
К сожалению, выбор компилятора часто обусловлен, опять-таки, идеологией и соображениями вроде "его все используют". Конечно, среда разработки Microsoft Visual C++ несколько более удобна, чем у портированного gcc - но это ведь вовсе не значит, что релиз своего продукта вы должны компилировать с использованием MSVC++. Используйте оболочку, компилируйте промежуточные версии на MSVC++ (кстати, время компиляции у него гораздо меньше, чем у gcc), но релиз можно собрать с использованием другого компилятора, например от Intel. И, в зависимости от компилятора, можно получить прирост в производительности на 10% просто так, на ровном месте. Но какой "правильный" компилятор выбрать, чтобы он сгенерировал максимально быстрый код? К сожалению, однозначного ответа на этот вопрос нет - одни компиляторы лучше оптимизируют виртуальные вызовы, другие - лучше работают с памятью.
Попробуем определить, кто в чем силен среди компиляторов для платформы Wintel (x86-процессор + Win32 ОС). В забеге принимают участие компиляторы Microsoft Visual C++ 6.0, Intel C++ Compiler 4.5, Borland Builder 6.0, MinGW (портированный gcc) 3.2.
Порядок тестирования
Как проверить, насколько эффективный код генерирует компилятор? Очень просто: нужно выбрать несколько наиболее часто употребляемых конструкций языка и алгоритмов - и измерить время их выполнения после компиляции различными компиляторами. Для более точного определения времени необходимо набрать статистику и выполнить каждую конструкцию некоторое количество раз.
Вроде все просто - но тут начинают возникать определенные проблемы. Провести тестирование некоторых конструкций (например, обращение к полю объекта) не удастся из-за оптимизации на уровне компилятора: строки типа for (unsigned i=0;i<10000000;i++) dummy = obj->dummyField; все компиляторы просто выбросили из конечного бинарного кода.
Вторым неприятным моментом является то, что в результаты всех тестов неявно вошло время выполнения самого цикла "for", в котором происходит набор статистики. В некоторых реализациях оно может быть очень даже существенным (например, два такта на одну итерацию пустого for для gcc). Измерить "чистое" время выполнения пустого цикла удалось не для всех компиляторов - VC++ и Intel Compiler выполняют достаточно хорошую "раскрутку" кода и исключают из конечного кода все пустые циклы, inline-вызовы пустых методов и т.д. Даже конструкцию вида for (unsigned i=0;i<16;i++) dummy++; VC++ реализовал как dummy += 16;.
Наличие такой нетривиальной низкоуровневой оптимизации наводит на мысль о необходимости анализа сгенерированного кода на уровне ассемблера. Во-первых, это позволит убедиться в том, что мы действительно измерили то, что хотели измерить (а не оптимизированный компилятором пустой цикл, из которого он выбросил все "лишние" вызовы). Во-вторых, это позволит более точно определить, чей код наиболее оптимален, что существенно дополнит картину тестирования.
Кроме того, для полноты картины было проведено тестирование времени компиляции работающего исходника с целью определить, у какого же из компиляторов время компиляции наименьшее.
Для измерения времени выполнения тестов использовался счетчик машинных тактов, доступный по команде процессора RDTSC, что позволило не только сравнить время выполнения большого количества однотипных операций, но и получить приближенное время выполнения операции в тактах (вторая величина является более показательной и удобной для сравнения). Все тесты проводились на Pentium III (700 МГц), параметры компиляции были установлены в "-O2 -6" (оптимизация по скорости + оптимизация под набор команд Pentium Pro). Кроме того, для Borland Builder была добавлена опция --fast-call - передача параметров через регистры (Intel Compiler, MSVC++ и gcc автоматически используют передачу параметров через регистры при использовании оптимизации по скорости).
Тестирование было разделено на несколько независимых частей. Первая - тестирование скорости работы основных конструкций языка (виртуальные вызовы, прямые вызовы и т.д.). Вторая - тестирование скорости работы STL. Третья - тестирование менеджера памяти, поставляемого вместе с компилятором. Четвертая - разбор ассемблерного кода таких базовых операций, как вызов функции и построения цикла. Пятая - сравнение времени компиляции и размера выполняемого файла.
Тестирование скорости работы основных конструкций языка
Первый тест очень даже прост, он заключается в измерении скорости прямого вызова (member call), виртуального вызова (virtual call), вызова статик-метода (данная операция полностью аналогична вызову обыкновенной функции), создания объекта и удаления объекта с виртуальным деструктором (create object), создания/удаления объекта с inline-конструктором и деструктором (create inline object), создание template'ного объекта (create template object). Результаты теста приведены в таблице 1.
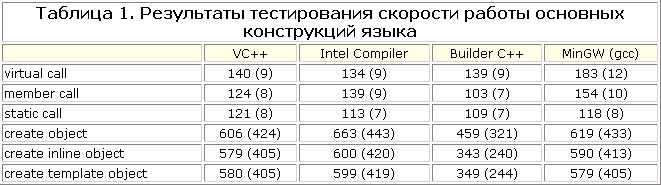
Первая цифра - это полное время, затраченное на тест (в миллисекундах); цифра в скобках - количество тактов на одну команду.
Результаты получились очень даже интересными: первое место занял Borland Builder, а вот gcc на вызове методов, особенно виртуальных, показал существенное отставание. По всей видимости - из-за бурного развития COM'а, где все вызовы виртуальные, разработчикам "родных" компиляторов под Win32 пришлось максимально оптимизировать эти типы вызовов. Другим интересным фактом является то, что хорошо оптимизировать создание объекта с inline-конструктором и деструктором смог, опять-таки, только Builder.
Конечно, у MSVC++ также наблюдается небольшой прирост производительности, но объясняется это тем, что MSVC++ очень хорошо "раскручивает" код и все заглушки просто выбрасывает. То есть в тесте с inline-вызовами MSVC++ определил, что вызываемый метод является пустым, и исключил его вызов. После исключения вызова пустого метода у него остался пустой цикл, который компилятор также выбросил.
Borland же в случае использования inline-конструктора делает inline не только вызов метода "Конструктор", но и выделение памяти под объект. То же самое делает Builder относительно деструктора. Любопытно отметить, что с шаблонами Builder работает точно так же, как с inline-методами, чего совершенно не скажешь о других компиляторах.
Тестирование STL
STL, как известно, входит в ISO стандарт C++ и содержит очень много полезного и превосходно реализованного кода, использование которого существенно облегчает жизнь программистам. Конечно, MCVC++, gcc и Builder используют различные реализации STL - и результаты тестирования будут сильно зависеть от эффективности реализации тех или иных алгоритмов, а не от качества самого компилятора. Но, так как STL входит в ISO-стандарт, тестирование этой библиотеки просто неотделимо от тестирования самого компилятора.
Проводилось тестирование только наиболее часто используемых классов STL: string, vector, map, sort. При тестировании string'а измерялась скорость конкатенации; для vector'а же - время добавления элемента (удаление не тестировалось, так как это просто тестирование realloc'а, которое будет проведено ниже); для map'а измерялось время добавления элемента и скорость поиска необходимого ключа; для sort'а - время сортировки. Так как Microsoft не рекомендует использовать STL в VC++, для сравнения было добавлено тестирование конкатенации строк на основе родного класса VC++ для работы со строками CString и, чтобы уж совсем никого не обидеть, то и родного класса Builder'а - AnsiString. Результаты, опять же, оказались очень даже интересными (см. табл. 2)
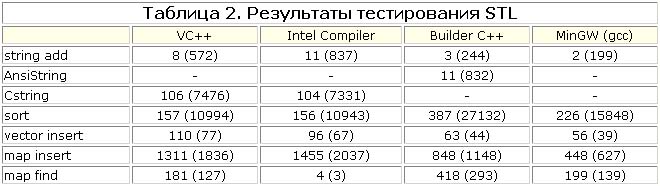
Согласно результатам, не рекомендованный STL string работает в 12 раз быстрее, чем родной CString Microsoft! Как тут в очередной раз не задуматься о практичности рекомендаций Microsoft... А вот просто потрясающий результат на поиске от Intel Compiler это результат оптимизации "ничего не делающего кода" - поиск как таковой он просто выбросил из конечного бинарного кода. Не менее интересен результат gcc - во всех тестах, связанных с выделением памяти, gcc оказался на первом месте.
Тестирование менеджера памяти
Как известно, при выделении памяти malloc редко обращается напрямую к системе - и использует вместо этого свою внутреннюю структуру для динамического выделения памяти и изменения размера уже выделенного блока. Скорость работы этого внутреннего менеджера может весьма существенно влиять на скорость работы всего приложения. Тестирование менеджера памяти было разбито на две части: в первой измерялась скорость работы пары malloc/free, а во второй - malloc/realloc, причем realloc должен был выделить вдвое больший объем памяти, чем malloc.

И снова быстрее всех был Borland Builder C++. Благодаря такой быстрой реализации malloc'а он находится на первом месте и по скорости создания/удаления объектов - да и на тестах STL, связанных с изменением размера блока памяти, бегает достаточно быстро.
Разбор ассемблерного кода неких базовых операций
Для анализа использовался достаточно простой код на С++:
void dummyFn1(unsigned);
void dummyFn2(unsigned aa) {
for (unsigned i=0;i<16;i++) dummyFn1(aa);
}
А теперь посмотрим, во что этот кусок кода компилирует MSVC++ (приводится только текст необходимой функции):
?dummyFn2@@YAXI@Z PROC NEAR
push esi
push edi
mov edi, DWORD PTR _aa$[esp+4]
mov esi, 16
$L271:
push edi
call?dummyFn1@@YAXI@Z
add esp, 4
dec esi
jne SHORT $L271
pop edi
pop esi
ret 0
?dummyFn@@YAXI@Z ENDP
Как видно, MSVC++ инвертировал цикл и for (unsigned i=0;i<16;i++) у него превратился в unsigned i=16;while (i--);, что очень правильно с точки зрения оптимизации - мы экономим на одной операции сравнения (см. следующий листинг), которая занимает, как минимум, 5 байт, и нарушает выравнивание. Конечно, компилятор по своему усмотрению поменял порядок изменения переменной i, но в данном примере мы ее используем просто как счетчик цикла, поэтому такая замена вполне допустима.
А вот что выдал Intel Compiler (вообще-то, он сначала вообще полностью развернул цикл, но после увеличения количества итераций на порядок прекратил заниматься такой самодеятельностью):
?dummyFn2@@YAXI@Z PROC NEAR
$B1$1:
push ebp
push ebx
mov ebp, DWORD PTR [esp+12]
sub esp, 20
xor ebx, ebx
$B1$2:
mov DWORD PTR [esp], ebp
call?dummyFn1@@YAXI@Z
$B1$3:
inc ebx
cmp ebx, 16
jb $B1$2
$B1$4:
add esp, 20
pop ebx
pop ebp
ret
?dummyFn2@@YAXI@Z ENDP
Во-первых, используется прямой порядок цикла for, поэтому появилась дополнительная команда сравнения "cmp ebx, 16". А вот и очень интересный момент -перед началом цикла мы выделили на стеке необходимое количество памяти плюс некий запас ("sub esp, 20"), а потом вместо пары push reg;..;add esp, 4;, как это делает MSVC++, использовали одну команду копирования. Кроме того, использование регистра общего назначения ebx для счетчика цикла вместо индексного esi, как в MSVC++, дополнительно уменьшает время выполнения и размер кода.
Borland Builder сгенерировал следующую конструкцию:
@@dummyFn2$qui proc near
?live16385@0:
@1:
push ebp
mov ebp,esp
push ebx
push esi
mov esi,dword ptr [ebp+8]
?live16385@16:
@2:
xor ebx,ebx
@3:
push esi
call @@dummyFn1$qui
pop ecx
@5:
inc ebx
cmp ebx,16
jb short @3
?live16385@32:
@7:
pop esi
pop ebx
pop ebp
ret
@@dummyFn2$qui endp
Если не считать большего количества подготовительных операций, то блок вызова собственно функции является чем-то средним между MSVC++ и Intel Compiler: цикл используется прямой и передача параметров осуществляется с помощью push reg;. Правда, есть интересный момент: вместо add esp, 4 используется pop ecx; что экономит, как минимум, 4 байта,- правда, из-за дополнительного обращения к памяти команда "pop" может работать медленнее, чем сложение.
Ну и, наконец, gcc (обратите внимание, gcc для ассемблера использует синтаксис AT&T):
__Z7dummy2Fnj:
LFB1:
pushl %ebp
LCFI0:
movl %esp, %ebp
LCFI1:
pushl %esi
LCFI2:
pushl %ebx
LCFI3:
xorl %ebx, %ebx
movl 8(%ebp), %esi
.p2align 4,,7
L6:
subl $12, %esp
incl %ebx
pushl %esi
LCFI4:
call __Z2dummyFn1j
addl $16, %esp
cmpl $15, %ebx
jbe L6
leal -8(%ebp), %esp
popl %ebx
popl %esi
popl %ebp
ret
Данный код является самым плохим из всех приведенных выше - gcc использует прямой цикл плюс пару push esi;..;add esp, 4 (это происходит неявно в команде "addl $16, %esp") для передачи параметров; кроме того, резервирует место на стеке прямо в цикле, а не вне его, как это делает Intel Compiler. Кроме того, совершенно непонятно, зачем резервировать место на стеке, а потом использовать команду push reg;. Единственный приятный момент - это явное выравнивание начала цикла по границе, чего не делают остальные компиляторы - поскольку линейка кэша сегмента кода достигает 32-х байт, то метки начала циклов должны быть выровнены по границе 16 байт. На каждый байт, выходящий за пределы кэша, процессор семейства P2 тратит 9-12 тактов.
Сравнение времени компиляции и размера выполняемого файла
Для выполнения этого теста использовался все тот же исходный код, из которого были удалены все compiler-specific тесты. Тестирование выполнялось отдельно для компиляции релиза и для отладочной версии, размер бинарного файла указан только для релиза (см. табл. 4). Чтобы исключить влияние файлового кэша, проводились две одинаковые компиляции подряд - время измерялось по второй с помощью команды "date" (исключение составил только Builder - он сам измеряет время компиляции).

Первое место поделили Borland Builder и MSVC++, а вот gcc - опять на последнем месте, как по скорости компиляции, так и по размеру бинарного файла. Интересным моментом является тот факт, что время компиляции отладочной версии у gcc и Builder'а выше времени компиляции релиза. Объясняется это тем, что при компиляции отладочной версии компилятору необходимо добавить отладочную информацию, что существенно увеличивает размер объектного файла - и, как следствие, время работы линковщика.
Результаты
Казалось бы, вывод о самом эффективном компиляторе напрашивается сам собой - это Borland Builder C++. Но не стоит спешить. Многие разработчики указывают на ошибки при формировании кода у Borland Builder (в частности, при использовании ссылок его поведение становится непредсказуемым). Кроме того, Borland Builder C++ явно наследует многое от Delphi (один модификатор вызова метода DYNAMIC чего стоит), в результате чего при компилировании абсолютно правильного С++ кода могут возникать ошибки (например, отсутствие множественного наследования для VCL-классов; а все потомки от TObject являются VCL-классами).
С другой стороны, самым стабильным и "вылизанным" компилятором можно назвать gcc. Но скорость выполнения откомпилированного кода на нем будет не слишком высокой. Причиной тому, вероятно, существование gcc на многих платформах и, как следствие, необходимость компилирования под эти платформы.
MSVC++ или Intel Compiler не имеют явно выраженных недостатков, так что их позиции примерно равны.
В общем, однозначно ответить, "какой компилятор наилучший", невозможно. Но пусть результаты данных тестов помогут вам сделать "правильный" выбор.