
Моделирование данных является важнейшим процессом при проектировании программного обеспечения (ПО). По этой причине, разработчики CASE-средств в своих продуктах вынуждены уделять моделированию данных повышенное внимание. Являясь признанным лидером в области объектных методологий, фирма Rational Software Corporation, тем не менее, до недавнего времени такого средства не имела. Основной причиной этого, по-видимому, является ориентация на язык Unified Modeling Language (UML), как универсальный инструмент моделирования. UML полностью покрывает потребности моделирования данных. Сложившаяся на протяжении десятилетий технология моделирования данных, традиции, система понятий и колоссальный опыт разработчиков не могли далее игнорироваться. Немаловажную роль здесь сыграла и необходимость формального контроля моделей данных, что является абсолютно необходимым при проектировании мало-мальски больших схем баз данных и что UML не обеспечивает в достаточной степени. И, наконец, последней причиной, побудившей специалистов Rational Software Corporation к созданию собственного средства моделирования данных, является требование построения эффективных физических моделей, прежде всего для конкретных СУБД - лидеров рынка.
В начале 2000 года фирма Rational Software Corpоration анонсировала появление собственного средства моделирования данных - Data Modeler, и в настоящее время оно доступно специалистам, например, использующим в своей работе Rational Rose 2000e.
Целью данной статьи является знакомство специалистов с основными возможностями этого нового средства и сравнение их с аналогичными функциями структурных CASE-средств. Сразу стоит отметить, что модуль Data Modeler произвел на нас положительное впечатление.
Авторы Data Modeler прежде всего ориентировались на создание инструмента проектирования физической модели данных. При этом не произошло отказа от UML как от средства моделирования данных, а некоторым образом были смещены акценты: теперь UML предполагается использовать для построения логической модели. По сути, логическая модель - это та же объектная модель, состоящая из объектов - сущностей. Переход от логической модели к физической и наоборот в части моделирования данных обеспечивается Rational Rose автоматически. Для этого введено соответствие элементов моделей.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Заметим, что для специфических элементов физической модели - триггеров и индексов - не нашлось достойного аналога UML, но в общем-то это не проблема.
Таким образом, концептуально модуль Data Modeler не является заменой UML в некотором его подмножестве (как же можно покуситься на святое!), а всего лишь дает приверженцам объектных технологий мощное средство эффективного построения физических схем БД. С этой точки зрения он нас и будет в дальнейшем интересовать.
При создании нового модуля специалисты Rational Software Corporation пошли по традиционной схеме расширения функциональных возможностей Rational Rose, а именно, создали подключаемый компонент (AddIns). После установки Rational Rose в специальной редакции (Rational Rose Professional Data Modeler Edition) в разделе главного меню Tools появляется новый раздел Data Modeler.
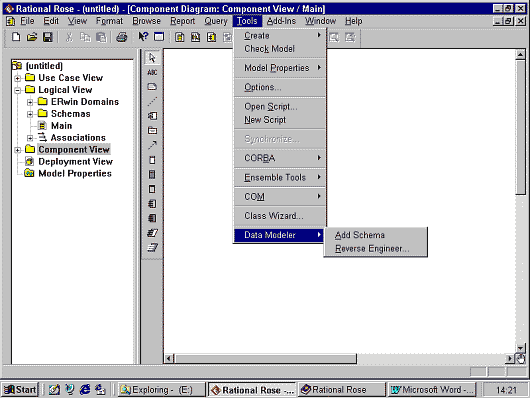 |
В разделе Data Modeler имеются два пункта: "Add Schema" и "Reverse Engeneer…". Пункт "Add Schema" используется для создания новых схем БД, а пункт "Reverse Engeneer" - для построения модели на основе существующей схемы БД.
Для того чтобы познакомиться с возможностями Data Modeler, мы воспользовались пунктом "Reverse Engeneer" и импортировали в Rational Rose реальную схему БД (180 таблиц в Oracle 8). Эта схема БД была создана с использованием CASE-средства ERWin. При ее проектировании применялось большинство основных приемов, используемых при моделировании данных в структурных CASE-средствах. Утилита импорта схемы БД организована удобно в виде мастера (Wizard). Для импорта нам потребовалось всего лишь указать данные для соединения с БД, все остальное система сделала за нас автоматически.
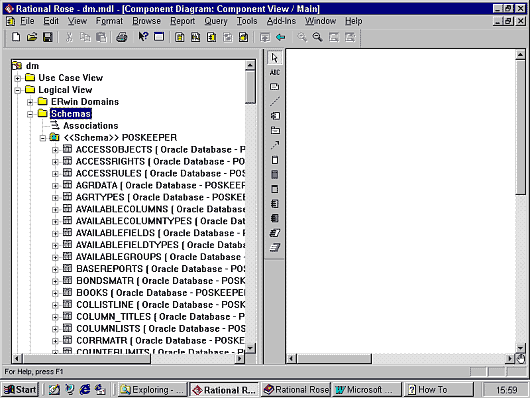 |
В разделе "Logical View" дерева проекта образовался пункт "Schemas" со схемой "Poskeeper" и набором таблиц.
В контекстном меню схемы имеется возможность создать новую для Rational Rose диаграмму - Data Model. Для демонстрации основных приемов работы Data Modeler мы создали такую диаграмму и перенесли в нее несколько таблиц, в результате получили следующее.
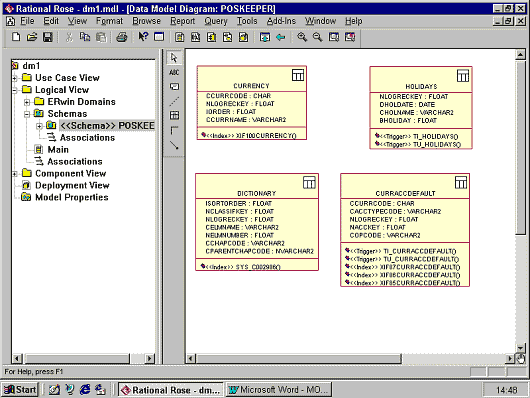 |
То, что получилось, очень напоминает представление схемы в традиционном CASE-средстве.
Однако, существенно, что были импортированы триггеры и индексы (они попали в поле, где обычно при визуальном представлении класса показываются операции).
Диаграмма Data Model предоставляет следующие возможности:
- создание и редактирование таблиц и их элементов (колонок, ограничений, индексов, триггеров и т. п.);
- создание и редактирование идентифицирующих связей между таблицами;
- создание и редактирование не идентифицирующих связей.
Основные возможности по работе с таблицей доступны, если войти в контекстном меню в пункт "Open Specification". Появляющееся на экране окно включает следующую информацию.
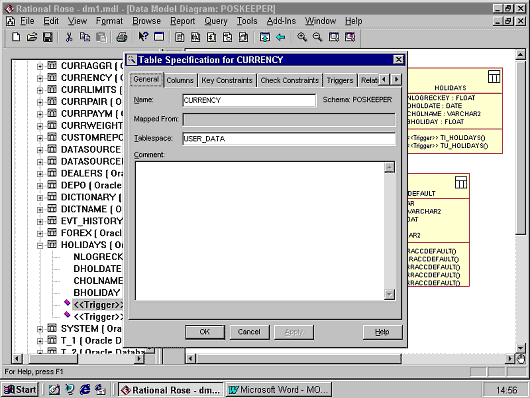 |
При редактировании спецификации таблицы обеспечиваются следующие возможности.
|
|
|
|
|
|
|
|
Задается описание колонок. Здесь можно добавить или отредактировать свойства колонок, задать тип, длину, обязательность (NULL, NOT NULL), а также пометить, что колонка входит в состав первичного ключа. Типы колонок соответствуют типам конкретной выбранной СУБД. |
|
|
Задаются ограничения на колонки таблицы. Здесь можно задать ограничение на уникальность первичного ключа, ограничение на уникальность альтернативных ключей, а также просто определить индекс. |
|
|
Задаются выражения - инварианты, которые должны выполнятся для всех строк таблицы. |
|
|
Содержит список триггеров, который можно отредактировать, в том числе добавив новый триггер. |
|
|
При наличии связей между таблицами, закладка содержит полный список связей. |
Содержащиеся в спецификации возможности, на наш взгляд, представляют практически полный набор действий с таблицей, необходимых для построения физической модели. В нашей импортированной модели мы ограничились лишь добавлением первичных ключей. После чего первичные ключи на экране отобразились красным флажком "PK".
В любой схеме БД важнейшую роль играют связи между таблицами. Мы внесли на диаграмму Data Model недостающие связи. При этом у нас получилось следующее.
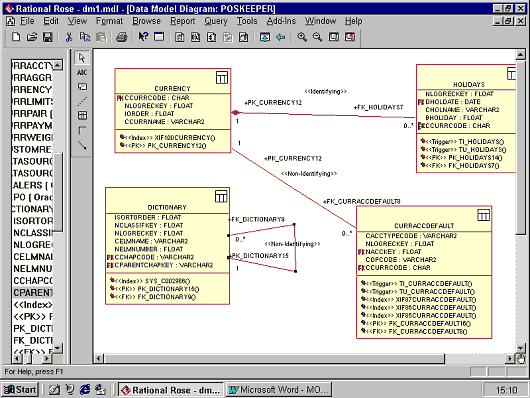 |
Между таблицами CURRENCY и HOLIDAYS существует идентифицирующая связь. Обратите внимание, что на картинке для ее представления использована нотация UML для ассоциации типа "композиция"), между таблицами CURRENCY и CURRACCDEFAULT - не идентифицирующая, а для таблицы DICTIONARY определена рекурсивная связь. Концы связей помечены кардинальностью (1, 0..*), а также именем роли.
В соответствующих таблицах образовались внешние ключи (поля, помеченные красным флажком "FK"). Там, где внешний ключ вошел в состав первичного ключа (идентифицирующая связь), поле помечено двумя флажками "PK", "FK".
Для редактирования свойств связи требуется войти в пункт контекстного меню "Open specification".
Появившееся на экране окно имеет следующий вид.
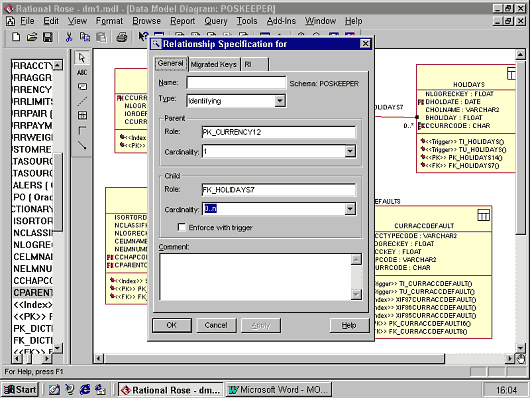 |
При редактировании спецификации связи обеспечиваются следующие возможности.
|
|
|
|
|
Основные свойства связи. Здесь задаются: имя связи; тип связи; наименования ролей (Parent, Child); кардинальность для каждой роли; |
|
|
Содержит список внешних ключей, образующихся в результате создания связи. |
|
|
Задание условий ссылочной целостности. Ссылочная целостность обеспечивается двумя способами: на основе триггеров; на основе декларативной ссылочной целостности (с использованием ограничений внешних ключей). Оба способа реализуют наиболее популярные алгоритмы, задаваемые для каждой роли (только для операций update и delete, для insert мы не нашли): Restrict; Cascade; Set Null; Set Default. |
Приведенные в табл. 3 возможности вполне покрывают потребности моделирования данных, связанные с определением связи.
Следующей необходимой функцией, имеющейся в любом CASE-средстве, является функция генерации физической схемы БД (Froward Engineering). В Data Modeler она присутствует и вызывается из контекстного меню подсхемы. Мы выполнили генерацию схемы, представленной на рис. 5.
При генерации схемы нас, прежде всего, интересовала правильность генерации условий ссылочной целостности. С удовольствием отметим, что Data Modeler великолепно справился с этой задачей в обоих случаях (декларативной ссылочной целостности и ссылочной целостности, отслеживаемой триггерами). В результате генерации схемы мы получаем скрипт, который тут же можем и исполнить. Особо отметим, что Data Modeler обеспечивает генерацию схемы БД для нескольких популярных СУБД: Oracle, MS SQL, DB-2 и др., а также в соответствии со стандартом ANSI SQL 92.
В течение жизненного цикла разработки ПО схема БД не является неизменной. По этой причине желательно иметь в CASE-средстве функцию сравнения существующей БД и модели, а также и функцию синхронизации БД и модели. Функция синхронизации в существующей версии Data Modeler пока отсутствует, а вот функцию сравнения нам удалось опробовать. Мы сравнили модель на рис. 5 со скриптом, полученным в результате генерации схемы. Результат был неожиданным: вместо отсутствия различий мы получили довольно внушительный их список. Основной вывод - функцией сравнения пока пользоваться не следует.
И, наконец, последняя функция, на которую мы бы хотели обратить внимание - генерация объектной модели на основе физической модели данных (без реализации этой функции Data Modeler вряд ли увидел бы свет).
Для схемы Poskeeper мы выполнили генерацию объектной модели. При этом Data Modeler автоматически сопоставил каждой таблице объект, а каждой связи ассоциацию. Все вновь созданные объекты были помещены в новый пакет. Названия объектов и ассоциаций состоят из префикса "OM_", далее следует название таблицы или ассоциации, из которой он образован. Объекты, соответствующие таблицам на рис. 5, мы вынесли на отдельную диаграмму классов. Вот что у нас получилось.
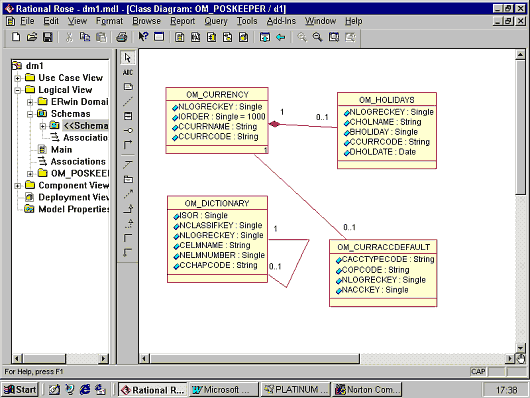 |
Последний вопрос, который нас интересовал, - согласование объектной модели и модели данных. Для проверки данного свойства мы изменили название одного из атрибутов класса. Увы, это изменение не отразилось в модели данных. Вполне возможно, что такое решение принято сознательно (в силу определенных алгоритмических сложностей), но на наш взгляд наличие функции автоматического согласования было бы не лишним. Однако способ согласования моделей все-таки существует. После того как мы внесли изменение в модель данных и выполнили повторную генерацию объектной модели, изменения, внесенные в таблицы, отразились в соответствующих объектах.
Подводя итог нашего краткого обсуждения возможностей Data Modeler, отметим следующее:
- Data Modeler поддерживает большинство возможностей структурных CASE-средств в плане физического моделирования данных;
- Data Modeler обеспечивает генерацию эффективной физической структуры БД, поддерживающей механизмы обеспечения ссылочной целостности;
- Data Modeler тесно интегрирован с Rational Rose, а диаграмма Data Model естественным образом вписывается в общую технологию разработки ПО с использованием линейки продуктов фирмы Rational Software Corporation;
- Можно отказаться от интеграции Rational Rose с другими средствами генерации физических моделей.
- Обеспечивается концептуальное соответствие моделирования данных и объектных моделей, что позволяет более эффективно проектировать программные средства.