
Для решения задач прогностического анализа, бизнес-анализа и интеллектуального анализа данных необходимо хранить и обрабатывать сложные и часто очень разные информационные структуры. Весьма вероятно ― особенно если это коммерческая или финансовая информация, ― что значительное количество обрабатываемых данных поступает из реляционных баз данных. Они следуют строгой структуре и требуют значительного объема подготовительной работы, такой как предварительная разработка схемы и модели данных. Новое поколение NoSQL- и документо-ориентированных баз данных значительно упрощает большую часть этой подготовки, позволяя создавать и хранить информацию в гибком формате. Кроме того, можно разработать методы извлечения этих данных в требуемом фиксированном формате. В этой статье говорится о том, как использовать документо-ориентированные базы данных для обработки и анализа данных в составе комплексного решения.
Архитектура документо-ориентированной базы данных
Одним из ключевых элементов всех документо-ориентированных баз данных является то, что они могут работать с гораздо более крупными структурами и наборами данных, чем обычно. В частности, ввиду их распределенной природы и другого способа физического хранения данных, они идеально подходят там, где нужно обрабатывать огромное количество информации, как это часто бывает в случае интеллектуального анализа данных.
Эти преимущества очевидны и документированы повсюду; предлагаемая статья посвящена структуре и формату информации, а также методам, которые используются для ее обработки и составления отчетов.
Гибкая структура данных
Документо-ориентированные базы данных имеют (почти) бесконечно гибкую структуру, которая обеспечивает ряд важных особенностей.
- Отсутствие схемы: документо-ориентированным базам данных не нужна предопределенная структура данных, которую нужно хранить в базе данных. В традиционных РСУБД сначала определяется структура таблиц, в которых будут храниться данные, для чего требуется знать наперед содержание, возможные значения и структуру информации. В документо-ориентированной базе данных информацию можно хранить прямо в документах и не нужно беспокоиться о структуре, достаточном количестве полей и в большинстве случаев даже о том, что такое отношения "один ко многим" и "многие ко многим". Вместо этого можно сосредоточиться на содержании самой информации. Хранить необработанные документы и информацию намного проще, даже если она поступает из разных источников. Дополнительная гибкость также означает, что можно объединять и обрабатывать информацию разных типов и с разной структурой. Например, в традиционных РСУБД трудно производить обработку текстовых данных, потому что нужно обеспечить достаточную гибкость структуры (количество предложений, абзацев и т.д.) для поддержки поступающей информации. Для наглядности представьте себе процесс сведения воедино данных из Twitter, Facebook и других социальных сетей и поиска в них типовых моделей. В Twitter информация имеет фиксированную длину и укладывается в одну короткую строку. Facebook разделяет элементы информации (текст, местоположение и учетные записи пользователей). При сборе всей этой информации и ее объединении значительная часть времени обработки уйдет на то, чтобы разместить все это в жесткой структуре.
- Логические объекты: большинство решений на основе СУБД используется для моделирования информации, которая обычно хранится в структурированном (относительно) формате. Затем с помощью SQL и соединений эта информация компонуется в объект, который используется внутри приложения. Различные элементы общей структуры данных можно просматривать отдельно, но часто информация скомбинирована и предоставляется в соответствии с объектом, в котором собраны все данные.
Для получения более сложной перспективы часто выполняются продольные и поперечные, плоскостные и объемные срезы, хотя на самом деле это просто подбор элементов одной и той же общей структуры. Документо-ориентированная конструкция меняет эту перспективу. Вместо того чтобы рассматривать отдельные, дискретные элементы данных, с документами можно работать как с цельными объектами. Например, для отслеживания сведений о коллекторах данных может потребоваться вся информация об этом объекте, хотя разные коллекторы данных могут иметь разные сенсоры, разное число сенсоров и разные уровни сложности. - Мигрирующая структура: с течением времени данные изменяются, иногда быстро, иногда медленно. Изменение структуры данных - это сложный процесс, который не только влияет на используемую базу данных, но и требует внесения изменений в приложения, которые обращаются к этой информации и работают с ней. В случае структуры на основе документов, так как структура данных фиксирована, адаптация этой структуры для новых версий и различных форматов исходных данных оказывается трудным и сложным делом. Нужно создать новую таблицу или изменить существующую для новой структуры, а это означает преобразование всех ранее созданных записей. В случае документо-ориентированной базы данных структура документов может меняться. На самом деле, отдельные документы могут иметь разную структуру. Так как вы всегда имеете дело с целым документом, приложение вряд ли потребует изменений, пока ему не придется обрабатывать новые данные.
С учетом всего этого, во что же выливается сбор, извлечение и обработка такой информации на практике?
Первое, что нужно рассмотреть, ― это формат самих данных. Документо-ориентированные базы данных могут хранить любую информацию, но наиболее широко используется структурный формат JSON, формат записи объектов из языка JavaScript. Он позволяет хранить данные, состоящие из строк, чисел, массивов и записей (хэш), а также комбинаций этих основных типов.
В целях разъяснения основ документо-ориентированной обработки в этой статье используются довольно простые данные. В листинге 1 представлен документ, в котором отслеживается уровень и температура воды в резервуаре.
Листинг 1. Документ, в котором отслеживается уровень и температура воды в резервуаре
{
"datestring": "Tue Nov 30 01:40:30 2010",
"hour": 1,
"min": 40,
"waterlevel": 96,
"day": 30,
"mon": 11,
"year": 2010,
"temperature": "28.64"
}Отдельные компоненты даты хранятся для гибкости, хотя это совершенно не обязательно. Уровень и температура воды хранятся в виде исходных значений.
В другом журнале отслеживается температура воды в трех разных точках резервуара, и эти данные представлены как хэш различных значений (листинг 2).
Листинг 2. Документ, в котором отслеживается температура воды в трех разных точках резервуара
{
"datestring": "Tue Nov 30 02:06:21 2010",
"temperature": {
"mid": 23.2148953489378,
"top": 23.6984348277329,
"bot": 23.0212211444848
}
}На самом деле ввод данных в документо-ориентированную базу данных, такую как Hadoop или Couchbase Server, пожалуй, ― самая простая часть процесса. Она не требует обработки, конструирования данных или структуры для их хранения. Нам не нужно анализировать данные с целью определения их структуры, достаточно просто хранить их в исходном виде.
Мощным инструментом интеллектуальный анализ документо-ориентированных данных делает обработка данных на этапе их извлечения.
Обмен данными
Когда уже имеются данные в виде традиционных РСУБД, например, IBM DB2, документо-ориентированную базу данных можно использовать для упрощения и унификации различных данных с формированием документов, которые будут обрабатываться с использованием преимуществ унифицированного формата.
Можно подумать, что это лишняя операция: ведь база данных уже есть, зачем ее куда-то переносить? Однако на протяжении многих лет решения на основе РСУБД используются для хранения текстовой информации и различных версий и редакций табличных данных. Документо-ориентированная база данных может стать эффективным средством их объединения в структуру, к которой можно применять операции map/reduce и другие методы.
Простейший процесс ― это загрузка объектов в том виде, в каком они отформатированы и структурированы в базе данных. Это легко, если для моделирования данных в объект используется система Object Relational Mapping (ORM). Этот процесс можно выполнить и вручную. Сценарий, приведенный в листинге 3, выполняет операцию, принимая сложный компонент записи, загружаемый с помощью функции, которая компилирует отдельные SQL-операторы для создания внутреннего объекта, форматирования JSON и его записи в документо-ориентированную базу данных (в данном случае, CouchDB).
Листинг 3. Операция загрузки объектов
foreach my $productid (keys %{$products})
{
my $product = new Product($fw,$productid);
my $id = $product->{title};
$id =~ s/[ ',\(\)]//g;
my $record = {
_id => $id,
title => $product->{title},
componentcount => $product->{componentcount},
buildtime => $product->{metadata_bytag}->{totalbuildtime},
testtime => $product->{metadata_bytag}->{totaltesttime},
totaltime => $product->{metadata_bytag}->{totaltime},
keywords => [keys %{$product->{keywordbytext}} ],
};
foreach my $component (@{$product->{components}})
{
push(@{$record->{component}},
componentqty => $component->{'qty'},
component => $component->{'componentdesc'},
componentcode => $component->{'componentcode'},
}
);
}
my $req = HTTP::Request->new('POST' => $base);
$req->header('Content-Type' => 'application/json');
$req->content(to_json($record));
my $res = $ua->request($req);
}Аналогичный процесс можно использовать и с другой информацией и другими документо-ориентированными базами данных. Например, в Hadoop для каждой записи о товаре можно создавать новый отдельный файл.
При объединении данных из нескольких таблиц в единый формат для обработки, хотя и не обязательно использовать те же имена полей (конфликты могут быть разрешены во время обработки), нет причин этого не делать, по крайней мере, стандартизировать некоторые поля (даты, точки данных), если информация по большей части повторяется.
Во время обработки, как видно на примере кода, можно также выполнить некоторые предварительные операции и отформатировать информацию. Например, можно согласовать данные для использования одних и тех же точек измерения или объединить поля, которые в разных источниках данных использовались по-разному.
Обработка при извлечении
В гибкой документо-ориентированной структуре обработка и выявление моделей в информации - это процесс, происходящий при извлечении данных, вместо того чтобы требовать извлечения информации и составления отчетов в момент ввода данных.
В типичной РСУБД структура состоит из таблиц и полей, основанных на том, как нужно будет извлекать эту информацию впоследствии. Например, при протоколировании информации таблицу точек регистрации (содержащую дату) можно связать с таблицей точек данных, содержащей определенные данные журнала. Из процесса известно, что можно соединить точки регистрации с данными о времени, информацией о температуре и уровне воды, чтобы можно было отслеживать значения с течением времени (см. рисунок 1).
Рисунок 1. Выполнение соединения
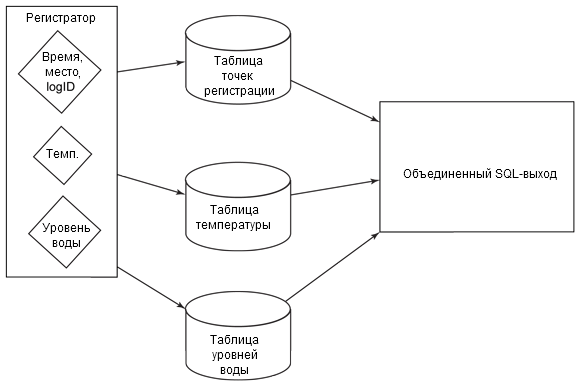
Обработка этой информации производится на входе, когда она разделяется, чтобы эту информацию можно было вставлять в таблицы, а затем, на выходе, происходит объединение путем рекомбинирования этой информации. Процесс требует знания того, как отображать, соединять и обрабатывать информацию на выходе. Когда структура таблицы известна, достаточно написать SQL-оператор.
В случае документо-ориентированной базы данных из исходных данных создается согласованное представление информации, которое позволяет обрабатывать эту информацию, будь то числовые данные или текст. Информация помещается в разные документы, и система map/reduce обрабатывает ее, создавая структурированную таблицу (см. рисунок 2).
Рисунок 2. Создание табличной структуры из данных
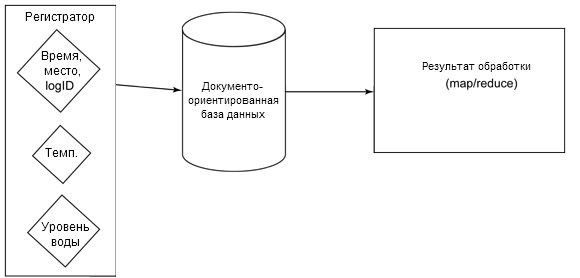
В документо-ориентированной базе данных информация обрабатывается, когда она уже введена. Это означает, что данные можно обрабатывать и даже изменить способ их извлечения, продолжая использовать исходные данные в первоначальном формате. Сохраняется полная гибкость в отношении представления данных без потери какой бы то ни было контекстной информации.
Конечно, следуя этому методу, придется внести некоторые коррективы в способ обработки исходных данных.
Использование метода map/reduce
Существует множество различных систем для обработки "больших данных" и для создания и приема информации и ее обработки в целях анализа данных, особенно с применением документо-ориентированных баз данных. Решения различаются своими подходами, от простых механизмов запросов, аналогичных тем, которые работают с базами данных SQL, до более сложных программ разбора и интерпретации. Последний вариант часто используется в ситуациях, когда нужно моделировать и интерпретировать данные таким образом, чтобы система могла изложить суть информации в формате, подходящем для обработки и обобщения.
На сегодняшний день наиболее распространенным из таких методов является метод map/reduce. Он работает в два этапа: на этапе map информация извлекается, а на этапе reduce ― сокращается и обобщается.
Роль функции Map ― принимать входную информацию (сохраненные документы) и упростить ее до формата, который обеспечит согласованные выходные данные для анализа. Например, используя вышеупомянутые журналы, можно взять отдельные данные о температуре и данные о температуре в разных точках и вывести эту информацию как один элемент данных, содержащий дату и температуру, как показано в листинге 4.
Листинг 4. Вывод отдельных данных о температуре и данных о температуре в разных точках в виде одного элемента данных
function (doc, meta) {
if (doc.temperature && doc.temperature["mid"]) {
emit(doc.datestring, parseFloat(doc.temperature["mid"]));
emit(doc.datestring, parseFloat(doc.temperature["top"]));
emit(doc.datestring, parseFloat(doc.temperature["bot"]));
} else
{
emit(doc.datestring, parseFloat(doc.temperature));
}
}Операция Map, показанная в листинге 4, написана на JavaScript и предназначена для использования с Couchbase Server, хотя она будет работать и с CouchDB, а основные принципы могут быть реализованы в Hadoop. Вызов emit создает "строку" информации, в данном случае, ключ и значение. Пример вывода исходных данных приведен в листинге 5.
Листинг 5. Вывод исходных данных
{"total_rows":404,"rows":[
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":22.6132600653245},
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":25.903221768301},
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":29.0646016268462},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":22.7931975564504},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":23.8901498654126},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":23.9022843956552},
{"id":"1292554769","key":"Fri Dec 17 02:59:29 2010","value":26.55},
{"id":"1324617141","key":"Fri Dec 23 05:12:21 2011","value":24.43},
{"id":"1296843676","key":"Fri Feb 4 18:21:16 2011","value":23.75},
{"id":"1297446912","key":"Fri Feb 11 17:55:12 2011","value":24.56}
]
}Идентификатор id в распечатке, приведенной в листинге 5, соответствует документу, из которого сгенерирована строка (в результате вызова emit()). В данном случае первая и вторая записи происходят из документов, содержащих показания нескольких датчиков температуры, потому что их идентификаторы идентичны.
Главное в интеллектуальном анализе данных с помощью метода map/reduce ― гарантировать, что собирается нужная информация, и нужные поля данных для получения желаемых сведений. В методе map/reduce решающую роль играет формат map. Мы выводим ключ и соответствующее значение. Значение потребуется на этапе сокращения, и я вскоре расскажу об эффективной записи этой информации. Но правильно выбрать значение очень важно. При обработке текста значением может быть результат тематического анализа строки или предложения. При анализе сложных данных иногда объединяют несколько элементов данных; например, при анализе коммерческой информации можно скомбинировать уникального покупателя, товар и место покупки.
Ключ при интеллектуальном анализе данных обеспечивает основу для сопоставления информации. В примере, приведенном в листинге 5, я выбрал дату целиком, но можно создавать и более сложные структуры. Например, если разделить дату на составные части (год, месяц, день, часы, минуты), то информацию можно группировать по разным правилам.
В листинге 6 привдена модифицированная версия операции Map, которая разбивает дату на отдельные части.
Листинг 6. Модифицированная версия операции map, которая разбивает дату на отдельные части
function (doc, meta) {
if (doc.temperature && doc.temperature["mid"]) {
emit(dateToArray(doc.datestring), parseFloat(doc.temperature["mid"]));
emit(dateToArray(doc.datestring), parseFloat(doc.temperature["top"]));
emit(dateToArray(doc.datestring), parseFloat(doc.temperature["bot"]));
} else
{
emit(dateToArray(doc.datestring), parseFloat(doc.temperature));
}
}При этом генерируются слегка измененные выходные данные map с указанием даты в виде массива (см. листинг 7).
Листинг 7. Измененные выходные данные map с указанием даты в виде массива
{"total_rows":404,"rows":[
{"id":"1291323688","key":[2010,12,2,21,1,28],"value":23.17},
{"id":"1292554769","key":[2010,12,17,2,59,29],"value":26.55},
{"id":"1292896140","key":[2010,12,21,1,49,0],"value":25.79},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":23.5796487295866},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":26.7156670181177},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":29.982973219635},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":22.2949007587861},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":24.1374973576972},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":27.4711695088274},
{"id":"1293417481","key":[2010,12,27,2,38,1],"value":25.8482292176647}
]
}Объединив эти данные с функцией Reduce, можно получить сводку по разным интервалам времени. Функции сокращения принимают выходные данные функции map() и обобщают эту информацию в соответствии с выбранной структурой ключей, приводя ее к простому формату. Распространенными примерами служат сумма, среднее значение или подсчет. В листинге 8 приведен пример функции Reduce, которая вычисляет среднее значение.
Листинг 8. Функция Reduce, вычисляющая среднее значение
function(keys, values, rereduce) {
if (!rereduce){
var length = values.length
return [sum(values) / length, length]
} else {
var length = sum(values.map(function(v){return v[1]}))
var avg = sum(values.map(function(v){
return v[0] * (v[1] / length)
}))
return [avg, length]
}
}В силу природы системы сокращения необходимо обрабатывать как первоначальное среднее значение (вычисленное по выходным данным функции map()), так и перерасчет (для получения окончательного результата для выбранного диапазона входных данных результат сокращения первого уровня объединяется с другими).
В основном функция занимается тем, что вычисляет среднее значение для входных данных (массив значений из функции map()), а затем вычисляет общее среднее путем деления общей суммы на количество точек.
При первом обращении весь набор данных группируется и обрабатывается с получением среднего значения всех сохраненных данных (см. листинг 9).
Листинг 9. Сгруппированный и обработанный набор данных дает среднее для всех сохраненных данных
{"rows":[
{"key":null,"value":[26.251700506838258,400100]}
]
}Выводя информацию о дате в виде массива, его компоненты можно использовать как критерии отбора генерируемых данных. Например, если задать один уровень группирования, то информация будет сгруппирована по первому элементу массива, то есть по годам (см. листинг 10).
Листинг 10. Группирование информации по первому элементу массива
{"rows":[
{"key":[2010],"value":[26.225817751696518,17484]},
{"key":[2011],"value":[26.252118781247404,199912]},
{"key":[2012],"value":[26.253719707387862,182704]}
]
}Если же задать три уровня, то можно получить сводки по отдельным комбинациям год/месяц/день (см. листинг 11).
Листинг 11. Сводки по отдельным комбинациям год/месяц/день
{"rows":[
{"key":[2010,11,30],"value":[26.23524809151833,505]},
{"key":[2010,12,1],"value":[26.37107941210551,548]},
{"key":[2010,12,2],"value":[26.329862140504616,547]},
{"key":[2010,12,3],"value":[26.31599258504074,548]},
{"key":[2010,12,4],"value":[26.389849136337002,548]},
{"key":[2010,12,5],"value":[26.175710823088224,548]},
{"key":[2010,12,6],"value":[26.21352234443162,548]},
{"key":[2010,12,7],"value":[26.10277260171637,548]},
{"key":[2010,12,8],"value":[26.31207700104686,548]},
{"key":[2010,12,9],"value":[26.207143469079593,548]}
]
}Функции сокращения можно использовать для обобщения и выявления различий в разных наборах информации. Более сложную функцию reduce() можно объединить с текстовым представлением температуры для разных уровней значений (warning, error и fatal) и объединить их в единую структуру (см. листинг 12).
Листинг 12. Объединение более сложной функции Reduce с текстовым представлением в единую структуру
function(key, values, rereduce)
{ var response = {"warning" : 0, "error": 0, "fatal" : 0 };
for(i=0; i<data.length; i++)
{
if (rereduce)
{
response.warning = response.warning + values[i].warning;
response.error = response.error + values[i].error;
response.fatal = response.fatal + values[i].fatal;
}
else
{
if (values[i] == "warning")
{
response.warning++;
}
if (values[i] == "error" )
{
response.error++;
}
if (values[i] == "fatal" )
{
response.fatal++;
}
}
}
return response;
}Теперь можно указать количество отдельных сигналов для любой комбинации интервалов даты и времени, например, по месяцам (см. листинг 13).
Листинг 13. Отдельные сигналы, подсчитанные по месяцам
{"rows":[
{"key":[2010,7], "value":{"warning":4,"error":2,"fatal":0}},
{"key":[2010,8], "value":{"warning":4,"error":3,"fatal":0}},
{"key":[2010,9], "value":{"warning":4,"error":6,"fatal":0}},
{"key":[2010,10],"value":{"warning":7,"error":6,"fatal":0}},
{"key":[2010,11],"value":{"warning":5,"error":8,"fatal":0}},
{"key":[2010,12],"value":{"warning":2,"error":2,"fatal":0}},
{"key":[2011,1], "value":{"warning":5,"error":1,"fatal":0}},
{"key":[2011,2], "value":{"warning":3,"error":5,"fatal":0}},
{"key":[2011,3], "value":{"warning":4,"error":4,"fatal":0}},
{"key":[2011,4], "value":{"warning":3,"error":6,"fatal":0}}
]
}Это упрощенные примеры, призванные продемонстрировать мощность и гибкость метода map/reduce, но они дают представление о том, как работать с различными форматами документов и структурами своих источников информации и как обобщать и извлекать информацию в ходе этого процесса.
Цепочка операций map/reduce
Как видите, map/reduce ― это практический метод синтаксического анализа и обработки больших объемов данных независимо от того, хранится ли исходная информация в подходящей базе данных.
Однако метод map/reduce имеет ограничения на количество информации, связанной (явно или неявно) через различные документы, которые можно объединять и включать в общий результат. К тому же для очень сложной информации один процесс map/reduce может оказаться не в состоянии выполнить обработку за один проход.
Невозможность использовать оператор JOIN для объединения информации из разных таблиц (включая ту же таблицу), как в традиционных РСУБД всех видов, не позволяет делать определенные операции в рамках map/reduce за один шаг.
Например, при обработке текстовой информации и выполнении тематического анализа данных процесс можно пройти, сначала обработав информацию и предложения из исходного материала, а затем разделив эти исходные данные на отдельные блоки документов. Это делается с помощью простой функции map(), которая обрабатывает информацию, создавая новые документы.
Вторым шагом будет обработка извлеченной информации для более детального анализа отдельных фрагментов и сопоставления и подсчета этой информации (см. рисунок 3).
Рисунок 3. Обработка извлеченной информации для более детального анализа
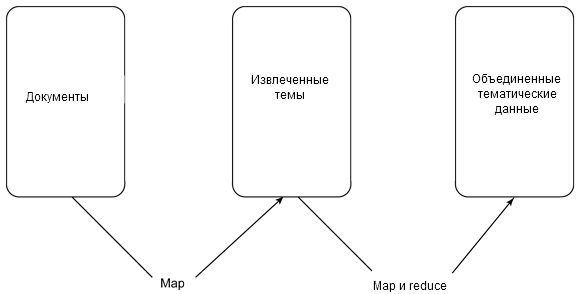
С практической точки зрения цепочки map/reduce ― это случай выполнения функции map/reduce для анализа первого уровня с использованием ключа результата (функции map()) в качестве идентификатора документа, содержащего структуру данных, полученную для этой сокращенной строки.
В предыдущем примере протоколирования можно взять комбинированную структуру warning/error/fatal, записать эту информацию в новую базу данных (или блок, как в Couchbase), а затем запустить дополнительный процесс обработки для этого блока, чтобы выявить тенденции или другие данные (см. рисунок 4).
Рисунок 4. Выполнение дополнительной обработки для выявления тенденций или других данных
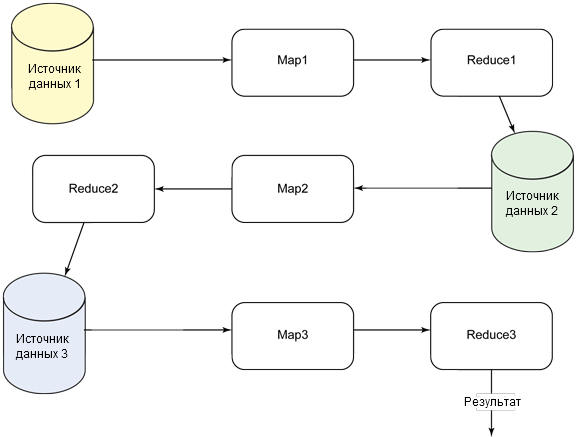
Помните, что прямая операция map/reduce применяется только к одному элементу данных. При экспорте и объединении информации из других источников в процессе обработки эту информацию также можно использовать и соединять в поток данных.
Например, при анализе информации о продажах сведения о покупателях могут находиться в одной базе данных, о продажах ― в другой, а о товарах - в третьей. Применяя метод map/reduce к данным по продажам с экспортом в другую базу данных, комбинируя ее с данными о товарах и затем снова сокращая с последующим объединением с информацией о покупателях, можно сгенерировать сложные данные, поступающие из разных источников.
Заключение
Документо-ориентированные базы данных радикально меняют привычные представления о структурах данных и правилах их обработки. Информацию больше не нужно предварительно анализировать, конструировать и переводить в табличный формат для упрощения последующей обработки. Вместо этого достаточно сохранять данные в том формате, в каком они поступают, а затем выполнять обработку, по ходу дела анализируя данные и манипулируя различными форматами и структурами. Этот процесс позволяет очень легко упростить и сократить огромное количество данных. Серверный процесс, который может работать с очень большими, распределенными базами данных, обычно облегчает работу, а не затрудняет ее. Можно обрабатывать гораздо более крупные и сложные данные с использованием многоузловой архитектуры. Как показывает эта статья, основной заботой для эффективной обработки данных становится составление подходящего документа и написание правильной комбинации map/reduce.