
Весь процесс можно разделить на несколько основных этапов:
1) Уменьшение исходного изображения
2) Выбор наиболее информативного канала
3) Предобработка изображения, выделение контуров
4) Детектирование границ и определение углов документа
5) Проверка полученных гипотез
6) Уточнение координат углов документа
Рассмотрим каждый из этапов подробнее.
1. Уменьшение исходного изображения
Целью этого этапа является получение сильно уменьшенной копии изображения, такой что max(w, h) составляет величину порядка 200 пикселей, где w - ширина, а h - высота получаемого изображения. Сразу во столько раз уменьшать исходное изображение (имеющее размер порядка 2-3 тысяч пикселей по ширине и высоте) нельзя! Даже если использовать алгоритмы билинейной или бикубической интерполяции, мы получим изображение с сильным эффектом "биения" на контурах, называемого также aliasing (см. рис. 1, слева). Поэтому мы уменьшаем изображение в несколько итераций, каждый раз изменяя размер в 2 раза. В результате получаем более "гладкое" изображение (рис. 1, справа). Можно было бы использовать гауссово сглаживание и уменьшать сразу в нужное число раз, но, во-первых, гауссово сглаживание - процедура ресурсоемкая для изображения в несколько мегапикселей, а во-вторых, билинейная интерполяция реализована встроенными средствами OpenGL ES, нам нужно лишь последовательно менять размер текстуры.


Рисунок 1. Изображение, полученное уменьшением оригинала до размера 150 пикселей разными способами. Слева виден эффект "биения" на контурах, справа - более "гладкий" результат последовательного уменьшения в 2 раза.
2. Выбор наиболее информативного канала
Прежде всего отметим, что документ от окружающего фона может отличаться не только по яркости, но и по цвету. Поэтому, как бы нам ни хотелось сократить пространство поиска, нельзя просто избавляться от цветовых каналов в изображении. Посмотрим, какой из них наиболее подходит для дальнейшего анализа. Для этого вычисляем гистограммы 4-х каналов: R, G, B и яркости. Далее из гистограмм вычисляем средние значения и дисперсию каналов. Если максимальная дисперсия одного из цветовых каналов больше, чем у канала яркости на некоторый коэффициент К>1 (параметр алгоритма), то далее мы будем использовать его, в противном случае будем использовать канал яркости.





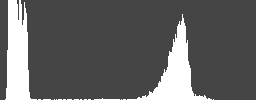


Рисунок 2. Сверху вниз: изображения каналов R, G, B и яркости и соответствующих им гистограмм.
3. Предобработка изображения, выделение контуров
Над полученным в предыдущем этапе каналом уменьшенного изображения придется немного поработать. Нам по-прежнему мешают некоторые элементы внутри документа (строки текста, заголовки, сепараторы сохраняют свою видимость даже на этом масштабе), поэтому проведем медианную фильтрацию изображения, с радиусами R1=3 и R2=5 пикселей, по 3 итерации для каждого радиуса. Сохраним полученные в результате изображения (см. рис. 2). Первое из них используется для выделения границ при помощи известного алгоритма Canny edge detection, а второе будет использовано при проверке полученных гипотез по сторонам. Первый этап алгоритма Canny edge detection (фильтрация изображения) можно пропустить, поскольку мы это уже сделали с учетом свойств нашего сигнала. Значения "верхнего" и "нижнего" порога для алгоритма Canny edge detection следует настраивать, также как и остальные параметры нашего алгоритма, но об этом позже.




Рисунок 3. Слева направо: исходное изображение одного из каналов, после 1, 2, 3 итераций медианной фильтрации с радиусом R=3, результат выделения контуров алгоритмом Canny edge detection.
4. Детектирование границ и определение углов документа
Итак, на предыдущем этапе мы получили контурное представление нашего изображения, нам остается лишь обнаружить на нем границы нашего документа. Для этого применяем другой, хорошо известный алгоритм -преобразование Хафа (Hough transform). Строго говоря, для каждой из сторон можно использовать "свое" подпространство Хафа, с наиболее подходящей параметризацией, которое можно вычислить гораздо быстрее, чем полное пространство Хафа. Используя эти подпространства, находим линии с максимальным откликом для каждой из сторон документа. Точки пересечения этих линий определяют углы документа. Переходим к следующему этапу.


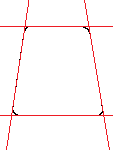
Рисунок 4. Слева направо: контурное представление изображения, подпространства Хафа, результат обнаружения границ на изображении.
5. Проверка полученных гипотез
Мы хотели бы проверить полученные гипотезы для границ документа, поскольку алгоритм, в силу его простоты, довольно часто ошибается в сложных ситуациях. Наиболее грубых ошибок можно избежать, переводя (при проверке гипотез) алгоритм из автоматического режима в полуавтоматический, или даже ручной, когда пользователю предлагается исправить полученный результат, или самостоятельно выделить документ.
Для проверки полученной гипотезы на контуре мы используем изображение, полученное в результате медианной фильтрации с радиусом R2=5 пикселей (см. 3-й этап). Для каждой из границ будем перебирать положения, отстоящие на +-1,+-2,…,+-10 пикселей, и вычислять энергию контура (интеграл вдоль контура от градиента) в каждом из положений. Выберем положение с максимальной энергией контура, по значению энергии принимаем решение, годится ли граница для автоматического алгоритма, для полуавтоматического, или её следует отбросить и перейти в ручной режим. Таким образом, любая из границ документа может повлиять на перевод алгоритма в другой режим.
Проверка по геометрии для полученных границ включает в себя несколько правил:
1) Соотношение длин всех противоположных границ должно быть, например, 0.5<a<2.
2) Углы на общей стороне не должны отличаться более чем на 12 - 15 градусов.
3) Площадь получаемого четырехугольника должна быть не менее 15 - 25% от изображения.
4) Сдвиг документа относительно центра изображения не более 5 - 10 % от ширины или высоты изображения.
6. Уточнение координат углов документа
Полученное таким образом решение является приближенным в геометрическом смысле, координаты углов документа можно попробовать уточнить. Вокруг каждого угла документа определим квадратный регион, в котором будем производить поиск точки, для которой значение медианного фильтра отличается от сигнала (выбранного нами канала изображения, см. этап 2) на величину, превышающую некоторый порог Т=12. По знаку отличий можно также определять угол как "нормальный" или "инвертированный", т.е. принадлежащий документу, который светлее или темнее своего окружения. В итоге мы должны принять решение в отношении всего документа в целом.
Разумеется, конкретные значения параметров метода могут быть другими, их настройку следует проводить по большой базе изображений, содержащей различные типы документов, снятых при различных условиях.
После того, как определены координаты всех 4-х углов документа, можно выполнить перспективное преобразование, исправляющее геометрические искажения в изображении. При этом можно автоматически определять пропорции исходного документа, используя только координаты углов. Однако рассмотрение этой задачи выходит за рамки данной статьи.