
Оглавление
- Введение
- Начало работы
- Первый принцип анализа и мониторинга производительности
- Поуровневый подход к изучению
- Итерация, итерация, итерация
- Где смотреть
- Хост VOB
- View-хосты
- Клиент
- Совместно используемые сетевые ресурсы
- При оптимизации времени выполнения не забывайте о латентности
- Пример применения
- Уровень 1: Операционная система / аппаратная среда
- Уровень 2: Настраиваемые параметры Rational ClearCase
- Уровень 3: Пространство приложения
- Что? Где? Когда?
- Примечания
Введение
Сколько раз за день ваша группа разработчиков подтверждает взятие на редактирование и регистрирует сдачу на контроль артефактов базы версий объектов (VOB) из вашего экземпляра IBM Rational ClearCase? Как много сборок продукта они выполняют? Если вы задумались над вопросом, сколько действий с Rational ClearCase выполняет ваша группа разработчиков за жизненный цикл проекта, то легко поймете, что даже небольшое увеличение скорости этих операций поможет значительно сэкономить время.
За прошедшие восемь лет я работал с группами разного состава и местоположения, помогая им более действенно и рационально использовать Rational ClearCase для управления конфигураций ПО (SCM). Я думаю, справедливо будет сказать, что все они будут благодарны за любую помощь, которая позволит им выполнить большее количество работы за день, и, конечно же, быстрее закончить сами проекты. Кем бы вы ни были - администратором Rational ClearCase, решающим проблемы производительности, или же вы всего лишь оцениваете возможности повышения производительности для улучшения эффективности труда группы разработчиков - всегда полезно иметь план.
Эта статья, являющаяся Частью I из серии описания принципов и техник по улучшению производительности IBM Rational ClearCase, предоставляет обзор принципов оценки производительности, а также советы, как применить эти оценки в среде Rational ClearCase. Здесь представлен подход, хорошо себя зарекомендовавший при диагностике проблем производительности и нахождении подходящего решения, и использован практический пример для иллюстрации описанного подхода.
В Части II этой серии будут обсуждаться приемы использования определенных инструментов и практик для анализа и улучшения производительности IBM Rational ClearCase в вашей организации.
Начало работы
Когда я рассматриваю проблему производительности, то начинаю со сбора общей информации. Я пробую идентифицировать характеристики проблемы, и определить, каким образом проблема может себя проявить. Проблемы производительности могут быть отнесены к двум обширным категориям:
- Проблемы, которые внезапно становятся серьезными.
- Проблемы, когда ситуация со временем постепенно ухудшается.
Внезапное торможение системы обычно проще диагностировать и исправить, так как подобные эффекты обычно связаны с недавними изменениями в рабочем окружении IBM Rational ClearCase. Проблемы производительности, проявляющиеся за длительный интервал времени - иногда за год или более - распознать значительно сложнее.
Во многих случаях вопросы, которые следует задать для диагностики проблем производительности, похожи на те, которые решаются при отладке приложения. Они подобны вопросам, которые врач может задать пациенту для обнаружения источника боли. Является ли проблема повторяющейся или кратковременной? Является ли она периодической? Происходит ли она в определенное время дня? Ассоциирована ли она с определенной командой или действием? Например, при работе с IBM Rational ClearCase, возникает ли проблема только тогда, когда сборка выполняется с использованием clearmake или некоторых других средств? И также как и в случае с программными ошибками, легче все работать с проблемами производительности, которые можно легко воспроизвести, например, связанными с определенными командами. Периодически возникающие проблемы по своей природе значительно более сложны.
По мере того, как у вас появится лучшее понимание, какие именно эффекты вызывает проблема, вы можете начать более глубокое изучение того, что именно происходит в различных системах, находящихся в ведении IBM Rational ClearCase.
Первый принцип анализа и мониторинга производительности
Системы представляют собой свободную иерархию независимых ресурсов2:
- Память
- Процессоры
- Дисковые контроллеры
- Диски
- Сети
- Операционная система
- База данных (в этом случае IBM Rational ClearCase)
- Приложения
- Сетевые ресурсы (например, контроллеры доменов, и т.д.)
Первый принцип анализа производительности заключается в том, что в большинстве случаев низкая производительность вызвана нехваткой одного или нескольких подобных ресурсов. При анализе использования этих ресурсов в среде IBM Rational ClearCase, прежде всего я обращаю внимание на явные патологические симптомы и конфигурации - то есть на вещи, которые просто несовместимы друг с другом. В качестве примера приведу недавно проведенный анализ проблем производительности, возникших у заказчика. При быстром просмотре процессов, выполняемых на хосте, было обнаружено выполнение 192 процессов Oracle, в дополнение к задачам Rational ClearCase. Вне зависимости от того, в действительности ли это вызвало проблемы производительности, сразу стало понятна необходимость оценки возможностей компьютера для поддержки такого количества интенсивно использующих память процессов.
Фактически подобная ситуация приводит нас к другому принципу анализа производительности: будьте осторожнее с выводами. Часто одна явная проблема будет маскировать менее очевидную, причем последняя и будет явной причиной снижения производительности. Кроме того, будьте осторожны и не позволяйте кому-нибудь подталкивать вас к заключению, например, в случае, если кто-то уже имеет идею о том, что же именно вызвало проблему. Важно отдавать себе отчет, что эта идея представляет собой всего лишь догадку и может не быть реальной причиной проблемы.
При анализе производительности я часто вспоминаю слова известного физика Ричарда Фейнмана: "Первый принцип состоит в том, что вы не должны одурачить самого себя, и среди кандидатов на одурачивание вы являетесь наиболее доступным". Особенно важно помнить о главной ловушке - вере в то, что именно первая обнаруженная причина и является главной проблемой.
Поуровневый подход к изучению
Изучение проблемы производительности IBM Rational ClearCase может быть достаточно сложной задачей. Я обнаружил, что большую помощь приносит разбиение проблемы на три уровня, которые составляют "стек производительности", как показано на рисунке 1. На самом нижнем уровне находятся операционная система и аппаратное обеспечение, такое как память, процессоры и диски. Выше этого располагаются настраиваемые параметры IBM Rational ClearCase, такие как размер кэша. И на самом верхнем уровне расположены приложения. В Rational ClearCase, пространство приложений включает скрипты, выполняемые при операциях Rational ClearCase, и триггеры Rational ClearCase, автоматически выполняемые до или после операции Rational ClearCase.
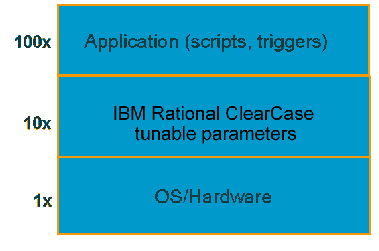
Рисунок 1: стек производительности IBM Rational ClearCase
Исходя из моего опыта - и исключая явно патологические ситуации - по мере перемещения вверх по уровням стека производительности, вы можете ожидать десятикратного увеличения вызванного вашими усилиями роста производительности. Потратив неделю на настройку и отшлифовку параметров ядра операционной системы, вы сможете добиться некоторого увеличения производительности. Но если вы потратите некоторое время на настройку параметров кэша IBM Rational ClearCase, то получите десятикратное увеличение производительности, по сравнению с тем, чего вы добились, настраивая ядро. При работе с еще более высокоуровневым звеном, и внесении улучшений на уровне приложений, ваш выигрыш в производительности будет примерно на два порядка больше, чем достигнутый при работе с низким уровнем. Если вы сможете оптимизировать скрипты и триггеры, или же вообще устранить их, то эффект будет весьма значителен. В Части II этой серии будет более подробно показано, как оптимизировать прикладной уровень для повышения производительности.
Учитывая вышесказанное, вы можете решить, что неплохо было бы начать с прикладного уровня. Но по принципиальным соображениям при выполнении анализа производительности я всегда начинаю работу с нижнего звена стека. Анализ начинается с уровня аппаратных средств и операционной системы, и затем выясняется, нет ли патологических ситуаций. Затем я перехожу к настраиваемым параметрам базы данных, а прикладной уровень рассматриваю в последнюю очередь. Подобный порядок изучения обусловлен целым рядом причин. Прежде всего, в действительности наиболее просто посмотреть на аппаратные средства и операционную систему, чтобы посмотреть, не происходит ли там что-нибудь необычного. Имеются достаточно общие инструменты, простые и довольно быстрые в работе, и любые нестандартные ситуации не скроются от вашего внимания - например, такие, как 192 процесса Oracle. Сходным образом, на более верхнем уровне, IBM Rational ClearCase предоставляет утилиты, которые покажут вам частоту обращений к кэшу и позволят вам настроить кэш. Эти утилиты также очень просты в использовании.
И последним я изучаю прикладной уровень, так как это сопряжено со многими трудностями. Этот уровень технически более сложен, так как он состоит из многих взаимосвязанных компонентов. Кроме того, это может быть значительно более сложно с политической точки зрения, так как скрипты и триггеры обычно имеют своих владельцев, создавших их по некоторой причине и чьи подходы к решению вопросов могут не совпадать с вашими. Некоторые становятся в оборонительную позицию даже при намеке на то, что они могли что-либо сделать неправильно. Но зачастую нет ничего "неправильного"; просто дело в том, что по самой своей природе скрипт сделан медленным.
Другой причиной начала работы на самом нижнем уровне является простая осмотрительность. Вам следует убедиться в правильности выполнения системой основных операций. Хотя я начинаю именно с этого места, совсем необязательно тратить здесь много времени - вы не получите достаточно серьезного результата от ваших усилий. Также я не буду тратить много времени на настраиваемые параметры IBM Rational ClearCase. Обычно проверка работы кэшей проходит довольно быстро, и после настройки параметров можно двигаться дальше.
Если бы вы начали с верхнего уровня, то могли бы потратить месяц на настройку триггеров и скриптов, и никогда не добраться до факта, что системе не хватает памяти. Если система исчерпывает всю имеющуюся память, тогда это проблема номер один. Следует добавить еще - это достаточно быстро и просто исправить. Прежде всего, закончив изучение двух нижних уровней, вы получите время для того, чтобы заняться прикладным уровнем. Если у вас есть достаточно времени для проведения оптимизации - или даже устранения - прикладного уровня, то именно таким образом вы получите наибольший эффект улучшения производительности.
Итерация, итерация, итерация
Настройка производительности является итеративным процессом:
- Выбор инструмента и измерение.
- Просмотр данных. Определение того, где же именно появилось текущее узкое место.
- Исправление проблемы.
- Повторение.
Вы можете бесконечно следовать этому циклу, но со временем вы придете к точке сокращения возвращений. После того, как вы обнаружите, что занимаетесь настройкой ядра или просмотром эзотерических параметров реестра из базы знаний Microsoft, то возможно, что сейчас вы находитесь в подходящем месте для того, что остановиться, так как вероятнее всего вы не получите большой отдачи от затраченного вами времени.
По мере выполнения вами итераций, не забывайте об иерархической природе процедуры настройки производительности. Помните о том, что память является основой всего. Симптомы, вызванные нехваткой памяти, включают перегрузку диск, процессора или сети. Например, когда система не имеет достаточного количества памяти, она начинает часто сбрасывать страницы данных на диск. После того, как это началось, процессор оказывается перегруженным, так как он вынужден контролировать подобный процесс, а диск оказывается непрерывно работающим для запоминания и извлечения всех этих страниц памяти. Увеличение мощности процессора или применение более быстрых дисков может принести небольшую помощь, но при этом не будет учтена сама первопричина данной проблемы. Прежде всего, проверьте и устраните нехватку памяти, и только затем приступайте к изучению остальных причин.
Где смотреть
IBM Rational ClearCase является распределенным приложением. В его работу вовлечены множество хостовых компьютеров, а также некоторые общие сетевые ресурсы. Для решения проблем производительности я предпочитаю воспринимать Rational ClearCase как треугольник, чьими углами являются VOB-хосты (машины, выполняющие процесс vob_server), хосты просмотра (машины, выполняющие процесс view_server), и клиент (см. рисунок 2). При проведении анализа производительности я проверяю каждый угол треугольника. Проверяю стек производительности для каждого из этих хостов для уверенности, что каждый обладает достаточным количеством памяти и других низкоуровневых ресурсов, и ищу аномальные ситуации.
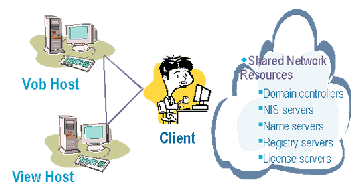
Рисунок 2: Среда IBM Rational ClearCase
Хост VOB
В среде IBM Rational ClearCase постоянный репозитарий программных артефактов содержит один или большее количество объектов VOB, располагающихся на одном или более объектах VOB.
VOB-серверы особенно чувствительны к объему оперативной памяти, так как производительность улучшается при кэшировании баз данных VOB. Используя больший объем памяти, VOB-сервер может хранить большую часть базы в оперативной памяти. Как результат, при этом потребуется реже запрашивать данные с жесткого диска, избегая таким образом процесса, который в тысячи раз медленнее, чем доступ к памяти. Для VOB-хоста, Руководство пользователя BM Rational ClearCase рекомендует минимальный объем оперативной памяти 128 MБайт, или же половину размера баз данных VOB, которые хост будет поддерживать. Обратите внимание на совет из Руководства администратора: "Достаточный объем физической памяти является наиболее важным фактором для производительности VOB; увеличение размера основной оперативной памяти хостов VOB является наиболее простым (и наиболее экономичным) способом, чтобы ускорить доступ к VOB и увеличить количество параллельно работающих пользователей без снижения производительности системы".
Обычно у VOB-хоста IBM Rational ClearCase имеется не так много настраиваемых параметров. Существуют установки, которые вы можете использовать для контроля за количеством серверных процессов, но они редко бывают нужны. Существуют другие параметры блокировки (lockmgr), которые можно изменить при обнаружении ошибок в log-файле Rational ClearCase. В подобном случае обратитесь к документации Rational ClearCase или в службу технической поддержки IBM Rational, специалисты которой постараются дать подробные указания, что именно вам следует делать.
View-хосты
View-сервер управляет задачей конкретного представления Rational ClearCase. На практике view-сервер не должен быть запущен на том же самом физическом компьютере, что и VOB-сервер. В некоторых случаях view-сервер и клиент могут работать на одной и той же машине, что определяется конфигурацией.
Как и в случае VOB-хоста, первые области для проверки остаются фундаментальными - память, другие запущенные процессы, и т.д. Но вместе с тем view-сервер имеет большее количество параметров Rational ClearCase, которые могут быть скорректированы. Представления имеют ассоциированные с ними кэши, и для увеличения производительности вы можете увеличить размер этих кэшей.
Клиент
Я был в некоторых офисах заказчиков, у которых прекрасно работали как VOB-хост, так и view-хост, но клиентские машины при работе испытывали острый недостаток памяти. Пользователи жаловались на проблемы при сборке, так как компилятор, который они использовали, расходовал все доступные ресурсы на машине клиента. Поэтому если ваши операции взятия на редактирование и сдачи на контроль не вызывают никаких проблем, но при этом процессы сборки идут медленно, то неплохо было бы проверить клиентские машины. С VOB-хостом наблюдается другая ситуация, потому что сборки, особенно сборки с использованием clearmake, нагружают VOB-сервер на более длительные периоды времени, чем операции взятия на редактирование и сдачи на контроль. Как обычно, прежде всего проверьте операционную систему и аппаратный уровень. Кроме того, если пользователь работает с динамическими представлениями, клиентская машина будет иметь кэш под управлением MVFS (файловая система с поддержкой множественных версий), который можно увеличить для улучшения производительности.3
О том, как проверять ресурсы и настраивать IBM Rational ClearCase, будет рассказано более подробно во второй части этой серии.
Совместно используемые сетевые ресурсы
На рисунке 2 показано облако совместно используемых сетевых ресурсов, которые также очень важны для производительности IBM Rational ClearCase. Подобные ресурсы включают контроллеры домена, серверы NIS, серверы доменных имен, серверы реестров и серверы лицензий. Перед тем, как разрешить любые операции, Rational ClearCase должна зарегистрировать пользователей. Если подключение к распределенным ресурсам, требующимся для этой регистрации, является медленным, то соответственно и аутентификация пользователей Rational ClearCase будет медленной. Сервер реестра и сервер лицензий требуют мало ресурсов и часто выполняются на VOB-хосте, поэтому скорость сетевого соединения с этими ресурсами обычно не является проблемой.
При оптимизации времени выполнения не забывайте о латентности
Углы треугольника на рисунке 2 также очень важны. Они представляют сетевые соединения между VOB-хостами, view-хостами и клиентом. В среде IBM Rational ClearCase, не все метрики сетевой производительности созданы равными. Латентность сети - время, требующееся от данных для прибытия к месту своего назначения - имеет значительно большее влияние на производительность Rational ClearCase, чем пропускная способность сети, являющаяся количеством данных, которые могут быть переданы через сеть в заданный диапазон времени. Это обусловлено тем, что в большинстве случаев Rational ClearCase не перебрасывает по сети большого количества файлов. Вместо этого производится большое количество удаленных вызовов процедур, или RPC.
Говоря упрощенно, RPC является определенным типом сообщения, которое работает как вызов подпрограммы между двумя процессами, который может выполняться на различных машинах. Когда клиентский процесс вызывает подпрограмму на сервере, данные RPC, включая аргументы для подпрограммы, пересылаются через низкоуровневый протокол, такой как TCP или UDP. Сервер получает RPC, выполняет соответствующий код, и отсылает ответ клиенту. Затем клиент получает ответ от сервера и продолжает обработку. RPC являются синхронными; это означает, что клиент не продолжает обработку до тех пор, пока не получит ответ. Важно отметить, что здесь имеется вызов и возврат - каждая RPC является улицей с двусторонним движением. Если для RPC необходимо 10 мс (миллисекунд) для пересылки данных от клиента на сервер, то общее время прохождения RPC будет равно 20 мс, плюс время обработки.
В типичной транзакции IBM Rational ClearCase, или MVFS или клиент будут посылать RPC на view-сервер. View-сервер, в свою очередь, вызывает RPC на VOB-сервере. Ответ должен прибыть сначала на view-сервер, и затем второй ответ отсылается обратно клиенту.
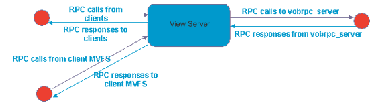
Рисунок 3: Вызовы удаленных процедур в типичной транзакции IBM Rational ClearCase
Каждый процесс имеет два уровня RPC, каждый с вызовом и ответом. Если латентность вашей сети составляет 10 мс между каждой машиной, то эта конкретная транзакция будет требовать 40 мс. Хотя это и не выглядит большой потерей времени, суммирование подобных задержек быстро приводит к значительному замедлению. Операция взятия на редактирование может содержать более чем 200 RPC, например, таких как регистрация пользователя в IBM Rational ClearCase, обнаружение VOB, обнаружение представления и т.д. Поэтому в подобном случае, даже с относительно небольшой латентностью в 10 мс, на выполнение всей операции Rational ClearCase затратит более чем секунду на ожидание, пока данные пройдут по сети.
Латентность увеличивается с появлением каждого звена - или роутера - через который должны пройти данные от своего источника к месту назначения. Каждый роутер должен обработать пакет для определения места его предназначения, и эта обработка занимает время. Поэтому, чем меньше звеньев в сети, тем лучше. Помните о том, что при настройке производительности Rational ClearCase особое значение имеет латентность, а не пропускная способность сети. У вас может быть сеть с гигабитной пропускной способностью, но если вызов RPC проходит через дюжину роутеров, то вы заплатите за это серьезной потерей производительности.
В части II этой статьи будет более подробно обсуждено, как оценить латентность сети и как решать другие проблемы с сетью.
Пример применения
Для иллюстрации только что обсужденных некоторых принципов анализа производительности и настройки IBM Rational ClearCase давайте рассмотрим случай из реальной практики. Я работал с заказчиком, который около года использовал Rational ClearCase. Они внедрили свой собственный процесс, который включал дополнительное отслеживание и авторизацию - они не использовали UCM (Unified Change Management - унифицированное управление изменениями4). Все VOB были расположены на одном сервере Solaris, в котором были установлены четыре процессора и 4 ГБайт оперативной памяти. View-сервер - который они также использовали для выполнения сборок - был на отдельной, но совершенно такой же машине. Даже работая с этими мощными компьютерами, заказчик жаловался на низкую производительность при выполнении операций взятия на редактирование и сдачи на контроль.
Уровень 1: Операционная система / аппаратная среда
Когда мы разговаривали с системными администраторами, они были убеждены, что VOB и view-серверы работали просто прекрасно. Они верили, что проблема состояла именно в IBM Rational ClearCase. Поэтому мы начали изучение со стека производительности, двигаясь с самого низа вверх. Мы провели наш первоначальный анализ с нижнего звена, отыскивая патологические случаи - такие как необычные конфигурации или странные процессы, выполняемые на машинах, - так же как и стандартной вариации метрик ресурсов - памяти, процессора, диска, и так далее. Мы обнаружили, что VOB-хост работал отлично, но со view-хостом были проблемы.
Выяснилось, что был клиент, выполнявший 192 процесса Oracle на view-хосте! Эти процессы потребляли 12 ГБайт виртуальной памяти в системе, имевшей лишь 4 ГБайт физической памяти. Конечно, некоторое количество памяти, занятой каждым процессом, использовалось в режиме совместного доступа, что уменьшало общее количество используемой памяти до уровня чуть меньшего 12 ГБайт - но, тем не менее, это было значительно больше, чем имела система. В результате наших наблюдений быстро выяснилось, что система исчерпала всю доступную память, а уровень загруженности процессора был очень высок - процессор имел нулевое время ожидания. Центральной проблемой была не мощность процессора, а оперативная память.
Мы рекомендовали, чтобы заказчик удалил процессы Oracle с компьютера, на котором выполнялся view-сервер. После этого, мы рекомендовали нарастить оперативную память, если это все еще было необходимо, и изменить их модель взаимодействия с пользователем, чтобы компиляция не выполнялась на view-хосте. Так как заказчик не отмечал проблем с производительностью до того, как установил Rational ClearCase (вместе с некоторыми скриптами прикладного уровня, которые они разработали), то они не спешили вносить какие-либо изменения, так как все еще подозревали, что именно Rational ClearCase, а не их система, была причиной проблемы.
Уровень 2: Настраиваемые параметры Rational ClearCase
Нашим следующим шагом было перемещение вверх по стеку производительности, и поиск способов настройки Rational ClearCase с целью повышения производительности. Мы определили, что MVFS и view-кэши имели слишком малый размер. Наша вторая рекомендация заключалась в улучшении размера этих кэшей, но вместе с тем мы предупредили заказчика об опасности, присущей этому шагу. Выделение большего размера памяти под кэши может быстрее привести к нехватке памяти, так как мы производим эту установку, игнорируя тот факт, что системе и так не хватает памяти. Мы продвигались вперед, осознавая, что не учитываем проблему с оперативной памятью. Производительность улучшилась, но незначительно.
Уровень 3: Пространство приложения
Нашим следующим шагом было изучение прикладного уровня. Заказчик установил скрипты, с помощью которых осуществлялась поддержка дополнительной аутентификации и регистрации операций взятия на редактирование и сдачи на контроль. Мы поставили эти скрипты на профилирование, с целью выяснения того, где же именно затрачивалось время, и затем периодически на протяжении всего дня выполняли их. Измерения показали, что фактическое время для операций взятия на редактирование и сдачи на контроль Rational ClearCase в среднем составляло 0.5 с, даже в случае, если на view-хосте была полностью исчерпана оперативная память. Остальное же время обработки скриптов составляло 17.4 с. Журналирование и другие функции, выполняемые на прикладном уровне, требовали примерно в тридцать пять раз больше времени, чем функции Rational ClearCase. И это было довольно постоянным отношением. В другое время дня, выполнение функций Rational ClearCase занимало до 0.7 с, но для выполнения скриптов уже требовалось до 25 с. И это было именно тем, на что жаловались сотрудники заказчика.
Мы начали работу с самого низа стека производительности. Занимаясь аппаратным уровнем, вы необязательно получите хороший эффект, но этот уровень нужно проанализировать для выявления патологий. Мы быстро выявили процессы Oracle, обнаружили, что машина также использовалась для компиляции, и определили, что view-хостам серьезно не хватало памяти. На следующем шаге мы изучили настраиваемые параметры IBM Rational ClearCase, и затем отметили ощутимое - но не такое уж большое - улучшение при их корректировке. Настоящий эффект был достигнут при работе c прикладным уровнем. При быстром изучении первых двух уровней у нас было достаточно времени для полного анализа прикладного пространства, и мы обнаружили, что для улучшений производительности в этой сфере существует много возможностей.
Заказчик проанализировал функциональность, которая достигалась с помощью скриптов прикладного уровня, и они обнаружил, что некоторые из этих функций уже имелись в IBM Rational ClearCase. Кроме того, некоторые из созданных ими более сложных функций отслеживания были встроены в Unified Change Management, поэтому они приняли решение внедрить UCM. Это привело к сокращению количества времени, требуемого на выполнение процессов прикладного уровня, поэтому время, необходимое для операций взятия на редактирование и сдачи на контроль значительно уменьшилось - и сотрудники прекратили жаловаться.
Что? Где? Когда?
До настоящего времени я говорил о том, на что нужно смотреть при анализе и настройке производительности IBM Rational ClearCase, и о том, на что именно следует смотреть. В части II рассмотрим, как улучшить производительность Rational ClearCase, используя инструменты и утилиты, которые, возможно, у вас уже имеются.
Примечания
1 Производительность IBM Rational ClearCase, как и всякого другого приложения, зависит от среды, в которой она работает, включая операционную систему, оборудование, и другие программы, выполняющиеся в той же среде. Кроме того, каждая организация имеет свои нормативы и ожидания в отношении производительности. Из-за подобного широкого диапазона потенциальных сред и ожиданий, практически невозможно дать точные указания по достижению приемлемого уровня производительности. Если вам нужна помощь в определении того, является ли производительность Rational ClearCase достаточной для вашей конкретной среды и конфигурации, то возможно, вы захотите обратиться к службе технической поддержки IBM Rational. Кроме того, за рамками данной статьи осталось обсуждение подробных процедур по настройке параметров ядра операционной системы, NFS (сетевой операционной системы), Samba и других низкоуровневых технологий.
2 За прекрасной и подробной дискуссией по этой теме обратитесь к работе Configuration and Capacity Planning for Solaris Servers, Брайан Л. Вонг (Brian L. Wong), (Sun Microsystems Press, 1997).
3 MVFS является функциональностью IBM Rational ClearCase, которая поддерживает динамические представления. Динамические представления используют MVFS для отображения выбранных комбинаций локальных и удаленных файлов в таком виде, как если бы они хранились в собственной файловой системе. MVFS также выполняет аудит целевых объектов clearmake и поддерживает несколько кэшей для максимизации производительности.
4 Unified Change Management представляет собой созданную IBM Rational систему "наилучших практик" для управления изменениями, начиная от требований и заканчивая релизом. Интегрируемая с IBM Rational ClearCase и IBM Rational ClearQuest, UCM определяет последовательный, основанный на выполнении отдельных задач процесс управления изменениями, который непосредственно может применяться группами для работы над проектами разработки ПО.