
В первых двух статьях этой серии рассказывалось об установке и настройке Hadoop в одноузловой и многоузловой конфигурациях. В этой, заключительной статье будут рассмотрены вопросы программирования в Hadoop, в частности, написание приложения MapReduce на языке Ruby. Я выбрал Ruby потому, что, во-первых, это великолепный объектно-ориентированный язык сценариев, который вам следует знать. При рассмотрении программирования MapReduce я также познакомлю вас с потоковым интерфейсом прикладного программирования (API). Этот API-интерфейс предназначен для разработки приложений на языках, отличных от Java.
Давайте начнем с короткого знакомства с операциями map и reduce (рассматривая их с точки зрения функционала), после чего перейдем к более детальному рассмотрению модели программирования фреймворка Hadoop и его элементов, которые формируют задания, распределяют их и управляют всей работой в целом.
Происхождение операций map и reduce
Итак, благодаря каким же функциональным элементам родилась концепция программирования MapReduce? В 1958 году Джон МакКарти (John McCarthy) изобрел язык программирования Lisp , который мог выполнять как числовые, так и символьные вычисления в рекурсивной форме, не присущей большинству сегодняшних языков программирования (в Википедии есть прекрасная статья об истории языка Lisp, включающая учебное руководство, которую действительно стоит прочесть). Впервые Lisp был реализован в первой массово продаваемой ЭВМ IBM® 704, в которой также присутствовала поддержка другого старого фаворита - языка FORTRAN.
Операция map, унаследованная из функциональных языков программирования, таких как Lisp, а теперь распространенная во многих других языках, означает применение определенной функции к списку элементов. Что это означает? В листинге 1 представлена интерпретированная сессия программной оболочки Scheme Shell (SCSH), являющейся производной от Lisp. Первая строка определяет функцию под названием square, которая принимает аргумент и возводит его в квадрат. В следующей строке продемонстрировано использование операции map. Как видно, с ее помощью вы указываете имя вашей функции и список элементов, к которым она должна применяться. Результатом является новый список, содержащий возведенные в квадрат элементы.
Листинг 1. Демонстрация использования операции map в SCSH
|
> (define square (lambda (x) (* x x))) > (map square '(1 3 5 7)) '(1 9 25 49) > |
Операция компоновки (reduce) также применяется к списку, но, как правило, в этом случае список приводится к скалярному значению. Пример, приведенный в листинге 2, содержит еще одну функцию SCSH, которая преобразует список в скалярную величину - в данном случае выполняется суммирование списка значений в форме (1 + (2 + (3 + (4 + (5))))). Заметьте, что это классическое функциональное программирование, опирающееся на рекурсию посредством итерации.
Листинг 2. Демонстрация компоновки в SCSH
|
> (define (list-sum lis) (if (null? lis) 0 (+ (car lis) (list-sum (cdr lis))))) > (list-sum '(1 2 3 4 5)) 15 > |
Интересно заметить, что в императивных языках рекурсия так же эффективна, как и итерация, поскольку рекурсия в конечном итоге преобразуется в итерацию.
Модель программирования Hadoop
Компания Google представила идею использования MapReduce в качестве модели программирования для обработки или генерации больших объемов данных. В канонической модели операция map обрабатывает пары вида "ключ-значение", формируя в результате промежуточный набор таких же пар. После этого операция reduce обрабатывает полученный промежуточный набор, объединяя значения для связанных ключей (рисунок 1). Входные данные разбиваются на части таким образом, чтобы их можно было распределить между узлами кластера с целью параллельной обработки. Точно так же, полученные промежуточные данные обрабатываются параллельно, благодаря чему такой метод идеально подходит для обработки очень больших объемов данных.
Рисунок 1. Упрощенное представление работы MapReduce
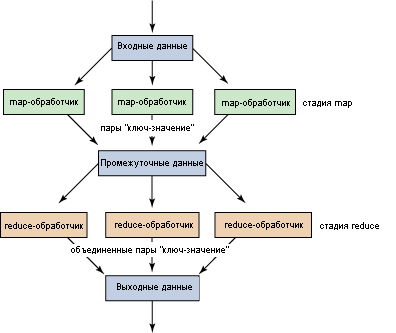
Посмотрите на архитектуру, изображенную на рисунке 1, с точки зрения использования операций map и reduce для подсчета слов (поскольку в этой статье вы будете разрабатывать приложение MapReduce). При получении входных данных (в файловой системе Hadoop [HDFS]) они сначала разбиваются на части, а затем передаются распределенным map-обработчикам (с помощью служб jobtracker). Хотя на рисунке 2 делится на части короткое предложение, обычно размер разбиваемого задания лежит в пределах 128 МБ по одной причине: на подготовку задания уходит некоторое количество времени, поэтому чем больше данных обработает задание, тем меньше будут эти издержки. Map-обработчики (в каноническом примере) разбивают обработку на отдельные массивы, содержащие отмеченное слово и начальное значение (в данном случае 1). Когда все задания map завершены (в соответствии с тем, как они определены в Hadoop с помощью службы tasktracker), в работу вступает reduce-обработчик, который компонует ключи в уникальный набор, отображающий количество найденных ключей.
Рисунок 2. Простой пример MapReduce
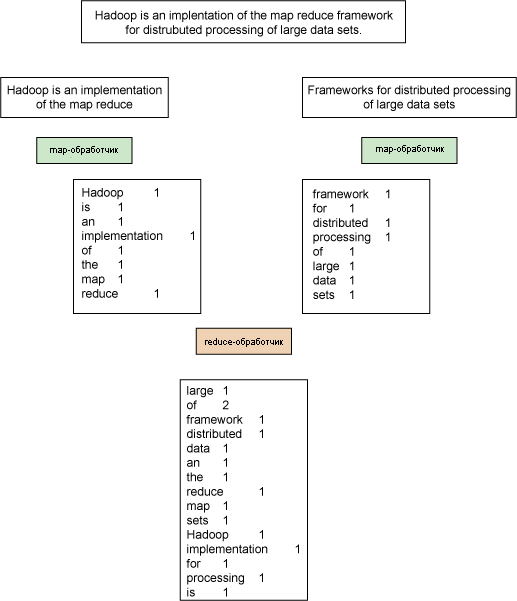
Обратите внимание на то, что процесс может выполняться на одном или нескольких компьютерах, последовательно или параллельно с различным распределением данных, тем не менее результат будет одним и тем же.
Хотя каноническое представление (для генерации поискового индекса с использованием подсчета слов) является одним из способов представления Hadoop, оно показывает, что эта модель вычислений в общем случае может быть применена к целому ряду вычислительных задач, в чем вы скоро убедитесь.
Обратите внимание, что в простом примере, изображенном на рисунке 2, двумя главными элементами являются процессы map и reduce. Несмотря на то, что здесь показана традиционная работа этих процессов, архитектура не требует, чтобы они выполнялись именно так. Настоящая сила Hadoop заключается в его гибкости, позволяющей реализовывать процессы map и reduce в соответствии с конкретной задачей. Пример с подсчетом слов полезен и применим к широкому ряду задач, но другие модели также укладываются в рамки этого общего фреймворка. Все, что для этого требуется - разработать приложения map и reduce, обеспечивающие доступность процессов для Hadoop.
Наряду с другими приложениями Hadoop использовался даже для приложений машинного обучения, содержащих такие разнообразные алгоритмы, как нейронные сети, поддержка векторных машин и k -means кластеризация.
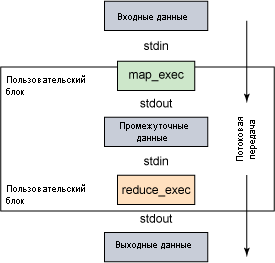
Несмотря на то, что фреймворк Hadoop основан на Java, можно писать приложения map и reduce на различных языках программирования, отличных от Java. Это возможно, благодаря потоковой передаче данных. Утилита streaming из состава Hadoop содержит связующие компоненты для организации потоков данных. С помощью этой утилиты вы можете определять свои собственные исполняемые файлы для операций map и reduce (каждый из которых принимает данные со стандартного устройства ввода [stdin] и передает результат на стандартное устройство вывода [stdout]), а утилита streaming надлежащим образом считывает и записывает данные, обращаясь к вашим приложениям по мере необходимости (листинг 3).
Листинг 3. Использование утилиты потоковой передачи данных
|
hadoop jar $HADOOP_HOME/hadoop-streaming.jar -input inputData -output outputData -mapper map_exec -reducer reduce_exec |
В листинге 3 показано, как использовать утилиту streaming, а на рисунке 3 представлено определение потока данных в графическом виде. Обратите внимание на то, что это лишь простой пример использования потоковой передачи. Существует множество различных опций, позволяющих выполнять разбор данных, вызывать образы, указывать образы замены для разделителя и объединителя, а также выполнять другие конфигурационные хитрости.
Рисунок 3. Графический пример потоковой передачи данных
Познакомившись с основными возможностями утилиты streaming, можно приступить к написанию простого Ruby-приложения MapReduce и посмотреть, как можно использовать процессы внутри фреймворка Hadoop. Приведенный здесь пример начинается с канонического приложения MapReduce, но позже вам будут продемонстрированы и другие приложения (а также то, как можно реализовать их в форме операций map и reduce).
Начнем с mapper-приложения. Этот сценарий принимает текстовые данные со стандартного устройства ввода stdin, маркирует их, разбивает на пары "ключ-значение" и передает эти пары на стандартное устройство вывода stdout. Как и для большинства объектно-ориентированных языков сценариев, эта задача является достаточно простой. Небольшой код mapper-сценария приведен в листинге 4. В этой программе используются два итератора: один для считывания строки со стандартного устройства ввода, а другой - для разделения полученной строки на отдельные маркеры. Затем каждый маркер (слово) передается на стандартное устройство вывода stdout вместе с соответствующим значением, равным 1 (маркер и значение разделяются знаком табуляции).
Листинг 4. Map-сценарий Ruby (map.rb)
|
#!/usr/bin/env ruby # Наши входные данные поступают с устройства STDIN STDIN.each_line do /line/ # Выполняем итерации для каждой строки, отделяя слова от строки # и преобразуя их в слова со счетчиком, равным 1. line.split.each do /word/ puts "#{word}\t1" end end |
Теперь перейдем к reduce-приложению. Оно ненамного сложнее, но использует хэш (ассоциативную матрицу) Ruby для упрощения операции компоновки (листинг 5). Этот сценарий тоже работает с входными данными, полученными с устройства stdin (переданными утилитой streaming), и разбивает строку на две части: слово и значение. Затем начинается поиск этого слова в хэше, и в случае его нахождения для элемента добавляется счетчик, показывающий, сколько раз это слово было найдено. В противном случае для слова создается новая запись в хэше и загружается счетчик (значение которого должно быть получено из mapper-процесса и равно 1). По окончании обработки всех входных данных выполняется простая итерация по всему хэшу, после чего пары "ключ-значение" передаются на устройство stdout.
Листинг 5. Reduce-сценарий Ruby (reduce.rb)
|
#!/usr/bin/env ruby # Создаем пустой хэш слов wordhash = {} # Наши входные данные поступают с устройства STDIN, обрабатывающего каждую строку STDIN.each_line do /line/ # Каждая строка представляет собой слово и счетчик word, count = line.strip.split # Если хэш уже содержит слово, добавляем к нему счетчик, # в противном случае, создаем новое if wordhash.has_key?(word) wordhash[word] += count.to_i else wordhash[word] = count.to_i end end # Выполняем итерации и создаем счетчики слов wordhash.each {/record, count/ puts "#{record}\t#{count}"} |
Теперь, когда сценарии map и reduce готовы, давайте протестируем их с помощью командной строки. Не забудьте добавить к этим сценариям флаг исполнения с помощью команды chmod +x. Начнем с создания входного файла, как показано в листинге 6.
Листинг 6. Создание входного файла
|
# echo "Hadoop is an implementation of the map reduce framework for " "distributed processing of large data sets." > input # |
С помощью этих входных данных мы можем проверить работу mapper-сценария, как показано в листинге 7. Вспомните, что этот сценарий просто разбивает входные данные на пары "ключ-значение", значение каждой из которых будет равным 1 (не уникальные входные данные).
Листинг 7. Проверка mapper-сценария
|
# cat input / ruby map.rb Hadoop 1 is 1 an 1 implementation 1 of 1 the 1 map 1 reduce 1 framework 1 for 1 distributed 1 processing 1 of 1 large 1 data 1 sets. 1 # |
Пока все работает хорошо. Теперь соберем все компоненты приложения в форме конвейера (Linux® pipes). В листинге 8 входные данные передаются в map-сценарий, сортируется полученный вывод (не обязательный шаг) и затем результирующие промежуточные данные передаются в reduce-сценарий.
Листинг 8. Простое приложение MapReduce с использованием конвейеров Linux
|
# cat input / ruby map.rb / sort / ruby reduce.rb large 1 of 2 framework 1 distributed 1 data 1 an 1 the 1 reduce 1 map 1 sets. 1 Hadoop 1 implementation 1 for 1 processing 1 is 1 # |
Мы убедились, что сценарии map и reduce работают в программной оболочке, и теперь давайте протестируем их с помощью Hadoop. Здесь я не буду рассматривать процесс установки и настройки Hadoop (для получения этой информации обратитесь к первой или второй части этой серии).
Прежде всего необходимо создать директорию в файловой системе HDFS для хранения входных данных, а также тестовый файл, с которым будут работать ваши сценарии. Эти шаги показаны в листинге 9 (для получения дополнительной информации обратитесь к первой или второй части этой серии).
Листинг 9. Создание входных данных для процесса MapReduce
|
# hadoop fs -mkdir input # hadoop dfs -put /usr/src/linux-source-2.6.27/Documentation/memory-barriers.txt input # hadoop fs -ls input Found 1 items -rw-r--r-- 1 root supergroup 78031 2010-06-04 17:36 /user/root/input/memory-barriers.txt # |
Теперь с помощью утилиты streaming запустим Hadoop вместе с нашими сценариями, указав входные данные и местоположение выходных данных (листинг 10). Обратите внимание на то, что параметры -file в этом примере просто указывают Hadoop считать Ruby-сценарии частью выполняемого задания.
|
# hadoop jar /usr/lib/hadoop-0.20/contrib/streaming/hadoop-0.20.2+228-streaming.jar -file /home/mtj/ruby/map.rb -mapper /home/mtj/ruby/map.rb -file /home/mtj/ruby/reduce.rb -reducer /home/mtj/ruby/reduce.rb -input input/* -output output packageJobJar: [/home/mtj/ruby/map.rb, /home/mtj/ruby/reduce.rb, /var/lib/hadoop-0.20/... 10/06/04 17:42:38 INFO mapred.FileInputFormat: Total input paths to process : 1 10/06/04 17:42:39 INFO streaming.StreamJob: getLocalDirs(): [/var/lib/hadoop-0.20/... 10/06/04 17:42:39 INFO streaming.StreamJob: Running job: job_201006041053_0001 10/06/04 17:42:39 INFO streaming.StreamJob: To kill this job, run: 10/06/04 17:42:39 INFO streaming.StreamJob: /usr/lib/hadoop-0.20/bin/hadoop job ... 10/06/04 17:42:39 INFO streaming.StreamJob: Tracking URL: http://localhost:50030/... 10/06/04 17:42:40 INFO streaming.StreamJob: map 0% reduce 0% 10/06/04 17:43:17 INFO streaming.StreamJob: map 100% reduce 0% 10/06/04 17:43:26 INFO streaming.StreamJob: map 100% reduce 100% 10/06/04 17:43:29 INFO streaming.StreamJob: Job complete: job_201006041053_0001 10/06/04 17:43:29 INFO streaming.StreamJob: Output: output # |
Наконец, проверим выходные данные с помощью файловой операции cat утилиты hadoop (листинг 11).
Листинг 11. Проверка выходных данных Hadoop
|
# hadoop fs -ls /user/root/output Found 2 items drwxr-xr-x - root supergroup 0 2010-06-04 17:42 /user/root/output/_logs -rw-r--r-- 1 root supergroup 23014 2010-06-04 17:43 /user/root/output/part-00000 # hadoop fs -cat /user/root/output/part-00000 / head -12 +--->/ 4 immediate 2 Alpha) 1 enable 1 _mandatory_ 1 Systems 1 DMA. 2 AMD64 1 {*C,*D}, 2 certainly 2 back 2 this 23 # |
Итак, реализация элементов map и reduce и демонстрация их работы внутри фреймворка Hadoop заняли менее 30 строк. Несмотря на свою простоту, этот пример демонстрирует реальную мощь Hadoop и объясняет, почему этот фреймворк пользуется такой популярностью при обработке больших объемов данных с использованием пользовательских или проприетарных алгоритмов.
Помимо простого вычисления количества слов в больших массивах данных, Hadoop может использоваться в различных приложениях. Все, что для этого нужно - представить данные в векторном формате, который может использоваться инфраструктурой Hadoop. Несмотря на то, что канонические примеры используют векторное представление в виде ключа и значения, вы можете определять значение в любой форме (например, в виде числовой суммы нескольких значений). Такая гибкость открывает новые возможности для использования Hadoop в самых разнообразных приложениях.
Одно из интересных применений, которое хорошо укладывается в модель MapReduce для подсчета слов - это составление таблицы частоты посещений Web-ресурсов (рассматривается в документации Google). В этом приложении в качестве ключей выступают посещаемые URL-адреса (содержащиеся в log-файлах сервера). Результатом процедуры прореживания данных (reduce) является общее количество посещений каждого URL-адреса для заданного Web-сайта, вычисляемое на основе анализа журналов Web-сервера.
В приложениях машинного обучения Hadoop используется в качестве способа масштабирования генетических алгоритмов для обработки большого количества их экземпляров (потенциальных решений). Операция map выполняет традиционный генетический алгоритм, выбирая наилучшее отдельное решение из локального пула. Операция reduce организует конкурс для выбора решения из тех, что были найдены на стадии map. Это позволяет отдельным узлам находить свои наилучшие решения, а затем прореживать их на стадии reduce для распределенного выбора наиболее подходящего.
Другое интересное приложение было написано для выявления botnet-сетей, рассылающих спам по электронной почте. На первом шаге этого процесса выполняется классификация поступающих от заданной организации электронных сообщений с целью их прореживания (на основе ряда признаков). На основе этих отфильтрованных данных строится график по определенным признакам (например, все сообщения, тело которых содержит одну и ту же ссылку). Затем все схожие сообщения прореживаются до уровня хостов (статические или динамические IP-адреса) для определения botnet-сетей, о которых идет речь.
Помимо приложений, оперирующих базовыми функциями map и reduce, Hadoop используется для распределения работы между компьютерными кластерами. Операции map и reduce не обязательно требуют использования приложений определенного типа. Вместо этого Hadoop может рассматриваться в качестве способа распределения данных и алгоритмов между различными узлами с целью более быстрой параллельной обработки.
Хотя Hadoop является достаточно гибким фреймворком, существуют и другие приложения, интерфейс которых может взаимодействовать с другими программами. Одним из интересных примеров является Hive - инфраструктура хранилища данных со своим собственным языком запросов (под названием Hive QL ), разработанная на основе Hadoop. Hive делает Hadoop более доступным для тех, кто знает основы языка Structured Query Language (SQL), но также поддерживает и традиционную инфраструктуру MapReduce для обработки данных.
Другая интересная система, основанная на HDFS, это HBase - высокопроизводительная СУБД, похожая на Google BigTable. Вместо традиционной обработки файлов HBase создает из таблиц БД входные и выходные формы для обработки с помощью MapReduce.
Наконец, Pig - платформа на базе Hadoop для анализа больших объемов данных. Pig имеет встроенный высокоуровневый язык, компилирующий приложения map и reduce.
Заключительная часть серии статей о Hadoop была посвящена написанию приложения MapReduce для фреймворка Hadoop на языке Ruby. Я надеюсь, что эта статья поможет вам оценить настоящую мощь Hadoop. Хотя Hadoop и ограничивает вас рамками специфической модели программирования, это достаточно гибкая модель, и ее можно применять для разработки большого числа приложений.