
Проблемы эффективного использования данных
Корпоративные системы управления предприятием, созданные на основе реляционных СУБД, как правило, эффективно решают задачи учета, контроля и хранения данных. Однако в силу своей специфики, реляционная структура не позволяет решать задачи анализа имеющейся информации с требуемой производительностью. Особенно остро эта проблема стоит в гетерогенных информационных средах, когда в центральном офисе организации и в филиалах эксплуатируются СУБД различных производителей (рис.1).
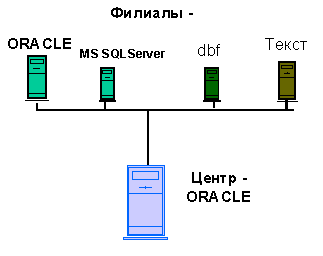
Рис.1. Гетерогенная информационная среда.
Такая ситуация часто возникает либо в результате слияния кoмпаний, когда компания превращается в филиал более крупной, но при этом нерентабельно перестраивать исторически сложившуюся информационную инфраструктуру, либо вследствие неудовлетворительного управления, когда филиалы не придерживаются корпоративного стандарта и внедряют собственные информационные системы. Одной из основных задач, решаемых в корпоративных информационных системах, является предоставление аналитической информации необходимой для принятия решений. Для поддержки принятия решения необходим не один заранее подготовленный отчет, а серия разнообразных отчетов, причем менеджер не всегда представляет, какой именно отчет понадобится ему в следующие полчаса. Например, при анализе продаж по компании оказывается, что в феврале текущего года произошел спад. Чтобы выяснить причины спада, необходимо просмотреть отчет о продажах в регионах. Отчет о продажах в регионах показывает, что спад произошел, видимо, по причине неудовлетворительной работы одного из филиалов, следовательно, необходим отчет о работе данного филиала и т.д. и т.п. Организовать выполнение таких отчетов в гетерогенной среде крайне сложно. Для эффективного анализа данных в этом случае необходимо объединять в одном запросе данные из разнородных источников. В настоящее время существуют мониторы транзакций и генераторы отчетов (например, Crystal Reports), обладающие такой функциональностью, однако производительность таких систем не может быть высокой. В процессе анализа данные, необходимые для принятия решений должны поступать к потребителю в режиме реального времени. Если же данные собираются из разных источников, то, во-первых, отчет готовится недопустимо медленно, во-вторых, другие приложения, работающие с реляционными СУБД во время выполнения отчета скорее всего будут заметно замедляться.
Решением проблемы производительности является создание специализированной базы данных - хранилища данных (Data Warehouse), предназначенной исключительно для обработки и анализа информации (рис.2).
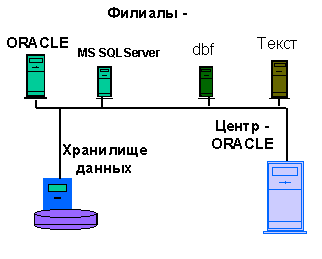
Рис.2. Пример гетерогенной информационной системы, включающей хранилище данных.
Хранилища данных позволяют разгрузить оперативные базы данных, и тем самым, позволяют пользователям более эффективно и быстро извлекать необходимую информацию. Они могут быть включены в общую корпоративную сеть, по которой в хранилище по заранее определенному расписанию, как правило, в период наименьшей загрузки сети и серверов копируется накопленная за день или за неделю информация. Поскольку данные меняются редко, то к хранилищу данных не предъявляются жесткие требования, которые обычно предъявляются к обычным базам данных - отсутствие аномалий при выполнении операций обновления или удаления и избыточности хранения информации. По этой причине может сложиться неверное представление, что проектировать хранилище проще, чем базы данных, предназначенные для оперативной обработки информации. На самом деле, проектирование хранилища данных является весьма сложной задачей.
- Менеджеру, принимающему решения, необходимы самые разнообразные отчеты, причем всякий раз новые. Не всегда возможно выделить специалиста, который бы непрерывно готовил все новые и новые отчеты. Лучший выход - научить создавать отчеты самого менеджера. Существуют разнообразные инструменты (например, упомянутый выше Crystal Reports), интерфейс которых достаточно прост для того, чтобы непрофессионалы в области информационных технологий могли создавать отчеты. Однако в этом случае конечный пользователь непосредственно обращается к структуре данных. Следовательно, структура данных хранилища должна быть понятна пользователям.
- Данные в хранилище должны регулярно пополняться. Требуется тщательно документировать правила пополнения и резервного копирования данных.
- Поскольку отчет будет создавать конечный пользователь, должны быть упрощены требования к запросам с целью исключения тех запросов, которые могли бы требовать множественных утверждений SQL в традиционных реляционных СУБД.
- Обработка запросов к хранилищу должна быть проведена с высокой производительностью, желательно в реальном масштабе времени, поэтому должна быть обеспечена поддержка сложных запросов SQL, которые требуют последовательной обработки тысяч или миллионов записей.
Очевидно, что для решения этой задачи необходимо использовать специальные инструментальные средства. Одним из таких инструментов является Erwin ERX- CASE-средство фирмы Computer Associates International, Inc.
Erwin ERX является незаменимым инструментом для проектирования хранилищ данных по нескольким причинам:
- Хотя реализовать хранилище данных можно на любом сервере БД, существуют специализированные сервера, специально предназначенные для поддержки хранилищ данных. Erwin поддерживает генерацию схемы БД для двух таких серверов - Teradata и Red Brick.
- Как было указано выше, при проектировании хранилища необходимо создавать подробные спецификации для всех источников данных, в том числе самых разных типов. Erwin поддерживает на физическом уровне прямое и обратное проектирование объектов более чем для 21 типа БД, поэтому является идеальным CASE-средством для работы с гетерогенными информационными системами.
- Для эффективного проектирования хранилищ данных ERwin использует размерную (Dimensional) модель. Dimensional - методология проектирования, специально предназначенная для разработки хранилищ данных.
Рассмотрим основные особенности техники моделирования хранилищ данных с помощью Erwin.
Поддержка методологии Dimensional
Нормализация данных в реляционных СУБД приводит к созданию множества связанных между собой таблиц. В результате, выполнение сложных запросов неизбежно приводит к объединению многих таблиц, что существенно увеличивает время отклика. Проектирование хранилища данных подразумевает создание денормализованной структуры данных (допускается избыточность данных и возможность возникновения аномалий при манипулировании данными), ориентированной в первую очередь на высокую производительность при выполнении аналитических запросов. Нормализация делает модель хранилища слишком сложной, затрудняет ее понимание и ухудшает эффективность выполнения запроса.
ERwin поддерживает методологию моделирования хранилищ благодаря использованию специальной нотации для физической модели - Dimensional. Наиболее простой способ перейти к нотации Dimensional в ERwin - при создании новой модели (меню File / New) в диалоге ERwin Teamplate Selection выбрать из списка предлагаемых шаблонов DIMENSION. В шаблоне DIMENSION сделаны все необходимые для поддержки нотации размерного моделирования настройки, которые, впрочем, можно установить вручную.
Моделирование Dimensional сходно с моделированием связей и сущностей для реляционной модели, но отличаются целями. Реляционная модель акцентируется на целостности и эффективности ввода данных. Размерная (Dimensional) модель ориентирована в первую очередь на выполнение сложных запросов к БД.
В размерном моделировании принят стандарт модели, называемый схемой звезда (star schema), которая обеспечивает высокую скорость выполнения запроса посредством денормализации и разделения данных. Невозможно создать универсальную денормализованную структуру данных, обеспечивающую высокую производительность при выполнении любого аналитического запроса. Поэтому схема звезда строится так, чтобы обеспечить наивысшую производительность при выполнении одного самого важного запроса, либо для группы похожих запросов.
Схема звезда обычно содержит одну большую таблицу, называемую таблицей факта ( fact table) , помещенную в центр, и окружающие ее меньшие таблицы, называемые таблицами размерности ( dimensional table) , соединенные c таблицей факта в виде звезды радиальными связями. В этих связях таблицы размерности являются родительскими, таблица факта - дочерней. Схема звезда может иметь также консольные таблицы (outrigger table) , присоединенные к таблице размерности. Консольные таблицы являются родительскими, таблицы размерности - дочерними.
В размерной модели ERwin обозначает иконкой роль таблицы в схеме звезда (рис.3)

Рис. 3. Обозначения таблиц в схеме "звезда".
Прежде чем создать базу данных со схемой типа звезда, необходимо проанализировать бизнес-правила предметной области с целью выяснения центрального вопроса, ответ на который наиболее важен. Все прочие вопросы должны быть объединены вокруг этого основного вопроса и моделирование должно начинаться с него. Данные, необходимые для ответа на этот вопрос, должны быть помещены в центральную таблицу модели - таблицу факта. На рисунке 4 приведен фрагмент учебной модели, входящей в поставку ERwin. Модель представляет собой хранилище данных фирмы, занимающейся продажей видеокассет. Например, необходимо создавать отчеты об общей сумме дохода от продаж за период, или по типу фильмов, или по рынкам фильмов. В таком случае следует разрабатывать модель так, чтобы каждая запись в таблице факта представляла общую сумму продаж, сумму для каждого клиента за определенный период времени и для каждого рынка. В примере таблица факта содержит суммарные данные о продажах ("REVENUE"), а таблицы размерности содержат данные о заказчике и заказах ("CUSTOMER"), продуктах ("MOVIE"), рынках ("MARKET") и периодах времени ("TIME").
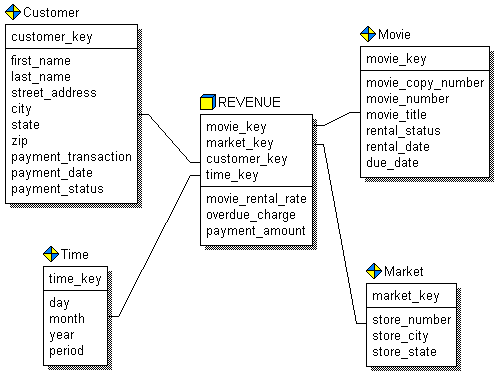
Рис.4. Схема звезда.
Таблица факта является центральной таблицей в схеме звезда. Она может состоять из миллионов строк и содержать суммирующие или фактические данные, которые могут помочь ответить на требуемые вопросы. Она соединяет данные, которые хранились бы во многих таблицах традиционных реляционных базах данных. Таблица факта и таблицы размерности связаны идентифицирующими связями, при этом первичные ключи таблицы размерности мигрируют в таблицу факта в качестве внешних ключей. В размерной модели направления связей явно не показываются - они определяются типом таблиц. Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц размерности. В примере (таблица факта "REVENUE") первичный ключ составлен из четырех внешних ключей: movie_key, market_key, customer_key и time_key.
Таблицы размерности имеют меньшее количество строк, чем таблицы факта и содержат описательную информацию. Эти таблицы позволяют пользователю быстро переходить от таблицы факта к дополнительной информации.
В примере на рис. 4 таблица "REVENUE" - таблица факта; "CUSTOMER", "TIME", "MOVIE" и "MARKET" - таблицы размерности, которые позволяют быстро извлекать информацию о том, кто и когда сделал покупку, какой продавец и на какую сумму продал и какие именно товары были проданы.
ERwin поддерживает использование вторичных таблиц размерности, называемых консольными (outrigger) таблицами, хотя они не требуются для схемы звезда. Консольные таблицы могут быть связаны только таблицами размерности, причем консольная таблица в этой связи родительская, а таблица размерности - дочерняя. Связь может быть идентифицирующей или неидентифицирующей. Консольная таблица не может быть связана таблицей факта. Она используется для нормализации данных в таблицах размерности. Нормализация данных полезна при моделировании реляционной структуры, но она уменьшает эффективность выполнения запросов к хранилищу данных. В размерной модели главной целью является обеспечение высокой эффективности просмотра данных и выполнения сложных запросов. Схема снежинка обычно препятствует эффективности, потому что требует объединения многих таблиц для построения результирующего набора данных, что увеличивает время выполнения запроса. Поэтому при проектировании не следует злоупотреблять созданием множества консольных таблиц. Когда консольные таблицы используются в размерной модели для нормализации каждой таблицы размерности, модель называется снежинка.
В диалоге описания свойств таблицы Table Editor имеется закладка Dimensional, в которой задаются специфические свойства таблицы в размерной модели (рис. 5).
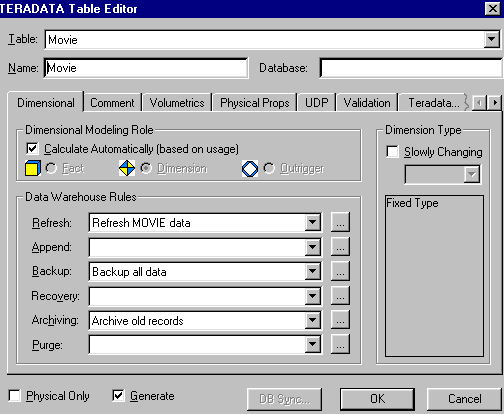
Рис. 5. Закладка Dimensional диалога Table Editor.
Роль таблицы в схеме (Dimensional Modeling Role). По умолчанию Erwin автоматически определяет роль таблицы на основании созданных связей (таблица факта, размерности или консольная). Таблица без связей определяется как таблица размерности, таблица факта не может быть родительской в связи, таблица размерности может быть родительской по отношению к таблице факта, консольная таблица может быть родительской по отношению к таблице размерности. При ручном назначении роли таблицы ERwin автоматически проверяет корректность размерной модели и выдает диалог с предупреждающим сообщением в случае следующих нарушений синтаксиса:
- Таблица факта не является в связи дочерней;
- Консольная таблица не является в связи родительской;
- Установлена идентифицирующая связь между консольной таблицей и таблицей факта.
Тип таблицы размерности (Dimension Type). Каждая таблица размерности может содержать неизменяемые, либо редко изменяемые данные (slowly changing dimensions). Поскольку хранилище данных имеет ненормализованную структуру, редактирование таблиц размерности может привести к коллизиям. Для того, чтобы избежать противоречий при хранении данных, ERwin позволяет задать тип редко изменяемых данных, который отличается способом редактирования данных:
- Перезаписывание старых данных новыми. При этом старые данные теряются.
- Создание новой записи в таблице размерности с новыми данными и временем изменения. В этом случае сохраняются старые данные и можно проследить историю изменения редактируемых данных, но необходимо генерировать ключ для ссылки на старые данные.
- Запись новых данных в дополнительном поле той же самой записи. В этом случае сохраняется первоначальное и последнее новое значение. Все промежуточные данные теряются.
Правила хранения данных (Data Warehouse Rules). Для каждой таблицы можно задать шесть типов правил манипулирования данными: обновление (Refresh), дополнение (Append), резервное копирование (Backup), восстановление (Recovery), архивирование (Archiving) и очистка (Purge). Для задания правила следует выбрать имя правила из соответствующего списка выбора. Каждое правило должно быть предварительно описано в диалоге Data Warehouse Rule Editor (меню Edit / Data Warehouse Rule). Для каждого правила должно быть задано имя, тип, определение. Например, определение правила дополнения данных может включать частоту и время дополнения (ежедневно, в конце рабочего дня), продолжительность операции и т.д. Связать правила с определенной таблицей можно с помощью диалога Table Editor.
Создание спецификаций для источников данных
При проектировании хранилища данных важно определить источник данных (для каждой колонки), метод, которым исходные данные извлекаются, преобразовываются и фильтруются прежде, чем они импортируются в хранилище данных. Хранилище данных может объединять информацию из текстовых файлов и многих баз данных, как реляционных (в том числе других БД на платформе Informix), так и нереляционных в единую систему поддержки принятия решений. Чтобы поддерживать регулярные обновления и проверки качества данных, необходимо знать источник для каждой колонки в хранилище данных. Для документирования информации об источниках данных используется редактор Data Warehouse Source Editor(рис.6.) .
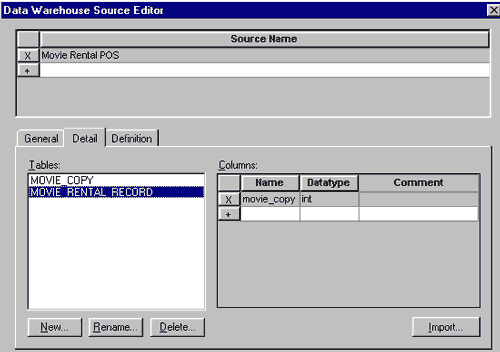
Рис.6. Диалог Data Warehouse Source Editor.
Источник данных может быть описан вручную в диалоге Data Warehouse Source Editor, либо импортирован. В качестве источника при импорте могут быть использованы другие модели Erwin, хранящиеся в файле, SQL - скрипты, модели, хранящиеся в репозитории ModelMart, либо системные каталоги СУБД, на основе которых в результате обратного проектирования могут быть созданы модели Erwin (рис.7).
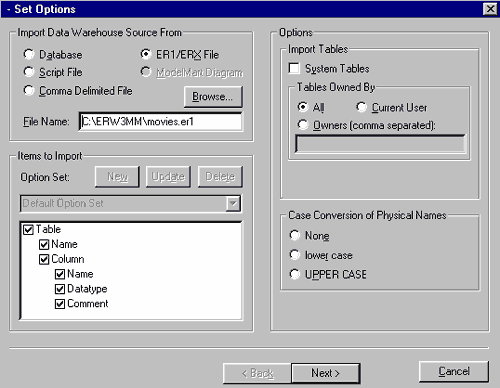
Каждому источнику может быть задано имя и определение.
В редакторе Column Editor можно внести информацию об использовании источников данных для каждой колонки таблиц хранилища данных, а так же дополнительную информацию о способах, режимах и периодичности переноса данных из источника в хранилище данных (рис.8).
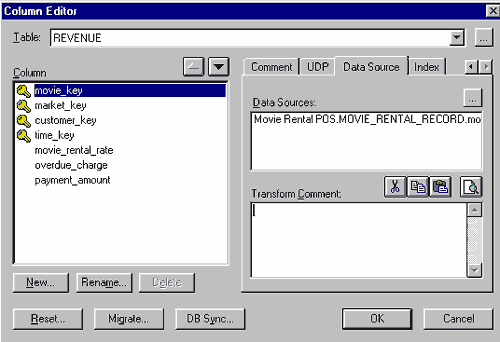
Рис.8. Описание источника данных для колонки хранилища в диалоге Column Editor.
Поддержка специализированных СУБД
Хотя хранилище данных можно создать, используя любую СУБД, существуют специализированные СУБД, позволяющие значительно увеличить производительность обработки данных при использовании схемы "звезда". Erwin поддерживает на физическом уровне две такие СУБД - Red Brick и Teradata. При прямом и обратном проектировании поддерживаются специфические свойства как Red Brick, так и Teradata.
Для Red Brick поддерживаются специфические свойства индексов:
- уникальность (unique);
- распределение по сегментам;
- FILLFACTOR;
- определение типа индекса BTREE (только для версии Red Brick 5.0 и выше), STAR или TARGET (только для версии Red Brick 4.0 и выше) с указанием размера домена;
Редактор Red Brick Physical Object Editor (меню Server / Red Brick Physical Object) позволяет создавать сегменты (Segment) Red Brick и изменять их свойства:
- имя сегмента;
- имя файла сегмента, его максимальный размер, начальный размер (больше 16 KB) и размер расширения.
Для каждой таблицы Red Brick можно указать сегменты для хранения данных и индекса первичного ключа, максимальное количество сегментов (для версии 5) и максимальное количество строк в сегменте (для Red Brick версии 5).
Для Teradata Erwin также поддерживает специфические объекты физической памяти. В диалоге Teradata Physical Object Editor Editor (меню Server / Teradata Physical Object) можно создать базы данных Teradata и определить их свойства:
- имя владельца базы данных;
- резервированный размер базы данных;
- возможность создания дубликатов таблиц для аварийного восстановления;
- размер spool-файлов;
- место для создания журнала (базы данных и таблицы) и его свойства;
- описание базы данных.
В закладке Physical Props диалога Teradata Table Editor можно определить параметры аудирования и восстановления после сбоя:
- имя таблицы, которая используется для ведения журнала;
- опция FALLBACK PROTECTION - создание одновременно основной и резервной копии таблицы;
- размер пространства, резервируемый для редактируемых данных;
- размер блоков данных.
Закладка Teradata MACRO диалога Teradata Table Editor позволяет создать шаблоны для хранимых процедур Teradata.