной поддержки
- Распознавание текстов, вписанных от руки печатными буквами в поля различных типов - подчёркнутые поля, рамки, поля с гребёнкой и др.
- Режим быстрого распознавания.
- В этом режиме текстовые поля (блоки) распознаются в 2-2,5 раза быстрее, чем в нормальном режиме.
- Многоязычное распознавание.
- Одним из основных преимуществ технологии ABBYY ICR является то, что цифры, цифры в комбинации в буквами одного языка и даже цифры в комбинации с буквами нескольких языков распознаются с почти одинаковым высоким качеством, даже если в поле одновременно присутствуют строчные и прописные буквы.
- Поддержка 22 стилей начертания рукопечатных знаков, в том числе европейского, американского, канадского, русского, японского, арабского и тайского стилей.
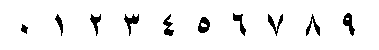 Поддержка индийских цифр, которые используются в современном арабском мире.
Поддержка индийских цифр, которые используются в современном арабском мире.
OMR, штрих-код
- Распознавание одномерного штрих-кода
- ABBYY FineReader Engine поддерживает распознавание наиболее популярных типов одномерного штрих-кода: Code 39, Checked Code 39, Interleaved 25, Checked Interleaved 25, EAN 8, EAN 13, EAN 13 Supplemental, Code 128, CODABAR (без контрольной суммы), UCC Code 128, Code 2 of 5 (Industrial, IATA, Matrix), Code 93, UPC - A, UPC - E и штрих-коды Postnet.
- Распознавание двумерного штрих-кода (PDF 417)
- Модуль 2 D Barcode позволяет распознавать штрих-код PDF 417, который является промышленным стандартом двумерного штрих-кода. PDF 417 позволяет кодировать до 1.1 Кб данных, включая текст и графическую информацию.
- Функция быстрого извлечения штрих-кода
- Эта функция позволяет автоматически обнаружить и распознать штрих-коды, расположенные на документе под любым углом по отношению к горизонтали. Функция работает как с одномерными, так и с двумерными штрих-кодами.
 OMR (оптическое распознавание меток)
OMR (оптическое распознавание меток)
- Поддержано распознавание одиночных меток и групп меток. Ошибочно выбранные и затем полностью закрашенные метки также обрабатываются корректно. Точность распознавания достигает 99.995%.
Ниже приведены два примера того, как использование данных языков может привести к повышению качества распознавания.
В документах, заполненных от руки, значения полей обычно принадлежат к определённой группе: названия городов, стран, почтовые индексы, коды изделия, суммы и т.д. Для повышения точности распознавания можно задействовать пользовательские языки. Они позволяют описать данные, которые могут быть указаны в данном поле.
Если документ содержит большое количество "неестественных", то есть отсутствующих в естественном языке элементов (коды изделия, телефонные номера, номера паспорта и др.), при распознавании возможны ошибки. Они возникают из-за того, что программа считывает такие структуры символ за символом. Для повышения качества распознавания кодов изделия и тому подобных элементов можно создать новый язык распознавания (например, включающий регулярное выражение), который позволит корректно считать эти данные.
В ABBYY FineReader Engine имеется API, предназначенный для создания и редактирования языков распознавания, создания копий системных языков распознавания и изменения их в соответствии с нуждами пользователя, а также добавления новых слов в пользовательские языки.
В подавляющем большинстве случаев ABBYY FineReader успешно распознаёт тексты без предварительного обучения. Однако, при распознавании шрифтов с декоративными элементами и контурами, а также при распознавании документов плохого качества в больших объёмах предварительное обучение эталона будет полезным. ABBYY FineReader Engine позволяет создавать, а также импортировать пользовательские эталоны, созданные с помощью ABBYY FineReader Professional/Corporate Edition.
Теперь на базе ABBYY FineReader Engine 8.1 можно более полно решать задачи преобразования PDF-файлов в файлы других форматов, а также задачи преобразования отсканированных или отснятых цифровой камерой изображений в PDF-файлы с текстовым слоем, который может быть использован при построении индекса для последующего поиска файла в хранилище.
Импорт
- Распознавание стало точнее и почти вдвое быстрее. При обработке PDF-файлов новая версия ABBYY FineReader Engine определяет наличие текстового слоя и его целостность. Эта информация сопоставляется с данными из служебных полей PDF-файла (аннотации, метаданные, текстовые объекты, подключенные шрифты, контент-потоки). В итоге относительно каждого текстового блока принимается решение: использовать ли текст, извлечённый из соответствующего слоя или распознавать блок. Решение для каждого блока принимается независимо. Подобный подход обеспечивает значительно более быстрое и качественное преобразование PDF-файлов.
- Распознавание внутренних и внешних ссылок. Система распознаёт и воспроизводит гиперссылки, как внутренние (например, оглавление PDF-документа), так и внешние, на интернет-ресурсы.
Экспорт
- Поддержка алгоритмов шифрования и других средств разграничения доступа. ABBYY FineReader Engine 8.1 позволяет сохранять результаты распознавания в виде PDF -файла, защищённого паролем. Пароль может быть установлен как на открытие файла, так и на прочие действия с документом (печать, извлечение содержимого, возможность редактирования, внесение комментариев, добавление/удаление страниц и др.). При этом можно выбрать разные уровни шифрования с длиной ключа 40 или 128 бит и с использованием:
- стандартного алгоритма шифрования RC 4,
- нового алгоритма стандарта AES (Advanced Encrypting Standard).
- Генерация тегов. Восьмая версия системы способна создавать PDF-документы с тегами, обеспечивающими удобство просмотра на экранах любого размера, в частности, на экранах карманных компьютеров.
- Управление размером страниц создаваемого PDF-файла.
- Экспорт в формат PDF/A (дополнительно подключаемый модуль).
- PDF/A - это перспективный архивный формат, рекомендованный в качестве стандартного (ISO 19005-1:2005) для длительного хранения документов. В отличие от обычного, широко распространенного PDF, этот формат имеет ряд жёстких ограничений. Их наличие позволяет повторно использовать документ после длительного хранения в архиве, исключает любую несовместимость версий файла и программы для его использования.
- Настройка баланса скорости и качества при преобразовании PDF-файлов.
- ABBYY FineReader Engine 8.1 позволяет достигать оптимального соотношения скорость/качество при конвертации PDF-файлов в зависимости от поставленной задачи. Предусмотрено 4 режима преобразования PDF-файлов. В зависимости от того, какой режим выберет разработчик, будут применены различные правила обработки PDF-файла. В соответствии с тем, какой режим был выбран перед преобразованием PDF-файла, FineReader Engine 8.1 может извлечь все данные, включая текст, таблицы и картинки, может обработать PDF-файлы как изображения или скомбинировать различные методы.
- Экспорт в формат PDF документов на китайском, японском и корейском языках с вертикальным расположением текста.
- Экспорт метаданных. Расширена возможность сохранения в создаваемых PDF-файлах различных метаданных: закладок, гиперссылок, кросс-ссылок и т.п.

Через ABBYY FineReader Engine 8.1 API пользователь получает доступ к функциональности программы ABBYY FormReader. Данная программа предназначена для обработки форм, т.е. большого количества сходных документов, таких как анкеты, бюллетени, гарантийных писем и т.п. Она также позволяет распознавать документы, содержащие сходные данные, но имеющие различное расположение элементов, такие как инвойсы, заявления о страховом возмещении, резюме, контракты и др., с помощью передовой технологии ABBYY FlexiCapture Studio. ABBYY FormReader входит в состав ABBYY FineReader Engine. Для использования ABBYY FlexiCapture Studio необходима дополнительная лицензия.
Для того чтобы использовать ABBYY FineReader Engine для обработки форм необходимо выполнить следующие действия. Сначала с помощью ABBYY FormReader или ABBYY FlexiCapture Studio создают шаблон, на нем отмечают блоки данных и реперные блоки. Реперные блоки необходимы для наложения шаблона и поиска полей, содержащих данные. Шаблон содержит информацию о расположении элементов формы, пространственном соотношении между реперами и полями, типах данных, содержащихся в каждом поле, включая пользовательские типы данных, а также абсолютные и относительные координаты полей и реперов. Готовый шаблон экспортируется через API в ABBYY FineReader Engine, где выполняется наложение шаблона на форму, распознавание данных, экспорт данных, и любые другие виды обработки.
FineReader Engine API совместно с ABBYY FormReader и ABBYY FlexiCapture Studio предоставляют разработчикам доступ к следующим функциям обработки форм:
- Встроенный редактор шаблонов.
ABBYY FormReader содержит редактор шаблонов, позволяющий создавать шаблоны для различных типов форм. Данный редактор удобен для создания шаблона на базе уже отпечатанной (и, возможно, даже уже заполненной) формы. - FormDesigner.
Если вам нужно создать форму, вы можете использовать для этого ABBYY FormDesigner. Данная программа является приложением к ABBYY FormReader и бесшовно интегрируется с редактором шаблонов ABBYY FormReader. После того, как форма нарисована в ABBYY FormDesigner, шаблон для неё создаётся автоматически. - В качестве реперных элементов могут быть использованы следующие элементы форм: чёрные квадраты, текст, линии, иллюстрации.
- Поля с многострочным текстом.
При создании шаблона формы несколько строк текста можно объединить в одно текстовое поле. При этом весь текст из данного поля будет экспортирован в одно поле базы данных. - Пользовательские типы данных.
Для поля данных можно задать пользовательский тип данных: с помощью регулярного выражения, набора символов, словаря из текстового файла или использовать любую комбинацию перечисленных способов. - Специализированные типы данных.
В ABBYY FormReader имеются специализированные типы данных для 21 языка которые используются при распознавании полей данных "имя", "фамилия", "город", "е- mail ", "адрес", "телефон", "страна" и т.п. Данные словари позволяют OCR / ICR Engine использовать всю доступную информацию для достижения наивысшего качества распознавания. - Автоматическая идентификация шаблона.
При вводе форм возможна обработка пакетов, содержащих формы различных типов и, соответственно, использование нескольких шаблонов. В таком случае программа будет автоматически выбирать нужный шаблон. - Компенсация линейных искажений с помощью реперных элементов (для документов, отправленных по факсу).
В ABBYY FineReader Engine имеются новые алгоритмы компенсации линейных искажений. Они заметно повышают качество распознавания форм, полученных по факсу, и других подобных документов.
Возможность обработки полуструктурированных форм и документов
- Создание гибких шаблонов (FlexiLayout) при помощи программы ABBYY FlexiCapture Studio
- Разработчики могут создавать гибкие шаблоны при помощи ABBYY FlexiCapture Studio. Гибкий шаблон - так называемый FlexiLayout - представляет собой набор формальных правил для извлечения данных из документов с нечёткой структурой. В гибком шаблоне можно задавать как простые элементы (например, статический текст, разделитель, пробел, штрих-код, строка символов, фрагмент текста, коллекция объектов, дата), так и составные элементы (несколько простых элементов, объединённых при помощи логического И).
- Созданию гибкого шаблона может предшествовать предварительное распознавание всего документа с целью выделить на нем такие объекты, как текст, разделители, штрих-коды, инвертированный текст, поля для меток, картинки. Есть возможность запускать предраспознавание в ускоренном режиме.
- Для каждого элемента гибкого шаблона задаются свойства, которые описывают расположение искомого объекта на документе и его геометрические отношения с другими объектами. Задание свойств элементов визуализировано в программной оболочке: пользователь может задать необходимые настройки, выбирая опции и вводя нужные значения в диалоговых окнах программы. В то же время имеется возможность создать гибкий шаблон, используя специальный язык, аналогичный языкам сценариев. Например, пользователь может указать программе, что объект А необходимо искать слева (или справа) от объекта Б, или что объект А - самый близкий к объекту Б, поэтому он может использоваться в качестве отправной точки для поиска Б, или что если найден объект Б, то не следует искать объект А, и т.д.
- При наложении гибкого шаблона на изображение документа программа формулирует ряд гипотез для всех элементов, которые описывает шаблон. Гипотезы ранжируются по качеству: программа оценивает, насколько хорошо обнаруженные объекты на документе соответствуют элементам шаблона, и штрафует неточные соответствия. Гипотезы выстраиваются в древовидную структуру, в которой наглядно видны отношения между элементами гибкого шаблона и их вероятными соответствиями на изображении документа. Программа выбирает самую "лучшую" цепочку гипотез в дереве гипотез, т.е. цепочку, которая позволит надёжно обнаружить все объекты, описанные в шаблоне. Такое наглядное представление дает пользователю возможность увидеть, как программа делает свой выбор, и "на лету" внести изменения в гибкий шаблон с целью повысить качество обнаружения объектов на документе.
- Понятие "нулевой гипотезы" позволяет определять некоторые объекты документа как факультативные: если программа не найдет такой необязательный объект, она не забракует шаблон, а выдвинет "нулевую гипотезу", т.е. решит, что объект просто отсутствует на документе.
- Если объект не является факультативным, он может использоваться в качестве идентификатора для определения типа документа. Такое решение позволяет программному ядру ABBYY FineReader Engine обрабатывать разнотипные документы, выбирая наилучший шаблон из набора шаблонов в пакете.
- Проверка гибких шаблонов в программе ABBYY FlexiCapture Studio.
- Пользователь имеет возможность протестировать гибкие шаблоны на тестовом пакете документов и проверить качество наложения шаблона на изображения.
- Функция пошаговой доработки гибких шаблонов позволяет пользователю постепенно добавлять новые образцы документов в пакет и проверять созданный им гибкий шаблон на все большем количестве разнообразных документов данного типа.
Остальные функции, такие как обработка изображений, распознавание и экспорт - такие же как в ABBYY FineReader Engine.
Низкоуровневая настройка технологического ядра
- Доступ к расширенному набору результатов распознавания.
- Для разработчиков систем, реализующих принцип "голосования", может оказаться полезным интерфейс Voting API. Он предоставляет доступ к расширенному набору гипотез, сформированных при распознавании.
- Динамическая настройка в процессе распознавания.
- Предусмотрен механизм воздействия на список гипотез непосредственно в процессе распознавания. Он позволяет выборочно увеличивать весовые коэффициенты гипотез и, таким образом, влиять на результат и продолжительность последующего процесса распознавания.
- Набор профилей настроек
- В состав программного обеспечения включены наборы предопределенных параметров ABBYY FineReader Engine (профили), которые рекомендованы для наиболее популярных типовых применений: преобразование в PDF-файл с возможностью поиска, распознавание на уровне полей, архивирование с обработкой изображений и индексацией, полнотекстовое преобразование в RTF и HTML и др. Эти профили помогают путём вызова одной функции установить такие настройки всех важных процессов обработки (от предварительной обработки изображения до экспорта распознанного текста), которые позволяют добиться оптимального соотношения скорости и качества обработки.
Получение и экспорт распознанного текста
FineReader Engine API предоставляет доступ к широкому набору функций обработки и экспорта текста на различных уровнях:
- Различные уровни сохранения форматирования текста при экспорте во внешние приложения (от простого текста без форматирования до сохранения полного форматирования страницы, включая колонки, таблицы, рамки, шрифты, размер шрифтов, стили абзацев, границы и т.п.).
- Доступ к полной информации о каждом распознанном символе (дополнительно подключаемый модуль).
- Функции редактирования и форматирования распознанного текста перед экспортом.
- Экспорт распознанного текста в различные форматы
- Полное сохранение структуры документа.
- Замена неуверенно распознанных символов соответствующими им фрагментами изображения при сохранении в формат PDF.
- Полное сохранение цвета иллюстраций и текста.
Преимущества
Преимущества, получаемые при интеграции ABBYY FineReader Engine 8.1 в информационные системы:
- Распознавание документов лучше хранения изображений.
FineReader Engine предоставляет возможности распознавания и преобразования документов. Любой бумажный документ может быть преобразован в электронный вид и сохранён в одном из наиболее распространённых форматов: PDF, RTF/DOC, HTML, XLS, XML и др. Преобразование в электронный вид позволяет организовать поиск по текстам сохранённых документов, редактировать и многократно использовать их. При хранении отсканированных документов в графическом виде большая часть этих функций будет недоступна. Кроме того, рынок приложений для преобразования документов растёт быстрее рынка приложений для создания изображений документов. - 3 технологии в 1 Engine: FineReader, FormReader и FlexiCapture.
Один инструментарий разработчика соединяет в себе 3 технологии, позволяющие создавать приложения для распознавания и преобразования документов (FineReader), а также для потокового ввода данных - со структурированных (FormReader) и с гибких форм (FlexiCapture). Данный продукт также позволяет реализовать распознавание печатных (OCR) и рукопечатных (ICR) текстов, меток (OMR) и штрих-кодов, обработку изображений (как до, так и после распознавания) и преобразование PDF-файлов. Благодаря модульной архитектуре, разработчики могут объединить в своём приложении именно те технологии, которые требуются для решения конкретных задач. - Расширение возможностей сервисных бюро на рынке аутсорсинга бизнес-процессов (АБП).
ABBYY предлагает мощную и гибкую платформу, объединяющую в себе возможности конвертирования документов, потокового ввода данных и автоматической обработки форм, которая позволит сервисным бюро занять прочные позиции на рынке АБП. Будь то автоматическая обработка структурированных или гибких форм или конвертирование документов (в том числе PDF), - сервисные бюро получают весь необходимый инструментарий для выполнения любого проекта точно в срок. - Превосходная точность распознавания и сохранение форматирования.
Благодаря разработанной ABBYY прогрессивной технологии IPA и методу многоуровневого анализа документов (MDA), FineReader Engine обеспечивает беспрецедентную точность распознавания и полное сохранение форматирования. Распознанный документ представляет собой точную копию бумажного оригинала. FineReader Engine сохраняет структуру и форматирование исходного документа, включая разбиение на строки, колонки, таблицы, иллюстрации непрямоугольной формы, вертикальный текст и расстояние между символами. Технологии адаптивной бинаризации и интеллектуальной фильтрации текстур, реализованные компанией ABBYY, обеспечивают точное распознавание трудночитаемых документов, в том числе документов с низкой контрастностью, с цветным текстом на цветном фоне, а также документов, отсканированных с плохим качеством. Продукты, разработанные на основе технологии FineReader, получили более 100 наград по результатам сравнительных тестов, проводимых ведущими ИТ-изданиями. Одним из важнейших преимуществ данной технологии является то, что она отвечает запросам конечных пользователей и позволяет получать электронные документы, являющиеся точной копией бумажного оригинала. - Многоязычное распознавание.
ABBYY FineReader Engine позволяет выполнять многоязычное распознавание печатного и рукопечатного текста. Система распознаёт печатный текст на 191 языках (включая языки с латинским, греческим, армянским и кириллическим алфавитами, иврит, а также китайский, японский, корейский и тайский языки) и текст, написанный от руки печатными буквами, на 92 языках. Дополнительным преимуществом является то, что FineReader Engine обеспечивает почти одинаково высокую точность:- при распознавании как одноязычного, так и многоязычного печатного текста;
- при распознавании цифр, написанных от руки, в том числе в сочетании с буквами одного или нескольких языков. Высокая точность сохраняется даже при наличии в полях как прописных, так и строчных букв.
- Обработка форм.
FlexiCapture и FormReader предоставляют разработчикам выход на новые рынки. Существует значительный спрос на приложения для обработки гибких и структурированных форм во всех сферах жизни, включая бизнес, управление, образование, торговлю, медицину, производство, страхование, банковское дело и многие другие. - Простота использования FlexiCapture Studio.
С программой может работать даже человек, не являющийся программистом. Работая с удобным визуальным инструментарием FlexiCapture Studio, не составляет труда создать, отредактировать и отладить описание шаблона формы. - Пригодность для проектов любого масштаба.
FineReader Engine успешно зарекомендовал себя во многих проектах - от небольших, где было задействовано всего несколько рабочих мест, до широкомасштабных, реализующих распределённую обработку документов на множестве серверов и рабочих станций. - Отсутствие пользовательского интерфейса - готовность к интеграции.
Низкоуровневый доступ к функциям ввода данных и преобразования документов позволяет создать любое приложение под своей торговой маркой. - Высокая репутация ABBYY помогает продажам решений на основе технологий ABBYY.
Компания ABBYY известна своими передовыми OCR -технологиями и имеет отличную репутацию на рынке обработки документов. Технологии OCR, разработанные компанией ABBYY, используются такими лидерами как Kofax, Toshiba, Lexmark, Cardiff и NSI. Продукты ABBYY выбрали более 600 компаний-разработчиков, системных интеграторов, VAR, и IT-отделов крупных компаний. Многолетний успех компании ABBYY способствует продажам решений, в которые интегрированы OCR -технологии ABBYY. - Квалифицированное сервисное обслуживание.
ABBYY проводит гибкую лицензионную политику и предлагает своим клиентам техническую поддержку, программы подписки, а также консультации квалифицированных специалистов, что делает работу с компанией и её продуктами выгодной и удобной. - Экономия времени на разработку.
ABBYY FineReader Engine 8.1 содержит много примеров программного кода, которые могут быть использованы для разработки новых продуктов. Это позволит сэкономить время и упростит использование программы. В системе предусмотрен также командно-строчный интерфейс (CLEI), благодаря которому для выполнения целой задачи требуется всего одна команда; это упрощает процесс интеграции.
Новое в версии
Новая версия ABBYY FineReader Engine 8.1 располагает всеми функциями и возможностями FineReader Engine 8.0. Кроме того, версия 8.1 позволяет сохранять документы в формате PDF/A, что упрощает процесс архивирования и снижает стоимость содержания крупных архивов. Сделан значительный шаг в развитии языковой базы: теперь можно распознавать документы на тайском языке и на иврите. Добавлена функция сохранения в форматах PDF и RTF документов на китайском, японском и корейском языках с вертикальным расположением текста.
Улучшение преобразования PDF-файлов
- Экспорт в формат PDF/A
PDF/A - это перспективный архивный формат, рекомендованный в качестве стандартного (ISO 19005-1:2005) для длительного хранения документов. В отличие от обычного, широко распространенного PDF, этот формат имеет ряд жёстких ограничений. Их наличие позволяет повторно использовать документ после длительного хранения в архиве, исключает любую несовместимость версий файла и программы для его использования. Многие компании по всему миру уже сейчас выразили намерение полностью перейти на PDF/A, приняв его как стандартный формат хранения документов в архивах и системах документооборота. Наиболее многочисленной группой пользователей PDF/A являются национальные архивы, федеральные службы и агентства, министерства и другие государственные организации.
- Настройка баланса скорости и качества при преобразовании PDF-файлов
ABBYY FineReader Engine 8.1 позволяет достигать оптимального соотношения скорость/качество при конвертации PDF-файлов в зависимости от поставленной задачи. Предусмотрено 4 режима преобразования PDF-файлов. В зависимости от того, какой режим выберет разработчик, будут применены различные правила обработки PDF-файла. Например, можно определить, следует ли распознавать текст или можно просто его импортировать из входящего PDF-файла, необходимо ли сравнивать результат распознавания с текстом в оригинальном PDF-файле или нет.
В соответствии с тем, какой режим был выбран перед преобразованием PDF-файла, FineReader Engine 8.1 может извлечь все данные, включая текст, таблицы и картинки, может обработать PDF-файлы как изображения или скомбинировать различные методы.
Расширение словарной поддержки
- Для распознавания теперь доступны тайский и иврит
ABBYY FineReader Engine теперь позволяет распознавать печатные документы и конвертировать PDF-файлы, составленные на 191 языке, в том числе на тайском и на иврите.
 Тайский язык, используемый более чем 70 миллионами человек по всему миру, является одним из труднейших языков для лингвистического анализа и распознавания. Он содержит около 80 символов, включая согласные, гласные, диакритику и цифры. В тайском языке присутствует 5 тоновых модуляций, в зависимости от которых звучание и смысл слова могут меняться.
Тайский язык, используемый более чем 70 миллионами человек по всему миру, является одним из труднейших языков для лингвистического анализа и распознавания. Он содержит около 80 символов, включая согласные, гласные, диакритику и цифры. В тайском языке присутствует 5 тоновых модуляций, в зависимости от которых звучание и смысл слова могут меняться. Они обозначаются с помощью специальных диакритических символов и гласных букв, располагаемых на 4 уровнях сверху и снизу от строки базовых символов или справа/слева от согласных букв. Стоит также отметить, что в тайском языке слова в предложении не разделяются пробелами, а пишутся слитно. ABBYY FineReader Engine 8.1 успешно решает задачу анализа тайского текста и разделения его на отдельные строки.
Они обозначаются с помощью специальных диакритических символов и гласных букв, располагаемых на 4 уровнях сверху и снизу от строки базовых символов или справа/слева от согласных букв. Стоит также отметить, что в тайском языке слова в предложении не разделяются пробелами, а пишутся слитно. ABBYY FineReader Engine 8.1 успешно решает задачу анализа тайского текста и разделения его на отдельные строки.
 Особенностью написания иврита, который используется примерно 3 миллионами человек по всему миру, является направление текста: справа налево. Интересен факт, что цифры (в большей части текстов на иврите сегодня используются арабские цифры 1,2,3,4,5,6,7,8,9,0) пишутся в противоположном направлении - слева направо. Более того, современные тексты часто содержат слова на английском и других языках; эти слова также пишутся в привычном нам направлении. ABBYY FineReader Engine 8.1 анализирует смешанные тексты и правильно распознаёт как английский, так и иврит.
Особенностью написания иврита, который используется примерно 3 миллионами человек по всему миру, является направление текста: справа налево. Интересен факт, что цифры (в большей части текстов на иврите сегодня используются арабские цифры 1,2,3,4,5,6,7,8,9,0) пишутся в противоположном направлении - слева направо. Более того, современные тексты часто содержат слова на английском и других языках; эти слова также пишутся в привычном нам направлении. ABBYY FineReader Engine 8.1 анализирует смешанные тексты и правильно распознаёт как английский, так и иврит. - Полнотекстовый экспорт в PDF и RTF для языков группы CJK
ABBYY FineReader Engine 8.1 позволяет конвертировать документы с вертикальным расположением текста на китайском (традиционном и упрощённом), японском и корейском языках в форматы PDF и RTF. При этом обеспечивается полное восстановление исходного оформления документа.
Расширение возможностей распознавания
- Сбалансированный режим для распознавания печатного текста
В дополнение к тщательному (Accurate) и быстрому (Fast) режимам распознавания печатного текста, FineReader Engine теперь снабжён третьим режимом (Balanced), который обеспечивает оптимальное соотношение между скоростью и качеством распознавания. Таким образом, у разработчиков появляется возможность быстро выбирать соотношение скорость/качество, в зависимости от поставленной задачи и параметров используемого аппаратного обеспечения.
- Новый штрих-код - EAN 13 Supplemental
 EAN 13 Supplemental - это вариант широко используемого штрих-кода EAN 13, который имеет специальную дополнительную часть в своём составе и широко используется в книжной индустрии для кодирования ISBN-номеров на книгах и журналах. ABBYY FineReader Engine 8.1 распознаёт этот тип штрих-кода.
EAN 13 Supplemental - это вариант широко используемого штрих-кода EAN 13, который имеет специальную дополнительную часть в своём составе и широко используется в книжной индустрии для кодирования ISBN-номеров на книгах и журналах. ABBYY FineReader Engine 8.1 распознаёт этот тип штрих-кода. - Новый тип текста - CMC7
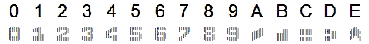 ABBYY FineReader Engine 8.1 распознаёт новый тип текста, используемый обычно на чеках и платёжных поручениях на денежные переводы - MICR CMC7. Этот тип, в частности, является во Франции стандартом для документов платёжной клиринговой системы.
ABBYY FineReader Engine 8.1 распознаёт новый тип текста, используемый обычно на чеках и платёжных поручениях на денежные переводы - MICR CMC7. Этот тип, в частности, является во Франции стандартом для документов платёжной клиринговой системы. - Поддержка внешних словарей
Дополнительно к собственным словарям и словарям, созданным по внутренним стандартам программы (как пользовательским, так и на основе регулярных выражений), ABBYY FineReader Engine поддерживает внешние словари, созданные по правилам интеграторов или внешними разработчиками.
- Дополнительный модуль: расширенная информация о символе
Новый дополнительный модуль позволяет разработчикам получить полную детальную информацию о свойствах каждого распознанного объекта (тип текста, штрих знака, параметры параграфа, регистр, верхний/нижний индекс и другие). Также он даёт возможность легко экспортировать данные в любой XML-формат, поддерживаемый FineReader Engine.
- Сохранение внешних данных в профили FineReader Engine
Новая версия позволяет разработчику специфицировать в профиле не только настройки распознавания и обработки, но и параметры, относящиеся к базовому приложению, а также сохранять всю эту информацию в одном INI-файле.
Спецификация
Сопроводительная техническая документация
- Встроенная справочная система (формат CHM, на английском языке) содержит подробное описание API и общие сведения о лицензировании и активации.
- Примеры кода, поставляемые вместе с инструментарием разработчика FineReader Engine 8.1, демонстрируют использование API для решения типовых задач. Данные примеры могут быть скопированы, изменены и использованы для создания приложений с помощью FineReader Engine API.
- Руководство системного администратора содержит информацию об установке FineReader Engine в локальной сети, а также сведения об управлении лицензиями с помощью программы Network License Manager.
Поддерживаемые среды разработки
- Microsoft Visual Studio.NET (VB.NET, C#)
- Microsoft Visual Basic 5.0, 6.0
- Microsoft Visual C++ версия 4. x или более поздняя
- VB Script и другие языки сценариев
- Borland Delphi, версия 2.0 или более поздние
- Любые другие среды разработки, корректно поддерживающие интерфейс COM и компоненты ActiveX.
Языки сообщений
Заголовки и тексты диалогов, сообщения об ошибках и другие сообщения программы могут выводиться на английском, немецком, итальянском, французском, испанском, нидерландском, португальском, русском, эстонском, польском, чешском, словацком, венгерском, болгарском, украинском, шведском, греческом, литовском и латышском языках.
Требования к системе
Автономная установка с лицензией на использование или разработку
- Компьютер с процессором Intel Pentium/ Celeron/ Xeon, AMD K6/ Athlon/ Duron/ Sempron или другим совместимым с ними процессором с тактовой частотой не менее 200 МГц.
- Операционная система Microsoft Windows 2003, Windows XP, Windows 2000, Windows NT 4.0 (с пакетом обновления SP 6 или более поздним), Windows Me/98. Для работы с локализованным интерфейсом операционная система должна поддерживать соответствующий язык.
- Оперативная память: 128 Мб.
- Свободное пространство на жёстком диске: 350 Мб для типовой установки, плюс 70 Мб для работы программы.
- 100% TWAIN -совместимый сканер, цифровая камера или факс-модем.
- Видеокарта и монитор (минимальное разрешение 800х600)
- Клавиатура, мышь или иное устройство указания/ввода.
- Пользователь должен иметь права на чтение и запись для следующих разделов системного реестра:
- HKEY_CLASSES_ROOT
- HKEY_LOCAL_MACHINE\Software\ABBYY
- HKEY_CURRENT_USER\Software\ABBYY
Сетевая установка с лицензией на использование
Для установки программы в данной конфигурации существуют следующие требования к серверу и рабочим станциям:
Требования к серверу
- Компьютер с процессором Intel Pentium/Celeron/Xeon, AMD K6/ Athlon/Duron или другим совместимым с ними процессором с тактовой частотой не менее 200 МГц
- Операционная система: Microsoft Windows 2003 Server, Windows XP, Windows 2000.
- Свободное пространство на жёстком диске: 10 Мб.
- Все пользователи ABBYY FineReader Engine 8.1 должны иметь права:
- на чтение для папки административной установки,
- на запись для папки License Manager.
- Сервер должен обеспечивать количество подключений, достаточное для всех пользователей ABBYY FineReader Engine 8.1. (Например, Microsoft Windows 2000 Professional допускает не более 10 одновременных подключений и при использовании данного сервера программа может быть развернута не более, чем на 10 рабочих станциях).
Требования к рабочей станции
Минимальные требования к рабочей станции, позволяющие установить и использовать ABBYY FineReader Engine 8.1:
- Компьютер с процессором Intel Pentium/Celeron/Xeon, AMD K6/ Athlon/Duron/Sempron или другим совместимым с ними процессором с тактовой частотой не менее 200 МГц
- Операционная система: Microsoft Windows 2003, Windows XP, Windows 2000, Windows NT 4.0 с пакетом обновления SP 6 или более поздним, Windows Me /98*. Для работы с локализованным интерфейсом операционная система должна поддерживать соответствующий язык.
- Оперативная память: 128 Мб.
- Свободное пространство на жёстком диске: 350 Мб для типовой установки, плюс 70 Мб для работы программы.
- 100% TWAIN-совместимый сканер, цифровая камера или факс-модем.
- Видеокарта и монитор (минимальное разрешение 800?600).
- Клавиатура, мышь или иное устройство ввода/указания.
- Все пользователи ABBYY FineReader Engine 8.1 должны иметь права на чтение/запись для следующих разделов реестра:
- HKEY_CLASSES_ROOT
- HKEY_LOCAL_MACHINE\Software\ABBYY
- HKEY_CURRENT_USER\Software\ABBYY
- HKEY_CLASSES_ROOT\CLSID
- HKEY_CLASSES_ROOT\TypeLib - только для инсталляции и активации.
- Следующие папки должны быть полностью доступны с рабочей станции:
- Папка с бинарными файлами ABBYY FineReader Engine 8.1
- Папка с временными файлами ABBYY FineReader Engine 8.1 (обычно это папка C:\FineReader8.SDK\Temp)
- Следующие компоненты должны быть установлены дополнительно:
- Microsoft Internet Explorer 5.0 или более поздней версии.
- Если приложение использует любой из методов ABBYY FineReader Engine для создания элементов пользовательского интерфейса, то компонента Windows Common Controls должна быть версии 5.80 или более поздней, компонента Rich Edit Control версии 3.0 или более поздней.
- Если на рабочей станции используется операционная система Windows Me /98, необходимо установить на ней DCOM98 1.3 (версию DCOM для Microsoft Windows 98 v 1.3).
* - открытие PDF-файлов возможно только при работе под операционными системами Microsoft Windows 2003, Windows XP, Windows 2000.
Форматы ввода/вывода
Поддерживаемые форматы изображений:
- BMP: чёрно-белый, серый, цветной
- PCX, DCX: чёрно-белый, серый, цветной
- JPEG: серый, цветной
- JPEG 2000, part1: серый, цветной
- PNG: чёрно-белый, серый, цветной
- TIFF: чёрно-белый, серый, цветной, многостраничный. Способы сжатия: несжатый, CCITT Group 3, CCITT Group 3 FAX (2D), CCITT Group 4, PackBits, JPEG, ZIP
- GIF
- DjVu
Форматы сохранения документов:
- Microsoft Word (*.DOC)
- Rich Text Format (*.RTF)
- Microsoft Word XML (*.XML) (только для Microsoft Office Word 2003)
- XML со схемой представления данных FineReader (*.XML).
- Adobe Acrobat (*.PDF)
- HTML. FineReader поддерживает различные кодовые страницы (Windows, DOS, Mac, ISO) и кодовые страницы Unicode (UTF-8).
- Microsoft PowerPoint (*.PPT)
- Формат с разделением запятыми (*. CSV). FineReader поддерживает различные кодовые страницы (Windows, DOS, Mac, ISO) и кодовые страницы (UTF-16, UTF-8).
- Обычный текст (*. TXT). FineReader поддерживает различные кодовые страницы (Windows, DOS, Mac, ISO) и кодовые страницы Unicode (UTF-16, UTF-8).
- Microsoft Excel (*.XLS)
- DBF. FineReader поддерживает различные кодовые страницы (Windows, DOS, Mac, ISO).
Языки распознавания
Распознавание печатного текста (OCR):
ABBYY FineReader Engine 8.1 поддерживает распознавание печатного текста (OCR) на 191 языке:
- 37 основных языков, для которых реализована морфологическая поддержка и проверка правописания: армянский (восточный, западный, грабар), болгарский, каталанский, хорватский, чешский, датский, голландский (Нидерланды и Бельгия), английский, эстонский, финский, французский, немецкий (новая и старая орфография), греческий, венгерский, итальянский, латышский, литовский, норвежский (нюнорск и букмол), индонезийский, польский, португальский (Португалия и Бразилия), румынский, русский, словацкий, словенский, испанский, шведский, татарский, башкирский, турецкий и украинский.
- 4 восточно-азиатских языка со словарной поддержкой: китайский (традиционный и упрощённый), японский и корейский.
- Тайский язык.
- 5 языков для распознавания документов, напечатанных в XVII - XIX столетиях (с морфологической поддержкой): английский, французский, немецкий, итальянский и испанский.
- Еврейский язык (иврит) со словарной поддержкой.
- 133 дополнительных языка, использующих латинский, кириллический или греческий алфавиты: абхазский, адыгейский, африкаанс, агульский, албанский, алтайский, аварский, аймара, азербайджанский (кирилица), азербайджанский (латиница), баскский, белорусский, бемба, блэкфут, бретонский, буготу, бурятский, себуанский, чаморро, чеченский, чукотский, чувашский, конго, корсиканский, крымско-татарский, кроу, дакота, даргинский, дунганский, эскимосский (кириллица), эскимосский (латиница), эвенский, эвенкийский, фарерский, фризский, фриульский, гагаузский, галисийский, ганда, немецкий (Люксембург), гуарани, хани, хауса, гавайский, исландский, индонезийский, ингушский, ирландский, цзинпо, кабардино-черкесский, калмыкский, карачаево-балкарский, каракалпакский, кашубский, гэлао, казахский, хакасский, хантыйский, кикуйю, киргизский, корякский, кпелле, кумыкский, курдский, лакский, латинский, лезгинский, луба, македонский, малагасийский, малайский, малинке, мальтийский, мансийский, маори, марийский, майа, мяо, минангкабау, могавк, молдавский (кириллица), молдавский (латиница), монгольский, мордовский, ацтекский, ненецкий, нивхский, ногайский, ньянджа, оджибве, осетинский, папьяменто, провансальский, кечуа, ретороманский, цыганский, рунди, русский (старая орфография), руанда, саамский, самоа, гелький (Шотландия), селькупский, сербский (кириллица), сербский (латиница), шона, сомали, лужицкий, сото, сунданский, суахили, свази, табасаранский, тагальский, таити, таджикский, ток-писин, тонга, тсвана, дун, туркменский, тувинский, удмуртский, уйгурский (кириллица), уйгурский (латиница), узбекский (кириллица), узбекский (латиница), валлийский, волоф, коса, якутский, сапотек, зулу.
- 4 искусственных языка: эсперанто, интерлингва, идо, оксиденталь.
- 6 языков программирования: Basic, C/C++, COBOL, Fortran, JAVA и Pascal.
- Простые химические формулы.
- Цифры.
- Распознавание различных типов текста: типографская печать, печатная машинка, матричный принтер, MICR (E13B), MICR (CMC7), OCR-A, OCR-B.
- Предусмотрены средства для создания пользовательских языков.
Распознавание рукопечатного текста (ICR):
ABBYY FineReader Engine 8.1 поддерживает распознавание текста, написанного печатными буквами от руки, (ICR) на 92 языках:
- 22 языка с морфологической/словарной поддержкой и проверкой правописания:
- 17 языков, в которых используется латиница: английский, венгерский, испанский, итальянский, литовский, немецкий (старая и новая орфография), нидерландский, нидерландский (Бельгия), польский, румынский, словацкий, турецкий, чешский, финский, французский, хорватский.
- Греческий язык.
- 3 языка, в которых используется кириллица*: болгарский, русский, украинский.
- 70 языков, в которых используется латиница, без словарной поддержки.
- Поддержка 22 стилей начертания рукопечатных знаков, в том числе европейского, американского, канадского, русского, японского, арабского и тайского стилей.
- Распознавание современных арабских цифр, которые используются
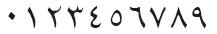 в большинстве стран Ближнего Востока.
в большинстве стран Ближнего Востока.
* - предоставляется только по специальному запросу.
Типы штрих-кодов
- Одномерные: Check Code 39, Check Interleaved 25, Code 128, Code 39, EAN 13, EAN 13 Supplemental, EAN 8, Interleaved 25, CODABAR (без контрольной суммы), UCC Code 128, Code 2 of 5 (Industrial, IATA, Matrix), Code 93, UPC-A, UPC-E и Postnet.
- Двумерные: PDF 417.