
Spark представляет собой кластерную вычислительную платформу с открытым исходным кодом, аналогичную Hadoop, но с некоторыми полезными особенностями, которые делают ее превосходным инструментом для решения некоторых видов задач. А именно, помимо интерактивных запросов Spark поддерживает распределенные наборы данных в оперативной памяти, оптимизируя решение итеративных задач.
Spark реализован на языке Scala и использует его в качестве среды разработки приложений. В отличие от Hadoop, Spark и Scala образуют тесную интеграцию, при которой Scala может легко манипулировать распределенными наборами данных как локальными коллективными объектами.
Хотя Spark предназначен для решения итеративных задач с распределенными данными, он фактически дополняет Hadoop и может работать вместе с файловой системой Hadoop. В частности, это может происходить в среде кластеризации Mesos. Spark разработан в лаборатории "Алгоритмы, машины и люди" Калифорнийского университета в Беркли для построения крупномасштабных и быстродействующих приложений анализа данных.
Кластерная вычислительная архитектура Spark
Несмотря на сходство с Hadoop, Spark представляет собой новую кластерную вычислительную среду, обладающую полезными особенностями. Во-первых, Spark предназначен для решения в вычислительном кластере задач определенного типа. А именно, таких, в которых рабочий набор данных многократно используется в параллельных операциях (например, в алгоритмах машинного обучения). Для оптимизации задач этого типа в Spark вводится понятие кластерных вычислений в памяти, когда наборы данных могут временно храниться в оперативной памяти для уменьшения времени доступа.
Кроме того, в Spark вводится понятие устойчивого распространенного набора данных (resilient distributed datasets - RDD). RDD - это коллекция неизменяемых объектов, распределенных по множеству узлов. Эти коллекции устойчивы, потому что в случае потери части набора данных они могут восстанавливаться. Процесс восстановления части набора данных опирается на механизм отказоустойчивости, поддерживающий родословную (или информацию, которая позволяет восстанавливать часть набора данных с помощью процесса, в результате которого эти данные были получены). RDD представляет собой объект Scala и может создаваться из файла; в виде параллельного среза (распространенного по узлам); как преобразование другой RDD; и, наконец, путем изменения персистенции существующей RDD, такой как запрос на кэширование в памяти.
В Spark приложения называются драйверами, и эти драйверы осуществляют операции, выполняемые на одном узле или параллельно на наборе узлов. Как и Hadoop, Spark поддерживает одноузловые и многоузловые кластеры. При многоузловой работе Spark опирается на менеджер кластера Mesos. Mesos обеспечивает эффективную платформу распределения ресурсов и изоляции распределенных приложений (см. рисунок 1). Такой подход позволяет Spark сосуществовать с Hadoop в общем пуле узлов.
Рисунок 1. Для распределения и изоляции ресурсов Spark опирается на менеджер кластера Mesos. 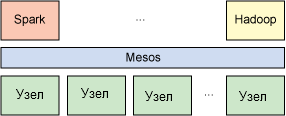
Драйвер может выполнять над набором данных операции двух типов: действия и преобразования. Действие ― это вычисление на наборе данных с возвратом значения в драйвер; преобразование создает новый набор данных из существующего набора данных. Примерами действий служат операции сокращения (с применением функций) и перебор набора данных (применение функции к каждому элементу, подобно операции Map). Примерами преобразования служит операция Map и операция Cache (которая требует сохранения в памяти нового набора данных).
Ниже мы рассмотрим примеры этих двух операций, но сначала познакомимся с языком Scala.
Scala, пожалуй, ― одна из самых заветных тайн Интернета. Scala работает на некоторых из популярнейших Web-сайтах, включая Twitter, LinkedIn и Foursquare (с его платформой Web-приложений Lift). Есть также свидетельства интереса к производительности Scala со стороны финансовых учреждений (например, EDF Trading использует Scala для расчета цен деривативов).
Scala - это мультипарадигмальный язык в том смысле, что он гладко и удобно поддерживает языковые функции, характерные для императивных, функциональных и объектно-ориентированных языков. С точки зрения объектно-ориентированного программирования каждое значение в Scala представляет собой объект. Аналогично, с точки зрения функционального программирования каждая функция - это значение. Кроме того, Scala статически типизируется с помощью выразительной и безопасной типовой системы.
В дополнение к этому Scala представляет собой язык виртуальной машины (VM) и работает непосредственно на Java Virtual Machine (JVM) с использованием Java Runtime Environment версии 2 посредством байт-кодов, генерируемых компилятором Scala. Этот подход позволяет Scala выполнять почти все, что работает на JVM (при наличии дополнительной библиотеки времени выполнения Scala). Таким образом, Scala использовать огромный каталог существующих Java-библиотек наряду с существующими Java-программами.
Наконец, Scala ― расширяемый язык (его название на самом деле означает Scalable Language), ориентированный на добавление простых, гладко интегрируемых расширений.
|
Происхождение Scala |
|
Язык Scala зародился в Федеральном политехническом институте Лозанны. Его разработал Мартин Одерский (Martin Odersky), который до этого работал над языком программирования Funnel , объединявшем идеи функционального программирования и сетей Петри. В 2011 году группа создателей Scala получила 5-летний грант от Европейского совета по исследованиям, и для коммерческой поддержки Scala была учреждена компания Typesafe, получившая надлежащее финансирование. |
Наш краткий обзор языка Scala с его интерпретатором начинается с листинга 1. После запуска Scala появляется командная строка, с помощью которой можно интерактивно проверять выражения и программы. Начнем с создания двух переменных, неизменяемой (vals, т.н. переменная с одноразовым присваиванием) и изменяемой (vars). Заметим, что если попытка изменить b (переменную типа var) будет успешной, то при попытке изменить val выдается сообщение об ошибке.
Листинг 1. Простые переменные в Scala
$ scala
Welcome to Scala version 2.8.1.final (OpenJDK Client VM, Java 1.6.0_20).
Type in expressions to have them evaluated.
Type :help for more information.
scala> val a = 1
a: Int = 1
scala> var b = 2
b: Int = 2
scala> b = b + a
b: Int = 3
scala> a = 2
<console>6: error: reassignment to val
a = 2
^
|
Далее, создадим простой метод для возведения числа Int в квадрат. Определение метода в Scala начинается со слова def, за которым следует имя метода и список параметров, после чего ему присваиваются разные значения (в этом примере ― одно). Никакие возвращаемые значения не указываются, так как они вытекают из самого метода. Это аналогично присвоению значения переменной. Я демонстрирую этот процесс на объекте 3, а результатом служит переменная res0 (которую интерпретатор Scala создает автоматически). Все это показано в в листинге 2.
Листинг 2. Простой метод в Scala
scala> def square(x: Int) = x*x square: (x: Int)Int scala> square(3) res0: Int = 9 scala> square(res0) res1: Int = 81 |
Теперь рассмотрим создание в Scala простого класса (см. листинг 3). Определим простой класс Dog, который принимает аргумент String (конструктор имен). Здесь следует отметить, что класс принимает параметр напрямую (без определения параметра class в теле класса). Единственный метод при вызове выдает строку. Создаем новый экземпляр класса и вызываем метод. Обратите внимание, что вертикальные линии вставляет интерпретатор - они не являются частью кода.
Листинг 3. Простой метод в Scala
scala> class Dog( name: String ) {
/ def bark() = println(name + " barked")
/ }
defined class Dog
scala> val stubby = new Dog("Stubby")
stubby: Dog = Dog@1dd5a3d
scala> stubby.bark
Stubby barked
scala>
|
Когда все готово, просто введите :quit, чтобы выйти из интерпретатора Scala.
Первый шаг ― загрузка и настройка Scala. Команды, показанные в листинге 4, иллюстрируют процесс загрузки и подготовки к установке Scala. Используйте версию Scala 2.8, потому что в ней Spark как следует документирован.
$ wget http://www.scala-lang.org/downloads/distrib/files/scala-2.8.1.final.tgz $ sudo tar xvfz scala-2.8.1.final.tgz --directory /opt/ |
Чтобы сделать Scala видимым, добавьте следующие строки в файл .bashrc (если в качестве оболочки используется Bash):
export SCALA_HOME=/opt/scala-2.8.1.final export PATH=$SCALA_HOME/bin:$PATH |
Вы можете проверить свою установку, как показано в в листинге 5. Этот набор команд загружает изменения в файл bashrc, а затем выполняет короткий тест оболочки интерпретатора Scala.
Листинг 5. Настройка и запуск Scala в интерактивном режиме
$ scala
Welcome to Scala version 2.8.1.final (OpenJDK Client VM, Java 1.6.0_20).
Type in expressions to have them evaluated.
Type :help for more information.
scala> println("Scala is installed!")
Scala is installed!
scala> :quit
$
|
Теперь вы должны видеть приглашение Scala. Чтобы выйти, введите :quit. Обратите внимание, что Scala выполняется в контексте JVM, который тоже должен присутствовать. Я использую Ubuntu, который входит в OpenJDK по умолчанию.
Теперь загрузите среду Spark последней версии. Для этого используйте сценарий, показанный в листинге 6.
Листинг 6. Загрузка и установка среды Spark
wget https://github.com/mesos/spark/tarball/0.3-scala-2.8/ mesos-spark-0.3-scala-2.8-0-gc86af80.tar.gz $ sudo tar xvfz mesos-spark-0.3-scala-2.8-0-gc86af80.tar.gz |
Настройте конфигурацию Spark в файле ./conf/spar-env.sh с помощью следующей строки в главном каталоге Scala:
export SCALA_HOME=/opt/scala-2.8.1.final |
На последнем шаге процесса установки обновите свой дистрибутив с помощью простого инструмента сборки (sbt). Это инструмент сборки для Scala, который применяется с дистрибутивом Spark. Выполните обновление и компиляцию в подкаталоге mesos-spark-c86af80:
$ sbt/sbt update compile |
Обратите внимание, что при выполнении этого шага требуется интернет-соединение. По завершении выполните короткий тест Spark, как показано в листинге 7. В этом тесте решается задача SparkPi, в которой вычисляется число Пи (методом случайного выбора точек внутри квадрата единичной площади). Приведенный формат вызывает программу (spark.examples.SparkPi) и параметр host, который определяет мастер Mesos (в данном случае localhost, так как это кластер с одним узлом), и количество используемых потоков. В листинге 7 обратите внимание на то, что две задачи решаются последовательно (задача 0 начинается и завершается до начала задачи 1).
Листинг 7. Выполнение короткого теста Spark
$ ./run spark.examples.SparkPi local[1] 11/08/26 19:52:33 INFO spark.CacheTrackerActor: Registered actor on port 50501 11/08/26 19:52:33 INFO spark.MapOutputTrackerActor: Registered actor on port 50501 11/08/26 19:52:33 INFO spark.SparkContext: Starting job... 11/08/26 19:52:33 INFO spark.CacheTracker: Registering RDD ID 0 with cache 11/08/26 19:52:33 INFO spark.CacheTrackerActor: Registering RDD 0 with 2 partitions 11/08/26 19:52:33 INFO spark.CacheTrackerActor: Asked for current cache locations 11/08/26 19:52:33 INFO spark.LocalScheduler: Final stage: Stage 0 11/08/26 19:52:33 INFO spark.LocalScheduler: Parents of final stage: List() 11/08/26 19:52:33 INFO spark.LocalScheduler: Missing parents: List() 11/08/26 19:52:33 INFO spark.LocalScheduler: Submitting Stage 0, which has no missing ... 11/08/26 19:52:33 INFO spark.LocalScheduler: Running task 0 11/08/26 19:52:33 INFO spark.LocalScheduler: Size of task 0 is 1385 bytes 11/08/26 19:52:33 INFO spark.LocalScheduler: Finished task 0 11/08/26 19:52:33 INFO spark.LocalScheduler: Running task 1 11/08/26 19:52:33 INFO spark.LocalScheduler: Completed ResultTask(0, 0) 11/08/26 19:52:33 INFO spark.LocalScheduler: Size of task 1 is 1385 bytes 11/08/26 19:52:33 INFO spark.LocalScheduler: Finished task 1 11/08/26 19:52:33 INFO spark.LocalScheduler: Completed ResultTask(0, 1) 11/08/26 19:52:33 INFO spark.SparkContext: Job finished in 0.145892763 s Pi is roughly 3.14952 $ |
Если увеличить число потоков, можно усилить параллельность их выполнения и сократить время вычисления (как показано в листинге 8).
Листинг 8. Еще один короткий тест Spark с двумя потоками
$ ./run spark.examples.SparkPi local[2] 11/08/26 20:04:30 INFO spark.MapOutputTrackerActor: Registered actor on port 50501 11/08/26 20:04:30 INFO spark.CacheTrackerActor: Registered actor on port 50501 11/08/26 20:04:30 INFO spark.SparkContext: Starting job... 11/08/26 20:04:30 INFO spark.CacheTracker: Registering RDD ID 0 with cache 11/08/26 20:04:30 INFO spark.CacheTrackerActor: Registering RDD 0 with 2 partitions 11/08/26 20:04:30 INFO spark.CacheTrackerActor: Asked for current cache locations 11/08/26 20:04:30 INFO spark.LocalScheduler: Final stage: Stage 0 11/08/26 20:04:30 INFO spark.LocalScheduler: Parents of final stage: List() 11/08/26 20:04:30 INFO spark.LocalScheduler: Missing parents: List() 11/08/26 20:04:30 INFO spark.LocalScheduler: Submitting Stage 0, which has no missing ... 11/08/26 20:04:30 INFO spark.LocalScheduler: Running task 0 11/08/26 20:04:30 INFO spark.LocalScheduler: Running task 1 11/08/26 20:04:30 INFO spark.LocalScheduler: Size of task 1 is 1385 bytes 11/08/26 20:04:30 INFO spark.LocalScheduler: Size of task 0 is 1385 bytes 11/08/26 20:04:30 INFO spark.LocalScheduler: Finished task 0 11/08/26 20:04:30 INFO spark.LocalScheduler: Finished task 1 11/08/26 20:04:30 INFO spark.LocalScheduler: Completed ResultTask(0, 1) 11/08/26 20:04:30 INFO spark.LocalScheduler: Completed ResultTask(0, 0) 11/08/26 20:04:30 INFO spark.SparkContext: Job finished in 0.101287331 s Pi is roughly 3.14052 $ |
Создание простого Spark-приложения на языке Scala
Для создания Spark-приложения Spark и описание его зависимостей должны находиться в одном файле архива Java (JAR). Создайте этот JAR в каталоге Spark верхнего уровня с помощью команды sbt:
$ sbt/sbt assembly |
Результатом будет файл ./core/target/scala_2.8.1/"Spark Core-assembly-0.3.jar"). Добавьте его в CLASSPATH, чтобы он был доступен. В данном примере этот JAR не используется, потому что мы не компилируем его, а запускаем в интерпретаторе Scala.
Здесь применяется стандартное преобразование MapReduce (см. листинг 9). Пример начинается с необходимого импортирования классов Spark. Затем мы определяем класс (SparkTest) с его основным методом, который анализирует аргументы для дальнейшего использования. Эти аргументы определяют среду, в которой будет выполняться Spark (в данном случае, кластер с одним узлом). Далее, создаем объект SparkContext, который указывает Spark, как получить доступ к кластеру. Этому объекту требуется два параметра: имя мастера Mesos (passed in) и имя, присвоенное задаче (SparkTest). Анализируем число фрагментов из командной строки, указывая Spark, сколько потоков использовать в задании. Последний шаг настройки ― указание текстового файла для операции MapReduce.
Наконец, получаем реальный код примера Spark, который состоит из ряда преобразований. С помощью своего файла вызываем метод flatMap, который возвращает RDD (посредством указанной функции разделения строки текста на маркеры). Затем этот RDD проходит через метод map (который создает пары "ключ-значение") и, наконец, через метод ReduceByKey, который объединяет пары "ключ-значение". Это делается путем передачи пар "ключ-значение" анонимной функции _ + _. Эта функция просто принимает два параметра (ключ и значение) и соединяет их вместе (String и Int), возвращая результат. Это значение выводится как текстовый файл (в выходной каталог).
Листинг 9. Сценарий MapReduce в Scala/Spark (SparkTest.scala)
import spark.SparkContext
import SparkContext._
object SparkTest {
def main( args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SparkTest <host> [<slices>]")
System.exit(1)
}
val spark = new SparkContext(args(0), "SparkTest")
val slices = if (args.length > 1) args(1).toInt else 2
val myFile = spark.textFile("test.txt")
val counts = myFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("out.txt")
}
}
SparkTest.main(args)
|
Чтобы выполнить сценарий, просто запросите выполнение:
$ scala SparkTest.scala local[1] |
Тестовый файл MapReduce можно найти в выходном каталоге (output/part-00000).
Другие платформы для анализа больших объемов данных
С тех пор как появился Hadoop, был разработан ряд других платформ для анализа больших объемов данных, которые стоит рассмотреть. Их диапазон простирается от простых предложений на основе сценариев до платформ производственного уровня, подобных Hadoop.
Одна из простейших называется bashreduce, что предполагает возможность выполнять операции типа MapReduce в среде Bash на нескольких компьютерах. bashreduce опирается на Secure Shell (без пароля) для кластера машин, который планируется использовать, а затем выполняется как сценарий запуска задачи с применением UNIX-инструментов (sort, awk, netcat и т.п.).
GraphLab ― еще одна интересная реализация абстракции MapReduce, ориентированная на параллельное исполнение алгоритмов машинного обучения. В GraphLab на этапе Map определяются вычисления, которые можно выполнять независимо друг от друга (в отдельных узлах), а на этапе Reduce производится объединение результатов.
Наконец, Twitter предложил новинку в области обработки больших объемов данных ― Storm (в результате приобретения компании BackType). Storm преподносится как "Hadoop для обработки данных реального времени" и ориентирован на потоковую обработку и непрерывные вычисления (результаты передаются потоковым способом по мере их получения). Storm написан на языке Clojure (современный диалект языка Lisp), но поддерживает приложения на любом языке (например, Ruby или Python). Twitter выпустил Storm в сентябре 2011 года как проект ПО с открытым исходным кодом.
Spark ― интересное пополнение в растущем семействе платформ анализа больших объемов данных. Это эффективная и удобная (благодаря простым и четким сценариям на языке Scala) платформа для обработки распределенных наборов данных. Как Spark, так и Scala находятся в стадии активной разработки. Однако освоение того и другого ключевыми интернет-ресурсами переводит их из разряда интересных проектов ПО с открытым исходным кодом в разряд основных Web-технологий.