
Введение
Мы продолжаем цикл статей на тему юридического искусственного интеллекта, аспектов его разработки и перспектив практического применения на отечественном рынке. В предыдущих публикациях мы неоднократно говорили, что, по нашему мнению, разработка Legal AI может быть обеспечена с помощью создания и применения нового семантического блока, включающего в себя:
- инструменты лингвистического анализа текстов на естественном языке;
- структурированную модель юридических знаний (графы знаний и онтологии);
- предобученные нейронные сети.
В первой статье мы детально исследовали существующие инструменты процессинга русскоязычного текста. Во второй статье мы рассмотрели подходы к созданию продуктов на основе искусственного интеллекта, а также вопросы взаимодействия специалистов в области IT и юриспруденции. В настоящей статье мы предлагаем погрузиться в тему онтологий и ответить на следующие вопросы:
- Какова роль онтологий в процессе создания искусственного интеллекта?
- Почему существующие онтологии в области права неприменимы для Legal AI, несмотря на многолетние попытки зарубежных специалистов структурировать юридические знания?
- Какими свойствами должны обладать онтологии для Legal AI, чтобы решать практические задачи?

1. Логическая интерпретация данных
1.1. Уровни описания знаний
Применение комплекса инструментов процессинга текста на естественном языке, как мы отмечали ранее, позволяет решить первую задачу на пути к Legal AI, а именно - добиться глубокого уровня детализации смыслового содержания юридических документов при помощи группы методов лингвистического анализа (морфология, синтаксис, семантика), машинного обучения и др. Представим, что "завтра" данная задача для русского языка решена на 99,99%.
Следующий важный шаг - это интерпретация результатов с точки зрения предметной области (reasoning). Именно на данном этапе происходит соотношение полученных данных с юридической картиной мира и определение правового содержания того или иного документа.
Например, традиционно в деловой практике при составлении любых гражданско-правовых договоров одним из первых разделов является "Предмет договора", который закрепляет сущность отношений между сторонами. Иными словами, в предмете договора содержатся ответы на вопросы: "По поводу чего заключен договор, и каким образом стороны воздействуют на определенный объект?". Так, в договоре купли-продажи предмет обычно сформулирован следующим образом: "В соответствии с условиями настоящего договора продавец обязуется передать товар в собственность покупателя, а покупатель обязуется принять товар и оплатить его стоимость".
На основе формулировки предмета договора юристы чаще всего определяют его правовую природу, что позволяет правильно квалифицировать отношения между сторонами и применить нужные нормы права, соответствующие характеру правоотношений. Безусловно, это простой и наиболее распространенный пример. Для того, чтобы по такой формулировке идентифицировать договор купли-продажи, экспертных юридических знаний, как правило, не требуется. Но в реальной юридической практике мы чаще сталкиваемся со сложными экономическими взаимоотношениями сторон, которые выходят далеко за рамки простых договоров (купли-продажи) и требуют глубокой работы по толкованию содержания контракта, чтобы дать ему правовую оценку. Однако от сложности конкретной ситуации не зависит общий методологический подход. Человек-юрист читает текст договора или иного документа, идентифицирует в его содержании ключевые юридические факты и смыслы, структурирует их в соответствии с известными ему юридическими концептами и, наконец, применяет системные знания и опыт для формирования логических суждений и выводов. При этом очень часто данные процессы проистекают в сознании юриста неразрывно и параллельно, поскольку любой человек воспринимает и обрабатывает входящую информацию под призмой собственных профессиональных знаний.
Когда мы делегируем программным инструментам любую работу, связанную с логической обработкой данных, необходимо, в первую очередь, сформировать единую картину мира, которая станет общей базой знаний, доступной для восприятия человеком и программными инструментами.
В случае с программными решениями для юристов, целью которых является логическая обработка данных, требуется концептуальное описание юридической картины мира, закономерностей и взаимосвязей правовой системы, глубина которых определяется спектром решаемых задач. Чем сложнее задачи, тем более глубокая и масштабная оцифровка юридических знаний необходима для достижения нужного результата.
Говоря о формализации знаний в контексте data science, нельзя не упомянуть описанную Judea Pearl концепцию из 3 уровней: Association, Causation и Counterfactuals (его книга на эту тему настоятельно рекомендуется к прочтению) .
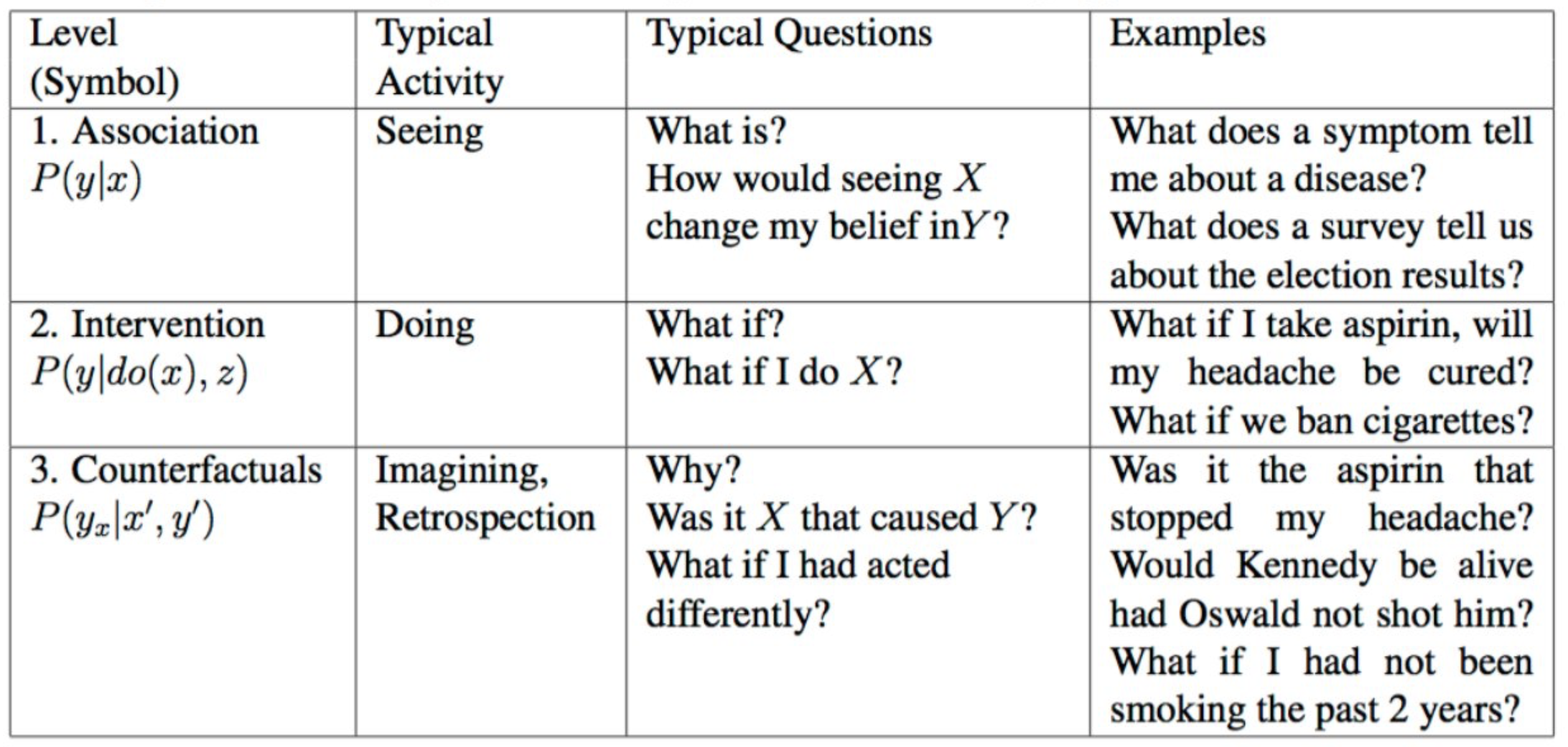
Уровень Association является базовым и наиболее распространенным методом в машинном обучении. Он предполагает генерацию суждений на основе статистики, полученной по итогам обработки большого объема исходных данных. Особенность данного уровня заключается в том, что получаемый конечный результат с высокой долей вероятности будет верным, однако логическое объяснение такого результата будет отсутствовать.
Следующий уровень - Causation. На данном уровне присутствует поверхностная причинно-следственная связь, которая позволяет приходить к определенному результату на основе ряда отличительных признаков. Например, из десятков фотографий животных можно идентифицировать изображение, на котором изображена кошка, с помощью обнаружения уникальных анатомических признаков, присущих именно кошке. Уровень Сausation существенно превосходит предыдущий уровень по возможностям прогнозирования и анализа, однако выявляемая причинно-следственная связь является прямой. Для примера: на уровне Causation мы можем утверждать, что рак легких способен привести к летальному исходу. Но на уровне Causation мы не сможем с уверенностью сказать, что летальный исход явился следствием именно этой вредной привычки, а не какого-либо иного фактора.
И, наконец, третий уровень - Counterfactuals. Данный уровень включает в себя возможности глубоких причинно-следственных рассуждений и способен давать ответы на вопросы, требующие ретроспективного анализа. Возвращаясь к примеру с курением, с помощью данного уровня можно не только утверждать, что курение может привести к летальному исходу, но и формировать рекомендации по снижению рисков заболеваемости раком легких, игнорировать незначительные факторы и др.
Как мы уже отмечали ранее, наиболее распространенным уровнем знаний в машинном обучении является Association. По своей сути все методы достижения результата сводятся к поиску идеального математического уравнения / функции, позволяющей наиболее точно ответить на необходимый вопрос.
Однако, с точки зрения юриста-профессионала, такая "подгонка под результат" вряд ли когда-нибудь станет общепринятым инструментом. В юриспруденции идеальным уровнем, на котором должно оперировать ПО, является Counterfactuals, который предполагает использование полноценной и детализированной картины мира, позволяющей находить ответы на самые разнообразные вопросы и прогнозировать результат на основе произвольных вводных данных. Именно на данном уровне мы можем говорить о возможности формировать суждения и умозаключения в какой-либо предметной области, соответствующие функционалу цифрового юриста.
1.2. Построение суждений и умозаключений
Построение суждений и умозаключений в отношении входных данных на основе юридической логики является ключевой задачей Legal AI. В процессе разработки и создания инструментов, обеспечивающих решение данной задачи, как мы отмечали в предыдущих публикациях, необходимо руководствоваться "first principles" и подходить к ее реализации с самых фундаментальных начал.
Одной из основных возможностей и назначений онтологий как семантических моделей представления знаний предметной области является возможность генерации и вывода новых знаний на основе взаимосвязей между имеющимися концептами (reasoning). Результаты данного процесса включают в себя два элемента: суждение и умозаключение. Их отличия берут свое начало в философии и логике, которые изучают процессы мышления и познания. Так, суждением является мысль, в которой посредством связи понятий утверждается (отрицается) что-либо о чем-либо, а умозаключение - более высокий уровень логического опосредования, чем суждение, в ходе которого из сопоставления ряда суждений выводится новое суждение.
Возвращаясь к рассматриваемой проблематике, можно привести классический пример суждения: "S есть P". Генерация подобных суждений может быть обеспечена при помощи набора лингвистических инструментов с применением семантики и графа знаний. В результате мы можем говорить о том, что задача процессинга текста сводится к трансформации предложений на естественном языке в набор подобного рода суждений.
Практический пример реализации данного инструментария может быть проиллюстрирован с помощью анализа вводной части ("шапки") искового заявления, в которой традиционно указываются следующие сведения:
- наименование и адрес суда, в который адресован данный иск;
- наименование, идентификаторы (ОГРН/ОГРИП, ИНН, КПП и др.) истца и его адрес;
- наименование, идентификаторы (ОГРН/ОГРИП, ИНН, КПП и др.) ответчика и его адрес и др.
Например, в части сведений об истце/ответчике шапка искового заявления обычно содержит в себе его наименование и адрес в формате: "Истец: ООО "Ромашка", г. Москва, ул. Тверская, д. 1, офис 1". Из данного фрагмента текста может быть выделен набор суждений, которые изначально не имеют прямой связи между собой. Такие связи подразумеваются, и в результате их восстановления мы можем с помощью инструментов лингвистики и NER получить следующие суждения:
- "ООО "Ромашка"" есть "Организация" типа "Общество с ограниченной ответственностью";
- "г. Москва, ул. Тверская, д. 1, офис 1" есть "Адрес".
При этом подразумевается наличие еще одной связи, следующей из данного фрагмента: "ООО "Ромашка" имеет "Адрес" равный "г. Москва, ул. Тверская, д. 1, офис 1". Данная связь является примером умозаключения, которые мы получаем путем сопоставления двух суждений. Это и есть результат процесса reasoning'а.
Для того, чтобы генерировать умозаключения, необходимо иметь набор формализованных знаний, на основе которых становится возможным сопоставлять суждения и выводить новые знания о конкретных субъектах и объектах отношений. В нашем примере таким знанием является правило о том, что "Организация" типа "Общество с ограниченной ответственностью" имеет "Адрес". Очевидный вопрос в данной ситуации: "Каким образом формировать данные формализованные знания?". Здесь нам на помощь приходит дескрипционная логика и объектно-ориентированное программирование.
1.3. Дескрипционная логика и объектно-ориентированное программирование
Дескрипционная логика (описательная логика, логика концептов) - язык представления знаний, позволяющий описывать понятия предметной области в недвусмысленном, формализованном виде, организованный по типу языков математической логики. Дескрипционные логики сочетают, с одной стороны, богатые выразительные возможности, а с другой - хорошие вычислительные свойства, такие как разрешимость и относительно невысокая вычислительная сложность основных логических проблем, что делает возможным их применение на практике, обеспечивая компромисс между выразительностью и разрешимостью.
Современное название семейство дескрипционных логик получило в 1980-е годы. В то время они изучались как расширения теорий фреймовых структур и семантических сетей механизмами формальной логики. В 2000-е годы дескрипционные логики получили применение в рамках концепции семантической паутины, где их предлагалось использовать при построении онтологий. Язык OWL разрабатывается как язык, на котором можно формулировать и публиковать так называемые сетевые онтологии - формально записанные утверждения о понятиях и объектах некоторой предметной области. Одно из требований к таким онтологиям заключается в том, чтобы содержащиеся в них знания были доступны для машинной обработки, в частности, для автоматизированного логического вывода новых знаний из уже имеющихся. Для этого требуется, чтобы язык, на котором формулируются онтологии, имел точную семантику, а соответствующие логические проблемы были разрешимы (и имели практически допустимую вычислительную сложность). Кроме того, желательно, чтобы такой язык имел довольно большую выразительную силу, пригодную для формулировки на нём практически значимых фактов. Дескрипционные логики обладают такими свойствами, и по этой причине они были выбраны в качестве логической основы для языка OWL. OWL базируется на языке разметки XML, поэтому можно сказать, что OWL является результатом преобразования некоторых дескрипционных логик с использованием синтаксиса XML.
Таким образом, мы подошли к исследованию онтологий как формы структурирования информации. Подобные модели представления знаний нашли свое практическое применение в широких областях. Самое очевидное и первостепенное применение - использование онтологий в качестве источника данных для компьютерных приложений (для информационного поиска, анализа текстов, извлечения знаний и др.), поскольку онтологии позволяют более эффективно обрабатывать сложную и разнообразную информацию. Этот способ представления знаний позволяет распознавать те семантические отличия, которые являются само собой разумеющимися для людей, но не известны программным инструментам. На современном этапе своего развития онтологии и графы знаний становятся инструментами выражения знаний и опыта предметной области в том числе для решений на базе технологий искусственного интеллекта в самых различных сферах, в том числе и в области юриспруденции.
Говоря о необходимости создания юридических онтологий и графов, мы не ставим перед собой задачу по переводу в машиночитаемый формат норм права из текстов законов, иных нормативно-правовых актов, а также судебных решений. Подобные идеи возникали в научном сообществе, однако, по нашему мнению, они не имеют практического смысла.
Юриспруденция является крайне сложной и фрагментарной областью знаний, несмотря на то, что имеется общепринятая в РФ система права, которая позволяет выделить определенные отрасли, подотрасли, институты и др.
На практике реальные кейсы очень часто лежат на пересечении многих отраслей права, имеющих в том числе противоположное регулирование. В теории права даже существуют такие понятия, как пробелы правового регулирования (наличие отношений, не имеющих какого-либо правового регулирования), коллизии права (случай, при котором одна ситуация подвергнута противоположному регулированию), аналогия права и др. Кроме того, нормативно-правовые акты задают общий вектор правового регулирования, часто определяя лишь основные начала и его принципы, оставляя диспозитивным субъектам отношений право самостоятельно согласовать для себя правила поведения в установленных пределах.
Например, в отношении отдельных видов договоров ГК РФ закрепляет определенные существенные условия, без согласования которых договор считается незаключенным. Как правило, это предмет договора, срок и/или цена (точный набор существенных условий зависит от конкретного вида обязательства). Они выступают минимально необходимым числом условий для заключения договора, но в деловой практике редки случаи, когда договор ограничивается только существенными условиями, упомянутыми в законе.
Очень часто стороны самостоятельно формулируют подходящие для них условия сотрудничества, которые в законе не упомянуты. Кроме того, в гражданском праве существуют такие категории, как непоименованные договоры (соглашения, не предусмотренные ГК РФ в качестве самостоятельного вида договора), регулирование которых осуществляется по аналогии закона/права. Помимо этого тексты законов определяют только правило поведения. Возвращаясь к примеру про существенные условия договора, важно отметить, что ГК РФ требует наличия данных условий в договоре, но не определяет порядок их согласования, рекомендуемые формулировки того или иного условия и др. Все это свидетельствует о том, что тексты нормативно-правовых актов и судебных решений охватывают, по нашей оценке, не более 20-30 % реальной юридической практики. Многие вопросы правоприменения лежат за их рамками и формируются в формате обычаев делового оборота, поэтому трансформация законов и судебных решений в машиночитаемый формат не позволит в полном объеме воспроизвести юридическую картину мира.
Отдельная проблема данного подхода - неоднозначность и сложность юридического языка. В предыдущей публикации мы рассказывали об эксперименте 1986 года по разбору нормативного акта (The British Nationality Act) с применением логики языка Prolog. Суть эксперимента заключалась в попытке разложения текста данного закона на структурные единицы (смысловые триплеты), что и было осуществлено. Авторы эксперимента тогда отмечали, что большой проблемой для самих правоприменителей (юристов, адвокатов, судьей и др.) является неоднозначность и двусмысленность законов, которые создают дополнительные проблемы при попытке их толкования в процессе применения. Сложность профессиональной лексики, проблемы в юридической технике авторов законов и многое другое не всегда позволяют однозначно истолковать тот или иной нормативно-правовой акт, приводя к разному пониманию одной и той же нормы. Данная проблема актуальна для всех юрисдикций, в том числе и для России. Достаточно вспомнить сложившуюся практику применения новых норм. После принятия и вступления в силу новых положений законодательства часто требуется значительное количество времени для выработки практики их применения, в том числе нередки случаи, когда за принятым законом следуют разъяснения ВС РФ в виде Постановлений Пленума, которые объясняют как правильно интерпретировать те или иные положения. Все это говорит о том, что оцифровка текстов нормативно-правовых актов и судебных решений не позволит в полной мере воссоздать юридическую картину миру и выработать базу правовых знаний.
Отдельно остановимся на ограничениях и трудностях структурирования юридических знаний в формате онтологий. Язык OWL обладает рядом ограничений, которые порождают сложности при попытках отражения отдельных видов отношений, существующих в объективной реальности.
К таким отношениям могут быть отнесены почти все связи, которые на естественном языке выражаются с помощью причастий и деепричастий, а также отношения, которые длились в течение определенного периода времени. Например, утверждение: "Генеральный директор, назначенный решением собрания акционеров, осуществлял полномочия в период с 01.09.2015 г. по 01.09.2019 г." на практике крайне трудно смоделировать в OWL, поскольку связи (object properties) не предполагают наличие собственных свойств.
Существующие в OWL подходы к решению данной проблемы создают приводят к практически неконтролируемому росту классов, в результате чего:
- онтологии становится крайне сложно интерпретировать и поддерживать;
- операции с классами и инстансами (instances) становятся сложновычислимыми.
Данная проблема характерна в принципе для всего объектно-ориентированного программирования, однако в последнее время появляются перспективные проекты и решения в этой области. Например, сообществом W3C в 2017 г. принят стандарт Shapes Constraint Language (SHACL), который позиционируется в качестве альтернативы RDFS/OWL и обладает более широкими возможностями по описанию свойств и характеристик объектов. Кроме того, потенциальным решением является переход к нереляционным базам данных (графовым системам), которые обладают гораздо большей выразительностью при описании классов и связей.
2. Графы знаний и онтологии
2.1. Обзор существующих юридических онтологий
В рамках предыдущей публикации мы исследовали отдельные вопросы, связанные с онтологиями. Тогда мы писали, что онтология является унифицированной и структурированной базой знаний предметной области, представляющей собой объективное семантическое отражение картины мира в виде набора связанных между собой терминов, иерархически записанных в формате классов, подклассов и связей (Relationships) между ними, что позволяет соотносить имеющиеся данные между собой с точки зрения экспертной логики.
Также мы отмечали, что среди способов систематизации знаний онтологии предшествовала таксономия (любая структура знаний в виде иерархически соотносящихся сущностей с связями одного типа - "subclass of"), а органическим развитием онтологических систем представления знаний является граф. Граф структурно включает в себя графовые хранилища семантических метаданных и онтологий, которые в данном случае выступают в роли полуструктурированной модели предметной области, являясь ядром графа знаний. В результате такого способа обеспечивается возможность решения интеллектуальных задач с помощью постоянной циркуляции данных за счет применения методов машинного обучения.
Вопросы о необходимости структурирования и систематизации знаний в различных предметных областях впервые начали возникать еще в XX веке. Активное применение онтологий в качестве модели такой систематизации началось за рубежом в 1990-х годах, и на тех этапах был создан ряд обширных онтологий, включающих несколько тысяч терминов (OMEGA, SUMO, DOLCE и другие). В начале 2000-х годов были выработаны единые стандарты построения онтологий. Так, в 2004 г. объединенным консорциумом W3C была опубликована первая рекомендация и спецификации языка OWL 1.0, который получил свое развитие до версий 1.1 и 2.0. Следует отметить, что до принятия спецификаций языка OWL их развитие происходило с применением других языков представления онтологий (KIF, Ontolingua, XOL и др.). В России единый подход не был выработан, поэтому развитие онтологических систем знаний происходит менее активно (как и их практическое применение).
Первые онтологии создавались в основном в рамках научных исследований. Позднее онтологии стали получать свое распространение в самых различных прикладных областях (медицина, биология, информатика, финансы, бизнес-сфера и др.). Не стала исключением и юриспруденция. Первые функциональные онтологии в области права появлялись еще в 1990-х годах (Functional Ontology of Law by Valente et al. (1994), Frame-based ontology by van Kralingen (1997) и др.). В настоящее время наиболее распространенными в мире являются следующие юридические онтологии: LKIF, UFO, FIBO, FBO и Legal Rule ML. Мы решили детально исследовать и сравнить данные онтологии между собой (подробнее в Разделах 2.1.1-2.1.6).
Прежде чем перейти к анализу конкретных онтологий, необходимо определить критерии сравнения и оценки их практической применимости. На основе длительных теоретических исследований и практической деятельности по моделированию онтологий и графов для оцифровки отдельных правовых знаний мы выработали собственное видение идеальной модели представления юридической картины мира и требований к ним.
В первую очередь, необходимо понимать, что создать универсальную и общеприменимую онтологию в области права невозможно в силу различия государственно-правовых систем и применяемого языка. Мы детально рассматривали данные причины в предыдущей публикации, в которой приводили пример того, что даже внутри одной правовой семьи существуют значительные и фундаментальные отличия в понимании одних и тех же правовых институтов и явлений.
Кроме того, говоря об уровне детализации онтологий, мы отмечали, что существующие модели знаний не отличаются глубоким уровнем проработки, поскольку они создавались преимущественно для целей обмена знаниями и информацией, что требует использования высокой степени абстракции, а потому они не применимы для целей практической юриспруденции, поскольку используемых концептов будет недостаточно для отражения правоотношений.
С учетом данных обстоятельств в качестве критериев сравнения рассматриваемых далее 5 (пяти) онтологий мы предлагаем использовать следующие:
- уровень детализации (количество понятий и концептов);
- возможность структурирования концептов из правовой системы РФ;
- возможность и необходимость доработки онтологии для обеспечения совместимости с правовой системой РФ;
- логика и удобство использования;
- ширина охвата правоотношений;
- необходимость модификации при изменении законодательства.
2.1.1. FIBO
Financial Industry Business Ontology (FIBO) является одной из наиболее распространенных онтологий в финансовой сфере. Она разрабатывается международным сообществом под управлением консорциума OMG, который занимается объектно-ориентированными технологиями и стандартами с 1989 года. Стандарты FIBO применяются многими налоговыми органами различных государств в том числе в рамках автоматического обмена информацией (сведения о бенефициарах и др.).
Данная онтология в контексте анализа моделей представления юридических знаний имеет неоднозначное значение. С одной стороны, FIBO описывает финансовый рынок и отношения между его участниками (финансовые сделки/операции, финансовые активы и др.), не имея в качестве своей основной цели структурировать правовые категории и стать стандартом юридической онтологии. С другой стороны, в силу наличия значительных пересечений финансовой сферы и права описывать финансовые отношения без использования базовых правовых категорий невозможно, поэтому FIBO включает в себя правовой блок терминов, минимально необходимых для структурирования финансовой области знаний. Так, например, для построения финансовой онтологии невозможно не использовать такие классические правовые понятия, как юридические лица, ценные бумаги, сделки и многое другое.

Однако мы отмечали в предыдущей статье, что рассматривать FIBO в качестве юридической онтологии неправильно. Во-первых, вследствие различия глубины проработки вопросов финансов и права онтология FIBO малоприменима для решения задач в сфере Legal AI, а, во-вторых, даже имеющиеся в ней юридические концепты построены на зарубежных правовых системах, которые не адаптированы для российского права. Но несмотря на данные факты, онтология FIBO обрела крайне широкое распространение и практическое применение в бизнес-сфере, а также считается одним из лучших примеров онтологий в целом, поэтому мы решили детально проанализировать ее состав и особенности.
FIBO совокупно состоит из 3099 классов. Понятия онтологии FIBO представлены двумя способами: формальным описанием понятий и их взаимосвязей на языке OWL, а также их описанием на естественном языке с использованием толковых словарей финансовой отрасли. Формальное описание понятий на языке OWL выполнено с применением широко используемого в семантическом моделировании редактора онтологий Protege. Предполагается, что онтология FIBO должна стать общим языком для финансовой индустрии, поддерживающим автоматизацию бизнес-процессов. Она предназначена для использования разработчиками программного обеспечения, бизнес-аналитиками и другими участниками сферы финансов. Бизнес-термины и определения, описанные в FIBO, могут быть использованы в качестве эталонной модели, с которой финансовые организации могут связывать свои собственные (локальные) модели. Появляется возможность создавать логические модели данных, которые получают из FIBO свою формальную семантику.
В основе FIBO лежит онтология верхнего уровня, которая включает категории, называемые "разделами". Разделы включают описание различных типов базовых сущностей (например, таких, как независимые/связанные, реальные/абстрактные и т.п.). Онтологию верхнего уровня использует базовый модуль FIBO Foundations, который содержит большой набор подмодулей. А на основе FIBO Foundations уже разрабатываются такие модули, как FIBO Business entities (бизнес-сущности) и FIBO Indices and Indicators (индексы и показатели). Такая модульная формальная модель позволяет раздельно описать, использовать и при необходимости дополнять группы понятий, содержащихся в отдельных модулях.
FIBO Foundations включает в себя набор базовых понятий, которые в дальнейшем используются для описания соответствующих им терминов финансовой отрасли. В этом модуле описываются общие понятия, которые не являются уникальными для финансовой индустрии, но требуются для описания понятий, связанных с финансами, в том числе набор базовых юридических категорий (договоры и сделки, организации и др.). В некоторых случаях в FIBO Foundations используются понятия-заместители ("Proxy" concept) для выполнения ссылок на понятия, описанные в других разделах. Например, подобные заместители используются для таких понятий, как адрес (address) или страна (country). Это связано с двумя причинами: понятия, используемые в финансовой отрасли, обычно имеют более специфичный смысл, чем соответствую-щие им более общие, нефинансовые понятия.

Примерами таких понятий являются контракты или транзакции, которые включены в FIBO Foundations для того, чтобы их можно было уточнить в других спецификациях онтологий. Вторая причина использования понятий-заместителей заключается в том, что свойства некоторых понятий финансовой отрасли часто должны использоваться во взаимосвязи с другими, не финансовыми понятиями (например, страны, юрисдикции, адреса и т.п.). Такие понятия включены в FIBO Foundations, чтобы на них можно было ссылаться в других спецификациях FIBO.
Раздел FIBO Business entities не входит в состав FIBO Foundations и создан на его основе. Он представляет собой модель бизнес-концепций, которые представлены в терминах финансовой индустрии, используемых в нормативных и финансовых документах организаций. В данном модуле описан набор терминов, связанных с хозяйствующими субъектами (business entities), в том числе юридическими лицами различных органи-зационно-правовых форм, отношениями управления и собственности между ними. Также FIBO Business entities содержит подробные требования к формированию диаграмм и отчетов, предназначенных для использования бизнес-экспертами. FIBO Business entities включает набор подмодулей, позволяющих описывать юридические лица, корпорации, партнерства, трасты, собственность и контроль, функционально определенные хозяйствующие субъекты и др.

Подводя итог обзору FIBO, отметим следующие выводы. FIBO включает в себя 3099 понятий, описывающих финансовую сферу и взаимоотношения ее субъектов, не все их которых имеют отношение к юридической сфере. Среди правовых категорий, используемых в данной онтологии, применяются только базовые понятия субъектов финансовых отношений (организации и физические лица) и объектов финансового рынка (акции и иные ценные бумаги). При этом в онтологии в юридической части воспроизведена система англо-американского права, которая не подходит для применения в РФ. Модульная структура онтологии положительно сказывается на возможностях ее модификации. В результате отметим, что FIBO, хотя и является примером детализированной отраслевой онтологии, для решения практических задач в области Legal AI в России не подходит ввиду того, что унификация знаний в области бизнеса и финансов не охватывает в необходимой мере юридические концепты.
2.1.2. LKIF
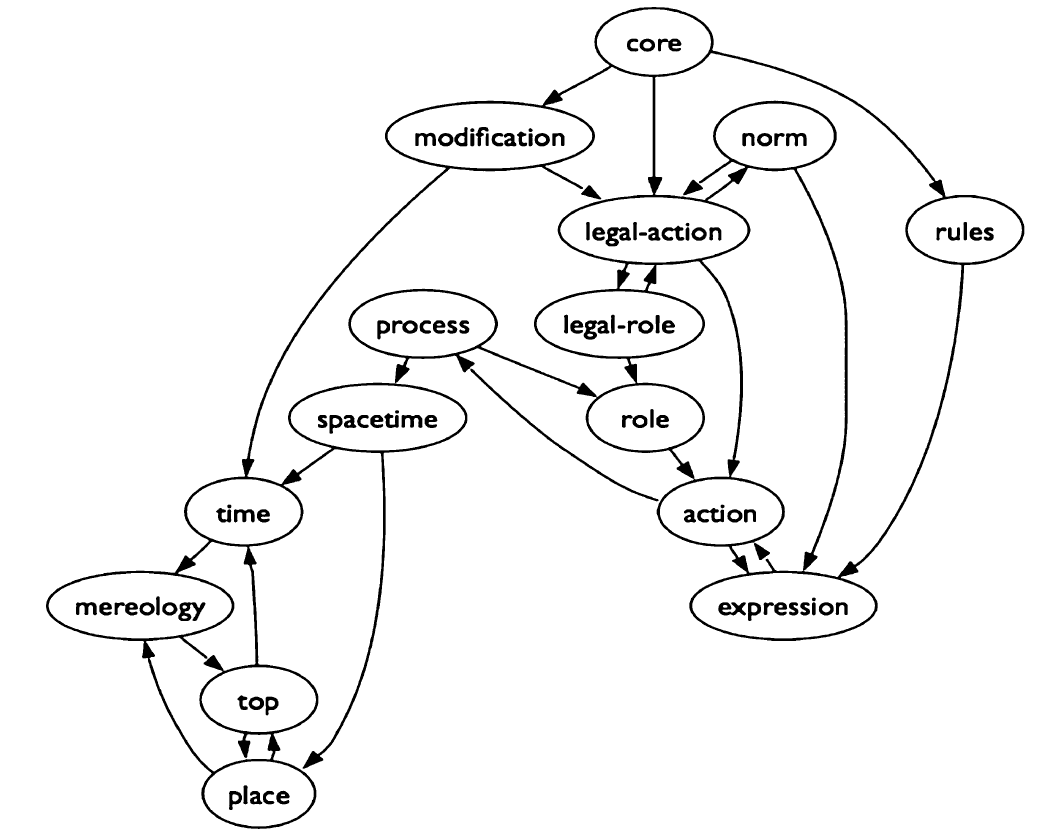
Одной из наиболее объемных юридических онтологий является LKIF (Legal Knowledge Interchange Format), созданная в рамках проекта Estrella. В LKIF правовые концепции моделируются на основе объективной реальности и основываются на объектах и процессах реального мира. По замыслу создателей данной онтологии на практике она должна способствовать осуществлению двух основных функций: выполнять перевод между правовыми базами знаний, написанными в разных форматах, и представлять юридические данные в формализованном формате для разработки правовых систем знаний. В действительности LKIF является не единой онтологией, а представляет собой набор большого количества онтологий, которые разделены по модулям и подмодулям. Модули (подмодули) включают в себя наборы совместно используемых онтологий. Так, LKIF включает в себя когда-то самостоятельную объемную онтологию LRI-core ontology. LRI-core представляет собой базовую онтологию, содержащую основные понятия, общие для всех правовых систем, такие как норма права, мораль, контракт, роль, юридическая ответственность и др.
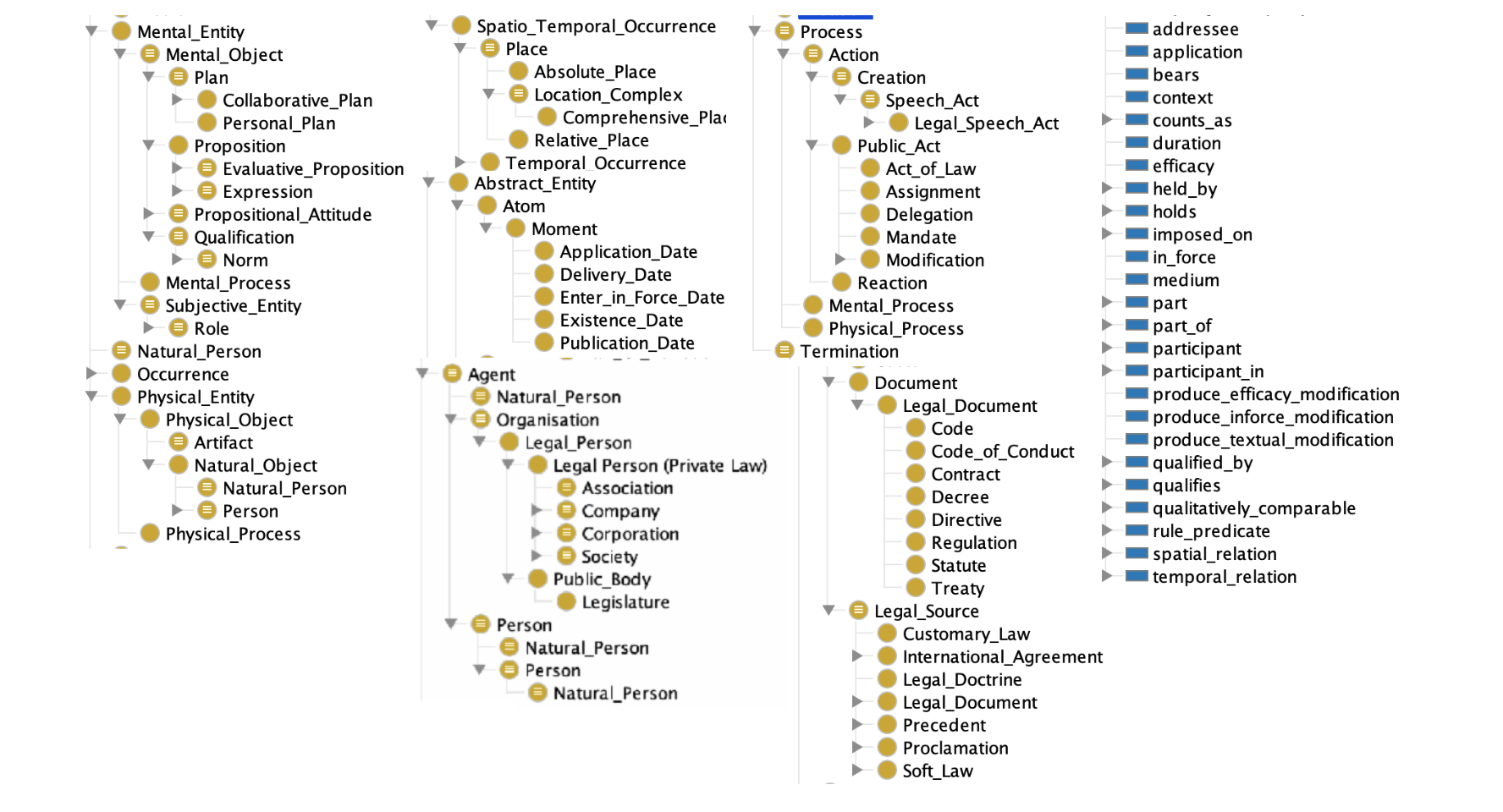
LKIF представляет собой библиотеку юридических онтологий, состоящую из 15 модулей, каждый из которых описывает набор тесно связанных понятий как из области права, так и общих концептов, необходимых для отражения объективной реальности. Среди данных модулей можно выделить следующие:
- Верхний модуль - описывает такие основные понятия и концепции, как "Ментальный объект" (Mental entity), "Абстрактный объект" (Abstract entity), "Событие" (Occurrence), "Физический объект" (Physical entity);
- Модуль связей - описывает отношения между частью и целым в различных смыслах. Включает такие отношения, как: "является компонентом" (is component), "является частью" (is part of), "является членом" (member of) и другие;
- Модуль места - включает понятия и отношения, описывающие пространственные связи между объектами реального мира;
- Модуль времени - описывает временные характеристики и отношения. Содержит концепции "момент" (самая малая единица времени) и "интервал" (может содержать моменты, а также другие интервалы). Основные типы отношений: "произошло до" (before), "завершилось" (finish), "между" (between) и другие;
- Модуль процессов - содержит описания процессов изменения объектов реального мира. Выделено три типа изменений: начало, продолжение, прекращение;
- Модуль агентов - субъекты, совершающие действия и взаимодействующие друг с другом. Типы агентов: индивиды, организации;
- Модуль действий - описывает возможные реакции и действия агентов. Действия могут осуществляться с помощью предметов;
- Модуль ролей - описывает социальную структуру, а также допустимое и недопустимое поведение агентов.
- Модуль описания классов - описывает утверждения, характеристики других классов и выступает основой для описания содержимого юридических документов;
- Модуль юридических действий - дополнительный модуль к действиям, определяющий действия исполнителей в зависимости от их определения в каком-либо нормативном документе;
- Модуль описания юридических норм - расширяет модуль описания высказываний и определяет различные виды юридических документов: контракт (Contract), директива (Directive), кодекс (Code) и другие.
Отдельно остановимся на описании юридических концептов (Legal Concepts). Legal Concepts является основным блоком онтологии LKIF и представлен в виде трех модулей: Legal role, Legal action и Legal norm.

Legal role направлен на расширение общего модуля Role, описывающего возможные роли активных субъектов материального мира, путем выделения специальных правовых субъектов, имеющих особый юридический статус. Он включает в себя такие классы, как государственные органы, юридические лица, физические лица, агенты и др.
Legal action направлен на расширение модуля Action и включает в себя описание действий, осуществляемых классами, включенными в модуль Legal role.

Модуль Legal norm является расширением прежде всего модуля выражений, где нормы определяются как квалификации. Модуль содержит в себе классы типа: законы, подзаконные акты, постановления и др., тем самым детализируя возможные источники права.
Несмотря на обширность модулей, входящих в LKIF, она является базовой и верхнеуровневой юридической онтологией, которая при этом адаптирована под систему англо-саксонской правовой семьи. В результате такая модель представления знаний имеет некоторую универсальность и способна выполнять задачи, для решения которых она создавалась, однако применение ее в качестве полноценной юридической базы знаний невозможно, поскольку она имеет высокий уровень абстракции. Важно отметить, что LKIF исследовалась отечественными учеными (П.А. Ломов и А.Г. Олейник), которые предпринимали попытки структурирования текста отечественного нормативного акта на основе данной онтологии. В качестве такого акта использовалась "Стратегия социально-экономического развития Мурманской области до 2020 года и н период до 2025 года". Основной идеей ученых была разработка автоматизированной системы проверки проектов нормативных актов на целостность и отсутствие противоречий. В идеальном представлении авторов, такая система способствовала бы обеспечению целостности правового поля при принятии новых актов. Решать данную задачу ученые планировали с помощью представления нормативных документов в OWL-онтологии, что обеспечило бы выявление некоторых отношений между классами, указывающих на неточности или противоречия в положениях исходных документов. Методология формализации нормативно-правового документа в онтологии, по мнению ученых, должна была состоять из следующих основных шагов:
- определение документа как экземпляр класса "Основание" (Medium) или его подклассов, а также атрибутов документа: относительный уровень юридической силы, автор, дата публикации, дата вступления в силу, исполнитель и др.;
- представление в онтологии объектов, процессов, явлений реального мира, используемых в положениях документа;
- формализация положений документа в виде подклассов класса "Предложение" (Proposition) и/или суждений (Qualification);
- корректировка положений в соответствии с предложенными системой рекомендациями.
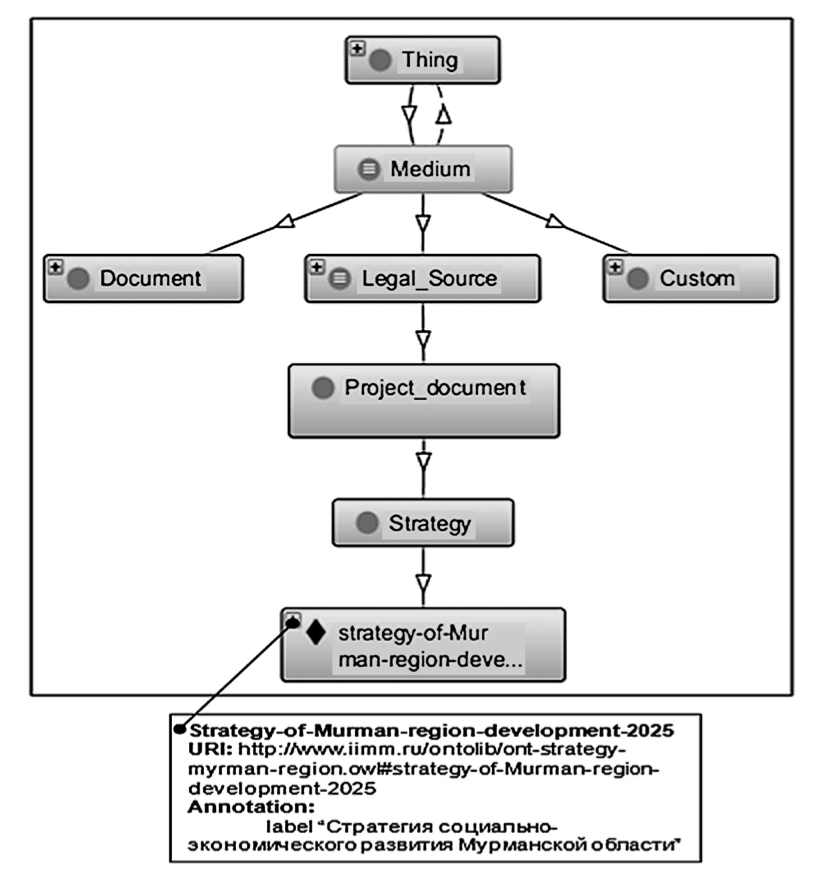

В ходе эксперимента П.А. Ломов и А.Г. Олейник подтвердили свою концепцию на отдельных примерах формализации некоторых положений документа и пришли к выводу, что онтология LKIF может быть принята за базовую версию концептуального описания юридической картины мира для поставленных целей. Это лишь подтверждает наши выводы о том, что LKIF является крайне верхнеуровневой онтологией, которая подходит для формализации текстов законов на абстрактном уровне, но не применима для решения практических задач по обработке входных данных и формированию суждений и умозаключений с точки зрения юридической логики.
Онтология LKIF в области изучения моделирования правовых знаний является, пожалуй, самой исследуемой в научном сообществе. Ей посвящены следующие научные работы:
- M. Ceci, A. Gangemi ("An OWL ontology library representing judicial interpretations", Semantic Web, 2016);
- Cevenini C., Contissa, G., Laukyte, M., Riveret, R., Rubino, R. ("Development of the ALIS IP ontology: Merging legal and technical perspectives", Computeraided innovation (CAI), Boston, 2008);
- Distinto, I., d"Aquin, M., & Motta, E. ("LOTED2: An ontology of European public procurement notices", Semantic Web, 2016);
- Ghosh, M. E., Naja, H., Abdulrab, H., & Khalil, M. ("Towards a legal rule-based system grounded on the integration of criminal domain ontology and rules", In Procedia Computer Science: 112, 2017);
- Rodrigues, C. M. O., Azevedo, R. R., Freitas, F. L. G., da Silva, E. P., & da Silva Barros, P. V. (An ontological approach for simulating legal action in the brazilian penal code. In Proceedings of the 30th annual ACM symposium on applied computing", New York, 2015) и др.
Кроме того, онтология LKIF применялась в практико-ориентированных проектах. На ее основе предпринимались попытки систематизации источников права во Вьетнаме с возможностями поиска по базе нормативных актов, а также попытки структурирования правил пассажирских авиаперевозок на основе выборки наиболее нарушаемых прав пассажиров.
С 2008 года проект Estrella, в рамках которого разрабатывалась онтология LKIF, закрыт.
2.1.3. Legal Rule ML
Следующей моделью представления знаний, которую мы предлагаем рассмотреть, является Legal Rule ML. Данная модель разработана некоммерческим сообществом OASIS, осуществляющим реализацию проектов в области информационных технологий (кибербезопасность, блокчейн, защита информации, криптография, облачные вычисления, IoT и др.) с открытым исходным кодом с 1993 г. Само сообщество в своей деятельности стремится продвигать работу, направленную на снижение затрат и повышение эффективности разных видов деятельности, стимулирование инноваций, расширение рынков и развитие процессов мировой глобализации. Одним из направлений деятельности сообщества стало развитие универсального языка представления юридических текстов. Интересен также тот факт, что над созданием Legal Rule ML работала группа ученых, ранее участвовавших в проекте Estrella по разработке LKIF Core ontology. После закрытия проекта Estrella в 2008 г. и прекращения поддержки LKIF Core, Legal Rule ML по праву считается преемником LKIF, хотя и между ними очевидно не прослеживаются прямые признаки преемственности, кроме целей разработки.
Как отмечают представители сообщества, на создание Legal Rule ML их побудило обнаружение ряда проблем в области нормотворчества. Юридические тексты (законы, положения, судебные акты, договоры и др.) содержат в себе принципы и правила поведения, которыми руководствуются субъекты различных общественных отношений. При этом с течением времени и с усложнением общественных отношений количество нормативных актов растет, что порождает для правоприменителей значительные сложности в поиске, толковании, сравнении их содержания и др. Кроме того существует проблема и для лиц, разрабатывающих и принимающих новые нормативные акты, поскольку необходимость ручной проверки проекта документа на непротиворечие действующим источникам права не всегда является эффективной и не позволяет избежать правовых коллизий в будущем. Потенциальным решением данных проблем, по мнению сообщества OASIS, может стать обеспечение возможности конвертации текстов нормативных актов в машиночитаемый формат (XML) и их структурирование. В последующем это станет платформой для унификации и структурирования юридических знаний, что будет способствовать развитию программных решений в области юриспруденции, а также позволит создать универсальный язык обмена правовыми знаниями и будет способствовать постепенному переходу от естественного языка при конструировании новых правовых норм к формализованному и машиночитаемому формату. Именно для решения данных проблем была разработана Legal Rule ML.
Итак, с учетом поставленных создателями Legal Rule ML целей данная модель не является правовой онтологией в чистом виде, а представляет собой скорее язык обмена правилами на основе XML, который направлен на расширение более общего языка разметки правил Rule ML функциями, присущими юридической области. Legal Rule ML имеет верхнеуровневую структуру в виде групп Node elements и Edge elements, которые выполняют служебную роль по объединению групп правил. Сами правила (значение нормы) выражаются с помощью существующих операторов (классов) в виде связей, отражающих воздействие нормы на субъекты или объекты.
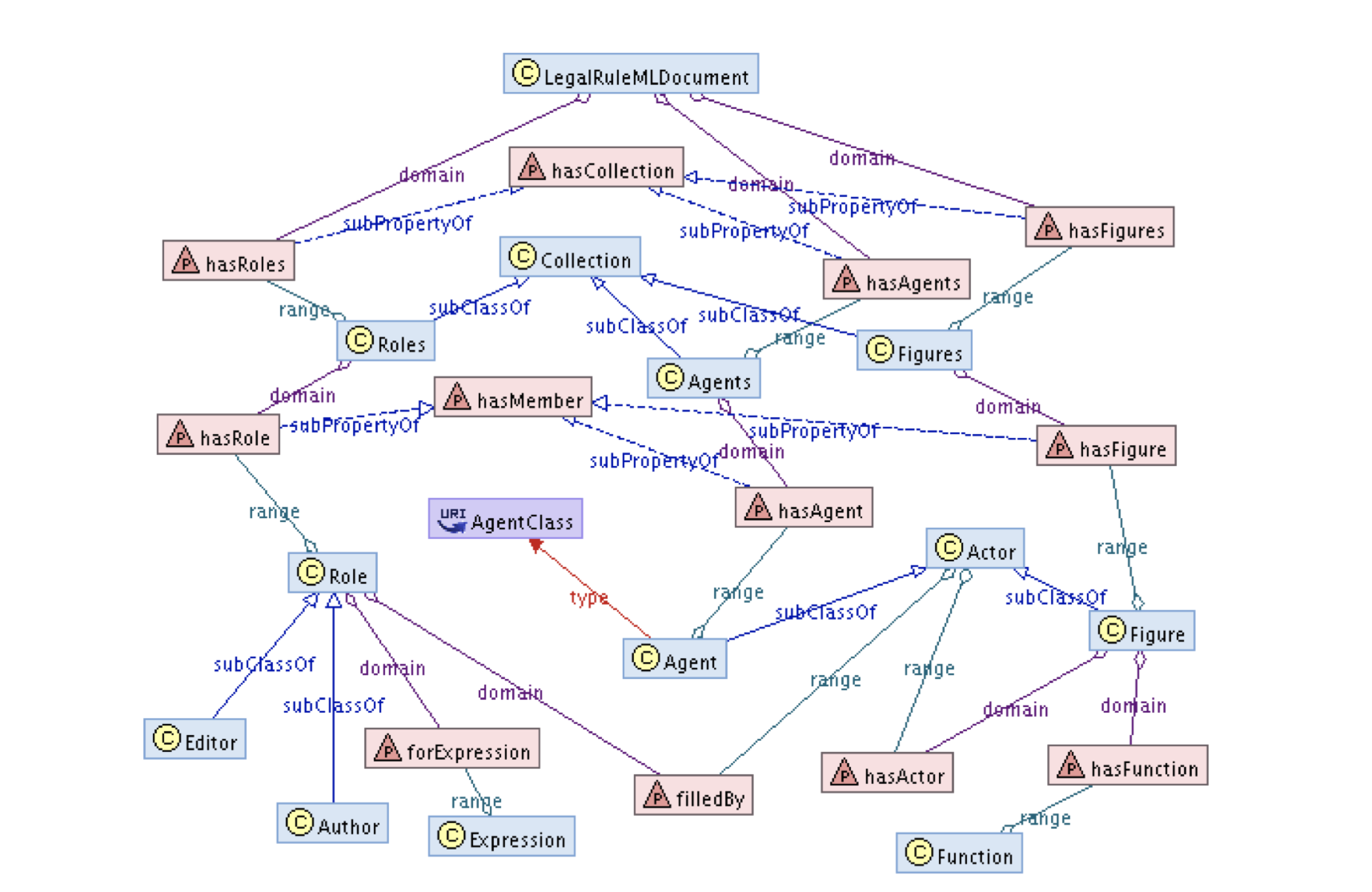
В качестве основных операторов предусмотрены Agent (активный субъект, который действует или имеет возможность осуществлять действия), Figure (функция, которую выполняет субъект, или его статус) и Role (роль, которая формируется при реализации субъектом своих функций). Например, с помощью данных операторов могут быть структурированы все нормативные акты, принятые конкретным должностным лицом.
Помимо данных категорий Legal Rule ML содержит операторы юрисдикции (географические пределы действия нормативного акта), полномочий, времени для отражения временных пределов действия нормативного акта (момент вступления в силу, момент прекращения действия и др.), а также событий как разновидности юридических фактов, с которыми могут быть связаны определенные правовые последствия.
Подводя итог обзору Legal Rule ML, отметим, что данная модель представления знаний, безусловно, имеет свои преимущества и позволяет структурировать содержание нормативного акта. Но применение этой модели для целей правовой оценки данных невозможно в силу ее специфической структуры. Мы не склонны считать это недостатком, поскольку изначальный замысел ее создателей был направлен на выработку языка представления нормативного акта на основе логики и синтаксиса Rule ML. Кроме того, Legal Rule ML по своей структуре не имеет привязки к правовой системе, поскольку оперирует общими понятиями и категориями, что позволяет использовать ее для работы с нормативными документами разных государств. Учитывая тот факт, что модель поддерживается и развивается сообществом OASIS в настоящее время, не исключено, что мировая общественность в будущем увидит впечатляющие практические результаты в данных направлениях, но не в контексте Legal AI и цифрового юриста.
2.1.4. UFO
Онтология Unified Fundamental Ontology (UFO) была разработана в 2004 году G. Guizzardi и его рабочей группой с целью разработки фундаментальной и универсальной теории концептуального моделирования любой области знаний. Данная модель не является примером юридической онтологии. Ее ключевой задачей было создание некоторой обобщенной модели представления событий и действий объективной действительности, которую можно применять в самых разнообразных прикладных областях, в том числе в сфере права.
Первая версия UFO 0.1 появилась в результате синтеза двух других фундаментальных онтологий, а именно:
- General Formal Ontology (GFO), которая лежит в основе онтологического языка General Ontological Language (GOL) (разработка исследовательской группы OntoMed Research group при Университете Лейпциг (Германия));
- Descriptive Ontology for Linguistic and Cognitive Engineering (DOLCE), которая построена на основе принципов и методов OntoClean (разработка исследовательской группы ISTC-CNR-LOA Research group (Италия)).
Основу структуры UFO определяет систематический метод сравнения метамодели языка с конкретным представлением концептуализации той или иной предметной области, называемой эталонной онтологией. Онтология UFO успешно применяется для интерпретации моделей, включая бизнес-моделирование, а также для решения проблем семантической совместимости и интеграции различных языков моделирования. UFO является основополагающей онтологией для OntoUML, языка моделирования онтологий.
UFO состоит из трех фрагментов: UFO-A, UFO-B, UFO-C. Основные категории UFO (UFO-A) были полностью формально охарактеризованы в докторской диссертации G. Guizzardi и далее расширены в исследовательской группе по онтологии и концептуальному моделированию (NEMO) в Бразилии совместно с сотрудниками Бранденбургского технологического университета (Gerd Wagner) и Лаборатории прикладной онтологии (LOA). UFO-A был использован для анализа структурных концептуальных конструкций моделирования, таких как типы объектов и таксономические отношения, ассоциации и отношения между ассоциациями, роли, свойства, типы данных и зависимые сущности, а также парные отношения между объектами. Более поздние разработки включают в себя онтологию событий в UFO (UFO-B), а также онтологию социальных и интенциональных аспектов (UFO-C). Комбинация UFO-A, UFO-B и UFO-C использовалась для анализа, перепроектирования и интеграции эталонных концептуальных моделей в ряде сложных областей, таких как, например, моделирование предприятий, разработка программного обеспечения, нефтегазовая отрасль, телекоммуникации и биоинформатика.
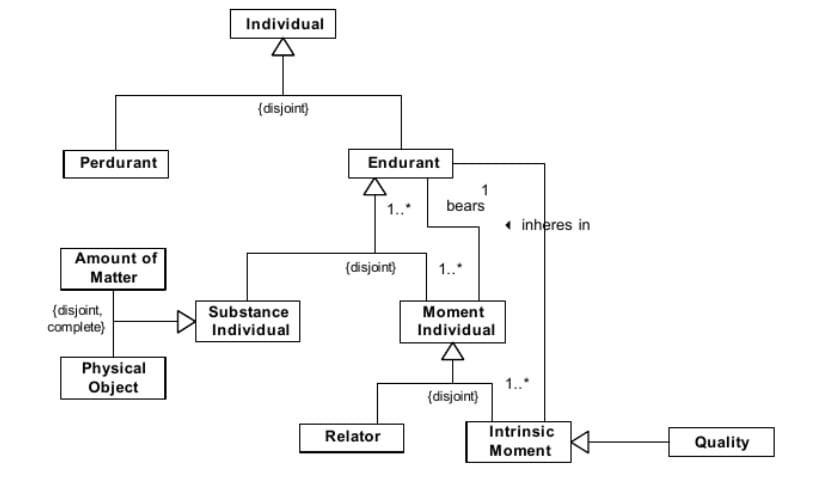
В основу онтологии положено понятие фундаментального различия между двумя категориями: Particular (Individual) и Universal (Type). Particulars - сущности, которые существуют в реальности и обладают уникальной индивидуальностью. Universals, наоборот, представляют собой шаблоны характеристик, которые могут быть представлены несколькими различными индивидуальностями (Particulars). В рамках фрагмента UFO-A также вводится понятие Substances - экзистенционально независимые индивидуальности (Particulars). Понятие Момент (Moment), напротив, обозначает индивидуализированное свойство/характеристику, которое не может существовать без других индивидуальностей. Отношения (Relations) - это сущности, которые соединяют другие сущности. Relators - индивидуальности, обладающие возможностью соединять другие сущности.
Описываемые в части UFO-A индивидуальные сущности объединяются общим понятием - Endurants. Endurants - сущности, которые не имеют промежуточного состояния. Если они присутствуют, то присутствуют целиком и полностью. В части UFO-B вводится еще одно обобщающие понятие - Perdurants (события), представляющее собой сущности, состоящие из временных частей. Они "случаются во времени" в том смысле, что они распространяются в течение времени, накапливая временные части. В отличие от Endurants, если Perdurant присутствует, то это еще не означает, что все его составляющие временные части также присутствуют. Основную категорию в онтологии UFO-B занимает концепт "Событие" (Event), он же Perdurant. События могут изменять реальность: в результате возникновения события реальность переходит от одной ситуации (предшествующей наступлению события) к другой (после наступления события). С одной стороны, события экзистенциально зависят от непосредственных участников данных событий, с другой стороны, события можно рассматривать с точки зрения временного аспекта и расширяющих его сущностей.
На третьем уровне онтологии UFO-С рассматриваются социальные сущности (Endurants и Perdurants). Вводятся понятия Agents (агенты) и Objects (объекты), которые представляют собой экзистенциально независимые индивидуальности, в первом случае - деятельные (агентивные), во втором случае - бездействующие, как правило, неодушевленные объекты. Агенты могут "нести" так называемые преднамеренные моменты (Intentional Moments). Каждый Intentional Moment имеет тип (например, Belief, Desire, Intention) и содержание (Proposition). Намерение - это тип интенциональности, называемый Intention. Содержание намерения (propositional content) - это цель (Goal). Два других типа интенциональности - намерение (Belief) и желание (Desire). Желание выражает стремление агента к определенному состоянию в реальности, тогда как намерение - желаемое состояние, для достижения которого агент готов выполнить какие-то действия. По этой причине намерения вынуждают агентов выполнять действия (Actions). Действия - это события, которые являются Instance некоторого плана (Plan), и имеют своей целью удовлетворение некоторого намерения. Примером атомарного действия является акт коммуникации (Communication Act), который может быть использовать для создания социальных моментов (Social Moments). Комплексное действие, для выполнения которого необходим вклад нескольких агентов, называется взаимодействием (Interaction).
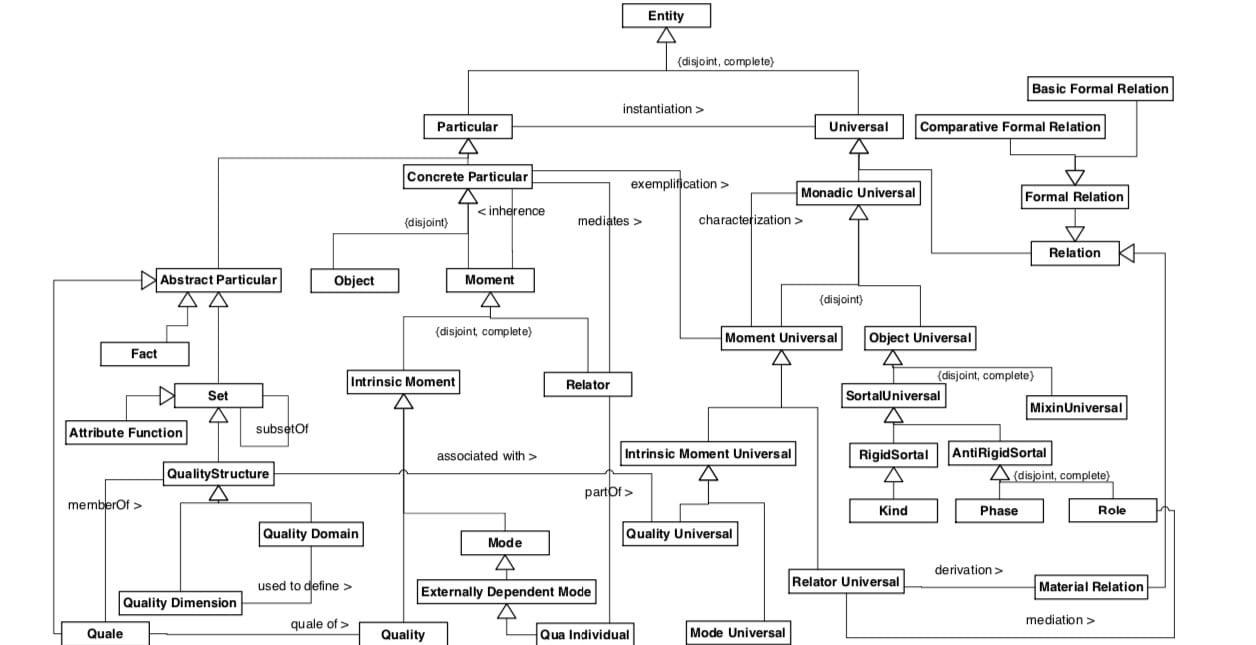
В целом, если оценивать концепцию представления объективной реальности в онтологии UFO, то можно отметить ее универсальность и преемственность. Многие юридические концепты могут быть описаны с помощью такой логики. Примечательно, что в научном сообществе еще в 2015 г. предлагались идеи адаптации UFO под правовую реальность путем разработки нового блока UFO-L, который бы детализировал существующую онтологию конкретными правовыми категориями. К сожалению, нам не удалось найти публикации о результатах таких экспериментов, однако перспективы успеха в данных начинаниях имеют место быть. UFO была объектом исследования в таких научных работах, как:
- Griffo, C., Almeida, J. P. A., & Guizzardi, G. A systematic mapping of the literature on legal core ontologies. Ontobras. In CEUR Workshop Proceedings: 1442. CEUR-WS.org, 2015;
- Rodrigues, C. M. O., Freitas, F. L. G., & Azevedo, R. R. An ontology for property crime based on events from ufo-b foundational ontology. 5th Brazilian conference on intelligent systems (bracis), 2016 и др.
2.1.5. FBO
Последней онтологией в данном обзоре является Frame-based ontologies (FBO), которая представляет собой совокупность онтологий, включающую в себя общую юридическую онтологию (нормы, акты, описания концептов) и онтологию, которая приобретает статус так называемой специфической онтологии. Различие основано на наблюдении, что некоторые части онтологии могут быть повторно использованы в различных правовых поддоменах.
Общая правовая онтология (GLO), в отличие от специфической онтологии, является универсальной и многоразовой частью онтологии. Она делит юридические знания на три отдельных объекта: нормы, акты и описания концептов. Для каждого из этих объектов онтология определяет шаблон (также называемый структурой кадра), в котором перечислены все атрибуты, относящиеся к объекту.
Нормы являются общими правилами, стандартами и принципами поведения, которые субъекты права обязаны соблюдать. В онтологии норма включает в себя следующие восемь элементов:
- идентификатор нормы (используется в качестве отправной точки для нормы);
- тип нормы (либо норма поведения, либо норма компетенции);
- обнародование (источник нормы);
- сфера охвата (сфера применения нормы);
- условия применения (обстоятельства, при которых применяется норма);
- субъект нормы (физическое или юридическое лицо, которому адресована норма);
- юридическая форма (должна, не должна, может, не может);
- идентификатор действия (используется в качестве ссылки на отдельное описание действия).
Акты представляют собой динамические аспекты, которые влияют на изменения в состоянии мира. В рамках категории актов существуют два различия. Первое различие между событиями и процессами. События представляют собой мгновенное изменение между двумя состояниями, в то время как процессы имеют продолжительность. Второе различие заключается между институциональными актами и физическими актами. Оно выражается в том, что первый тип актов рассматривается как правовые (институциональные) версии (физических) актов, которые происходят в реальном мире (институциональный акт - это юридическая квалификация физического акта). Предполагается, что все акты имеют следующие тринадцать элементов:
- идентификатор акта (используется в качестве отправной точки для акта);
- обнародование (источник описания акта);
- область действия (область применения описания акта);
- агент (физическое лицо, группа лиц, совокупность или конгломерат);
- тип акта (как базовые акты, так и действия, которые были указаны в другом месте);
- модальность средств (материальные объекты, используемые в акте);
- модальность манеры (способ, которым использовались объекты или выполнялись действия);
- временные аспекты (спецификация абсолютного времени, например, на первое августа, по воскресеньям, ночью и т. д., но не во время пожара, после смерти президента и т. д.);
- пространственные аспекты (указание места, где происходит акт);
- косвенные аспекты (описание обстоятельств, при которых происходит действие);
- причина действия (указание причины выполнить действие);
- цель действия (цель, визуализируемая агентом);
- намеренность действия (состояние ума агента);
- конечное состояние (результаты и последствия действия).
Концептуальные описания имеют дело со значениями понятий. Они могут быть определениями или определяющими положениями и могут использоваться для окончательного определения значения понятия, либо путем обеспечения необходимых и достаточных условий. Другим типом концепции является фактор, который может либо установить достаточное условие, либо указать некоторый вклад в применимость концепции. Наконец, существуют мета-концепции, которые являются положениями, регулирующими применение других положений.
Специфическая онтология состоит из предикативных отношений, которые используются в качестве дополнения к терминологии для норм, актов и описаний понятий. Специфическая онтология не может быть повторно использована для других юридических поддоменов, и ее всегда следует создавать для каждого рассматриваемого юридического поддомена. Специфическая онтология устанавливает словарный запас, с помощью которого создается база знаний. Ключевое различие между GLO и специфической онтологией состоит в следующем:
- различие между физическими актами и индивидуальными актами (юридическое - интерпретация физических актов, которые происходят в реальном мире);
- акцент на модальность действия, временные и пространственные аспекты и обстоятельства;
- представление объема, условий применения и правовой формы норм.
При оценке практической применимости онтологии FBO для целей юридической экспертизы мы приходим к выводам, что данная модель нацелена на структурирование и формализацию текстов нормативных актов с помощью GLO. Однако наличие специфической онтологии в ее составе позволяет выражать влияние норм права на субъекты и объекты материального мира, а именно какие действия субъектов и какое воздействие на объекты опосредованы и связаны с определенной нормой, содержащейся в тексте нормативного акта. Данное обстоятельно, безусловно, расширяет общую применимость FBO, но не для целей Legal AI, поскольку в последнем случае требуется глубокая детализация правовых концептов, а не правовых норм.
2.2. Результаты сравнения
В рамках обзора мы задались целью проанализировать и оценить юридические онтологии, которые создавались в разные периоды времени. В результате мы пришли к выводу, что общим для большинства данных моделей представления юридических знаний является их привязанность к описанию законов и норм. Они не описывают конкретные нормативные документы, а содержат универсальные концепты их представления. Многие из онтологий изначально создавались для концептуализации самой структуры нормативно-правовых актов и представления их содержания на языке семантической структуры.
Обзор представленных онтологий привел нас к выводу о том, что такие онтологии выполняют задачу обмена знаниями, поиска противоречий и дублирования норм, но никак не служат основой для формализации правовых знаний для систем юридического искусственного интеллекта.
Результаты сравнения и оценки правовых онтологий представлены в таблице ниже. Оценка производится на основе 5-бальной шкалы по 6 критериям.
1. Уровень детализации.
Данный критерий отражает степень детализации правовых категорий и терминов, с помощью которых в онтологии могут быть структурированы правовые знания. На данный критерий влияет количество классов в онтологии, а также количество и разнообразие связей. При этом значение имеют те классы и связи, которые позволяют выражать именно правовые знания, а не общие концепты объективной реальности. Оценка по данному критерию производится следующим образом:
- 0 - полное отсутствие необходимых классов и связей;
- от 1 до 2 - наличие общих классов и связей, позволяющих на абстрактном уровне отражать базовые юридические категории (например, организация, место и др.);
- от 3 до 4 - наличие системы специальных правовых классов и связей, позволяющих отражать юридические концепты;
- 5 - наличие развитой системы правовых классов и связей, позволяющих отражать юридическую картину мира в полной мере.
2. Возможность структурирования концептов отечественного права в текущей версии.
Данный критерий отражает возможность представления правоотношений в существующей в системе отечественного права при использовании исходной версии онтологии. Иными словами он отражает степень пригодности онтологии для права РФ. Оценка по данному критерию производится следующим образом:
- 0 - полная невозможность использования;
- от 1 до 2 - наличие общих классов и связей, которые могут быть использованы при определенных ограничениях и допущениях;
- от 3 до 4 - наличие системы специальных правовых классов и связей, позволяющих отражать некоторые отечественные концепты;
- 5 - полная совместимость с отечественным правом.
3. Возможность доработки под особенности отечественного права.
Данный критерий отражает степень привязанности структуры онтологии к определенной правовой системе и возможность ее модификации под особенности и характеристики права РФ. Оценка по данному критерию производится следующим образом:
- 0 - полное отсутствие возможности адаптации;
- от 1 до 2 - слабо выраженная возможность адаптации при сохранении существенных ограничений и допущений;
- от 3 до 4 - наличие возможности адаптации, которая требует значительной переработки структуры;
- 5 - возможность простой адаптации при незначительной доработке.
4. Логика и удобство использования.
Данный критерий отражает степень логичности существующей структуры онтологии и сложность ее восприятия и использования специалистом предметной области. Оценка по данному критерию производится следующим образом:
- 0 - отсутствие логики и сложность для восприятия;
- от 1 до 2 - наличие определенной логики построения онтологии, но сложность ее восприятия;
- от 3 до 4 - наличие выраженной и понятной логики, которая доступна специалисту предметной области при изучении онтологии;
- 5 - логичность структуры и простота восприятия.
5. Ширина охвата правоотношений.
Данный критерий отражает количество правоотношений, которое может быть структурировано в онтологии при существующей степени ее детализации. В отличие от первого критерия данная характеристика отвечает на вопрос: "Насколько онтология приближена к разнообразию реальных правоотношений?". Оценка по данному критерию производится следующим образом:
- 0 - полное отсутствие концептов для структурирования правоотношений;
- от 1 до 2 - наличие общих классов и связей, позволяющих на абстрактном уровне отражать базовые правоотношения;
- от 3 до 4 - наличие системы специальных правовых классов и связей, позволяющих отражать некоторые сложные правоотношения;
- 5 - наличие развитой системы правовых классов и связей, позволяющих отражать все разнообразие правоотношений.
6. Зависимость от изменений законодательства.
Данный критерий отражает степень привязанности онтологии к действующему в настоящий момент или на момент ее создания законодательству. Необходимость введения данного критерия обусловлена тем, что правовая система РФ, в отличие от многих зарубежных правовых систем, находится на стадии своего формирования и развития, в связи с чем достаточно часто принимаемые нормативные акты коренным образом изменяют и/или дополняют регулирование определенной группы отношений. Оценка по данному критерию производится следующим образом:
- 0 - строгая зависимость и необходимость полной переработки при изменении законодательства;
- от 1 до 2 - наличие сильной зависимости, которая требует различных изменений структуры онтологии при изменении законодательства;
- от 3 до 4 - наличие средней зависимости и необходимость изменения только при фундаментальных реформах;
- 5 - слабая зависимость и отсутствие необходимости модификации.
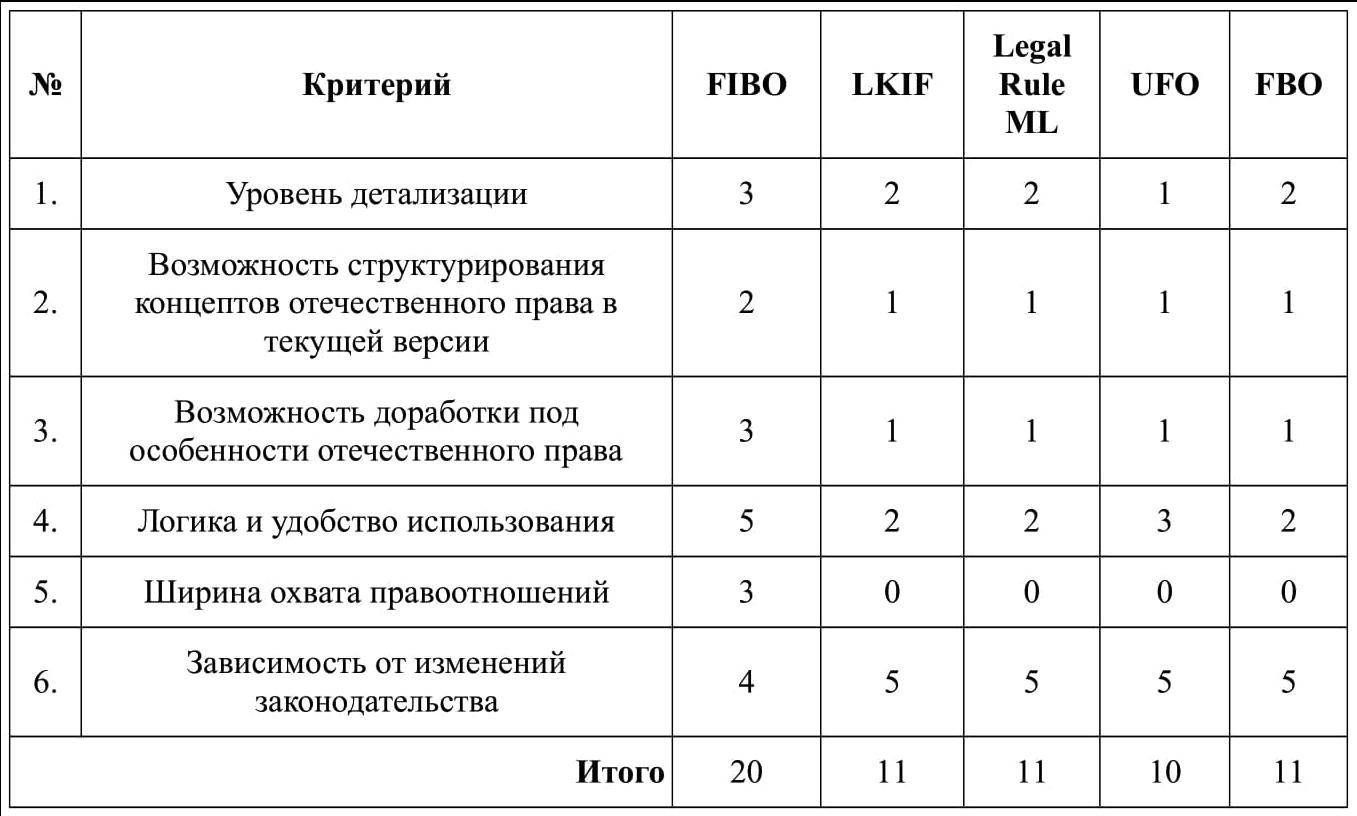
Онтологии LKIF, Legal Rule ML, FBO изначально создавались для представления текстов нормативных актов, поэтому по своей структуре они адаптированы под формализацию законов. Обладая высокой степенью абстракции, данные модели потенциально позволяют описать практически любой нормативный акт во многих его частях независимо от правовой системы. При этом верхнеуровневость онтологий не привязывает их к действующему законодательству, правовой системе и др., придавая им свойства универсальности и "reusable". Однако отсутствие возможности описать реальные правовые концепты, роль участников правоотношений, взаимосвязи и свойства субъектов, объектов права и др. не позволяет использовать их для Legal AI.
Исключением служат онтологии UFO и FIBO. UFO является универсальной моделью отражения отношений в любой области знаний, что потенциально позволяет использовать ее для юридической сферы. Однако к настоящему времени модуль UFO-L не разработан, поэтому оценивать эффективность UFO в области права невозможно. FIBO в значительной степени является практико-ориентированной финансовой онтологией, и ее эффективность в решении практических задач многократно подтверждена. Однако предметная область данной онтологии нацелена на отражение взаимоотношений в области финансов и бизнеса, что не позволяет применять ее к юриспруденции, поскольку данные сферы хотя и пересекаются, но имеют различное и самостоятельное содержание. Кроме того, уровень детализации в FIBO невысокий, что также ограничивает сферу ее применения.
Таким образом, мы приходим к выводу, что существующие онтологии в области права не подходят для решения задач Legal AI в силу низкого уровня детализации, нацеленности не на систематизацию правовых знаний, а на структурирование нормативных актов, уникальности правовых систем и невозможности создания универсальной юридической онтологии для применения во многих странах. Данный вывод свидетельствует о необходимости самостоятельного создания юридической онтологии (графа знаний), который бы соответствовал практическим потребностям Legal AI и правовому полю РФ.
И здесь напрашивается очевидный вопрос: "Какие подходы и критерии следует использовать для создания необходимой базы юридических знаний?".
В качестве примера онтологии, которая, по нашему мнению, является эталонной моделью структурирования знаний, хотелось бы привести онтологию объектов культурного наследия CIDOC CRM (Committee on Documentation "Conceptual Reference Model").
CIDOC CRM разработана рабочей группой по стандартизации документации комитета CIDOC и специализированной рабочей группой. Она представляет собой формальную онтологию, предназначенную для улучшения интеграции и обмена гетерогенной информацией по культурному наследию и является онтологией верхнего уровня для данной предметной области. Если рассматривать более конкретно, CIDOC CRM определяет семантику схем баз данных и структур документов, используемых в культурном наследии и музейной документации, в терминах формальной онтологии. Модель не определяет терминологию, используемую в конкретных структурах данных, но имеет характерные отношения для ее использования. Она не стремится предлагать то, что должны документировать учреждения культуры, но объясняет логику того, что они фактически документируют и представляют семантическую интероперабельность между музеями, библиотеками, архивами. В настоящий момент онтология используется в ряде крупных проектов, таких как MIDAS XML, IST Project SCULPTEUR, IST Project I-Mass и др.
Модель может служить как руководством для разработчиков информационных систем, так и общим языком для экспертов предметной области и специалистов по информационным технологиям, чтобы сформулировать требования к информационным системам и служить руководством для надлежащей практики концептуального моделирования. Она предназначена для покрытия контекстной информации исторического, географического и теоретического характера об отдельных экспонатах и музейных коллекциях в целом.
Структурно CIDOC CRM состоит из иерархии классов и широкого набора свойств (бинарных отношений), связывающих классы между собой. Версия 5.0.1 CIDOC CRM содержит 82 класса и 142 свойства, связывающих классы между собой и описывающих предметы, понятия, людей, события, место, время и их отношения. Все концепты (классы и свойства) модели можно разделить на три группы.

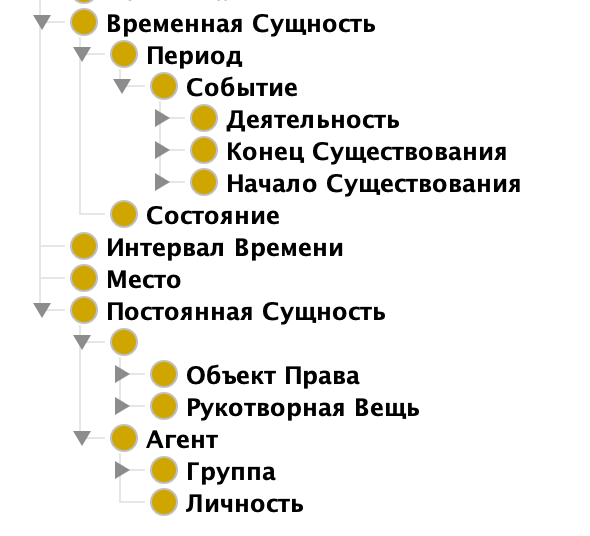
Первая группа включает классы и отношения, охватывающие наиболее общие понятия окружающего мира: постоянные и временные сущности, отношения участия, зависимости, совпадения во времени.

Вторая группа содержит понятия, частично поддерживающие функции управления: приобретение и учет единиц хранения, передача прав собственности на объекты культуры. К третьей группе относятся классы и свойства, используемые для внутренней организации самой онтологии: средства, необходимые для подключения внешних источников терминов, например, тезаурусов по отраслям культуры. Иерархия классов модели CIDOC CRM делится на 2 ветви: Постоянные сущности и Временные сущности. Прочие классы являются вспомогательными. На самых нижних уровнях иерархии классов появляются понятия, характерные для сферы культуры: "Хранение", "Перемещение (ценностей)", "Проект или Процедура" (в том числе техника производства), "Период" (в том числе художественный стиль). Иерархия классов может быть гибко расширена с применением встроенного класса "Тип".
Наибольший интерес представляют свойства. Классы на нижних уровнях иерархии имеют около 10-15 свойств, причем большая часть свойств наследуется от классов-родителей. Названия свойств представляют собой глагольные фразы, выбранные так, что при последовательном связывании двух классов свойством получается осмысленная фраза с субъектом, предикатом и объектом. Отличительным свойством данной онтологии является то, что она не преследует цель описать документы музейных экспонатов или сами объекты культурного наследия. Онтология воспроизводит свойства и отношения таких объектов, позволяя описать всю полноту характеристик любых музейных экспонатов в универсальном и формализованном формате. Именно такими свойствами, по нашему мнению, должна обладать юридическая онтология.


Отдельно хотелось бы отметить необходимость использования Ontology Design Patterns. Моделированием онтологий научное сообщество занимается уже не один десяток лет, и за данный продолжительный период времени были разработаны многочисленные концепты, которые нашли свое успешное применение в различных моделях знаний и сферах. Дело в том, что несмотря на различия предметных областей (право, финансы, медицины, культура и др.), внутри них существует много общего. Концептуальные отношения между объектами (часть и целое, принадлежность, зависимость и др.) мы встречаем в любой области знаний. Кроме того, даже в каждой узкоспециализированной онтологии нельзя обойтись без моделирования общих категорий, позволяющих отражать те или иные состояния действительности. Речь идет, например, о времени, событиях и др. Так, существует некоммерческий проект ODPA (Ontology Design Patterns), который предлагает использовать выработанные и универсальные концепты записи отдельных объектов и категорий в онтологическом формате, которые позволяют улучшить методологию и повысить эффективность создаваемой онтологии.
2.3. Автогенерация онтологий
В предыдущей публикации мы упоминали в качестве альтернативной методологии построения моделей знаний автогенерацию онтологии. Автоматическая генерация онтологий представляет собой процесс формирования онтологии предметной области на основе обучающей выборки документов в автоматическом режиме с последующей ручной корректировкой отдельных понятий и связей. Основным аргументом сторонников данного подхода является то, что моделирование юридической онтологии в ручном режиме потребует многолетней работы, а существующий инструментарий по извлечению данных из текста и их пост-обработки позволит сгенерировать части необходимой онтологии с минимумом временных затрат. Мы выступаем против данного подхода, поскольку для построения юридической онтологии и графов автогенерация не применима, и тому есть несколько подтверждений.
Во-первых, ранее мы говорили о том, что ключевое значение в юридической онтологии имеют связи, поскольку именно они отражают множественные отношения между классами. Онтологии и графы, создаваемые для Legal AI, должны иметь в совокупности сотни и тысячи связей для решения даже простых юридических задач. Если воспользоваться математической формулой полного графа n*(n-1)/2, где n - количество задействованных классов, вершин, мы приходим к выводу, что необходимое количество связей на порядок превышает количество необходимых классов. При автогенерации онтологии на выходе мы получаем крайне скудный набор связей, которого явно недостаточно для полноценного описания юридической картины мира. В частности, среди всего многообразия отношений при автогенерации онтологии мы получаем только отношения принадлежности (is-a, subclass of).
Во-вторых, существует проблема в источнике данных для генерируемой онтологии: не существует такого набора документов, который бы наиболее полно и целостно описывал непосредственную юридическую жизнь (legal practice). Использование текстов нормативных актов и судебных решений - метод, который, на наш взгляд, заведомо обречен на неудачу, поскольку, как мы уже упоминали ранее, законы и судебная практика несут в себе не более 30% всех правовых знаний.
Кроме того, цена ошибки в данном случае слишком высока. Даже тексты существующих судебных решений в полной мере не отражают смысловое содержание нормативных актов и реальную юридическую практику. Например, процедуре принятия искового заявления арбитражным судом посвящено 6 статей АПК РФ (ст. 125-129 АПК РФ). Однако при построении графа, отражающего данную процедуру и отвечающего только на два вопроса (может ли данное исковое заявление быть принято к производству арбитражным судом, и какой судебный состав уполномочен рассматривать данное исковое заявление), данных статей было недостаточно для выполнения поставленной задачи. На множество вопросов тексты нормативных актов (не только АПК РФ, но и судебные регламенты, судебная практика и др.) не дают ответов, поэтому необходимо руководствоваться опытом практикующих юристов, который документально нигде не оформлен.
В-третьих, если обратиться к предыдущим рассуждениям о иерархической структуре знаний (пирамида Рассела Акоффа), в которой выделяются data (неструктурированные, разрозненные данные), information (структурированные данные, информация), knowledge (знания) и wisdom (мудрость), то становится очевидным тот факт, что инструменты ML и DL работают на 90 % с неструктурированными данными и только на 10% с информацией. Однако ценные знаний и опыт предметной области находятся на уровнях knowledge и wisdom, которые существуют только в сознании экспертов соответствующей области знаний.
Суммарно данные факторы объясняют отсутствие успешных попыток автоматической генерации онтологий.
Также важно понимать, что концепция машинного обучения исходит из попыток создать инструмент, который получает исходные данные, а на выходе выдает правильный результат. В случае с автогенерацией правовой онтологий применение машинного обучения - это попытка создать end-to-end решение, которое на основе выборки текста (законов, судебных решений и др.) смоделирует необходимую концептуальную модель знаний. Однако в силу высокой сложности данной задачи и необходимости зайдействовать common sense такой подход при нынешнем уровне развития технологий представляется тупиковым.
3. Заключительные положения
В результате обзора существующих онтологий мы приходим к главному выводу: если для зарубежных правовых систем существуют различные варианты готовых решений, которые в разной степени соответствуют потребностям Legal AI, то для отечественной системы права моделей юридических знаний не существует вовсе. Причин тому множество, одной из них является отсутствие значительных государственных инвестиций в развитие данного направления. А ведь создание структурированной юридической картины мира в формате графа знаний позволит решить наиболее сложную задачу при разработке Legal AI - обеспечить искусственный интеллект логикой и знаниями эксперта соответствующей предметной области. Без решения данной задачи невозможно создать программный инструмент, способный генерировать суждения и умозаключения по итогам анализа определенных входных данных (reasoning). Именно поэтому следующим важным шагом после реализации инструментов лингвистической обработки текста является построение графа знаний юридической области, основанного на отражении объективной юридической реальности.
Сегодня в проектах по развитию систем искусственного интеллекта основной фокус сосредоточен на ML и DL. Однако, как мы отмечали ранее, все машинное обучение работает на уровне неструктурированых данных (data) - уровне Asscoation, что не позволяет перейти к решению интеллектуальных и сложных практических задач, связанных с полноценной цифровой экспертизой. Для создания настоящего цифрового эксперта требуется переход на следующие уровни - knowledge (знания) и wisdom (мудрость). Перейти на данные уровни позволит, по нашему мнению, создание графа знаний юридической области, который станет основой Legal AI.
Помимо этого важно понимать взаимосвязь между инструментами и технологиями, применяемыми для создания Legal AI. Само по себе создание онтологий и графов знаний не имеет практического смысла без разработки инструментария для процессинга текста на естественном языке. Модели представления знаний служат источником логики предметной области и позволяют генерировать суждения и умозаключения на ее основе. Однако входными данными для них являются результаты лингвистической обработки текста. Чтобы запустить reasoning, необходимо задать необходимые instances в онтологии, определить их исходные свойства, атрибуты, что без семантического анализа текста на естественном языке сделать невозможно.