

Тише едешь дальше будешь...? Оценка производительности.
Больше 7 лет я занимаюсь анализом производительности в составе группы Performance Analysis новосибирского отделения Интел. Мы работаем над улучшением производительности различных приложений, а точнее, ищем способы, с помощью которых ее смог бы улучшить наш компилятор. За это время накопился полезный опыт, который, на мой взгляд, был бы интересен посетителям уважаемого Хабра. Речь в данном случае будет идти не об алгоритмической оптимизации приложений, а о различных модификациях приложений без принципиального изменения их алгоритмов. Понятно, что алгоритмические оптимизации программы тоже имеют право на жизнь, но это совсем другая задача.
Я являюсь разработчиком компилятора Интел, поэтому все мои исследования связаны с различными компиляторными оптимизациями, сравнением различных компиляторов (на Windows это, как правило, сравнение интеловского компилятора с компилятором Microsoft Visual Studio). Собственно поэтому прошу не рассматривать мои посты как рекламу или антирекламу. Для иллюстрации моих мыслей я буду использовать различные инструменты, в том числе и разработанные в нашей компании. Надеюсь, что этот пост вырастет в серию статей об оптимизации приложений.
Существует ли простой критерий оценки оптимальности приложения?
Понятно, что любая проблема и задача, в том числе задача по улучшению производительности приложения, начинается с исследования текущего состояния дел. Необходима оценка: насколько приложение уже оптимизировано, и имеет ли смысл прилагать усилия чтобы его ускорить. На первый взгляд, задача имеет простое решение. Достаточно измерить загрузку процессора, чтобы такую оценку получить. Различные анализаторы производительности позволяют не только замерить время исполнения различных участков программы, но и подсчитать и привязать к коду программы все внутрипроцессорные события, возникающие при ее выполнении. С помощью этой информации можно оценить загрузку вычислительного ядра. Например, определить сколько тактов процессора в среднем потребовалось на выполнение одной инструкции, и какие причины вызывали задержки исполнения Т.е. предлагаемый критерий связывает эффективность работы ядра с возможностью улучшения производительности приложения. А именно, если ядро работает эффективно, то повода для беспокойства нет - программа работает оптимально, в противном случае приложение может быть улучшено и есть смысл заниматься его анализом. В результате использования такого критерия на свет появляются работы, в которых анализируются какие-то процессорные события, и авторы на основе этого анализа строят предположения о возможностях улучшения производительности приложений. Возможно, такие методы работы действительно полезны для архитекторов вычислительных систем и дают им возможность пофантазировать об улучшении архитектуры процессора. Но, к сожалению, для программиста, размышляющего об улучшении производительности своего приложения, этот метод крайне сомнительный, редко работает и не дает ответа на извечный вопрос русской интеллигенции: "Что делать? и Можно ли есть курицу руками?".
Во многих случаях максимальная загрузка вычислительного ядра вовсе не значит, что невозможно улучшить производительность программы и наоборот.
Давайте рассмотрим простой тестик с перемножением прямоугольных матриц. Создание маленьких работающих примеров, на мой взгляд, лучший метод получения интересной информации об устройстве вселенной и, в том числе, о работе компиляторов и процессоров. В таких тестах важно, чтобы время исполнения исследуемого кода было достаточно велико, чтобы на него не влияло время загрузки программы и какие-то случайные события, поэтому можно исполнять исследуемый код много раз.
#include <stdio.h>
#include <stdlib.h>
#define N 200
#define T 100
void matrix_mul_matrix(int t, int n, double *C, float *A, float *B) {
int i,j,k;
for (i=0; i<t; i++)
for (j=0; j<t; j++)
for(k=0;k<n;k++)
C[i*t+j]+=(double)A[i*n+k] * (double)B[k*t+j];
}
int main() {
float *A,*B;
double *C;
int i,j;
//… Выделение памяти и инициализация массивов
for(i=0;i<10000;i++)
matrix_mul_matrix(T,N,C,A,B);
printf("%f %f %f\n",C[0],C[1],C[100]);
free(A);
free(B);
free©;
}
На моей лабораторной машине c Windows Server 2008 R2 Enterprise и процессором Intel Xeon X5570 я компилирую эту программу с помощью компилятора Майкрософт VS 10.0. и Интел Parallel Studio XE2013. Для простоты я работаю с командной строкой и беру опции, соответствующие релизовскому варианту компиляции, используемыми по умолчанию в Visual Studio.
cl matrix.c /O2 /GL /GS /GR /W3 /nologo /Wp64 /Zi -Ob0 -Fematrix_cl
icl matrix.c /O2 /GL /GS /GR /W3 /nologo /Wp64 /Zi -Ob0 -Fematrix
Выясняется, что время работы matrix_cl равно ~21.9 s, в то время как время работы matrix равно ~9.3 s.
Теперь посмотрим, что нам скажет Amplifier о загрузке процессора. Intel VTune Amplifier XE 2011 - это как раз инструмент для оценки производительности, позволяющий работать с процессорными событиями интеловских процессоров.
Давайте создадим в Amplifier два проекта для полученных приложений и сделаем предварительный анализ - general exploration. Ну и что мы в результате видим? Вот результаты "разведки" приложения matrix_cl:
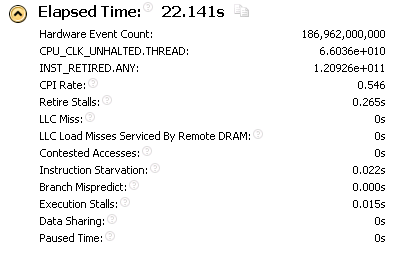
Обращаем внимание на CPI Rate (Clock per instruction, среднее количество тактов на одну инструкцию). Для моего процессора теоретический минимум этой величины 0.20. (Параллельное исполнение 4-х инструкций на 4-х исполнительных устройствах плюс фьюзинг еще одной. Итого 5 инструкций за такт - теоретический максимум). Число CPI 0.546 считается очень хорошим. Есть конечно и задержки. Но, вроде ничего критического нет. Вычислительное ядро работает с хорошей нагрузкой, и все выглядит вполне прилично. Можно ли из этой оценки понять, что производительность приложения реально улучшить в два раза?
Результаты исследования для matrix:
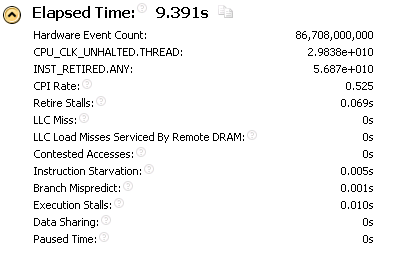
Волшебное улучшение производительности более чем в два раза, практически никак не отразились на основных "рейтингах" вычислений, собираемых Intel VTune Amplifier XE 2011. Т.е. исследование работы процессора в данном случае не дало нам никаких сигналов о том, что производительность может быть кардинально улучшена.
Данное улучшение производительности было достигнуто благодаря автовекторизации. Это легко увидеть, если добавить к опциям для интеловского компилятора -Qvec_report. Компилятор выдаст
…
...\matrix.c(9): (col. 5) remark: PERMUTED LOOP WAS VECTORIZED.
Т.е. производительность приложения была улучшена за счет применения цикловой перестановочной оптимизации. Для того чтобы понять, что такая оптимизация могла быть применена, необходимо было исследовать алгоритм перемножения матриц.
Теперь возьмем пример другого рода и создадим программу, которая будет обходить длинную цепочку объектов:
#include <stdio.h>
#include <stdlib.h>
#define N 1000000
struct _planet {
float x;
float y;
float z;
double m;
struct _planet *prev;
struct _planet *next;
};
typedef struct _planet planet;
planet* init_chain() {
Создание и инициализация цепочки
}
int main() {
planet *planet_chain;
planet *cur;
int i;
double sum=0.0;
planet_chain=init_chain();
for(i=0;i<1000;i++) {
cur=planet_chain;
while(cur) {
sum += cur->m;
cur=cur->next;
}
}
printf("%f\n",sum);
}
Оба оптимизирующие компилятора создали приложения выполняющиеся ~6.2s. Amplifier сообщает о том, что в данном приложении все плохо:

CPI rate очень плохой, и большую часть времени вычислительное ядро ожидает получения данных для обработки.
Ну и что с этим делать? Допустим, мы продолжим исследования и установим, что причиной плохой загрузки вычислительного ядра является задержка с работой подсистемы памяти. Очевидно, что ядро загружено плохо. Но нам то это сакральное знание чем помогает? Какие существуют методы для улучшения работы подсистемы памяти? Позволяет ли специфика нашего приложения применить уже известные методы?
Это пример приложения, в котором все плохо, и ситуацию нельзя кардинально исправить без изменения алгоритма.
заключение
Таким образом, простые вычисления различных процессорных коэффициентов дают мало информации для оценки эффективности приложения.
В данном случае простым аналогом задачи по оценке эффективности выполняющегося приложения является спортсмен, двигающийся из точки A в точку B. Если мы возьмем за критерий оптимальной работы спортсмена нагрузку на его мышцы или сравним среднюю его скорость на трассе и максимальную скорость, с которой данный спортсмен может двигаться, то далеко ли мы уйдем с такими критериями? Если спорсмен дурной, хоть и очень сильный, и постоянно ломится через чащу, вместо того чтобы оббежать ее по тропинке, то нужен просто более умный спортсмен. Обратно, если спортсмен бежал медленно, но его путь пролегал по болоту, где приходилось останавливаться, нащупывать путь и даже возвращаться периодически назад, то виноват ли спортсмен? Можно привлечь к решению задачи более тренированного и быстрого атлета (за большие деньги), а можно - грамотного тренера, который на старте проанализирует трассу забега, сильные и слабые стороны бегуна, а затем предложит бегуну оптимальный маршрут, а возможно, научит его принимать на ходу правильное решение в каких-то простых ситуациях.
Одним словом, без анализа пути, который нужно было преодолеть и знаний сильных и слабых сторон атлета, трудно оценить насколько он реально был хорош на дистанции.
Поэтому, на мой взгляд, не существует простого универсального работающего метода оценки эффективности работы приложения и, следовательно, простых путей его улучшения. Для решения этой задачи нужно подключать мозг и анализировать множество ситуаций, применяя к ним известные методы улучшения производительности. Как и в любом деле, здесь нужна методология подключения мозга. Для успешного решения задачи он должен знать некоторые вещи, например:
1.) Основные проблемы, влияющие на производительность процессора, и методы оптимизации, влияющие на эти проблемы.
2.) Основные методы компиляторной оптимизации. Как правило, все те методы, которые могут помочь улучшить производительность программы уже как-то учтены и реализованы в существующих оптимизирующих компиляторах. Полезно знать инструмент, которым вы пользуетесь в своей работе. Возможно, к успеху ведет простое добавление еще одной опции. Интересно выяснить, умеет ли ваш компилятор делать ту или иную оптимизацию, и почему он не сделал ее для вашего кода?
3.) Многие из известных оптимизаций эффективно могут быть сделаны руками. В каких случаях можно попробовать их сделать? Когда применение той или иной оптимизации выгодно и почему?
Соответственно, в дальнейшем я попробую представить образец такой методологии и расскажу об известных мне полезных методах оптимизации приложений.