
 Как-то так получается, что во многих системах, с которыми мне приходилось работать были свои компонентные модели или дело шло к тому, что они должны были появиться в данной системе, так как уже приходило понимание того, что уже нужна декомпозиция и коду системы в одном модуле существовать все труднее и труднее.
Как-то так получается, что во многих системах, с которыми мне приходилось работать были свои компонентные модели или дело шло к тому, что они должны были появиться в данной системе, так как уже приходило понимание того, что уже нужна декомпозиция и коду системы в одном модуле существовать все труднее и труднее.
Имеет ли смысл что-то подобное писать или взять готовое решение. Свое видение по этому вопросу я описывал в статье "О желании изобретать один и тот же велосипед снова и снова". Так что в данной статье не будет философии на тему "А зачем оно нужно".
Ранее я уже публиковал статью "Своя компонентная модель на C++", в которой была разработана компонентная / плагинная модель, живущая в рамках процесса. Для меня решение подобной задачи интересно. В gcc 4.7.2 уже появилось все, что мне было интересно на момент начала этой статьи, а это начало этого (2013) года. И тут я дорвался до C++ 11… На работе в одном направлении, дома в другом. Чтобы поиграться с C++ 11 я и решил переписать материал из старой статьи с новыми возможностями языка. Сделать в некотором смысле упражнение на C++. Но в силу некоторых причин мне не удавалось довести материал статьи до конца более полугода, и статья провалялась в черновиках нетронутой. Достал, стряхнул нафталин. Что из этого получилось можете прочесть далее.
О решении использовать C++ 11
Мы ждали, ждали и наконец-то дождались выхода обновлений C++. Вышел новый стандарт языка - C++ 11. Данная редакция языка программирования принесла много интересных и полезных возможностей, а стоит ли его использовать это пока спорный вопрос, но не все компиляторы его поддерживают или поддерживают в неполном объеме.

Введение и немного философии
Тут будет немного рассказано о том, на каких принципах построена данная реализация плагинной системы или компонентной модели и почему выбран тот, а не иной путь. Будет вылито некоторое количество воды: мои размышления. Если вас не интересует подобное философствование, то смело переходите к реализации.
Интерфейсы и идентификаторы
В основу описываемой разработки будет положено взаимодействие компонент системы посредством интерфейсов. Интерфейс в данном контексте стоит понимать как C++ структуру, содержащую только чисто виртуальные методы. Интерфейс будет некоторой логической единицей, вокруг которой все постороено.
Одним из немаловажных вопросов может быть - что использовать в качестве идентификатора интерфейса, реализации, модуля и прочих сущностей. В предыдущей статье в качестве идентификатора использовалась C-строка, так как можно обеспечить большую уникальность если, например, в качестве идентификатора использовать uuid, сгенерированный каким-нибудь инструментом и переведенным в строку. Можно в качестве идентификатора использовать и числовой идентификатор. У такого решения уникальность будет более слабой, но есть преимущества - это, как минимум, большая производительность, что очевидно, сравнивать строки более трудоемко нежели числа. В качестве значения числового идентификатора можно использовать например CRC32 от строки. Предположим есть интерфейс Ibase и находится он в пространстве имен Common. В качестве идентификатора может стать CRC32 от строки "Common.IBase". Да, если вдруг совпадут где-то идентификаторы интерфейсов, так как это не uuid, то вы получите долгие часы "счастливой" отладки и неплохо прокачаетесь в освоении сильной стороны русского языка. Но если у вас нет амбиций, что вашу модель будут использовать во всем мире в глобальных системах, то вероятность исхода с долгой отладкой минимальна. В паре контор имел дело со своими "поделками" в стиле MS-COM'а, в которых в качестве идентификатора использовались числовые значения и не натыкался на проблему описанную выше, да и слухов, что у кого-то она возникала тоже не было. Следовательно, в данной реализации будет использован числовой идентификатор. Кроме производительности от такого решения есть еще один положительный момент: с числовым идентификатором в момент компиляции можно сделать много интересного, так как манипулировать строками как параметрами шаблонов не получится, а числом легко. И тут как раз первый плюс C++ 11 будет использован - это constexpr, с использованием которого можно вычислять значения хэшей в момент компиляции.
Кроссплатформенность и поддержка со стороны языка
Описываемая модель будет кроссплатформенной. Кросс чего-то там - это один из интересных моментов в разработке. Для C++ разработчика одна из наиболее понятных задач - это поддержка кроссплатформенности, но реже встречаются и задачи, связанные с кросскомпиляцией, так как то, что легко поддерживается одним компилятором, на ином может не поддерживаться. Один из таких примеров - это до появления реализации decltype попытки реализации получения типа выражения в момент компиляции. Хороший пример - BOOST_TYPEOF. Если заглянуть "под капот" BOOST_TYPEOF, вы обнаружите немалый набор палок и костылей, так как подобные вещи не могли быть реализованы с использованием C++ 03, а решались в основном на каких-то расширенных возможностях конкретного компилятора. Так же в C++ 11 расширилась стандартная библиотека, которая дала возможность отказаться от написания собственных оберток над потоками, объектами синхронизации и т.д. За библиотечные функции по поддержке типов разработчикам стандарта можно сказать отдельное спасибо, так как избавили от необходимости написания своего кода во многих случаях, и, самое главное, дали реализацию таких методов как std::is_pod и прочих, реализовать которые стандартными средствами языка C++ 03 без использования расширений компиляторов было невозможно.
Использовать ли сторонние библиотеки
Было желание минимизировать использование сторонних библиотек и по возможности свести их использование к нулю. Это будет разработка на чистом C++. При реализации конечных компонент может быть использовано что угодно в силу задачи, любые библиотеки, но сама модель, приводимая здесь, будет в смысле использования сторонних библиотек чистой.
К использованию сторонних библиотек у меня сложилось определенное отношение: не использовать библиотеку в проекте если ее функционал не используется клиентским кодом максимально возможным образом. Не стоит тащить в проект Qt только потому что некоторым нравится использовать QStrung и QList. Да, встречал проекты, в которых были притянуты за уши некоторые библиотеки и фреймворки только ради того, чтоб использовать какую-то малую и неважную ее часть просто из-за привычки некоторых разработчиков. В целом же, нельзя отрицать использование таких библиотек как boost, Qt, Poco и прочих, но они должны применяться к месту, включаться в проект только когда в них есть большая необходимость. Не стоит разводить зоопарк, так, завести в проекте пару-тройку экзотических зверушек и не более :) чтоб не получить проект в котором есть штук 5-7, а то и более типов строк, 2-3 из которых - это собственные велосипеды, а остальные пришедшие из других библиотек и написанная куча конвертеров из одних реализаций в другие. Как результат разработанная программа вместо полезной работы тратит вполне может быть заметное время на конвертацию между разными реализациями одних и тех же сущностей.
Boss...
Как-то привык я раскладывать код по пространствам имен. В качестве названия пространства имен и всей модели будет выбрано Boss (base objects for service solutions). Об истоках происхождения имени можно прочесть впредыдущей статье на эту тему. В комментариях к статье было отмечено, что "Boss" может смущать в коде, в силу напоминании о начальстве и стереотипах с этим связанных. Изначально не было цели сделать акцент в названии на некоторого "насяльника" (© Наша Раша). Но если у кого-то вызывает негативные ассоциации, то почему бы не посмотреть под другим углом на это? Есть замечательная книга Кена Бланшара "Лидерство к вершинам успеха", в которой описываются высокоэффективные организации и руководители-слуги, цель которых сделать максимум, чтобы работнику дать все для его работы с максимальной производительностью, а не просто стоять с палкой за спиной. Т.е. руководитель - помощник в организации эффективной работы. Boss желательно воспринимать как руководителя в высокоэффективной организации, который помогает сотрудникам достичь максимальной производительности, обеспечивая их всем необходимым для этого. В рамках компонентной модели - это именно помощь в организации тонкой прослойки для более простого взаимодействия сущностей в системе, а не монструозный фреймворк с которым надо бороться и большая часть работы направлена только на работу с ним, а не на бизнес-логику.
Минимализм в интерфейсе
Один из критериев, который для меня играет немаловажную роль при рассмотрении очередной библиотеки - это скорость начала работы с библиотекой и предоставление ею все более и более расширенных возможностей по ее настройке под задачу. Т.е библиотека не должна заставлять совершать ее пользователя очень длинный ритуал перед тем как что-то начнет работать с ее использованием. Но при этом, по мере необходимости, должна быть возможность получить все больше и больше возможностей по ее настройке и приспособлению к более трудным задачам. Т.е. изначально вот тебе кнопка "Пыщь", по нажатию на которую по определенному шаблону совершается некоторая последовательность действий, а при необходимости вот пульт управления с кучей кнопок и переключателей. Эта идея и была одной из заложенных в предлагаемую модель: скрыть от пользователя как можно больше на начальных этапах. Внутри библиотек код может быть сколь угодно сложным, но всей своей сложностью он должен оправдывать максимальную простоту использования самой библиотеки.
Множественное наследование реализаций
О множественном наследовании реализаций на просторах интернета велось и ведется немало священных войн. Я считаю, что множественное наследование - это одна из сильных сторон C++. Да, местами с ним имеются проблемы, но без него так же не всегда удается легко выкрутиться. Каждый инструмент C++ предназначен не для того, чтобы его как-то взять и использовать только потому что он есть, а когда появится необходимость, то вот и инструмент имеется.
Когда мне начинают воспевать преимущества языков с множественным наследованием только интерфейсов, я люблю спрашивать о решении примерно следующей задачи. Предположим есть два интерфейса и по реализации для каждого. Эти интерфейсы и реализации используются в проекте какое-то немалое время. Да, проблема дизайна и жирные интерфейсы это плохо, но скажем эти интерфейсы имеют более чем по десятку методов, и соответственно их реализации все это реализуют. И вот появляется необходимость реализовать компонент с функционалом этих двух сущностей, но с реализацией еще одного третьего интерфейса. С поддержкой множественного наследования реализаций все решается просто: делается класс, производный от нового интерфейса и от двух существующих реализаций и реализуются только методы нового третьего интерфейса. А вот с поддержкой только множественного наследования интерфейсов такого простого решения не будет.
Тут конечно можно развести немалую дискуссию о дизайне системы, но реальная практика не бывает столь идеалистична как теоретический дизайн кода.
Как-то на собеседовании я спросил кандидата (далеко не юнца) о том, что он знает о множественном наследовании. Ответ был примерно таков: "Да, я знаю что есть множественное наследование и, вроде бы как, есть и виртуальное множественное наследование, но это плохо. Я этим никогда не пользуюсь. И более ничего о нем сказать не могу".
Если вы хотите делать новые сущности, набирая их из кубиков-готовых сущностей, то множественное наследование один из полезнейших механизмов. А компонентные модели просто раздолье для построения чего-то нового из кусочков из чего-то уже существующего.
Реализация

Ядро
Как уже отмечалось, все построено вокруг интерфейсов - C++ структур с чисто виртуальными методами и некоторой примесью (идентификатором интерфейса).
Базовый интерфейс, от которого должны наследоваться все существующие в этой реализации:namespace Boss { struct IBase { BOSS_DECLARE_IFACEID("Boss.IBase") virtual ~IBase() {} BOSS_DECLARE_IBASE_METHODS() }; }
Мда, виртуальный деструктор и пара макросов… Многие воскликнут: "Макросы - это же плохо!" Да, плохо при их избытке и применении где попало. В небольших количествах и только при необходимости это бывает полезно, как яд в фармакологии - убивает и лечит в зависимости от дозировки.
добавляет некоторый статический метод, с помощью которого можно получить идентификатор интерфейса. Так как статический метод никак не повлияет на структуру данных, следовательно, можно смело передавать интерфейс между модулями, собранными даже на разных компиляторах, а constexpr позволит полученное значение использовать и при параметризации шаблонов.
Как идентификатор интерфейса параметром макроса передается строка. Как-то строки более приятно смотрятся в коде нежели сухие числа, да и надо иметь некоторый набор данных, от которого генерировать числовой идентификатор. В качестве идентификатора выбран crc32 от строки. И вот она сила нового стандарта: можно считать crc32 и прочие вещи от строк в момент компиляции! Такой трюк, конечно, не выйдет со строками динамически создаваемыми в программе, да и не пригодится для решения данной задачи.
Для реализации расчета crc32 потребуется некоторая таблица с данными, которую можно легко найти в интернете. С ее помощью считать crc32 можно примерно таким образом:namespace Boss { namespace Private { template <typename T> struct Crc32TableWrap { static constexpr uint32_t const Table[256] = { 0x00000000L, 0x77073096L, 0xee0e612cL, 0x990951baL, 0x076dc419L, 0x706af48fL, 0xe963a535L, 0x9e6495a3L, 0x0edb8832L, 0x79dcb8a4L, ... etc }; }; typedef Crc32TableWrap<EmptyType> Crc32Table; template<int const I> inline constexpr std::uint32_t Crc32Impl(char const *str) { return (Crc32Impl < I - 1>(str) >> 8) ^ Crc32Table::Table[(Crc32Impl< I - 1>(str) ^ str[I]) & 0x000000FF]; } template<> inline constexpr std::uint32_t Crc32Impl<-1>(char const *) { return 0xFFFFFFFF; } } template <std::size_t N> inline constexpr unsigned Crc32(char const (&str)[N]) { return (Private::Crc32Impl<sizeof(str) - 2>(str) ^ 0xFFFFFFFF); } }
Почему таблица завернута в структуру, да еще и в шаблон? Чтобы избавиться от cpp-файла с определением данных, т.е. все только в подключаемом файле и без прелестей static-данных в подключаемых файлах.
Crc32 рассчитан, идентификатор сформирован. Теперь к рассмотрению того, что кроется под вторым макросом:
Однако! Неужто нельзя было просто взять и поместить три метода в структуру? Зачем макрос? И добить вопросом о наличии родственников в Индии… Но так как от множественного наследования нет отказа и, более того, оно очень приветствуется в данной модели, то для того чтобы успокоить тревоги компилятора о том что ему не понятно из какой ветки наследования брать какой-нибудь из методов, описанных под макросом, этот макрос будет использован еще в нескольких местах.
Управление временем жизни объектов реализовано через подсчет ссылок. В функции интерфейса IBase входят методы для работы со счетчиком ссылок и метод для запроса интерфейсов у объекта.
Пример определения пользовательского интерфейса:struct IFace : Boss::Inherit<Boss::IBase> { BOSS_DECLARE_IFACEID("IFace") virtual void BOSS_CALL Mtd() = 0; }; Почти все понятно: интерфейс, объявление его методов, определение идентификатора. Но почему просто не сделать наследование от Ibase?
Второй пример пользовательского интерфейса, чтоб дальнейшее объяснение было понятнее:
struct IFace1 : Boss::Inherit<Boss::IBase> { BOSS_DECLARE_IFACEID("IFace1") virtual void BOSS_CALL Mtd1() = 0; }; struct IFace2 : Boss::Inherit<Boss::IBase> { BOSS_DECLARE_IFACEID("IFace2") virtual void BOSS_CALL Mtd2() = 0; }; struct IFace3 : Boss::Inherit<IFace1, IFace2> { BOSS_DECLARE_IFACEID("IFace3") virtual void BOSS_CALL Mtd3() = 0; };
Теперь все раскрылось? Нет? Все просто: при наличии множественного наследования даже только интерфейсов нужно как-то иметь возможность их "обходить" в поисках нужного при реализации QueryInterface. Случай немного эзотерический, но иногда я натыкался на подобное. Предположим у вас есть указатель на IFace3, понятно, что все методы его базовых классов вы можете тут на месте и вызвать. А если передать его в иную функцию, более обобщенную, которая от некоторого интерфейса, необязательно с такой структурой наследования, всегда запрашивает IFace1 или IFace2, то она уже не на C++ механизмы опирается, а на реализованный QueryInterface, реализации которого надо как-то эту иерархию обойти. Вот тут-то и пригождается некоторая примесь: Boss::Inherit, которая имеет следующую реализацию:
namespace Boss { template <typename ... T> struct Inherit : public T ... { virtual ~Inherit() {} typedef std::tuple<T ... > BaseInterfaces; BOSS_DECLARE_IBASE_METHODS() }; }
Данная примесь просто наследуется от переданного списка базовых интерфейсов, "успокаивает" компилятор от неразборчивости выбора нужного метода (использование BOSS_DECLARE_IBASE_METHODS) и "прикапывает" список унаследованных интерфейсов. Тут новый стандарт дает такое преимущество как шаблоны с переменным количеством параметров. Ура, дождались! Ранее это решалось через громоздкие списки типов в стиле Александреску. Ну также тут новые "плюсы" еще дали бонус в виде кортежа, избавив от написания своего аналогичного велосипеда.
Как, от чего и почему определить пользовательские интерфесы рассмотрено, но их где-то и как-то надо реализовывать. Для начала маленький пример реализации интерфейсов:struct IFace1 : Boss::Inherit<Boss::IBase> { BOSS_DECLARE_IFACEID("IFace1") virtual void Mtd1() = 0; }; class Face_1 : public Boss::CoClass<Boss::Crc32("Face_1"), IFace1> { public: virtual void Mtd1() { // TODO: } };
со всеми "подлостями" для реализации, которые она должна будет разобрать. Понятно, что можно наворотить больший хаос. Приведенный пример описывает возможности реализации в построении "из кубиков".
Трудно не заметить, что каждая реализация наследуется от CoClass. CoClass имеет весьма простую реализацию:namespace Boss { template <ClassId ClsId, typename ... T> class CoClass : public virtual Private::CoClassAdditive , public T ... { public: typedef std::tuple<T ... > BaseEntities; CoClass() : Constructed(false) { } // IBase BOSS_DECLARE_IBASE_METHODS() private: template <typename Y> friend void Private::SetConstructedFlag(Y *, bool); template <typename Y> friend bool Private::GetConstructedFlag(Y *); bool Constructed; }; } Данный класс, так же как и структура Inherit, наследуется от списка переданных сущностей, "прикапывает" этот список наследования, наследуется от некоторой
(по которой будет производится классификация сущностей: интерфейс или реализация), так же избавляет от неразборчивости компилятор (подпихнув ему методы через BOSS_DECLARE_IBASE_METHODS) и содержит признак сконструированности объекта (Constructed).
Есть интерфейсы, есть их реализации, но пока не было реализации IBase. Реализация этого интерфейса, пожалуй будет одной из сложных.
Для создания объекта из приведенного выше большого примера будет выглядеть примерно так:auto Obj = Boss::Base<Face123456>::Create();
Boss::Base - это класс-реализация Boss::IBase. В реализации для выполнения тех или иных операций придется обходить иерархию класса. Так для примера, приведенного выше, упрощенная иерархия будет выглядеть так: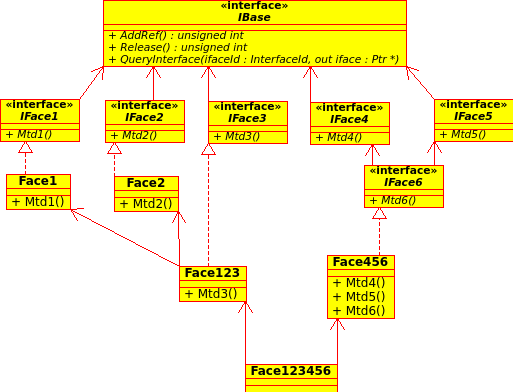
Обход иерархии классов в поисках нужного ненадолго отложу. Быстро пройдусь по более простым методам.
Подсчет ссылок осуществляется вызовом методов AddRef (увеличивает счетчик ссылок) и Release (уменьшает счетчик ссылок и при достижении нуля удаляет объект, делая delete this). Так как предполагается возможность использования объектов в многопоточной среде, то работа со счетчиком осуществляется через std::atomic, что позволяет атомарно увеличивать и уменьшать счетчик в многопоточной среде. Да, наконец-то C++ признало существование потоков и появилась поддержка работы с потоками и примитивы синхронизации.
Метод Create имеет такую реализацию:
template <typename ... Args> static RefObjPtr<T> Create(Args const & ... args) { Private::ModuleCounter::ScopedLock Lock; RefObjPtr<T> NewInst(new Base<T>(args ...)); Private::FinalizeConstruct<T>::Construct(NewInst.Get()); return std::move(NewInst); }
Наличие шаблонов с переменным количеством параметров позволяет создать метод для конструирования объектов и в конструктор передавать нужные параметры. Ранее такого сделать нельзя было и если объект нуждался в каких-то изначальных настройках, то приходилось создавать объект, у которого был некоторый метод (свой специфичный) типа Init, в который необходимое и передавалось.
Управляет счетчиком ссылок модуля. Имеется два счетчика ссылок - это счетчик ссылок непосредственно у объекта и счетчик всех ссылок модуля. Счетчик ссылок модуля нужен для того, чтобы можно было понять, когда в модуле есть "живые" объекты, а когда нет ни одного и модуль можно выгрузить.
Чтобы отказаться от статических библиотек и реализовать паттерн "одиночка" (для каждого из модулей) нужно для сущности ModuleRefCounter реализовать его только во включаемом файле, то тут вполне пригодится трюк с шаблонами и статическими объектами. Более подробно об этом можно прочесть в предыдущей статье. Кратко описать это можно так: если создать шаблон типа со статическим полем и инстанцировать его любым типом, то экземпляр этого объекта будет единственный на весь модуль. Получается небольшая хитрость, применяемая для написания одиночек во включаемых файлах без реализации где-то в cpp-файле (одиночки в include'ах).
И в этом красивом решении есть грабли, детские грабли: черенок в два раза короче, бьет точнее и больнее… Это решение прекрасно работает в .dll, но в .so поймал проблему: шаблон со статическими полями, инстанцированный одним и тем же типом стал одним на все .so с компонентами данной модели в рамках процесса! Почему я немного позднее осознал, но пришлось от красивого решения отказаться в пользу более простого, основанного на безымянных пространствах имен и включаемом файле, который в каждый модуль включается не более одного раза (кому интересно - boss/include/plugin/module.h).
Язык C++ многие считают языком, позволяющим легко "выстрелить себе в ногу". И, как правило, часто гонения на него идут именно из-за учета парности операций по выделению/освобождению ресурсов, а в частности памяти. Но если использовать умные указатели, то одной головной болью становится меньше. RefObjPtr как раз и является умным указателем, вызывающим AddRef и Release для управления временем жизни объекта и в программе при его использовании, методы AddRef и Release не должны встречаться в пользовательском коде.
Такая плюшка нового стандарта как r-value позволяет писать более оптимальные сущности; например, все тот же RefObjPtr возвращать объект не вызывая лишний раз AddRef/Release на конструкторах копирования (return std::move(NewInst)).
Есть еще в Create и обращение к некому FinalizeConstruct. Что это и зачем? Предположим у вас есть иерархия, примерно не проще приведенной на рисунке выше и в одной из реализаций интерфейса нужно что-то вызвать, что определено в классе уровнем ниже. Можно использовать виртуальные функции, но, если сказать по-простому, то в конструкторе еще нет виртуальной таблицы функций, а в деструкторе ее уже нет. Все вызовы виртуальных функций будут как вызовы обычных функций класса и вызвать переопределенную функцию уровнем ниже не получится из конструктора. На этот случай и сделан FinalizeConstruct, который будет вызван после того как объект уже полностью создан. Получается, что надо реализовать некоторую логику, аналогичную логике вызова конструкторов, только своими силами, т.е. обойти всю иерархию и вызвать FinalizeConstruct у каждого класса в том порядке, в котором и вызываются конструкторы.
Разработчик класса не обязан определять FinalizeConstruct в своем классе. При обходе иерархии классов реализованная в модели логика FinalizeConstruct определит с помощью старого доброго SFINAE наличие в классе FinalizeConstruct и при наличии этого метода вызовет его. Основное правило: реализация в пользовательском коде FinalizeConstruct не должна быть виртуальной! В противном случае получится неразбериха при построении сущностей из готовых кубиков.
Наличие в классе FinalizeConstruct определяется таким кодом:
template <typename T> class HasFinalizeConstruct { private: typedef char (&No)[1]; typedef char (&Yes)[10]; template <typename U, void (U::*)() = &U::FinalizeConstruct> struct CheckMtd { typedef Yes Type; }; template <typename U> static typename CheckMtd<U>::Type Check(U const *); static No Check(...); public: enum { Has = sizeof(Check(static_cast<T const *>(0))) == sizeof(Yes) }; };
Вся логика по вызову FinalizeConstruct
построена на частных специализациях шаблонов и хождению по иерархии через "прикопанные" кортежи с типами базовых классов. Стандартная библиотека стала иметь средства по работе с типами, так, для определения того принадлежит ли класс к классу реализации, можно теперь использовать std::is_base_of, а не писать свою реализацию. Так же вместо списков типов в стиле Александреску можно использовать std::tuple.
Аналогия конструкторам готова, а как же аналогия деструкторам? Куда же без нее. В модели реализована логика по обходу иерархии классов в порядке вызова деструкторов, поиска в классе реализации все через тот же SFINAE метода BeforeRelease и при наличии вызова его. Реализация логики по работе с BeforeRelease аналогична логике FinalizeConstruct, но только в обратном порядке обход.
Теперь есть возможность доконструировать объект после его полного создания и высвободить что-то перед разрушением объекта. Но в конструкторе можно сообщить о проблеме, кинув из него исключение. Такое же поведение реализовано в данной модели: в любом методе FinalizeConstruct в иерархии можно кинуть исключение и остальная цепочка FinalizeConstruct уже не будет вызываться, кроме того, для объектов иерархии, для которых FinalizeConstruct уже прошел успешно будет вызван BeforeRelease. Получается полная аналогия конструкторам и деструкторам C++. BeforeRelease вызывается из реализации метода Release и при обходе иерархии BeforeRelease будет вызван только для тех объектов, для которых прошел успешный вызов FinalizeConstruct, а успешность вызова определяется флагом Constructed, находящегося в CoClass'е (помните?). Так же стоит отметить, что если нет необходимости в парности этих методов в классе, то может присутствовать только один, если он вообще нужен.
Осталось реализовать логику
которая по большому счету не особо отличается от обхода иерархий, описанному выше. При обходе иерархии и при встрече в дереве класса реализации берется его "прикопанный" список базовых сущностей и рекурсивно обходится он в поисках нужного интерфейса. Есть одно дополнение. Так как есть возможность работы с интерфейсами, множественно наследованными от других интерфейсов, то при встрече в иерархии поиска интерфейса, он обходится в поиске нужного интерфейса аналогично обходу класса реализации, но только с "прикопанным" списком только одних интерфейсов.
листом в иерархии наследования пользовательских реализаций и прочих вспомогательных классов, а дабы исключить возможность наследования от этой реализации, можно воспользоваться ключевым словом final, так же для явного исключения возможности копирования и перемещения объектов этого типа можно в интерфейсе данного класса явно об этом сказать, пометив все что не нужно как deleted.
Ядро готово! Все самое сложное и интересное описано. Далее будет все гораздо проще и уже все ровнее, без головоломок.
Плагины
В данной части речь пойдет по организации плагинов. Под плагинами стоит понимать в текущем контексте динамические библиотеки (.so / .dll), в которых размещаются классы-реализации интерфейсов (компоненты) и небольшой набор функций для доступа к объектам этих классов-реализаций.
Эта часть статьи, на мой взгляд, самая простая, так как тут нет никакого "программирования на шаблонах" и прочего глумления над компилятором. Всего лишь создание некоторого набора интерфейсов и реализаций для организации системы плагинов.
Для "жизни" компонент в своих жилищах (плагинах) в рамках одного государства, именуемого процессом, нужно не так много:
- Реестр плагинов / компонент / сервисов
- Фабрика классов
- Загрузчик
Реестр сервисов - место хранения всей информации о сервисе:
- Идентификатор сервиса
- Список содержащихся в плагине классов-реализаций
- Путь к модулю (so / dll) в случае плагинов, обитающих в рамках одного процесса
- Некоторая информация по загрузке Proxy/Stub'ов и организации канала связи между клиентом и сервером. Это немного забег вперед в преодоление границ процесса
На основании этой информации фабрика классов сможет загружать необходимые плагины и создавать объекты-реализации интерфейсов.
Роль загрузчика заключается в том, чтобы загрузить реестр компонент, загрузить фабрику классов и настроить ее на совместную работу с реестром сервисов. После чего все обращения на создание объектов будут только к фабрике и пользователь получает некоторую абстракцию, он не должен беспокоиться в каком из модулей находится его объект и как его создать. Пользователь оперирует только идентификаторами классов реализаций при запросе на создание нового объекта.
Реестр сервисов поставляет интерфейс всего с одним методом, которого достаточно для получения необходимой информации для фабрики классов.
namespace Boss { struct IServiceRegistry : public Inherit<IBase> { BOSS_DECLARE_IFACEID("Boss.IServiceRegistry") virtual RetCode BOSS_CALL GetServiceInfo(ClassId clsId, IServiceInfo **info) const = 0; }; }
Но сам класс реализации реестра сервисов может поставлять несколько интерфейсов. Ради чего все затевалось? Делать наборные компоненты.
т.е. реализация предоставляет интерфейс для манипулирования реестром (IServiceRegistryCtrl,) и его загрузкой и сохранением (ISerializable).
так же поставляет несколько интерфейсов: один основной (IClassFactory), которым будут пользоваться все клиенты для создания объектов и вспомогательный (IClassFactoryCtrl), которым пользуется загрузчик для настройки фабрики на реестр.
Код загрузчика весьма прост, но, к сожалению, С++11 мало признал платформу (ОС). Многопоточность они признали, а вот существование таких вещей как динамические библиотеки пока нет. Так что для загрузки модулей будет использоваться код, зависящий от операционной системы. Конечно же запрятанный глубоко. Тут неплохо было бы вспомнить про pImple, но так как взят курс на отказ от статических библиотек, то будет немного иное: реализация для каждой ОС в своем заголовочном файле и файл-интерфейс, разбирающий что включить на основе макросов __linux__ и _WIN32.
Маленький пример использования сервисов в рамках модели плагинов, обитающих в одном процессе:
#include <iostream> #include "plugin/loader.h" #include "plugin/module.h" int main() { try { Boss::Loader Ldr("Registry.xml", "./libservice_registry.so", "./libclass_factory.so"); Boss::RefObjQIPtr<Boss::IBase> Inst; Inst = Ldr.CreateObject<Boss::IBase>(Boss::Crc32("MyClass")); } catch (std::exception const &e) { std::cerr << e.what() << std::endl; } return 0; }
Как и было отмечено в начале раздела, все весьма просто, только потребовалось написать некоторое количество вспомогательного кода.

Примеры
Лучший пример - это реальная задача, а не искусственно выдуманное нагромождение, по максимуму демонстрирующее ту или иную возможность.
Выше, при описании ядра, приводился весьма крупный пример, который максимально и пытался отобразить имеющуюся гибкость в сборе сущностей из готовых реализаций и добавлением нового интерфейса. Но пример, несмотря на то, что отображает возможности модели, он надуман и выглядит не очень дружелюбно. Поэтому, в качестве примеров, можно рассмотреть реализации необходимых компонент плагинной части, а именно реестра сервисов и фабрики классов. Они хоть и являются частью плагинной модели, но являются такими же плагинами, как и те которые может разрабатывать пользователь для свои нужд.
Еще раз приведу класс-реализацию для реестра сервисов.
Теперь попробую описать, что здесь происходит…
Для создания класс-реализации одного или нескольких интерфейсов нужно создать класс производный от класса-шаблона CoClass. Этот класс в качестве параметров принимает идентификатор класс-реализации (который уже может быть использован при создании объекта через фабрику классов) и список наследуемых интерфейсов или уже готовых реализаций интерфейсов. Если взглянуть на приведенный класс-реализацию реестра сервиса, то в ней как раз и виден идентификатор (Service::Id::ServiceRegistry) и далее перечислены интерфейсы, которые реализованы в этом классе (IServiceRegistry - интерфейс реестра сервисов, который будет использован фабрикой классов; ISrviceRegistryCtrl - интерфейс управления реестром; ISerializable - реестр должен быть куда-то сохранен и откуда-то загружен и этот интерфейс позволяет выполнять требуемое). На этом вся работа по созданию компонента закончена и нужно всего лишь реализовать его методы.
Компонент готов. Осталось его как-то опубликовать, т.е. дать возможность доступа к нему извне модуля, в котором он находится.
В макрос передается строка от которой будет рассчитан CRC32, используемый в качестве идентификатора модуля и список класс-реализаций, который экспортируется данным модулем. После чего компонент и его модуль готов (а в модуле может находиться несколько компонент), им можно пользоваться, зарегистрировав в реестре (исключение: реестр сервисов и фабрику классов для обычного использования модели можно не регистрировать).
Еще один аналогичный пример: реализация фабрики классов, который так же уже был приведен выше.
Полностью аналогичный пример. Так же наследование от CoClass, идентификатор и список реализуемых интерфейсов. Фабрика классов размещена в отдельном модуле, соответственно она имеет и свою
аналогичную точке входа реестра сервисов.
Это были простые реализации компонент, в которых каждая компонента наследовала только список интерфейсов, реализовывала их методы и все. Не было наследования уже готовых реализаций. А если Вы посмотрите еще раз на интерфейс реестра сервисов, то в нем Вы увидите работу с IServiceInfo, через который и передается вся информация. IServiceInfo может передавать только общую информацию о сервисе, но есть и частная. Изначально хотел сделать плагины, живущие не только в динамических библиотеках, но и разбросанные по процессам, в своих исполняемых модулях. Отсюда и разная информация: для плагинов в динамических библиотеках только дополнение о пути к ней, а для плагинов в отдельных исполняемых модулях куча дополнительной информации: информация о Proxy/Stub'ах, транспорте и т.д. (но, к сожалению, я не довел эту часть до конца, а зачатки отрезал, чтоб не засорять код недоделками). Теперь как раз и приведу пример, в котором уже компоненты наследуются не только от интерфейсов, но и от реализаций.
Реализация ServiceInfo может показаться немного сложноватой. Зачем и тут шаблон? Это уже тонкость реализации структуры данных, которая мне пришла в голову, а не дань, отдаваемая компонентной модели / плагинной системе. Чтобы немного прояснилась причина такой реализации, приведу интерфейс:
Чуть более понятная реализация с наследованием интерфейсов и реализаций приведена в описании ядра с причудливым классом Face123456 без всяких шаблонов :)
Как компоненты реализовывать все прояснилось. Все просто. А как запрашивать и работать с интерфейсами, запрашивать из одного другой - можно рассмотреть на примере загрузчика, который загружает реестр сервисов, получает из него нужные интерфейсы, настраивает этот самый реестр, загружает фабрику классов и настраивает ее на работу с реестром. Далее, конечно, вся работа клиента идет уже с фабрикой классов и клиент уже не должен работать с модулями, а иначе ради чего вся эта абстрактность затевалась-то.
Кроме приведенных примеров, актуальны примеры из статьи с реализацией предыдущей версии на C++ 03. Единственное отличие - работа с идентификаторами. В новой модели не надо добавлять отдельным макросом в класс-реализацию, про который можно забыть. Если в новой модели забыть про идентификатор, то компилятор об этом Вам напомнит, так как теперь это параметр шаблона.
Заключение
Была некоторая большая задумка, но реализовалась только на 2/3:
- Реализовано полностью ядро
- Реализованы базовые сервисы для существования плагинной системы
- Плагины, которые должны были обитать в других процессах, не доведены до ума, а все зачатки вырезаны, чтобы не засорять код
Как-то так сложилось, что наиболее интересен для меня момент построения каркаса или скелета системы, а вот наращивание мышц и вливание жира (разработка всяких полезностей / псевдополезностей) это уже может иногда быть работой, которая выполняется весьма быстро в силу хорошей осведомленности в системе. В силу этого получилось весьма полное (местами может быть избыточно полное) ядро (сферические кони в вакууме меня всегда привлекали). Есть небольшая часть мышц (основные компоненты плагинной системы: реестр сервисов и фабрика классов), чтобы модель хоть как-то могла существовать. Но данная реализация получилась полностью обезжиренной: в ней нет ничего вспомогательного. Собран скелет системы, наращено немного мышц и дан пинок под зад, чтоб это хоть как-то двинулось с места - стало материалом и статьей Хабра.
Проект обязательно должен быть или выпущен, или прекращен как можно ранее, пока он не съел все ресурсы и благополучно не пропал из поля внимания. В силу этого суждения и того, что материал статьи получился великоват и, возможно, местами сложноват, и той причины, что мне не удалось больше полугода уделить внимания данной статье, часть с плагинами пока отсутствует. Скоро может например появиться C++14 и тогда материал этой статьи, посвященный C++11 уже может стать неактуальным. Вполне может быть нереализованная часть выйдет отдельным постом… Этот материал будет базироваться на материале статьи "Proxy/Stubs своими руками, который я хотел переработать с учетом стандарта C++11, добавить маршалинг интерфейсов и подложить под это все транспорт (реализовать один из механизмов IPC).
К сожалению и счастью одновременно, читатель не всегда выносит всего замысла автора из его работы, который был им заложен в нее. По исходному коду есть немного разбросанных заделок на будущее типа RemoteServiceInfo и прочих, которые вполне могут быть пропущены при рассмотрении материала.
Весь исходный код доступен для скачивания. Имеет минимальный сборочный скрипт. Вполне может послужить некоторым источником примеров, может быть источником идей, паттернов для своих разработок или антипаттернов, что-то большее, по моему мнению, маловероятно.
Рекомендуемые ссылки
- MSDN. Visual C++ Project Model.
- MSDN. Project Modeling.
- MSDN. Automation Model Overview.