
Введение
На большом современном предприятии разные подразделения почти неизбежно будут использовать разные системы управления базами данных для хранения и поиска своих важнейших данных. Конкуренция, развитие технологий, слияния, приобретения, территориальная распределенность и децентрализация растущего бизнеса способствуют развитию такой разнородности. И только объединяя информацию из всех этих систем, предприятие может в полной мере использовать ценные знания, содержащиеся в данных.
Например, в отрасли финансовых услуг слияния стали практически обычным явлением. Создаваемая организация наследует хранилища данных объединяемых учреждений. Многие из таких хранилищ являются реляционными системами управления базами данных, но зачастую от разных поставщиков - например, одна компания может использовать в основном Sybase, а другая Informix. Возможно, каждое из учреждений развернуло одну или несколько систем управления документами - таких как Documentum или IBM Content Manager - для хранения текстовых документов, например копий кредитных договоров. У каждого из них могут быть приложения, которые вычисляют важную информацию (например, кредитный риск для конкретного клиента), или анализируют данные о закономерностях покупательского поведения клиентов.
После слияния необходимо обеспечить доступ ко всей информации о клиентах в хранилищах обоих учреждений, анализировать новые портфели с применением существующих и новых приложений и, как правило, использовать объединенные ресурсы обоих учреждений через общий интерфейс. Необходима возможность идентифицировать общих клиентов и консолидировать их счета, хотя разные учреждения могут определять своих клиентов с использованием совершенно разных идентификационных ключей. Технологии федерирования позволяют значительно упростить решение проблем, возникающих в таких ситуациях, предоставляя единый интерфейс к разрозненным данным.
IBM много инвестирует в технологии федерирования, что позволило ей разработать лучшие на рынке функциональные возможности для всего семейства продуктов IBM Information Management. В настоящее время средства федерирования обеспечивают единый доступ к любой цифровой информации, представленной в любом формате, структурированной и неструктурированной, в любом информационном хранилище. Средства федерирования сегодня доступны во многих продуктах IBM, включая InfoSphere® Federation Server, DB2® for Linux/UNIX/Windows, InfoSphere Warehouse и IBM Enterprise Information Portal (EIP). Комплекс технологий федерирования продолжает совершенствоваться, и инвестиции наших клиентов во все эти продукты продолжают обеспечивать реальные выгоды для бизнеса.
Эта статья посвящена передовым средствам создания федерированных баз данных, основывающимся на технологии, иногда называемой кодовым именем Garlic. Это новое поколение усовершенствований в области федерирования информации в программном обеспечении IBM. Эти усовершенствования позволят клиентам интегрировать и использовать данные и специализированные вычислительные возможности обширного спектра реляционных и нереляционных источников. Со временем технология Garlic будет включена во все программные продукты IBM, предоставляющие средства федерирования. Клиенты могут быть уверены в том, что их инвестиции в существующие продукты будут защищены сегодня и в будущем. Вне зависимости от выбранного продукта, они смогут эффективно использовать описанные здесь передовые возможности.
Предлагаемые IBM технологии федерирования данных включают мощные средства объединения информации из множества источников. Созданные на основе лучшей в своем классе технологии из предшествующего продукта DB2 DataJoiner [3](который теперь превратился в InfoSphere Federation Server) и дополненные передовыми средствами расширяемости и высокой производительности из исследовательского проекта Garlic [2], технологии IBM являются уникальными. Решение DB2 DataJoiner ввело понятие виртуальной базы данных, создаваемой путем федерирования множества гетерогенных реляционных источников. Пользователи DB2 DataJoiner могли осуществлять произвольные запросы к данным, хранящимся в федерированной системе, не заботясь о том, где именно находятся данные, о диалекте SQL реальных хранилищ данных или об их функциональных возможностях. Они могли применять весь спектр функций DB2 к любым данным в федерированной системе. Проект Garlic продемонстрировал возможность расширения этой концепции для создания федерированной системы баз данных, которая эффективно использует средства выполнения запросов разнообразных, возможно нереляционных, источников данных. В обеих этих системах, как и в современной DB2, обработчик запросов связующего ПО создает оптимизированные планы исполнения, а также компенсирует отсутствие любых функциональных возможностей, которых может не быть в конкретных источниках данных.
В этой статье мы описываем ключевые характеристики технологии федерирования IBM - прозрачность, гетерогенность, высокую функциональность, автономность исходных федерированных источников, расширяемость, открытость и оптимальную производительность. Затем мы показываем, как работают средства федерирования IBM. Мы приводим примеры возможного использования средств федерирования в различных сценариях и в заключение описываем некоторые направления будущего развития.
Характеристики решения IBM для создания федерированных баз данных
Прозрачная федерированная система скрывает от пользователя различия, особенности и принципы развертывания исходных источников данных. В идеале она представляет пользователю набор федерированных источников в виде одной системы. Пользователю нет необходимости знать, где хранятся данные (прозрачность размещения), какой язык программирования или программный интерфейс поддерживается источником данных (прозрачность вызова), используется ли SQL и какой диалект SQL поддерживает источник (прозрачность диалектов), как физически хранятся данные и являются ли они фрагментированными и/или реплицированными (физическая независимость данных, прозрачность фрагментирования и репликации) и какие используются сетевые протоколы (сетевая прозрачность). Пользователь должен видеть единый интерфейс, с единым набором кодов ошибок (прозрачность кодов ошибок). IBM предоставляет все эти возможности, позволяя создавать приложения так, как если бы все данные находились в одной базе данных, хотя фактически они могут храниться в гетерогенной совокупности источников данных.
Гетерогенность - это степень различия между источниками данных. Источники могут отличаться по многим аспектам. Они могут быть развернуты на разном оборудовании, использовать разные сетевые протоколы и иметь разное программное обеспечение для управления своими хранилищами данных. У них могут быть разные языки запросов, разные средства выполнения запросов и даже разные модели данных. Они могут по-разному обрабатывать ошибки или предоставлять разные семантики транзакций. Они могут быть похожими, как, например, два экземпляра Oracle, один Oracle 11g, а другой Oracle 9i, с одинаковыми или разными схемами. И они могут быть совершенно разными, как мощная реляционная база данных, простой структурированный файл, web-сайт, принимающий запросы в виде URL-адресов и выдающий полуструктурированный XML в соответствии с некоторым шаблоном DTD, web-сервис или приложение, реагирующее на конкретный набор вызовов функций. Технология IBM способна объединять все эти источники, обеспечивая гладкое, прозрачное федерирование.
Высокая степень функциональности
Технология федерирования IBM предоставляет пользователям все обширные функциональные возможности передовых, соответствующих стандартам средств DB2 SQL для всех данных в федерированной системе, а также все функциональные возможности исходных источников данных. DB2 SQL включает поддержку множества функций обработки сложных запросов, в том числе внутренние и внешние объединения, вложенные подзапросы и табличные выражения, рекурсию, пользовательские функции, агрегирование, статистический анализ, автоматические сводные таблицы и многое другое. Многие источники данных могут не предоставлять всех этих функций. Но пользователи могут применять все возможности DB2 SQL к данным из этих источников благодаря компенсации функций. Суть компенсации функций состоит в том, что если источник данных не может выполнять конкретную функцию обработки запроса, то федерированная база данных извлекает необходимые данные и сама применяет эту функцию. К примеру, при хранении данных в файловой системе обычно не поддерживается произвольная сортировка. Однако пользователям может потребоваться, чтобы данные из этого источника (например, некоторое подмножество файла) были извлечены в некотором порядке или чтобы из данных были исключены дубликаты. Федерированная база данных просто извлечет соответствующие данные и сама выполнит сортировку.
Хотя многие источники и не предоставляют всех функций DB2 SQL, многие из них имеют специализированные функциональные возможности, которых нет в федерированной базе данных IBM. Например, в системах управления документами часто есть функции для оценки степени соответствия извлеченных документов поисковому запросу пользователя. В отрасли финансовых услуг особенно важны данные в виде временных рядов, и существуют системы, способные сравнивать, графически отображать, анализировать и разбивать на подмножества эти данные. В фармацевтической отрасли новые лекарственные препараты создаются на основе существующих соединений с конкретными свойствами. Специализированные системы могут сравнивать химические структуры или моделировать связь двух молекул. Хотя такие функции можно было бы реализовать самостоятельно, однако зачастую эффективнее и экономичнее использовать функциональные возможности, которые уже существуют в источниках данных и прикладных системах. IBM предоставляет пользователю возможность определять интересующие функции федерированных источников и затем использовать их в запросах, поэтому ни одна из функций источника не будет потеряна для пользователя федерированной системы.
Любые системы должны развиваться с течением времени. В том числе может понадобиться добавление в федерированную систему новых источников для удовлетворения меняющихся требований бизнеса. IBM обеспечивает простоту добавления новых источников. Механизм федерирования получает доступ к источникам через программный компонент, называемый оболочкой (wrapper). Доступ к источнику нового типа обеспечивается через приобретение или создание оболочки для такого источника. Архитектура оболочек поддерживает разработку новых оболочек. После развертывания оболочки простые операторы определения данных (DDL) позволяют динамично включать источники в федерированную систему без остановки выполняемых запросов или транзакций.
В оболочку могут помещаться любые источники данных. IBM поддерживает стандарт ANSI SQL/MED [1](MED - Management of External Data). Этот стандарт документирует протоколы, используемые федерированным сервером для взаимодействий с внешними источниками данных. Любая оболочка, написанная для интерфейса SQL/MED, может использоваться с федерированной базой данных IBM. Поэтому оболочки могут создаваться не только IBM, но и другими разработчиками, и затем использоваться с федерированной базой данных IBM.
Автономность источников данных
Обычно у источника данных уже есть приложения и пользователи. Поэтому важно, чтобы использование источника в федерированной системе не оказывало влияния на его функционирование. Федерированная база данных IBM не нарушает локальные операции существующего источника данных. Существующие приложения будут работать без изменений, данные не перемещаются и не модифицируются, интерфейсы остаются теми же. На обработку источниками запросов к данным не оказывает влияния выполнение глобальных запросов к федерированной системе, хотя такие глобальные запросы могут затрагивать множество различных источников данных. Подобным же образом включение источника в федерированную систему или исключение из нее не оказывает никакого влияния на состояние локальной системы. Единственным исключением является федерированная двухфазная фиксация для участвующих источников. Источникам данных, включенным в одну и ту же единицу работы, нужна возможность участвовать в обработке с фиксацией и при необходимости выполнять откат связанных изменений.
В отличие от других продуктов, наша архитектура оболочек не требует установки какого-либо программного обеспечения на машину, где размещается источник данных. Взаимодействия с источником данных обеспечиваются средствами клиент-серверной архитектуры с использованием обычного клиента источника. Таким образом, федерированная система IBM выглядит для источника просто как еще одно приложение.
Оптимальная производительность
Оптимизатор - это компонент реляционной системы управления базами данных, который определяет наилучший способ выполнения каждого запроса. Реляционные запросы не являются процедурными, и обычно существует несколько разных реализаций каждого реляционного оператора, а также множество возможных порядков операторов в существующем запросе. В то время как некоторые оптимизаторы используют эвристические правила для выбора стратегии исполнения, федерированная база данных IBM рассматривает различные возможные стратегии, моделирует для каждой из них вероятные затраты - и выбирает одну, с наименьшими затратами. (Как правило, затраты измеряются в терминах потребляемых системных ресурсов.)
В федерированной системе оптимизатору необходимо решать, должны ли различные операторы, участвующие в запросе, выполняться федерированным сервером или источником, в котором хранятся данные. Он должен также определить порядок операций, и какие реализации использовать для выполнения локальных фрагментов запроса. Для принятия таких решений у оптимизатора должен быть какой-либо способ узнать, что может делать каждый источник данных и сколько это стоит. Например, если источником данных является файл, то нет смысла запрашивать у него сортировку или применение некоторой функции. А если источником является реляционная система управления базами данных, способная применять предикаты и выполнять объединения, то может быть разумно использовать ее возможности, если это сократит количество данных, которые необходимо вернуть в механизм федерирования. Обычно все зависит от деталей конкретного запроса. Оптимизатор IBM работает с оболочками для разных источников, участвующих в запросе, чтобы оценивать такие возможности. Зачастую разница между хорошим и плохим решением о стратегии исполнения измеряется несколькими порядками производительности. Федерированная база данных IBM уникальна своей способностью работать с оболочками для моделирования затрат на федерированные запросы к разнообразным источникам. В результате пользователи могут ожидать максимально высокой производительности федерированной системы.
Для еще большего повышения производительности каждая реализация оболочки использует операционные регуляторы, предоставляемые каждым источником данных, используя API-интерфейсы источника. Например, распространенным регулятором производительности является объединение множества результирующих строк в одно сообщение (блочная выборка). Компилятор запросов взаимодействует с оболочкой, указывая фрагменты, которые могут использовать блочную выборку, и тем самым обеспечивает максимальную производительность исполнения без потери семантики запросов.
Как работают средства федерирования IBM
Архитектура федерированной базы данных IBM представлена на рисунке 1. Приложения могут использовать для взаимодействий с федерированным сервером любой поддерживаемый интерфейс (включая ODBC, JDBC или клиент web-сервиса). Федерированный сервер взаимодействует с источниками данных через программные модули, называемые оболочками.
Рисунок 1. Архитектура федерированной системы IBM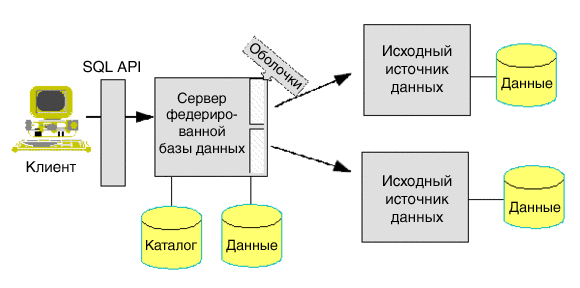
Конфигурирование федерированной системы
Федерированная система создается путем развертывания механизма федерирования и его конфигурирования для взаимодействий с источниками данных. Добавление нового источника данных в федерированную систему выполняется в несколько шагов. Во-первых, необходимо задать оболочку для источника и затем сообщить федерированной базе данных IBM, где найти эту оболочку. Это делается с использованием оператора CREATE WRAPPER. Для включения множества источников одного типа требуется только одна оболочка. Например, если федерированная система будет включать пять экземпляров базы данных Oracle, возможно, на разных машинах, то нужна только одна оболочка для Oracle, и, следовательно, потребуется только один оператор CREATE WRAPPER. Однако каждый источник должен быть определен отдельно. Это делается с помощью оператора CREATE SERVER. Если есть пять экземпляров базы данных Oracle, то необходимы пять операторов CREATE SERVER.
Предположим, к примеру, что есть оболочка для доступа к web-сайтам и есть конкретный сайт, к данным которого пользователь хочет получить доступ. Федерированная база данных может быть проинформирована об оболочке с использованием следующего оператора:
CREATE WRAPPER web_wrapper LIBRARY "/u/haas/wrappers/libweb.a" |
Этот оператор по сути сообщает федерированной базе данных, где найти код для оболочки web_wrapper. Затем федерированной базе данных можно сообщить о реальном web-сайте, который будет использоваться, определяя его как сервер, связанный с оболочкой web_wrapper.
CREATE SERVER weather_server WRAPPER web_wrapper OPTIONS (URL 'http://www.weatherforecast.com') |
Параметр OPTIONS позволяет связать базовый оператор CREATE SERVER с информацией, которая потребуется оболочке для доступа к экземплярам источников данных этого типа.
После определения оболочки и сервера данные в удаленном источнике должны быть описаны в терминах модели данных связующего программного обеспечения для федерирования. Поскольку описываемая здесь федерированная база данных поддерживает объектно-реляционную модель данных, то каждая совокупность данных из внешнего источника должна быть описана для механизма федерирования как таблица со столбцами соответствующих типов. Совокупность внешних данных, смоделированных в виде таблицы, называется псевдонимом, а имя таблицы и имена столбцов используются в SQL-запросах приложений к федерированной системе. Псевдонимы определяются с использованием оператора CREATE NICKNAME. Следующий оператор устанавливает псевдоним для совокупности информации о погоде и определяет столбцы, которые могут использоваться в запросе.
CREATE NICKNAME weather
(zone integer, climate varchar(10), yearly_rainfall float)
SERVER weather_server OPTIONS (QUERY_METHOD 'GET') |
Параметр OPTIONS снова является способом передачи информации, которая необходима оболочке, на этот раз чтобы обрабатывать запросы к псевдонимам.
Помимо хранения данных, многие источники также способны выполнять специальный поиск и другие вычисления. Такие возможности могут представляться в SQL как пользовательские функции. Например, пользователю может потребоваться прогноз температуры по месту и дате, чтобы определить клиентов для продаж кондиционеров.
SELECT c.Name, c.Address FROM customers c, stores s, weather w WHERE temp_forecast(w.zone, :DATE) >= 85 AND c.ShopsAt = s.id and s.location = w.zone |
Здесь функция temp_forecast используется для представления способности источника делать температурные прогнозы для псевдонима weather. Мы называем определяемые пользователем функции, которые выполняются внешним источником данных, отображаемыми (mapped) функциями. Отображаемые функции определяются для федерированной системы с использованием операторов DDL. Оператор CREATE FUNCTION говорит федерированной базе данных, что это функция, которая может появиться в операторе SELECT.
CREATE FUNCTION temp_forecast (integer, date) RETURNS float AS TEMPLATE DETERMINISTIC NO EXTERNAL ACTION |
Параметр AS TEMPLATE сообщает федерированной базе данных об отсутствии локальной реализации этой функции. Затем оператор CREATE FUNCTION MAPPING сообщает федерированной базе данных, какой сервер должен вычислять функцию. Для одной и той же функции может быть создано несколько отображений. В нашем примере отображение определяется с использованием следующего оператора:
CREATE FUNCTION MAPPING tf1 for temp_forecast SERVER weather_server |
Указанные выше операторы DDL производят метаданные, описывающие информацию о псевдонимах и признаках отображаемых функций. Эти метаданные используются механизмом обработки федерированных запросов и хранятся в глобальных каталогах федерированной базы данных.
После конфигурирования федерированной системы приложение может подавать SQL-запрос к федерированному серверу. Федерированный сервер оптимизирует запрос и разрабатывает план исполнения, разделяющий запрос на фрагменты, которые могут выполняться в конкретных источниках данных. Как уже отмечалось, возможны различные разделения запроса, и оптимизатор выбирает из множества альтернатив вариант с минимальной оценкой общими затратами ресурсов. Как только план выбран, федерированная база данных переходит к исполнению, вызывая оболочку для выполнения назначенных ей фрагментов. Для выполнения фрагмента оболочка исполняет любые требуемые операции источника данных, это может быть последовательность вызовов функций или запрос к источнику данных на его собственном языке запросов. Результирующий поток данных возвращается на федерированный сервер, который объединяет их, выполняет дополнительную обработку, которая не может быть выполнена источником данных, и возвращает окончательный результат приложению.
В основе подхода IBM к обработке федерированных запросов лежит метод, при котором оптимизатор федерированного сервера и оболочки вместе приходят к плану для выполнения запроса [4]. Оптимизатор несет ответственность за изучение возможных планов выполнения запроса. По умолчанию для перечисления соединений используются методы динамического программирования; при этом оптимизатор сначала генерирует планы для доступа к одной таблице, затем двусторонние соединения и так далее. На каждом уровне оптимизатор рассматривает различные порядки и методы соединений, и если все таблицы размещены в общем источнике данных, то он рассматривает выполнение соединений либо в источнике данных, либо на федерированном сервере. Схема этого процесса представлена на рисунке 2.
Рисунок 2. Планирование запросов для соединений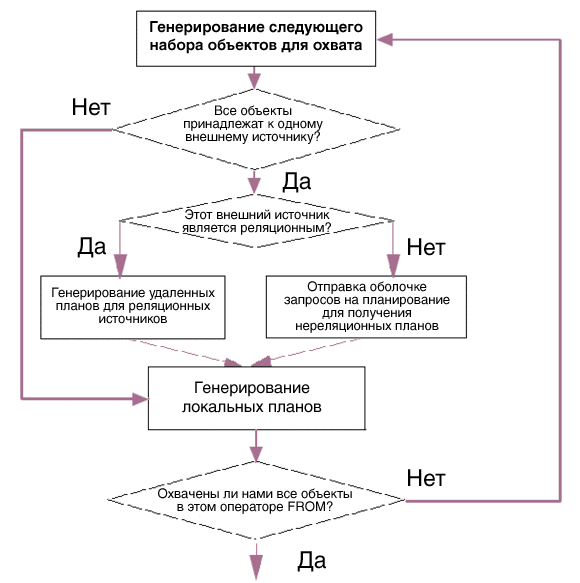
Оптимизатор по-разному работает с реляционными и нереляционными оболочками. Он детально моделирует реляционные источники, используя предоставляемую оболочкой информацию для генерирования планов, включающих ожидаемые действия источника.
Однако у нереляционных источников нет общего набора операций или общей модели данных, поэтому для них требуется более гибкая схема. Оптимизатор работает с нереляционными оболочками следующим образом:
- Федерированная база данных IBM отправляет оболочке возможные фрагменты запроса, если эти фрагменты применяются к одному источнику.
- Когда нереляционная оболочка получает фрагмент запроса, она определяет, какая часть соответствующего фрагмента запроса может быть выполнена источником данных.
- Оболочка возвращает ответ, который описывает принятую часть фрагмента. Ответ также включает оценку количества строк, которые будут сформированы, оценочное общее время исполнения и план для оболочки - упакованное представление всего, что оболочке потребуется знать для выполнения принятой части фрагмента.
- Оптимизатор федерированной базы данных включает ответ в глобальный план, вводя при необходимости дополнительные операторы для компенсации частей фрагментов, которые не были приняты оболочкой. Информация о затратах и кардинальности из ответов используется для оценки общей стоимости плана, и среди всех кандидатов выбирается план с минимальной общей стоимостью. Выбранный план не обязательно выполняется немедленно - он может храниться в каталогах базы данных и впоследствии использоваться один раз или многократно для выполнения запроса. Даже если план используется немедленно, он не обязательно должен исполняться в том же процессе, в котором был создан, как показано на рисунке 3.
Рисунок 3. Процессы компиляции и исполнения для нереляционных источников
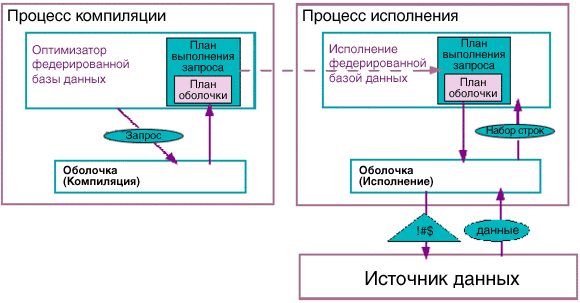
Рассмотрим, например, web-сайт, который экспортирует информацию о ценных бумагах, в том числе о биржах, курсах открытия и закрытия и торгуемых объемах. По web-сайту может осуществляться поиск с использованием формы. Как это обычно бывает, форма позволяет ограничивать значения некоторых, но не всех атрибутов. Рассмотрим следующий запрос:
SELECT TickerSymbol, StockName FROM Stocks WHERE Exchange='NYSE' AND Closing - Opening > 5 |
Поскольку это запрос к одной таблице, учитывать методы соединения и кардинальность не нужно, и оболочке web-источника передается только один фрагмент, содержащий весь запрос целиком. Если форма предоставляет пользователю возможность указывать соответствующее значение для атрибута Exchange исходных данных, но не предлагает никакого способа указывать разницу между курсами открытия и закрытия, то оболочка сформирует ответ, который разрешает предикат для Exchange, но отклоняет предикат Closing - Opening > 5. Оптимизатор выполнит компенсацию, введя оператор для оценки последнего предиката на федерированном сервере. Вообще говоря, оболочка должна быть способна возвращать значение любого конкретного столбца, запрошенного в списке SELECT, однако может отклонить любой предикат или более сложное выражение для списка SELECT.
В дополнение к сообщению о том, что источником данных будет вычисляться только предикат Exchange, ответ будет включать план оболочки, содержащий достаточно информации для выполнения запроса, представленного ответом. Например, план оболочки может содержать параметризованный URL-адрес, эквивалентный адресу, который браузер мог бы сформировать, если бы пользователь заполнил форму запроса вручную. Во время исполнения федерированный сервер вернет этот план оболочке, которая извлечет URL-адрес, отправит его на web-сайт, разберет результирующий поток данных и возвратит запрошенные значения федерированному серверу.
Использование федерированной системы баз данных
Чем полезна федерированная система? Как клиенты используют средства федерирования? Вообще говоря, федерирование полезно в любых ситуациях, когда есть множество источников данных и потребность объединять информацию из этих источников. В этом разделе мы рассмотрим, как некоторые клиенты в настоящее время используют технологии федерирования IBM для решения своих бизнес-задач.
Распределенные операции: крупная фармацевтическая компания
Многие компании сегодня являются глобальными, так что им нужно координировать операции своих филиалов по всему миру. Например, у фармацевтической компании могут быть исследовательские лаборатории в Европе и США. В каждой из лабораторий исследователи ищут новые лекарственные препараты для борьбы с конкретными заболеваниями. Все исследователи имеют доступ к базам данных химических соединений в специализированных системах, позволяющих осуществлять поиск по конкретным характеристикам соединений или по химической структуре (структурное подобие). В обеих лабораториях исследователи выполняют высокопроизводительный анализ соединений для тестирования их эффективности в отношении различных биологических целей. Результаты этих тестов хранятся в реляционных базах данных в каждой из лабораторий. Кроме того, исследователи получают доступ к таким источникам данных, как большие текстовые файлы с геномной и протеомной информацией, базы данных патентов, электронные таблицы с данными и результатами анализа, изображения и документы.
У исследователей двух лабораторий разные цели, они разрабатывают разные методы лечения. Поэтому они проводят разные эксперименты и сосредоточиваются на конкретных наборах соединений. Однако зачастую некоторые соединения могут быть полезны для разных целей, и иногда один тест может быть хорошим индикатором результатов для других тестов. Поэтому исследователям одной лаборатории важно иметь доступ к данным, которые создаются в другой, чтобы не дублировать усилия. Это может обеспечиваться созданием большого хранилища со всеми данными о соединениях и результатами тестов, однако у этого подхода есть определенные недостатки. Во-первых, данные о результатах тестов быстро меняются, и тысячи записей добавляются ежедневно с обеих сторон Атлантики, усложняя задачи обслуживания. Во-вторых, это хранилище либо должно реплицироваться на обе площадки, либо одна из площадок будет испытывать проблемы с производительностью доступа к данным. Репликация повышает стоимость решения и сложность обслуживания. В-третьих, данные о соединениях, хранимые сейчас в специализированных репозиториях, нужно будет перенести в реляционную базу, а также повторно реализовать алгоритмы поиска и существующие приложения.
Решение для федерирования источников данных исключает эти проблемы. Данные остаются в существующих источниках со своими собственными путями доступа, и существующие приложения работают без изменений. В то же время можно легко создавать новые приложения, которые будут иметь доступ к данным в любых источниках с любого континента. Локальные данные остаются локальными, что обеспечивает быстрый доступ. Редко используемые удаленные данные по-прежнему доступны по мере необходимости, а запросы к ним оптимизируются федерированным сервером, чтобы обеспечивать максимально эффективное их извлечение. При желании по-прежнему можно применять репликацию для тех фрагментов данных, к которым часто обращаются обе лаборатории.
Простота извлечения, трансформации и загрузки (ETL)
Многие компании принимают решение хранить множество копий своих данных. Например, крупная розничная компания с торговыми площадками, распределенными по всей территории США, выполняет резервное копирование данных из своих филиалов в региональные хранилища. Розничные магазины используют одну реляционную систему управления базами данных, а хранилища развернуты с использованием другой распределенной СУБД, которая хорошо масштабируется. Однако это приводит к проблеме - как передавать данные из источника в хранилище. Технология федерирования IBM упрощает не только перемещение данных, выбирая их из источников и помещая в хранилище, но и их трансформацию, агрегируя информацию из разных магазинов перед тем, как включать ее в хранилище.
Распределенное хранилище данных
Развертывание распределенного хранилища данных обеспечивает повышение готовности и сокращение общих затрат. Предприятие может создать несколько витрин данных, которые содержат только общие сводки для данных, извлекаемых из хранилища. Технология федерирования IBM позволяет разместить витрины данных и хранилище на отдельных системах, однако пользователи витрины данных могут по-прежнему легко углубляться в данные от своего локального уровня агрегации до уровня хранилища. Технология федерирования предоставляет пользователям доступ к виртуальному хранилищу данных, экранируя внутреннее устройство реального хранилища, в том числе тот факт, что это хранилище данных является распределенным.
Геопространственные приложения
Банку требуется выбрать место для нового филиала. Выбранная площадка должна обеспечивать максимальную ожидаемую прибыль. Поэтому для каждой потенциальной площадки нужно изучить демографические характеристики окружения (соответствуют ли они целевой клиентской базе?), уровень преступности в районе (низкий уровень преступности важен для розничных операций), близость площадки к основным магистралям (для привлечения клиентов за пределами прилегающей территории), близость к основным конкурентам (небольшая конкуренция скорее всего будет означать более высокие объемы продаж), а также близость к известным проблемным местам, которых необходимо избегать (мусорная свалка или любая другая непривлекательная характеристика окружения может оказывать негативное влияние на бизнес). Некоторые из требуемых данных будут поступать из собственных баз данных банка. Другую информацию нужно извлекать из внешних хранилищ публичных данных. Необходима интеграция геопространственных данных с традиционными бизнес-данными. Также необходимы развитые функции выполнения аналитических запросов для коррелирования данных, а также инструменты для конечных пользователей, позволяющие наглядно представлять данные в геопространственном контексте.
Традиционно геопространственные данные обслуживаются специализированными геоинформационными системами (ГИС), которые не могут интегрировать пространственные данные с другими бизнес-данными, хранимыми в СУБД компании, а также со сведениями из внешних источников. DB2 Spatial Extender является результатом сотрудничества с партнером IBM - институтом исследований окружающей среды Environmental Systems Research Institute (ESRI). DB2 Spatial Extender работает с федерированной базой данных IBM, предоставляя клиенту возможность использовать средства геопространственного анализа, встроенные в DB2 Spatial Extender, в сочетании со значительными объемами доступной информации из федерированной системы. Это позволяет организации лучше понимать свой бизнес, эффективно использовать существующие данные и создавать новые сложные приложения для поддержки успешного бизнеса.
Несмотря на пристальное внимание со стороны исследовательского сообщества, лишь немногие коммерческие системы управления базами данных справляются с проблемой интеграции реляционных и нереляционных источников данных в федерированную систему. Разработанные IBM средства федерирования позволяют значительно продвинуться в достижении этой цели. Уникальная технология IBM для обработки федерированных запросов предоставляет пользователям передовые функции DB2 SQL вместе с возможностями конкретных источников данных. Она предлагает пользователям преимущества прозрачности, гетерогенности, высокой функциональности, автономности исходных федерированных источников, расширяемости, открытости и оптимальной производительности. В настоящее время технологии федерирования используются для решения многих серьезных задач бизнеса.
Мы будем продолжать работать над повышением производительности и расширением функциональности средств федерирования. Например, уже сейчас можно в некоторой форме реализовать возможности кэширования с использованием механизма автоматических сводных таблиц (automatic summary table, AST), позволяющего администраторам определять материализованные представления данных в наборе базовых таблиц (псевдонимы). Для отдельных классов запросов база данных может автоматически определять, можно ли дать ответ на запрос с использованием AST без доступа к исходным таблицам. Помимо непрерывного повышения производительности, мы работаем над инструментами для поддержки конфигурирования, настройки и администрирования федерированных систем. В разработке находятся инструменты для генерирования статистики по данным из нереляционных источников и мониторинга поведения федерированной системы. Кроме того, ведется работа над вспомогательными инструментами для разработки оболочек.
В заключение следует отметить, что даже хорошо спроектированная федерированная система управления базами данных вместе с набором инструментов - это лишь частичное решение большой проблемы интеграции данных. Полное решение должно интегрировать приложения и данные, а также справляться с такими проблемами более высокого уровня, как качество, аннотирование, различия в терминологии и бизнес-правила, которые указывают, когда и как информация должна комбинироваться. Система IBM InfoSphere Information Server, ориентированная на этот обширный набор требований, позволяет клиентам удовлетворять потребности в интеграции информации, и федерирование в виде базы данных является лишь одной значимой интеграционной технологией.