
В статье описывается загрузка из файлов типа dbf объемом 700 MB (> 3 млн. записей) в базу данных ORACLE объемом 4 GB (20 млн. записей). Проведение входного контроля и проверкой на уникальность при добавлении базу данных ORACLE. Программы загрузки и выгрузки разработаны с использованием OCI. Проверки и контроль организованы с использованием хранимых процедур, триггеров, промежуточных таблиц.
В статье сравнивается производительность при использовании различных вариантов загрузки и, кратко, дальнейшее использование накопленной информации при ее хранении в ORACLE.
Система реализована и эксплуатируется с 1.1.1998 года и до сих пор в Самарском Территориальном фонде обязательного медицинского страхования.
Цели построения системы
- Хранение всей изменяемой информации о большом количестве объектов или субъектов (далее для простоты объект)
- Просмотр информации об объекте по ее состоянию на указанную дату
- Поиск объектов по указанным значениям его свойств, в т.ч. поиск в указанном диапазоне дат.
- Выполнение различных подсчетов количественных показателей:
- c группировками по различным свойствам объектов в указанном диапазоне дат
- с группировками по различным диапазонам дат для указанных свойств объектов
- Проведение сравнительных анализов для двух различных временных периодов
- Периодическое накопление нового текущего состояния информации обо всех объектах либо
- On-Line изменение свойств конкретного объекта по внешнему запросу
- Проведение входного контроля и проверкой на уникальность при добавлении базу данных ORACLE.
- Выгрузка из базы данных среза информации на текущую дату для передачи в другие организации.
- Построение на хранимой информации других систем.
- Организация диалогового доступа в локальной сети и внешних запросов по e-mail к хранимой информации об объектах в базе данных
Требования к системе:
- Гарантированная приемка месячной информации объемом 700 MB (> 3,5 млн. записей) за ограниченное время (4 суток). В это входит:
- входной контроль
- дополнительные преобразования информации
- объединение с хранимой историей изменений об объектах
- выгрузка из базы данных среза информации на текущую дату
- Обеспечение входного контроля принимаемой информации:
- уникальность по 12 уникальным ключам, каждый из которых содержит в среднем 7 необязательно заполненных колонок.
- Соответствию значений порядка 10 справочникам
- Не соответствие ряду исключающих таблиц
- Различные проверки на уровне полей
- Возврат записей не прошедших входной контроль, с указанием:
- всех несоответствий в каждой отсеянной записи
- всех полей с ошибочными значениями
- ссылками на более позднюю по изменению информации об объекте запись, прошедшую контроль и другими не прошедшими, с которыми возникла не уникальность отсеянной записи
- Хранение истории изменений информации более чем за 3 года объемом 4 GB (20 млн. записей).
- Получаемые и отправляемые файлы формата DBF.
Концепция реализации системы
- Основная информация, хранимая и используемая в системе - это история изменений информации об объекте. Хранение и доступ организованы очень просто. Хранится несколько версий информации об одном объекте. Для каждой хранимой версии хранится период действия этой версии. На этапе загрузки информации обеспечивается контроль на возможность пересечения периодов действия для одного объекта, а также уникальность самого объекта по 8-12 ключам в любом периоде. Ссылочная целостность с другими таблицами выполняется тоже процедурно с учетом периодов действия записей обоих таблиц.
- Вся логическая обработка выполняется в СУБД ORACLE.
- Загрузка информации разбивается на несколько этапов.
- Нужно следить, чтобы исходная таблица была всегда в табличном пространстве в состоянии READ ONLY.
- Нужно следить, чтобы исходный и результирующий массив (таблица, файл) всегда находились на разных дисках. Кроме того, необходимо иметь еще отдельные диски для табличных пространств сегментов отката, индексов и временного табличного пространства TEMP.
Начальный входной контроль, выполняемый на уровне одной записи
Он может быть разбит на части, выполняться последовательно и параллельно и повторяться для исправленных записей.
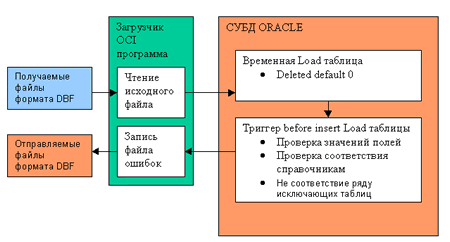
Его цель - быстро получить записи, не прошедшие контроль, выполняемый на уровне одной записи, для возможности исправления отправителем информации.
Создается временная Load таблица для загрузки информации в виде, как она хранится в исходном файле.
Написана универсальная программа Загрузчик файлов формата DBF в СУБД ORACLE. Она распознает заголовок DBF файла, сравнивает его структуру с одноименной Load таблицей, и если необходимо добавляет в нее колонки или расширяет их. Скорость работы программа равна скорости работы SQL*Loader. Программа может работать в режиме клиент-сервер или локально на сервере в среде ОС Win95/NT, Linux, AIX.
Файл отсеянных записей имеет структуру исходного файла и дополнительные колонки:
- Сообщение об ошибке, полученное из триггера по RAISE_APPLICATION_ERROR
- Список полей с ошибочными значениями из части сообщения об ошибке
- Номер записи в исходном файле
В файл отсеянных записей попадают также записи с нарушением типа данных и соответствующей ошибкой ORACLE.
Проверка уникальности
Нужно оставить одну из нескольких записей об объекте с наиболее поздней датой ввода. Как оказалось на объемах 700 MB и порядка 3,5 млн. записей выявление неуникальных записей использовать поиск по индексу не эффективно, т.к. нужно произвести поиск 12 раз для каждой из 3,5 млн. записей. Для каждой из 12 проверок делается следующее (упрощенное описание):
Create table NO_UK_N1 tablespace …unrecoverable as
Select <поле1>, <поле2>, <поле3>, … <полеN>
From LOAD_TABLE
Where Deleted = 0
Group by <поле1>, <поле2>, <поле3>, … <полеN>
Having count (*) > 1
Выполнение этого запроса занимает порядка от 20 минут до 2 часов. При работе с индексами я несколько раз ждал дня 4 и снимал запрос. За три года многократных проб найдено правильное решение.
Затем для таблицы NO_UK_N1 создается уникальный индекс по всем колонкам и создается вторая таблица NO_UK_N1_1 c усеченными неуникальными записями:
Create table NO_UK_N1_1 tablespace …unrecoverable as
Select a.<поле1>, a.<поле2>, a.<поле3>, … a.<полеN>,
a.DATA, a.ROWID NROWID, 0 P, NULL RNROWID
From LOAD_TABLE a, NO_UK_N1 b
Where a.Deleted = 0
And a.<поле1> = b.<поле1> -- NOT NULL
And NVL(a.<поле2>, 0 ) = NVL(b.<поле2> ,0) -- NUMBER NULL
And NVL(a.<поле3>,‘*’) = NVL(b.<поле3> ,‘*’) --VARCHAR2 NULL
…
And a.<полеN>= b.<полеN> -- аналогично NULL для полей типа DATE
Затем для таблицы NO_UK_N1_1 создается не уникальный индекс по всем ключевым колонкам <поле1>, <поле2>, <поле3>, … <полеN>.
В PL/SQL блоке последовательно продвигаясь по таблице NO_UK_N1 и подчиненной таблице NO_UK_N1_1, отбирается наиболее поздняя запись по полю NO_UK_N1_1.DATA. При этом используется фраза ORDER BY DATA DESC. Первая выбранная по ключу таблицы NO_UK_N1 запись из NO_UK_N1_1 старшая. Эта запись остается. В ней можно изменить поле P. Для остальных можно записать поле RNROWID значением NROWID старшей записи. Эти записи отсеиваются. Для этих записей по значению NROWID в таблице LOAD_TABLE изменяется поле DELETED с 0 на номер обработки уникальности, т.е. в нашем случае на 1.
В результате этой обработки в таблице LOAD_TABLE появится часть записей со значением поля DELETED не равным 0. Это отсеянные записи по уникальности.
Выделение оставшихся записей
Для повышения скорости и снижения требуемых ресурсов в последующих этапах неплохо сформировать таблицу записей прошедших контроль на уникальность.
Для этого создается на другом диске табличное пространство в одном файле размером 650 МВ с возможностью авторасширения по 20 МВ. Создается таблица:
Create table UK_TABLE
…
PCTFREE 0 PCTUSED 99
…
INITIAL 648 MB NEXT 20 MB
…
tablespace TS_UK_TABLE unrecoverable
as
Select *
From LOAD_TABLE
Where Deleted = 0
Перегрузка информации
Производится перегрузка информации из таблицы LOAD_TABLE в таблицу, хранящую всю историю изменений информации об объекте. Это один из наиболее интенсивных и продолжительных этапов. Продолжительность выполнения на 64 разрядном сервере RISC IBM AIX составляет 80 - 110 часов.
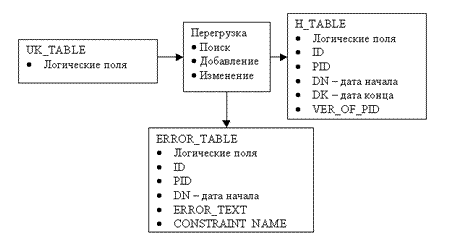
Структура хранимой процедуры:
- Чтение записей об объекте из исходной таблицы в цикле. Чтение без сортировки циклом FOR с обязательно неявным курсором. Табличное пространство исходной таблицы переведено в состояние READ ONLY для возможной блокировки таблицы по чтению. Назначается выделенный сегмент отката, размером превышающий размер добавляемой информации.
- Поиск объекта в результирующей таблице H_TABLE по 8 различным условиям поиска, используя составных 5 индексов.
- Если запись найдена
- Если информация об объекте не изменилась по отношению к предыдущему периоду, то увеличивается значение поля DK - расширение диапазона жизни записи. Очень важно, чтобы при этом не изменялся ни один из индексов. Это основной режим - 90% записей.
- Иначе значение из найденной записи поля ID переносится в поле PID новой записи. Это код объекта.
- Если информация об объекте не изменилась по отношению к предыдущему периоду, то увеличивается значение поля DK - расширение диапазона жизни записи. Очень важно, чтобы при этом не изменялся ни один из индексов. Это основной режим - 90% записей.
- Если запись найдена
- Если не было изменение значения поля DK, то вставка новой записи в таблице H_TABLE.
- Формируется ID. Это код экземпляра информации об объекте в определенном временном интервале. Он может быть в зависимости от требований к системе:
- Внутренним числовым кодом, полученным по SEQUENCE, для использования в ссылках на эту запись
- Символьной строкой составного ключа для внешнего смыслового использования, например регистрационного номера объекта и его версии (паспорт + дубликаты, страховые полюса, номер документа, накладной, акта, договора и т.п.). Может включать дату рождения, пол, регион проживания, контрольную сумму
- DN - дата начала действия записи
- DK - дата конца действия записи
- Формируется VER_OF_PID - версия объекта. Это номер внутри одного объекта. Для одного объекта одно значение VER_OF_PID соответствует одному периоду действия записи, т.е. паре DN, DK.
- Преобразование логических полей. Это может быть, например, нормализация:
- Замена символьных полей на коды из справочников
- Разделение записи исходной таблицы на две:
- Master
- Detail
- Формируется ID. Это код экземпляра информации об объекте в определенном временном интервале. Он может быть в зависимости от требований к системе:
- Если при вставке или изменении записи происходит исключительная ситуация, то необходимо такую запись не потерять. Потом ее не найдешь. Проверено. Для этого ее необходимо вставить в ERROR_TABLE. Эта таблица НЕ ДОЛЖНА содержать проверок ограничений целостности. Иначе запись будет потеряна.
- Если при вставке записи в таблицу ERROR_TABLE происходит исключительная ситуация, то производится запись в протокольную таблицу с указанием первичного ключа исходной записи.
- Если при вставке или изменении в любую таблицу происходит переполнение автораширяемого табличного пространства, то необходимо остановить выполнение процедуры для исправления ситуации и перезапуска с точки останова. Хранится в специальной таблице число прочитанных и обработанных записей исходной таблицы. При повторном запуске их обработка пропускается. Предполагается, при этом, что запрос на чтение записей исходной таблицы будет произведен последовательно в том же порядке, что и в предыдущий раз.
- Фиксация транзакции производится при обработке 1000 записей исходной таблицы, либо при записи в протокольную таблицу.
- При фиксации транзакции формируется запись в протокольной таблице о количестве обработанных записей, количестве вставленных, измененных, повторяющихся (при повторной загрузке) и ошибочных записей.
- Поиск объекта в результирующей таблице H_TABLE по 8 различным условиям поиска, используя составных 5 индексов.
- Формируется итоговая информация о работе процедуры с записью в протокольную таблицу.
- Выгрузка из базы данных среза информации на текущую дату для передачи в другие организации.
Необходимо обратно денормализовать информацию. И получить DBF файл.
- Опять применяется механизм "СREATE TABLE …. UNRECOVERABLE AS SELECT" над читаемым табличным пространством в READ ONLY состоянии и последующий
"FULL UPDATE … SET = (SELECT NAME FROM <справочник> WHERE …)"
по каждой колонке, что дает многократное преимущество JOIN соединению, естественно, отлаженному по EXPLAIN PLAN. - Затем запускается написанная программа UNLOAD с использованием OCI для получения DBF файла по написанному SQL-запросу.