

Данная статья составлена по материалам практики по курсу операционных систем в Академическом университете . Материал готовился для студентов, и ничего сложного здесь не будет, достаточно базового знания командной строки, языка C, Makefile и общих теоретических знаний о файловых системах.
Весь материал разбит на несколько частей, в данной статье будет описана вводная часть. Я коротко расскажу о том, что понадобится для разработки в ядре Linux, затем мы напишем простейший загружаемый модуль ядра, и наконец напишем каркас будущей файловой системы - модуль, который зарегистрирует довольно бесполезную (пока) файловую систему в ядре. Люди уже знакомые (пусть и поверхностно) с разработкой в ядре Linux не найдут здесь ничего интересного.
Введение
Файловая система является одной из центральных подсистем ОС. Развитие файловых систем шло вместе с развитием ОС. На настоящий момент мы имеем целый зоопарк самых разнообразных файловых систем от старой "классической" UFS , до новых интересныхNILFS (хотя идея совсем не новая, посмотрите на LFS ) и BTRFS . Так что, можно сказать, теория и практика создания файловых систем вполне проработаны. Мы не будем пытаться свергнуть монстров вроде ext3/4 и BTRFS, наша файловая система будет носить исключительно образовательный характер, на ее примере мы будем знакомиться с ядром Linux.
Настройка окружения
Перед тем как лезть в ядро, подготовим все необходимое для сборки нашего модуля файловой системы. У каждого свои предпочтения в дистрибутивах Linux, но мне привычнее использовать Ubutnu, поэтому настройку окружения я буду показывать на ее примере, к счастью это совсем не трудно. Для начала нам понадобятся компилятор и средства для сборки:
sudo apt-get install gcc build-essential
Дальше нам понадобятся исходники ядра, или не понадобятся. Мы пойдем простым путем - не будем пересобирать ядро из исходников, просто установим себе заголовки ядра, этого будет достаточно, чтобы написать загружаемый модуль. Установить заголовки можно так:
sudo apt-get install linux-headers-`uname -r`
Тут я должен сделать небольшое лирическое отступление. Ковыряться в ядре на рабочей машине не самая удачная идея, поэтому настоятельно советую проделывать это все в виртуальной машине. Мы не будем делать ничего опасного, так что сохраненные данные в безопасности, но если
что-то пойдет не так, вероятно придется перезагружать систему, а это довольно быстро надоедает. Кроме того отлаживать модули ядра удобнее в виртуальной машине (такой как QEMU), хотя этот вопрос не будет рассмотрена в этой статье.
Проверяем окружение
Чтобы проверить окружение напишем и запустим модуль ядра, который не будет делать ничего полезного (Hello, World!). Посмотрим на код модуля, я его назвал super.c (не подумайте ничего, super это от superblock):
#include <linux/init.h> #include <linux/module.h> static int __init aufs_init(void) { pr_debug("aufs module loaded\n"); return 0; } static void __exit aufs_fini(void) { pr_debug("aufs module unloaded\n"); } module_init(aufs_init); module_exit(aufs_fini); MODULE_LICENSE("GPL"); MODULE_AUTHOR("kmu");
В самом начале идут два заголовка, считайте, что они обязательная часть любого загружаемого модуля ядра, ничего интересного в них нет. Далее идут две функции aufs_init и aufs_fini - они будут вызваны после загрузки и перед выгрузкой модуля соответственно.
Некоторых из вас может смутить метка __init. __init это подсказка ядру, что функция используется только во время инициализации модуля, а значит, после инициализации модуля эту функцию можно выгрузить из памяти. Аналогичный маркер есть и для данных, впрочем, ядро вполне может игнорировать эти подсказки. Обращение к __init функциям и данным из основного кода модуля это потенциальная ошибка, поэтому во время сборки модуля проверяется, что таких обращений нет. Если же такое обращение найдено, система сборки ядра выдаст предупреждение. Аналогично проверка делается для __exit функций и данных. Если вам интересны детали того, что из себя представляют __init и __exit, то можете обратиться к исходникам .
Обратите внимание, что aufs_init возвращает int. Таким образом ядро узнает, что во время инициализации модуля что-то пошло не так - если модуль вернул не нулевое значение, значит во время инициализация произошла ошибка.
Чтобы указать какие именно функции нужно вызвать при загрузке и выгрузке модуля используются два макроса module_init и module_exit. Они раскрываются в некоторое количество компиляторной магии, но мы не будем углубляться в детали, интересующиеся могут обратиться к lxr и походить по ссылкам (надо сказать, для освоения ядра очень удобная штука).
pr_debug - это функция (на самом деле это макрос, но пока нам это не важно) вывода в лог ядра, очень похожа семейство функций printf с некоторыми расширениями, например, для печати IP и MAC адресов. Полный список модификаторов можно найти в документациик ядру. Вместе с pr_debug, есть целое семейство макросов: pr_info, pr_warn, pr_err и другие. Те кто немного знаком с разработкой модулей Linux наверняка знают про функцию printk, в принципе, макросы pr_* раскрываются в вызовы printk, так что вместо них можно использовать напрямую printk.
Далее идут макросы с информацией для потомков - лицензия и автор. Есть и другие макросы позволяющие сохранить самую разнообразную информацию о модуле, например, MODULE_VERSION, MODULE_INFO, MODULE_SUPPORTED_DEVICE и другие. Кстати, забавный факт, если вы используете лицензию отличную от GPL, то некоторые функции доступные GPL модулям вы использовать не сможете.
Теперь соберем и загрузим наш модуль. Для этого напишем Makefile, который будет собирать наш модуль:
obj-m := aufs.o aufs-objs := super.o CFLAGS_super.o := -DDEBUG all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
По факту, этот Makefile для сборки вызывает Makefile ядра, который должен находиться в каталоге /lib/modules/$(shell uname -r)/build (uname -r - команда, которая возвращает версию запущенного ядра), если у вас заголовки (или исходники) ядра находятся в другом каталоге, то нужно поправить.
obj-m - позволяет указать имя будущего модуля, в нашем случае модуль будет называться aufs.ko (именно ko - от kernel object). А aufs-objs позволяет указать из каких исходных файлов собирать модуль aufs, в нашем случае будет использоваться всего один файл super.c. Кроме того, можно указать различные флаги компилятора, которые будут использоваться (в дополнение к тем, которые использует Makefile ядра) при сборке объектных файлов, в нашем случае я передаю флаг -DDEBUG при сборке super.c. Если не передавать флаг -DDEBUG, то мы не увидим вывод pr_debug в системном логе.
Чтобы собрать модуль нужно выполнить команду make. Если все хорошо, то в каталоге должен будет появится файл aufs.ko - это наш загружаемый модуль. Загрузить модуль довольно просто:
sudo insmod ./aufs.ko
Чтобы убедиться, что модуль загрузился можно посмотреть на вывод команды lsmod:
lsmod / grep aufs
Чтобы посмотреть системный лог нужно вызвать команду dmesg, и там мы должны увидеть сообщения от нашего модуля. Выгрузить модуль тоже не сложно:
sudo rmmod aufs
Возвращаемся к файловой системе
Итак окружение настроено и работает, мы научились собирать простейший модуль, загружать и выгружать его, пора взяться за файловую систему. Проектирование файловой системы должно начинаться "на бумажке", с основательного продумывания используемых структур данных и прочего. Но мы пойдем простым путем и отложим детали хранения файлов и папок (и много чего другого) на диске на следующий раз, а сейчас напишем каркас нашей будущей файловой системы.
Жизнь файловой системы начинается с регистрации. Зарегистрировать файловую систему можно с помощью вызова register_filesystem . Мы будем регистрировать файловую систему в функции инициализации модуля. Чтобы разрегистрировать файловую систему есть функция unregister_filesystem , и вызывать мы ее будем в функции aufs_fini нашего модуля.
Обе функции принимают как параметр указатель на структуру file_system_type - она будет "описывать" файловую систему, считайте, что это класс файловой системы. Полей в этой структуре хватает, но нас интересуют лишь некоторые из них:
static struct file_system_type aufs_type = { .owner = THIS_MODULE, .name = "aufs", .mount = aufs_mount, .kill_sb = kill_block_super, .fs_flags = FS_REQUIRES_DEV, };
В первую очередь нас интересует поле name, оно хранит название файловой системы, именно это название будет использоваться при монтировании, но об этом позже, просто запомните его.
mount и kill_sb - два поля хранящие указатели на функции. Первая функция будет вызвана при монтировании файловой системы, а вторая при размонтировании. Нам достаточно реализовать всего одну, а вместо второй будем использовать kill_block_super, которую любезно предоставляет ядро.
Поле fs_flags - хранит различные флаги, в нашем случае оно хранит флаг FS_REQUIRES_DEV, который говорит, что нашей файловой системе для работы нужен диск (хотя пока это не так). Можно этот флаг не указывать, все будет прекрасно работать и без него.
Наконец, поле owner нужно для организации счетчика ссылок на модуль. Счетчик ссылок нужен, чтобы модуль не выгрузили раньше времени, например, если файловая система была примонтирована, то выгрузка модуля может привести к краху, счетчик ссылок не позволит выгрузить модуль, пока он используется, т. е. пока мы не размонтируем файловую систему.
Теперь рассмотрим функцию aufs_mount. Она должна примонтировать устройство и вернуть структуру описывающую корневой каталог файловой системы. Звучит довольно сложно, но, к счастью, и тут ядро почти все сделает за нас:
static struct dentry *aufs_mount(struct file_system_type *type, int flags, char const *dev, void *data) { struct dentry *const entry = mount_bdev(type, flags, dev, data, aufs_fill_sb); if (IS_ERR(entry)) pr_err("aufs mounting failed\n"); else pr_debug("aufs mounted\n"); return entry; }
По факту, большая часть работы происходит внутри функции moun_bdev, нас интересует лишь ее параметр aufs_fill_sb - это указатель на функцию (опять), которая будет вызвана из mount_bdev чтобы инициализировать суперблок. Но перед тем как мы перейдем к ней остановимся на важной для файловой подсистемы ядра структуре dentry . Эта структура представляет участок пути в имени файла, например, если мы обращаемся к файлу /usr/bin/vim, то у нас будут экземпляры структуры dirent представляющие участки пути / (корневой каталог), bin/ и vim. Ядро поддерживает кеш этих структур, что позволяет быстро искать inode (еще одна центровая структура) по имени (пути) файла. Так вот, функция aufs_mount должна вернуть dentry представляющую корневой каталог нашей файловой системы, а создаст его функция aufs_fill_super.
Итак, aufs_fill_super пока что самая важная функция в нашем модуле, и выглядит она так:
static int aufs_fill_sb(struct super_block *sb, void *data, int silent) { struct inode *root = NULL; sb->s_magic = AUFS_MAGIC_NUMBER; sb->s_op = &aufs_super_ops; root = new_inode(sb); if (!root) { pr_err("inode allocation failed\n"); return -ENOMEM; } root->i_ino = 0; root->i_sb = sb; root->i_atime = root->i_mtime = root->i_ctime = CURRENT_TIME; inode_init_owner(root, NULL, S_IFDIR); sb->s_root = d_make_root(root); if (!sb->s_root) { pr_err("root creation failed\n"); return -ENOMEM; } return 0; }
В первую очередь мы заполняем структуру super_block . Что это за структура такая? Обычно, файловые системы хранят в специальном месте раздела диска (это место выбирает файловая система) набор параметров файловой системы, таких как размер блока, количество свободных/занятых блоков, версию файловой системы, "указатель" на корневой каталог, магическое число, по которому драйвер файловой системы может проверить, что на диске хранится именно та самая файловая система, а не что-то еще, ну и прочие данные. Эта структура называется суперблоком (см. картинку ниже). Структура super_block в ядре Linux, в целом, предназначен для схожих целей, мы сохраняем в нем магическое число и dentry для корневого каталога (ту самую, которую возвращает mount_bdev).
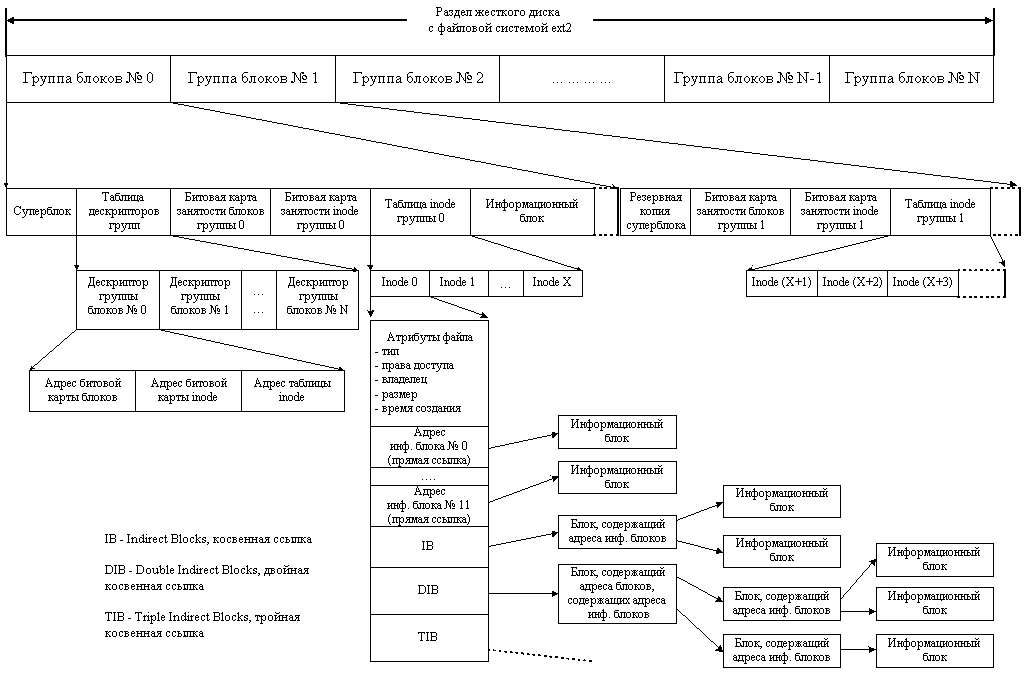
Кроме того, в поле s_op структуры super_block мы сохраняем указатель на структуруsuper_operations - это "методы класса" super_block, т. е. еще одна структура, которая хранит кучу указателей на функции.
Тут я сделаю еще одно отступление, ядро Linux написано на C, т. е. без поддержки различных ООП фич со стороны языка, но структурировать программу следуя идеям ООП можно и без поддержки со стороны языка, поэтому структуры содержащие кучу указателей на функции довольно часто встречаются в ядре - это такой способ реализации полиморфизма подтипов (aka виртуальных функций) имеющимися средствами.
Но вернемся к структуре super_block и ее "методам", мы не будем сейчас углубляться в детали структуры super_operations, нас будет интересовать только одно ее поле - put_super. В put_super мы сохраним "деструктор" нашего суперблока:
static void aufs_put_super(struct super_block *sb) { pr_debug("aufs super block destroyed\n"); } static struct super_operations const aufs_super_ops = { .put_super = aufs_put_super, };
Пока функция aufs_put_super ни делает ничего полезного, мы используем ее исключительно чтобы напечатать в системный лог еще одну строчку. Функция aufs_put_super будет вызвана внутри kill_block_super (см. выше) перед уничтожением структуры super_block, т. е. при размонтировании файловой системы.
Теперь вернемся к нашей самой важной функции aufs_fill_sb. Перед созданием dentry для корневого каталога мы должны создать inode корневого каталога. Структура inode является, пожалуй, самой важной в файловой подсистеме, каждый объект файловой системы (файл, папка, специальный файл, журнал и пр) идентифицируется inode. Как и с super_block, структура inode отражает то, как файловые системы хранятся на диске. Название inode происходит от index node, т. е. он индексирует файлы и папки на диске. Обычно внутри inode на диске хранится указание на то, где хранятся данные файла на диске (в каких блоках сохранено содержимое файла), различные флаги доступа (доступен для чтения/записи/исполнения), информация о владельце файла, время создания/модификации/доступа и прочие подобные вещи (см. картинку выше).
Пока мы не умеем читать с диска, так что заполняем inode фиктивными данными. В качестве времени создания/модификации/доступа используем текущее время, а назначение владельца и прав доступа делегируем ядру (вызываем функцию inode_init_owner). Ну наконец создаем dentry связанную с корневым inode.
Проверяем каркас
Каркас нашей файловой системы готов, пора его проверить. Сборка и загрузка драйвера файловой системы ничем не отличается от сборки и загрузки обычного модуля. Вместо реального диска для экспериментов мы будем использовать loop устройство. Это такой драйвер "диска", который пишет данные не на физическое устройство, а в файл (образ диска). Создадим образ диска, пока он не хранит никаких данных, поэтому все просто:
touch image
Кроме того, нам нужно создать каталог, который будет точкой монтирования (корнем) нашей файловой системы:
mkdir dir
Теперь используя этот образ примонтируем нашу файловую систему:
sudo mount -o loop -t aufs ./image ./dir
Если операция завершилась удачно, то в системном логе мы должны увидеть сообщения от нашего модуля. Чтобы размонтировать файловую систему делаем так:
sudo umount ./dir
И опять проверяем системный лог.
Итог
Мы поверхностно познакомились с созданием загружаемых модулей ядра и основными структурами файловой подсистемы. Мы также написали настоящую файловую систему, которая умеет только монтироваться и размонтироваться, пока она довольно глупая, даже сделать cd в корень файловой системы не получится, но мы собираемся исправить это в будущем.