
Высокая производительность Web-приложений зависит от эффективных баз данных, которые могут быстро обрабатывать запросы и извлекать их результаты. В статье описан анализ событий ожидания в Oracle для повышения производительности. В ней также демонстрируется использование системных утилит для эффективного сбора и анализа статистики производительности базы данных Oracle с целью определения проблем.
Мониторинг производительности базы данных и анализ событий ожидания
Чтобы повысить производительность СУБД Oracle, необходимо проанализировать события ожидания Oracle, чтобы определить узкие места и настроить параметры базы данных. Повышение эффективности обработки в базе данных Oracle повышает производительность всех систем и приложений, использующих эту базу данных. В статье демонстрируется использование системных утилит для эффективного сбора и анализа статистики производительности базы данных Oracle с целью определения проблем.
На производительность базы данных Oracle влияет множество факторов. В частности, существенное влияние на производительность оказывают факторы, перечисленные ниже.
Неэффективные SQL-операторы негативно влияют на производительность
При создании SQL-операторов имейте в виду, что они могут существенно повлиять на производительность запросов. Чем конкретнее оператор, тем быстрее будет получен результат. Предположим, нужно просмотреть информацию о конкретном сотруднике employee1 с идентификатором employee_id, равным 123, из таблицы employee. Таблица employee содержит столбцы employee_name, employee_sal и employee_id, где employee_id является первичным ключом. Рассмотрим следующие варианты в порядке повышения эффективности:
- С помощью запроса
select * from employee, извлекаем все записи из таблицы. Находим в результатах конкретного работника. Если результат запроса содержит много записей, этот процесс будет медленным. - Используем запрос
select * from employee where employee_name='employee1'. Этот оператор сужает поиск и ускоряет процесс. - Используем запрос
select * from employee where employee_id=123. Посколькуemployee_idявляется первичным ключом, этот запрос будет самым быстрым
Чтобы создать наиболее эффективный SQL-оператор, используйте следующие рекомендации:
- Избегайте запросов, которые не содержат условий
whereи первичных ключей. - Большое количество запросов delete со временем приводит к росту несвязных блоков данных. Оператор delete только удаляет данные из блока, но не освобождает блок данных для дальнейшего использования. Поскольку операторы delete не снижают верхнюю границу заполнения, общий объем данных, в которых будут выполнять поиск будущие запросы, не уменьшается. Используйте оператор truncate, где это возможно, поскольку он сбрасывает верхнюю границу заполнения.
- Используйте операторы
COMMITтолько в случае необходимости. Избегайте их частого использования, поскольку они инициируют очистку буфера, что может привести к чрезмерному количеству операций ввода/вывода.
Неэффективная конфигурация базы данных негативно влияет на производительность
Неумелое конфигурирование негативно влияет на производительность базы данных. Конкретные параметры инициализации и конфигурации базы данных влияют не только на конфигурацию запуска, но и на обработку запросов. На производительность могут повлиять в сторону ухудшения приведенные ниже параметры (если они не настроены оптимальным образом).
Параметр PCTFREE
Параметр PCTFREE устанавливает минимальный процент резервирования свободного пространства блока для возможных обновлений строк, уже существующих в этом блоке. Слишком низкое значение PCTFREE может вызвать проблемы при обновлении. Слишком высокое значение может привести к неэкономному использованию пространства и вызвать избыточное перемещение блоков данных.
Параметр PCTUSED
Параметр PCTUSED устанавливает минимальный процент использования блока для данных в строках и накладных расходов на добавление в блок новых строк. После заполнения блока данными до предела, определенного параметром PCTFREE, Oracle считает блок недоступным для вставки новых строк, пока процент не опустится ниже значения параметра PCTUSED. До достижения этого порога Oracle использует свободное пространство блока данных только для обновления строк, уже содержащихся в блоке.
Неадекватное выделение памяти System Global Area (SGA) негативно влияет на производительность
Системная глобальная область (System Global Area - SGA) представляет собой группу общих структур памяти, содержащих данные и управляющую информацию для одного экземпляра базы данных Oracle. Пользователи, одновременно подключившиеся к одному и тому же экземпляру, совместно используют данные в SGA экземпляра. Поэтому SGA иногда называют общей глобальной областью. Для обеспечения эффективной производительности базы данных необходимо определить оптимальный размер памяти SGA и настроить ее соответствующим образом. Слишком маленькая память может существенно снизить производительность базы данных.
События ожидания негативно влияют на производительность
События ожидания происходят во время обработки запросов. Запрос чтения/записи к базе данных Oracle вызывает несколько процессов. Эти процессы могут столкнуться с проблемами оборудования, программного обеспечения, операционной системы или конфигурации, что приведет к остановке или замедлению обработки. Такие блокирующие факторы называются событиями ожидания. Для эффективной работы базы данных необходимо свести к минимуму использование операторов wait. Следует проанализировать все выполняющиеся операторы wait и исправить их, если время ожидания слишком велико. Однако полностью устранить все события ожидания невозможно.
Oracle Database 11g имеет более 1000 событий ожидания, которые могут привести к задержкам обработки запроса. Эти события ожидания принято делить на следующие группы:
- Cluster (кластер)
- Network (сеть)
- Administration (администрирование)
- Configuration (конфигурация)
- Commit (фиксация)
- Application (приложение)
- Concurrency (параллелизм)
- System I/O (системный ввод/вывод)
- User I/O (пользовательский ввод/вывод)
- CPU (процессор)
Использование Oracle Enterprise Manager для анализа событий ожидания
Для мониторинга событий ожидания при обработке данных используется Oracle Enterprise Manager (OEM). OEM графически отображает состояние базы данных во время обработки. Он также предоставляет подробный аналитический отчет, в котором можно перейти к каждому событию и найти соответствующие SQL-операторы (см. рисунок 1). В легенде справа показаны типы событий ожидания.
Рисунок 1. Пример снимка экрана Oracle Enterprise Manager
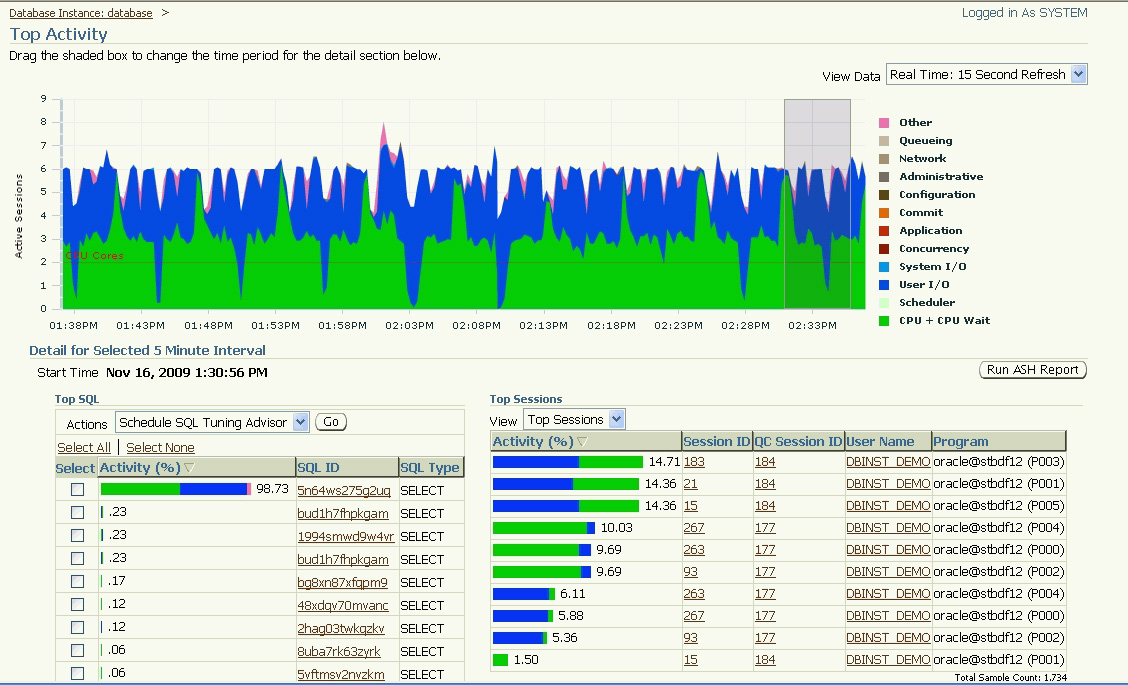
(Исходное изображение опубликовано на сайте docs.oracle.com в 2011 г. по адресу: http://docs.oracle.com/cd/E11857_01/em.111/e11982/database_management.htm.)
На рисунке 2 показано детальное представление ожидания типа User I/O для данных, использованных в рисунке 1. Нажмите User I/O в OEM, чтобы перейти на страницу сведений о событиях ожидания типа User I/O.
Рисунок 2. Ожидание активных сеансов
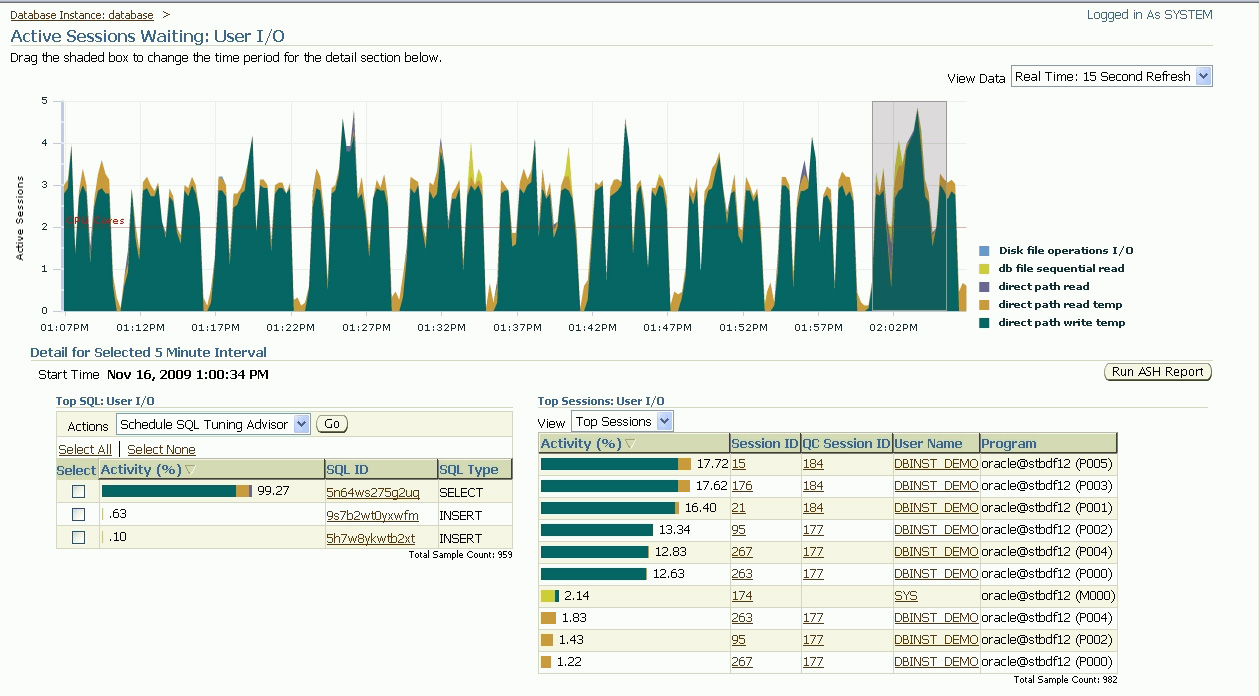
Анализ событий ожидания с помощью shell-сценария
Можно собрать статистику событий ожидания базы данных Oracle без использования инструментальных средств, воспользовавшись shell-сценарием и встроенными системными утилитами. Чтобы собрать и проанализировать статистику для выявления источника узких мест и исправления проблем при поддержке администратора базы данных, необходимо выполнить приведенные ниже шаги.
Подготовка данных
Необходимо подготовить достаточное количество данных, поскольку база данных будет работать в течение нескольких часов или всю ночь. Зачастую много времени занимает обнаружение проблем кэша, которые могут не проявиться в течение нескольких первых часов работы базы данных. Нагрузка на базу данных должна имитировать производственные условия. Необходимо обеспечить такую смесь данных, чтобы запросы содержали выполняемые в режиме реального времени операции вставки, обновления, удаления и усечения. Для каждого элемента синтаксиса языка манипулирования данными (DML) используются разные источники, поэтому нужно сделать набор данных аналогичным или близким к данным производственной среды.
Шаг 1. Создание сценария
Чтобы получить подробную информацию и SQL-операторы для событий ожидания в представлениях V$ACTIVE_SESSION_HISTORY, V$EVENT_NAME и V$SQLAREA, создайте простое соединение трех таблиц.
V$ACTIVE_SESSION_HISTORY- Отображает активность сеансов в базе данных. В нем содержатся ежесекундные снимки активного сеанса базы данных.
V$EVENT_NAME- Отображает информацию о событиях ожидания.
V$SQLAREA- Отображает статистику для общей SQL-области, содержит одну строку для каждого SQL-выражения. Предоставляет статистику по SQL-операторам, которые находятся в памяти, проанализированы и готовы к выполнению.
Поскольку данные в этих представлениях периодически очищаются, используйте сценарий, приведенный в листинге 1, для сбора данных через одинаковые промежутки времени.
Листинг 1. Сценарий gather_event_stats.sh для периодического сбора данных
#!/bin/sh
echo "Collecting the wait events statistics $1 times at an interval of $2"
# Создание отметок времени в поддерживаемом Oracle формате
curr_date=`date '+%d-%b-%y' / tr '[:lower:]' '[:upper:}'
curr_time=`date +%H.%M.%S`
start_time="$curr_date $curr_time"
outfile_name=Events_output_$curr_date $curr_time
# Ожидание для указанного интервала
sleep $2
# Выполнение указанного числа итераций
for((i=1;i<=$1;i++))
do
curr_date=`date '+%d-%b-%y' / tr '[:lower:]' '[:upper:}'
curr_time=`date +%H.%M.%S`
end_time="$curr_date $curr_time"
# Динамическое создание sql-файла для получения данных в нужном формате.
echo "">sql
echo "SET HEADING OFF;">>sql 2>/dev/null
echo "SET FEEDBACK OFF;">>sql 2>/dev/null
echo "SET PAGESIZE 0;">>sql 2>/dev/null
echo "SET LINESIZE 1500;">>sql 2>/dev/null
echo "SET ECHO OFF;">>sql 2>/dev/null
echo "SET VERIFY OFF;">>sql 2>/dev/null
echo "SET MARKUP HTML OFF;">>sql 2>/dev/null
# Указание " ~ " в качестве разделителя столбцов
echo "SET CLOSEP '~';">>sql 2>/dev/null
# Создание запроса, соединяющего все три таблицы, для получения события ожидания, времени ожидания и SQLID.
echo "SELECT TRIM(A.SAMPLE_TIME),TRIM(C.SQL_TEXT),TRIM(B.NAME),COUNT(*), SUM(TIME_WAITED) FROM v\$ACTIVE_SESSION_HISTORY A,v\$EVENT_NAME B,v\$SQLAREA C WHERE to_char(A.SAMPLE_TIME, 'DD-MON-YY HH24.MI.SS')BETWEEN '"$start_time", AND '"$end_time"' AND A.EVENT=B.NAME AND A.SQL_ID = C.SQL_ID GROUP BY A.SAMPLE_TIME, C.SQL_TEXT, B.NAME ORDER BE 1 ASC:" >>SQL
# Подключение к Oracle с помощью sqlplus и выполнение sql-файла. Добавление результатов в файл
sqlplus ORACLEID/PASSWORD@ORADBNAME< sql >> $outfile_name
2>/dev/null
# Ожидание для $2 в течение минут/часов/дней
sleep $2
start_time="$end_time"
# Очистка sql-файла для создания нового запроса с измененными отметками времени.
echo "">sql
done
Чтобы данные, собранные в текстовый файл, можно было представить с помощью электронных таблиц (например, Microsoft Excel) и в дальнейшем проанализировать, в качестве разделителя столбцов используется символ тильды (~). Этот сценарий создает SQL-файл через одинаковые промежутки времени, выполняет SQL-выражения для сбора данных и помещает статистику в текстовый файл
$outfile_name .
Шаг 2. Запуск сценария
Разместите сценарий на любом сервере приложений и выполните сценарий для сбора данных. В приведенном ниже коде перед вызовом сценария замените переменные ORADBNAME, ORACLEID, PASSWORD соответствующими значениями.
Примечание. Эти значения можно сделать параметрами и передать в сценарий во время выполнения.
Для выполнения сценария используйте следующий синтаксис:
Запустите сценарий до загрузки данных и не останавливайте его, пока загрузка данных не завершится. При выполнении сценария тщательно подберите значения No.Of.Iterations ($1) и Interval ($2) для выражения No.Of.Iterations x Intervals = Test Duration (Число итераций х интервалы = продолжительность теста).
Чтобы убедиться, что сценарий запущен, выполните следующую команду:
Шаг 3. Обработка данных
Введите данные и убедитесь, что приложение обрабатывает данные. Проверьте еще раз, что данные загружаются в базу данных. Подождите, пока не будут обработаны все данные. Выведите файл $outfile_name (имя файла, в который помещаются выходные данные запроса; в нашем случае - статистика событий ожидания) через одинаковые промежутки времени и убедитесь, что размер файла растет.
Шаг 4. Анализа данных и настройка базы данных
- После завершения обработки данных и выполнения сценария gather_event_stats.sh загрузите выходной файл
$outfile_name из машины Unix в машину Windows.
- Откройте файл в текстовом редакторе. Если в этом файле есть символы табуляции или дополнительные пробелы, замените их одним пробелом, прежде чем загрузить файл в электронную таблицу Excel. На рисунке 3 показано, как выглядят загруженные данные в редакторе Notepad.
Рисунок 3. Снимок экрана с исходными данными в текстовом файле
$outfile_name из машины Unix в машину Windows.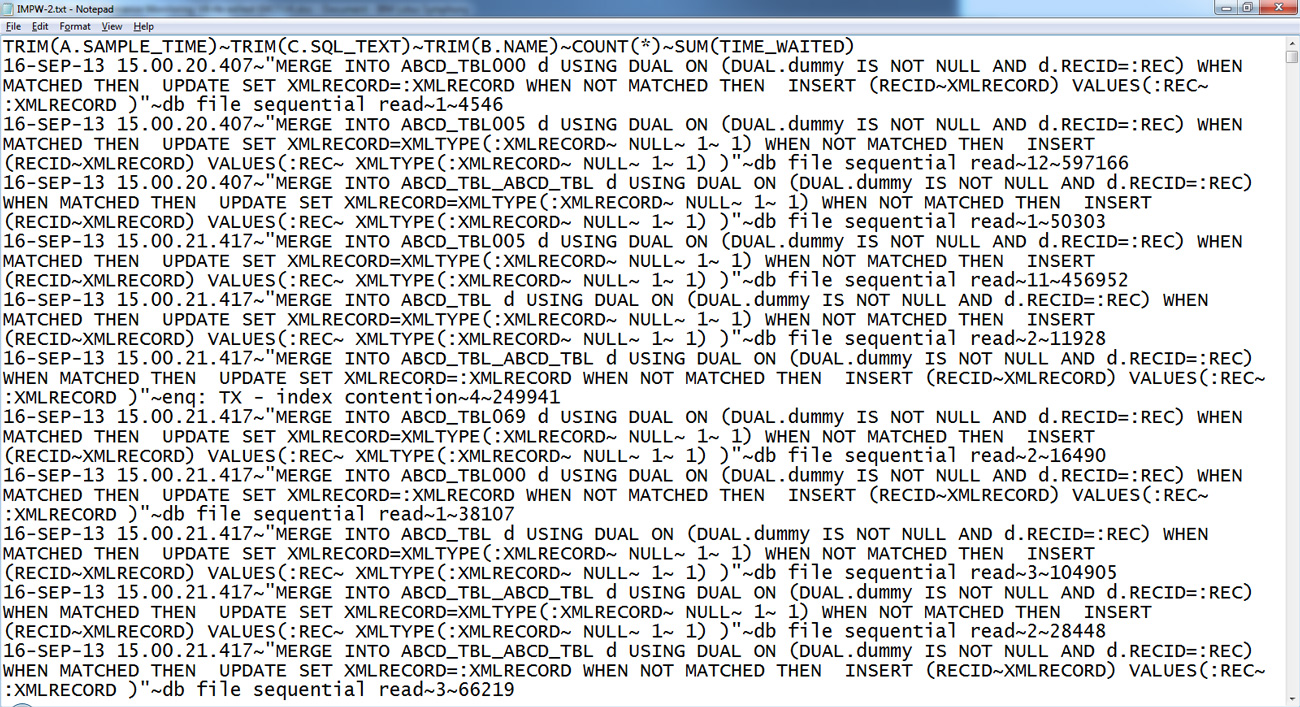
- Импортируйте данные в электронную таблицу Excel, выбрав Data > Convert Text to Columns. Укажите символ тильды (~) как разделитель данных в столбцах (см. рисунок 4).
Рисунок 4. Снимок экрана с данными событий ожидания после разделения в Excel с помощью разделителя ~
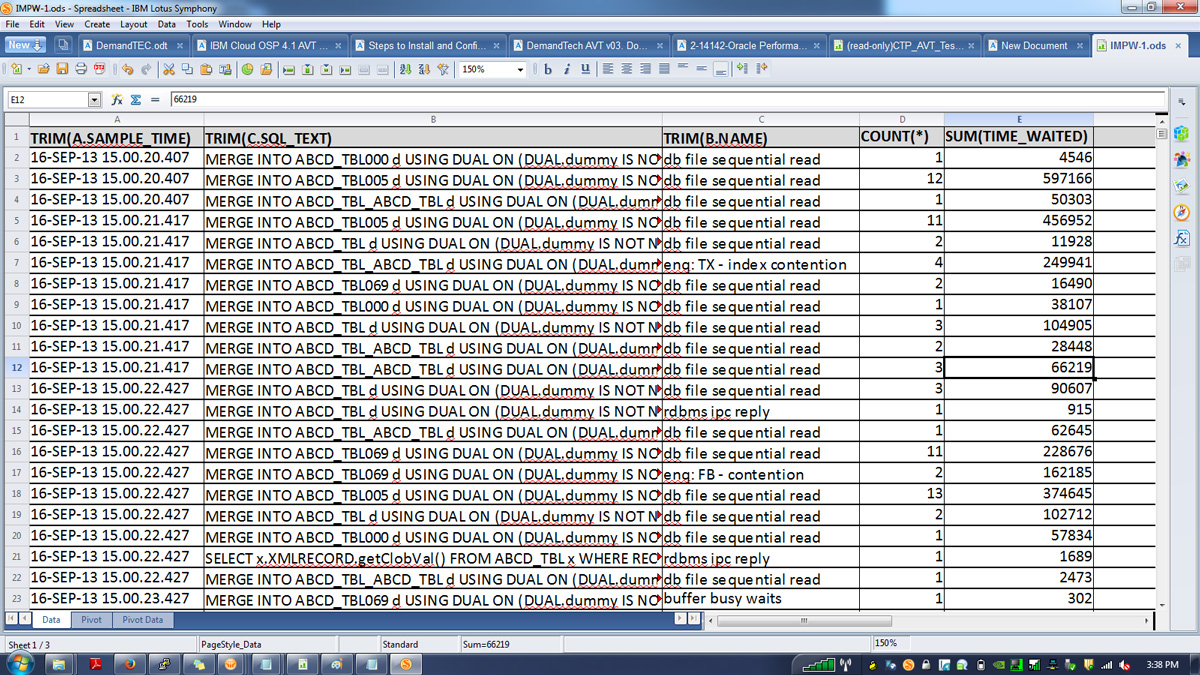
- На основании этих данных создайте сводную таблицу, чтобы получить сумму общего времени ожидания для каждого события. Единицей времени является одна сотая секунды, поэтому делите значение на 100, чтобы преобразовать его в секунды. После создания отсортируйте сводную таблицу, чтобы определить событие с максимальным временем ожидания (см. рисунок 5).
Рисунок 5. Снимок экрана сводной таблицы
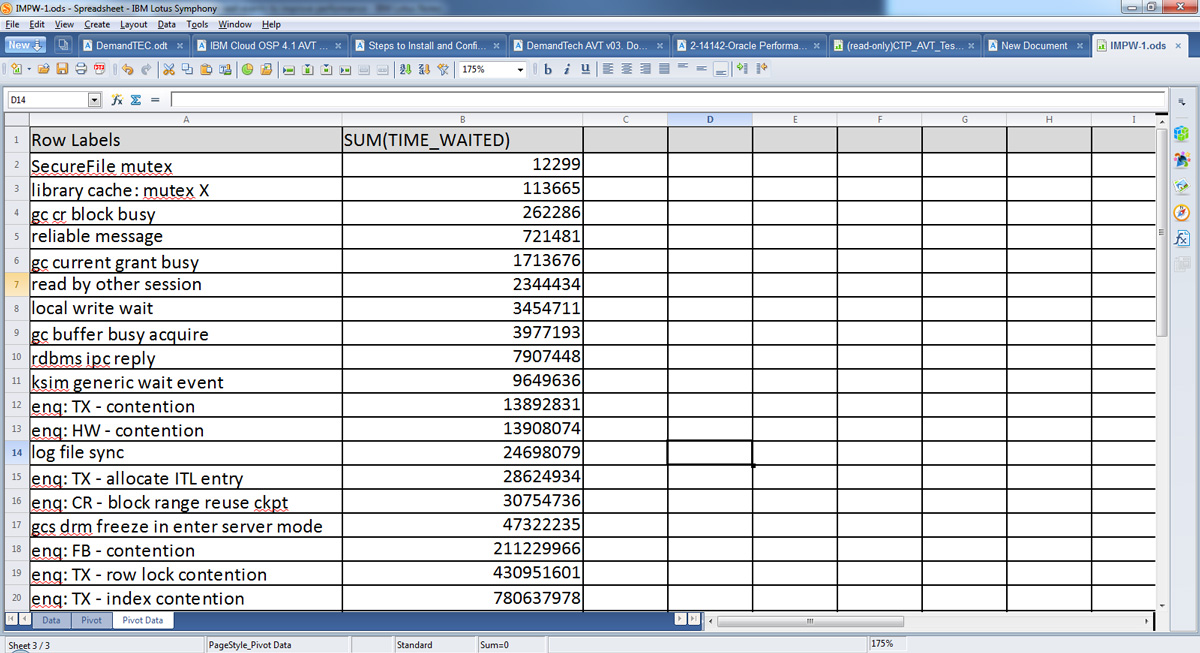
- Проанализируйте событие ожидания с помощью администратора базы данных Oracle, чтобы понять причину этого события. В нашем примере событием с наибольшим временем ожидания является
TX - index contention. Это говорит о наличии проблемы индексирования при обработке транзакций. - Получите
SQLIDдля операторов wait с наибольшим временем ожидания и проверьте соответствующие SQL-операторы. В полеC.SQL_TEXTуказывается SQL-оператор для каждогоSQLID. Обратитесь к разработчикам и администратору базы данных, чтобы определить возможность настройки SQL-операторов для сокращения времени ожидания. - Повторите пункт 6 для каждого из 10 событий с наибольшим временем ожидания.
- Реализуйте решения, предложенные разработчиками и администратором базы данных, для устранения этих событий ожидания.
- Снова выполните этот тест с той же нагрузкой и с той же продолжительностью, чтобы убедиться в уменьшении времени ожидания или полном устранении события ожидания.
Заключение
В этой статье описывается один из способов сбора статистики о событиях ожидания для базы данных Oracle. Процесс очень прост и не требует никаких специальных инструментов. Этот метод применим для анализа и решения проблем производительности базы данных для продуктов IBM, интегрированных с серверными базами данных Oracle.