
Быстродействие системы Linux вы можете увеличить разными способами, и один из наиболее популярных -- увеличить производительность процессора. Очевидное решение -- использовать процессор с большей тактовой частотой, но для любой технологии существует физическое ограничение, когда тактовый генератор просто не может работать быстрее. При достижении этого предела вы можете использовать гораздо лучший подход и применить несколько процессоров. К сожалению, быстродействие имеет нелинейную зависимость от совокупности параметров отдельных процессоров.
Прежде чем обсуждать применение многопроцессорной обработки в Linux, давайте взглянем на ее историю.
История многопроцессорной обработки
|
Многопроцессорная обработка зародилась в середине 1950-х в ряде компаний, некоторые из которых вы знаете, а некоторые, возможно, уже забыли (IBM, Digital Equipment Corporation, Control Data Corporation). В начале 1960-х Burroughs Corporation представила симметричный мультипроцессор типа MIMD с четырьмя CPU, имеющий до шестнадцати модулей памяти, соединенных координатным соединителем (первая архитектура SMP). Широко известный и удачный CDC 6600 был представлен в 1964 и обеспечивал CPU десятью подпроцессорами (периферийными процессорами). В конце 1960-х Honeywell выпустил другую симметричную мультипроцессорную систему из восьми CPU Multics.
В то время как многопроцессорные системы развивались, технологии также шли вперед, уменьшая размеры процессоров и увеличивая их способности работать на значительно большей тактовой частоте. В 1980-х такие компании, как Cray Research, представили многопроцессорные системы и UNIX®-подобные операционные системы, которые могли их использовать (CX-OS).
В конце 1980-х с популярностью однопроцессорных персональных компьютеров, таких как IBM PC, наблюдался упадок в многопроцессорных системах. Но сейчас, двадцать лет спустя, многопроцессорная обработка вернулась к тем же самым персональным компьютерам в виде симметричной многопроцессорной обработки.
Джин Амдаль (Gene Amdahl), компьютерный архитектор и сотрудник IBM, разрабатывал в IBM компьютерные архитектуры, создал одноименную фирму, Amdahl Corporation и др. Но известность ему принес его закон, в котором рассчитывается максимально возможное улучшение системы при улучшении ее части. Закон используется, главным образом, для вычисления максимального теоретического улучшения работы системы при использовании нескольких процессоров (смотри Рисунок 1).
Рисунок 1. Закон Амдаля для распараллеливания процессов![]()
Используя уравнение, показанное на Рисунке 1, вы можете вычислить максимальное улучшение производительности системы, использующей N процессоров и фактор F , который указывает, какая часть системы не может быть распараллелена (часть системы, которая последовательна по своей природе). Результат приведен на Рисунке 2.
Рисунок 2. Закон Амдаля для системы, имеющей до десяти CPU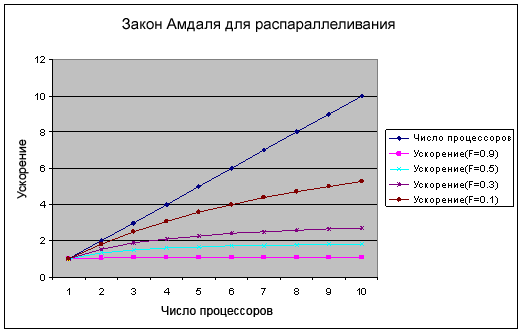
Верхняя линия на Рисунке 2 показывает число процессоров. В идеале это то, что вы хотели бы увидеть после добавления дополнительных процессоров для решения задачи. К сожалению, из-за того что не все в задаче может быть распараллелено и есть непроизводительные издержки в управлении процессорами, ускорение оказывается немного меньше. Внизу (лиловая линия) -- случай задачи, которая на 90% последовательна. Лучшему случаю на этом графике соответствует коричневая линия, которая изображает задачу, которая на 10% последовательна и, соответственно, на 90% -- параллелизуема. Даже в этом случае десять процессоров работают совсем не намного лучше, чем пять.
Многопроцессорная обработка и ПК
Архитектура SMP -- одна из тех, где два или более идентичных процессоров соединены друг с другом посредством разделяемой памяти. У всех них одинаковый доступ к разделяемой памяти (одинаковое время ожидания доступа к пространству памяти). Противоположностью ей является архитектура неоднородного доступа к памяти (NUMA -- Non-Uniform Memory Access). Например, у каждого процессора есть своя собственная память и доступ к разделяемой памяти с разным временем ожидания.
Слабосвязанная многопроцессорная обработка
Ранние SMP системы Linux были слабосвязанными многопроцессорными системами, то есть построенными из нескольких отдельных систем, связанных высокоскоростным соединением (таким как 10G Ethernet, Fibre Channel или Infiniband). Другое название такого типа архитектуры -- кластер (смотрите Рисунок 3), для которого популярным решением остается проект Linux Beowulf. Кластеры Linux Beowulf могут быть построены из доступного оборудования и обычного сетевого соединения, такого как Ethernet.
Рисунок 3. Слабосвязанная многопроцессорная архитектура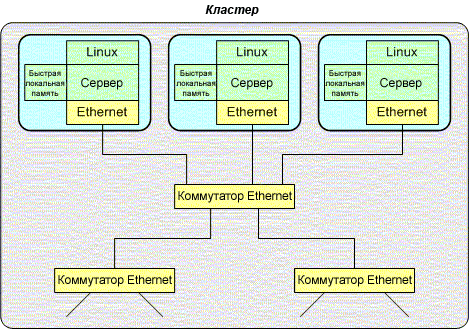
Построение систем со слабосвязанной многопроцессорной архитектурой просто (спасибо проектам вроде Beowulf), но имеет свои ограничения. Создание большой многопроцессорной сети может потребовать значительных мощностей и места. Более серьезное препятствие -- материал канала связи. Даже с высокоскоростной сетью, такой как 10G Ethernet, есть предел масштабируемости системы.
Сильносвязанная многопроцессорная обработка
Сильносвязанная многопроцессорная обработка относится к обработке на уровне кристалла (CMP -- chip-level multiprocessing). Представьте слабосвязанную архитектуру, уменьшенную до уровня кристалла. Это и есть идея сильносвязанной многопроцессорной обработки (также называемой многоядерным вычислением). На одной интегральной микросхеме несколько кристаллов, общая память и соединение образуют хорошо интегрированное ядро для многопроцессорной обработки (смотрите Рисунок 4).
|
Рисунок 4. Сильносвязанная архитектура многопроцессорной обработки
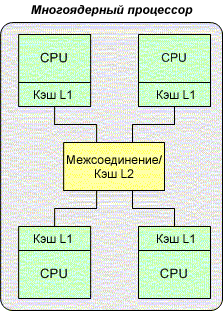
В CMP несколько CPU связаны общей шиной с разделяемой памятью (кэш второго уровня). Каждый процессор также имеет свою собственную быстродействующую память (кэш первого уровня). Сильносвязанная природа CMP позволяет очень короткие физические расстояния между процессорами и памятью и, вследствие этого, минимальное время ожидания доступа к памяти и более высокую производительность. Такой тип архитектуры хорошо работает в многопоточных приложениях, где потоки могут быть распределены между процессорами и выполняться параллельно. Это называется параллелизм на уровне потоков (TPL -- thread-level parallelism).
Принимая во внимание популярность этой многопроцессорной архитектуры, многие производители выпускают устройства CMP. В Таблице 1 приведены некоторые популярные варианты с поддержкой Linux.
Таблица 1. Выборка устройств CMP
| Производитель | Устройство | Описание |
|---|---|---|
| IBM | POWER4 | SMP, два CPU |
| IBM | POWER5 | SMP, два CPU, четыре параллельных потока |
| AMD | AMD X2 | SMP, два CPU |
| Intel® | Xeon | SMP, два или четыре CPU |
| Intel | Core2 Duo | SMP, два CPU |
| ARM | MPCore | SMP, до четырех CPUs |
| IBM | Xenon | SMP, три Power PC CPU |
| IBM | Cell Processor | Асимметричная многопроцессорная обработка (ASMP --Asymmetric multiprocessing), девять CPU |
Для того чтобы использовать SMP с Linux на совместимом с SMP оборудовании, необходимо правильно настроить ядро. Опция CONFIG_SMP должна быть включена во время настройки ядра, чтобы ядро знало об SMP. Если такое ядро будет работать на многопроцессорном хосте, вы сможете определить количество процессоров и их тип с помощью файловой системы proc.
Сначала вы получаете число процессоров из файла cpuinfo в /proc, используя grep. Как видно из Листинга 1, вы используете опцию -- счетчик (-c) строк, начинающихся со слова processor. Приведено также содержимое файла cpuinfo. В качестве примера взята материнская плата Xeon на двух кристаллах.
Листинг 1. Использование файловой системы proc для получения информации о CPU
mtj@camus:~$ grep -c ^processor /proc/cpuinfo 8 mtj@camus:~$ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 15 model : 6 model name : Intel(R) Xeon(TM) CPU 3.73GHz stepping : 4 cpu MHz : 3724.219 cache size : 2048 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 2 fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 6 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm pni monitor ds_cpl est cid xtpr bogomips : 7389.18 ... processor : 7 vendor_id : GenuineIntel cpu family : 15 model : 6 model name : Intel(R) Xeon(TM) CPU 3.73GHz stepping : 4 cpu MHz : 3724.219 cache size : 2048 KB physical id : 1 siblings : 4 core id : 3 cpu cores : 2 fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 6 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm pni monitor ds_cpl est cid xtpr bogomips : 7438.33 mtj@camus:~$ |
Когда только появился Linux 2.0, поддержка SMP состояла из основной системы блокировки, которая упорядочивала доступ в системе. Позднее небольшой прогресс в поддержке SMP был, но только с ядром 2.6 наконец проявилась вся сила SMP.
Ядро 2.6 представило новый 0(1) планировщик, который включал лучшую поддержку для систем SMP. Ключевой была возможность балансировать нагрузку на все доступные CPU, по мере сил избегая переключения процессов между процессорами для более эффективного использования кэша. Что касается производительности кэша, вспомните из Рисунка 4, что когда задача взаимодействует с одним CPU, перемещение ее на другой требует вовлечения кэша. Это увеличивает время ожидания доступа к памяти задачи, пока ее данные находятся в кэше нового CPU.
|
Ядро 2.6 сохраняет пару runqueue для каждого процессора (истекший и активный runqueue). Каждый runqueue поддерживает 140 приоритетов, из которых 100 используется для задач в реальном времени, а остальные 40 для пользовательских задач. Задачам даются отрезки времени для выполнения, а когда они используют свое время, они перемещаются из активного runqueue в истекший. Таким образом осуществляется равноправный доступ к CPU для всех задач (блокировка только отдельных CPU).
С очередью задач на каждом CPU работа может быть сбалансирована, давая взвешенную нагрузку всех CPU в системе. Каждые 200 миллисекунд планировщик выполняет балансировку загрузки, чтобы перераспределить задания и сохранить баланс в комплексе процессоров.
Потоки пользовательского пространства: развивая силу SMP
В ядре Linux была проделана большая работа для развития SMP, но операционной системы, самой по себе, недостаточно. Вспомните, что сила SMP заключается в TLP. Отдельные монолитные (одно-поточные) программы не могут использовать SMP, но SMP может использоваться в программах, которые состоят из многих потоков, которые могут быть распределены между ядрами. Пока один поток ожидает выполнения операции I/O, другой может делать полезную работу. Таким образом, потоки работают, перекрывая время ожидания друг друга.
Потоки стандарта Portable Operating System Interface (POSIX) (интерфейс переносимой операционной системы) являются прекрасным способом построить поточные приложения, которые могут использовать SMP. Потоки стандарта POSIX обеспечивают механизм работы с потоками, а также общую память. Когда программа активизируется, создается некоторое количество потоков, каждый из которых поддерживает свой собственный стек (локальные переменные и состояние), но разделяет пространство данных родителя. Все созданные потоки разделяют это же самое пространство данных, но именно здесь кроется проблема.
Чтобы поддерживать многопоточный доступ к разделяемой памяти, требуются механизмы координирования. POSIX предоставляет функцию взаимного исключения для создания критических секций , которые устанавливают исключительный доступ к объекту (участку памяти) только для одного потока. Если этого не сделать, может повредиться память из-за несинхронизованных манипуляций, производимых несколькими потоками. Листинг 2 иллюстрирует создание критической секции с помощью взаимного исключения POSIX.
Листинг 2. Использование pthread_mutex_lock и unlock для создания критических секций
pthread_mutex_t crit_section_mutex = PTHREAD_MUTEX_INITIALIZER; ... pthread_mutex_lock( &crit_section_mutex ); /* Внутри критической секции. Доступ к памяти здесь безопасен * для памяти, защищенной crit_section_mutex. */ pthread_mutex_unlock( &crit_section_mutex ); |
Если несколько потоков пытаются заблокировать семафор после начального вызова наверху, они блокируются, и их запросы ставятся в очередь, пока не выполнится вызов
pthread_mutex_unlock.
Защита переменной ядра для SMP
Когда несколько ядер в процессоре работает параллельно для ядра ОС, желательно избегать совместного использования данных, которые специфичны для данного ядра процессора. По этой причине ядро 2.6 представило концепцию переменных для каждого ядра, которые связаны с отдельными CPU. Это позволяет объявлять переменные для CPU, которые наиболее часто используются именно этим CPU, что минимизирует требования блокировок и улучшает выполнение.
Определение переменных отдельного ядра производится при помощи макроса DEFINE_PER_CPU, которому вы передаете тип и имя переменной. Поскольку макрос поступает как l-value, здесь же вы можете инициализировать ее. В следующем примере (из ./arch/i386/kernel/smpboot.c) определяется переменная, представляющая состояние для каждого CPU в системе.
/* State of each CPU. */
DEFINE_PER_CPU(int, cpu_state) = { 0 };
|
Макрос создает массив переменных, одну на каждый экземпляр CPU. Для получения переменной отдельного CPU используется макрос
per_cpu вместе с функцией smp_processor_id, возвращающей текущий идентификатор CPU, для которого в данный момент выполняется программа.
per_cpu( cpu_state, smp_processor_id() ) = CPU_ONLINE; |
Ядро предоставляет другие функции для блокировки каждого CPU и динамического выделения переменных. Эти функции можно найти в ./include/linux/percpu.h.
Когда частота процессора достигает своего предела, для увеличения производительности обычно просто добавляют еще процессоры. Раньше это означало добавить больше процессоров к материнской плате или объединить в кластер несколько независимых компьютеров. Сегодня многопроцессорная обработка на уровне кристалла предоставляет больше процессоров на одном кристалле, давая еще большее быстродействие путем уменьшения времени ожидания памяти.
Системы SMP вы найдете не только на серверах, но и на десктопах, особенно с внедрением виртуализации. Как многие передовые технологии, Linux предоставляет поддержку для SMP. Ядро выполняет свою часть по оптимизации загрузки доступных CPU (от потоков до виртуализованных операционных систем). Все, что остается, это убедиться, что приложение может быть в достаточной мере разделено на потоки, чтобы использовать силу SMP.