
Статистика успеха
Почему компании принимают решения о покупке технологий? Или, что не менее важно, почему компании воздерживаются от принятия таких решений? На известных технологических выставках вниманию посетителей предлагается невероятное количество технологий. Тем не менее, определяющим фактором является не выставочная активность и не рекламный блеск, которым окружена технология, а результаты, сказывающиеся на эффективности бизнеса, повышении прибыли и экономии денег.
Sybase активно работает на рынке хранилищ данных уже более 10 лет: сначала с Sybase SQL Server, а теперь - с Sybase Adaptive Server IQ, поставляя высокоэффективные решения в таких областях, как анализ продаж и рынка, финансовое планирование и управление отношениями с клиентами. Сегодня уникальная СУБД для хранилищ данных Sybase Adaptive Server IQ обеспечивает молниеносный доступ к огромным количествам информации, позволяет получить важнейшую информацию, которая ранее была скрыта и недоступна. За три недолгих года, прошедшие с момента появления этой базы данных на рынке, успела сложиться весьма впечатляющая статистика по количеству клиентов и доле на рынке. А вышедший в прошлом году продукт Sybase Warehouse Studio еще больше расширил возможности построения законченных решений из области хранилищ данных на базе нашей специализированной СУБД.
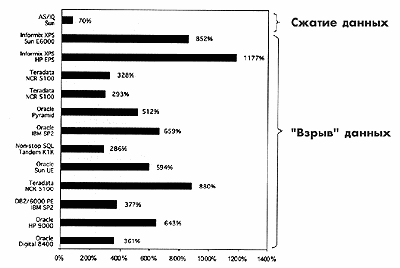
Внизу приведена сводная таблица с информацией о проценте увеличения объема данных (так называемый "взрыв" данных), происходящего при использовании традиционных технологий реляционных баз данных для хранения информации, необходимой для создания хранилища данных. Эта информация была получена нашими конкурентами в результате проведенных ими тестов. Как видно из приведенной ниже таблицы, Sybase Adaptive Server IQ имеет показатель сжатия данных равный 70%, в то время как конкурирующие технологии характеризуются взрывным увеличением объема данных до 300 - 1200% от исходного размера. Сегодня более 500 клиентов Sybase используют Sybase Adaptive Server IQ, который обеспечивает высокоэффективные бизнес-решения всего за часть стоимости конкурирующих технологий.
Хранилища данных и ОББД (Очень Большие Базы Данных) - почему Sybase?
Сегодня организации добиваются повышения своей конкурентоспособности путем быстрого принятия разумных решений, основанных на полной информации. Для того, чтобы правильно реагировать на все изменения рынка, угрозу конкуренции, во время определять и эффективно использовать новые возможности, организациям приходится анализировать огромные количества информации, зачастую поступающие не из одного, а из нескольких географических регионов, бизнес-подразделений и подразделений, сфокусированных на конкретных продуктах.
Хотя в существующих технологиях учитывается необходимость повышения эффективности и производительности запросов, системы хранения данных должны пройти длинный путь в своем развитии для того, чтобы обеспечивать тот уровень гибкости и согласованности, которые необходимы в сегодняшней бизнес-среде, где так много зависит от обладания нужной информацией. Технология должна обеспечивать следующее:
- увеличение скорости ответов на запросы путем сокращения необходимого объема обработки данных;
- поддержка большого количества пользователей без резкого возрастания затрат ресурсов как в однопроцессорных, так и в многопроцессорных системах;
- необходимая гибкость для быстрых ответов на запросы, как запланированные, так и незапланированные, без предварительной настройки;
- эффективное управление большими количествами информации.
Традиционные методологии не решают всех задач, связанных с построением хранилищ данных
Осознавая необходимость обеспечить высокую скорость ответов на аналитические запросы пользователей, компании, разрабатывающие программное обеспечение, включают в свои технологии разнообразные приемы индексирования и дизайна баз данных. В то время как каждый прием имеет свои сильные стороны и оптимизирует выполнение отдельных типов операций, ни один из этих отдельно взятых приемов не удовлетворяет всем требованиям хранилища данных.
Индексирование, основанное на алгоритме сбалансированного двоичного дерева (B-Tree-индексирование) - подходит для OLTP-систем, но не для хранилищ данных
Традиционные реляционные системы управления базами данных (РСУБД) позволили улучшить производительность механизмов поиска за счет использования B-tree-индексов. Индекс предлагает механизм обнаружения записей данных путем отслеживания значений выбранных полей в записи или строке данных и указания непосредственно на те страницы, которые содержат нужное поле. Ненужная информация автоматически отсеивается. Таким образом, для того чтобы найти определенные записи о клиенте, система просто считывает клиентский индекс, а затем переходит непосредственно на ту страницу, где содержится нужная информация. В рамках онлайновой обработки транзакций (OLTP) B-tree-индексы позволяют быстро осуществлять добавление, изменение и доступ к отдельным записям, так как эти индексы прекрасно подходят для поиска единичных записей. Примерами доступа такого типа к данным высокой кардинальности являются добавление, изменение или доступ к отдельным записям, таким как заказы или данные о клиентах.
К сожалению, B-tree-индексы обладают тремя характеристиками, которые делают их неподходящим выбором для приложений, базирующихся на сложных итеративных запросах, таких как получение, суммирование, группирование или сегментация тысяч (или миллионов) записей о транзакциях, необходимых для непредсказуемого (ad-hoc) бизнес-анализа на базе хранилища данных:
- Во-первых, B-tree-индексы практически бесполезны, когда речь идет о данных с немногочисленными уникальными значениями, такими как Женщина/Мужчина, Активный/Пассивный (так называемые "данные с низкой кардинальностью"), поскольку при использовании таких индексов очень малая часть информации будет отсеяна (как если бы индекс использовался для поиска в книге всех страниц с союзом "и" - легче открыть книгу в самом начале и последовательно просмотреть все страницы). Это объясняет, почему, для того чтобы преодолеть описанное ограничение традиционных реляционных баз данных и B-tree индексов, данные нуждаются в обязательной пре-агрегации.
- Второе ограничение B-tree-индексов при использовании их в хранилищах данных - это стоимость создания и поддержки таких индексов. Поскольку B-tree-индексы содержат сами значения данных и, кроме этого, карты индексов (maps), индексы становятся все больше по мере того, как возрастает объем индексируемых данных. Это может привести к "раздуванию" хранилища данных до размеров, в 2 - 3 раза превосходящих первоначальный объем "сырых" данных. B-tree-индексы также чрезвычайно чувствительны к массовым загрузкам и обновлениям данных, которые приводят к значительной реорганизации и снижают производительность. Изменения данных, составляющие 10 - 15%, зачастую могут повлечь за собой необходимость полной перестройки индекса.
- И наконец, B-tree-индексы созданы для использования в средах, где запросы относительно просты, а пути доступа к данным известны и настроены заранее. В типичном случае реляционная база данных вычисляет индексы последовательно, что приводит к хорошим результатам, если один из индексов очень высокоизбирателен, как, например, при возврате всех невыполненных заказов определенного клиента (типичная OLTP-транзакция). Этот подход гораздо менее уместен для приложений на базе хранилищ данных, объединяющих множество низкоизбирательных условий, а также условий группировки и сегментации. Для преодоления этого ограничения B-tree-индексов детальные записи транзакций пре-агрегируются для повышения производительности. Такая пре-агрегация часто повышает производительность специфического запроса, но за значительную стоимость, если вспомнить о дополнительном пространстве для данных и индексов. Не являются редкостью случаи, когда необходимое для агрегированных данных и поддерживающих индексов пространство в 3 -7 раз превышает пространство, занимаемое "сырыми" данными. Это еще одна причина "взрывов" данных, происходящих в традиционных реляционных базах данных.
В целом, B-tree-индексы могут найти лишь весьма ограниченное применение в настоящих "ad-hoc"-приложениях на базе хранилищ данных. Использование B-tree-индексов в таких системах приводит к плохой производительности или необходимости очень ресурсоемких настроек, таких как построение дополнительных индексов для каждого незапланированного ("ad-hoc") запроса. Это и является основной причиной "взрыва" данных.
Bitmap-индексирование - ограниченные возможности
Ряд нереляционных баз данных использует списки-инверсии (или bitmap-индексы) для повышения производительности приложений поддержки принятия решений. Вместо использования B-tree, bitmap-индексы создают массивы для каждого индивидуального значения поля и для каждой записи в каждом массиве указывают, верно ("1") или неверно ("0") это значение. Bitmap-индексам не свойственны некоторые ограничения, характерные для B-tree-индексов. В отличие от B-tree-индексов Bitmap-индексы эффективно представляют данные низкой кардинальности, занимают меньше места, ими легче управлять и можно обрабатывать одновременно. Традиционным bitmap-индексам свойственны 2 ограничения:
- Во-первых, по мере возрастания количества индивидуальных значений объем хранилища может быстро увеличиваться. Например, поле "штат" (имеется в виду американский штат), которое представлено в 2 байтах (16 бит) в большинстве бизнес-информации, потребовало бы 50 бит (по одному на каждый штат) или более для представления в виде bitmap. Для того чтобы сделать эту технологию индексирования удобной для использования с данными с большим числом отдельных значений и воспользоваться преимуществами побитового хранения, необходимо использовать технологии упаковки данных. Большинство баз данных не приспособлено для работы с упакованными структурами данных.
- Во-вторых, достаточно эффективные при работе с данными низкой кардинальности bitmap-индексы совершенно не подходят для данных высокой кардинальности, поскольку, в том виде, в котором они реализованы в большинстве баз данных, они требуют создания отдельного битового массива для каждого уникального значения. Непрактичность использования этой технологии с непрерывными данными, такими как прибыль или имя и адрес, которые могут иметь миллионы возможных значений, совершенно очевидна. Таким образом, в большинстве случаев система должна продолжать обрабатывать детальные записи, а зачастую и значительные порции всей таблицы для того, чтобы выполнить любой запрос, который совмещает данные низкой и высокой кардинальности. Это практически ставит крест на большинстве из преимуществ по производительности, которыми обладают bitmap-индексы. Bitmap-индексы также ограничены в своей возможности агрегировать данные, осуществлять соединения таблиц и просто возвращать значения "сырых" данных.
Инновационная технология Bit-Wiseд-индексирования для рентабельных высокопроизводительных хранилищ данных
Эксклюзивная запатентованная технология Bit-Wise-индексирования, используемая в Sybase Adaptive Server IQ, позволяет нам поставлять рентабельные, быстрые, гибкие и масштабируемые приложения на основе хранилищ данных.
Рентабельность: максимально эффективно используйте ваше компьютерное оборудование и ресурсы
При использовании Sybase Adaptive Server IQ размер всех структур данных (данных и индексов) составляет всего 20% от размера, обычного для традиционных РСУБД, что позволяет значительно сократить расходы на дисковое пространство. Различные методы сокращения объема данных и методы упаковки позволяют построить всю базу данных вместе с индексами для незапланированных запросов на меньшем пространстве, чем обычно требуется для хранения только "сырых" данных, сокращая расходы на необходимое компьютерное оборудование, позволяя хранить больше информации для анализа, снижая, в то же время, стоимость хранения. Эта СУБД эффективно обрабатывает запросы, манипулируя только теми данными, которые имеют непосредственное отношение к запросу, и позволяет полностью избежать потерь времени на сканирование таблиц.
Обработка запросов без настройки, сокращение затрат на администрирование
Одно из самых главных преимуществ, которое обеспечивает системам поддержки принятия решений Sybase Adaptive Server IQ - это возможность обрабатывать незапланированные расходы также легко как запланированные при минимальной ручной настройке. Обработка только значимой для конкретного запроса информации позволяет эффективно обрабатывать запросы. Администраторам не нужно заранее определять все специфические запросы или операции для того, чтобы добиться хорошей производительности, в отличие от случаев использования традиционных РСУБД и B-tree-индексов. Sybase Adaptive Server IQ позволяет экономить средства путем снижения затрат на администрирование и в то же время позволяет эффективно использовать дисковое пространство за счет отказа от ненужных индексов.
Защита инвестиций в существующее компьютерное и программное обеспечение
Sybase Adaptive Server IQ не требует кластерных или MPP-конфигураций компьютерного оборудования для высокой производительности или хранения больших объемов информации. Sybase Adaptive Server IQ может расширить возможности практически любой информационной среды, позволяя вашей организации увеличить производительность существующего компьютерного оборудования и программного обеспечения, сокращая расходы и в то же время расширяя возможности бизнес-анализа для бизнес-пользователей вашей организации. Ваша организация может эффективно использовать Sybase Adaptive Server IQ для создания новых приложений для поддержки принятия решений при минимальных инвестициях в новое компьютерное и программное обеспечение и людские ресурсы для администрирования базы данных. Sybase Adaptive Server IQ полностью совместима с мощными популярными инструментами обработки незапланированных запросов, которые используются сегодня для поддержки принятия решений.
Исключение "взрыва" данных
Как уже говорилось раньше, использование традиционных реляционных баз данных в рамках хранилища данных приводит к "взрыву" данных. Это приводит к тому, что стоимость больших хранилищ становится непреодолимым препятствием для осуществления проекта. Sybase Adaptive Server IQ исключает "взрыв" данных по двум причинам. Во-первых, наша технология сжимает данные на этапе их загрузки в Adaptive Server IQ. Например, использование Sybase Adaptive Server IQ позволило IRS (Налоговая Служба США) хранить 598 Гб "сырых" данных в 379 Гб хранилища данных - процент сжатия при этом составил 63%. Во-вторых, скорость и гибкость Sybase Adaptive Server IQ при работе с незапланированными запросами позволяет обходиться практически без пре-агрегации, которая является настоящим бедствием при использовании для создания хранилищ данных традиционных РСУБД. Согласно результатам тестов TPCD, технологии наших конкурентов требуют для построения хранилища данных пространства, в 3 - 11 раз превышающего объем "сырых" данных.
Скорость: Sybase Adaptive Server IQ обеспечивает высокопроизводительный бизнес-анализ
Sybase Adaptive Server IQ не только исключает "взрыв" данных, но и дает возможность бизнес-пользователям получать ответы на сложные аналитические запросы в 10 - 100 раз быстрее, чем при использовании традиционных РСУБД. В случае использования обычной РСУБД, даже при наличии самых оптимальных условий, обработка аналитического запроса может занять часы, в то время как Sybase Adaptive Server IQ позволяет получить ответ на тот же запрос через секунды или минуты. Такой уровень производительности достигается в Adaptive Server IQ за счет ввода/вывода дисковых блоков по 64 Кб в сочетании с избирательным доступом к колонкам и упаковкой, что в результате может обеспечить сокращение количество ввода/вывода на 98%. Сокращение ввода/вывода устраняет главное узкое место, характерное для большинства систем поддержки принятия решений при аналитической обработке запросов, и обеспечивает быстрое получение результатов. Sybase Adaptive Server IQ оптимизирует операции по манипулированию данными, такие как суммирование, группирование и сегментирование, путем использования преимуществ быстрых процессоров, по возможности - больших кэшей памяти, а также самых современных мультипроцессорных архитектур.
Гибкость: Sybase Adaptive Server IQ позволяет пользователям задавать вопросы в той форме, которая им удобна
Sybase Adaptive Server IQ не нуждается в специальных моделях данных, индексах или методах агрегации, необходимых для преодоления ограничений традиционных для B-tree-индексов. В Sybase Adaptive Server IQ индексирование ведется по полям/колонкам, а не по записям/рядам, так что специфические свойства колонок и характерные операции над ними (такие, как хранение текстов, арифметические операции/агрегация, группирование/сегментирование, низкая кардинальность и пр.) задаются сразу при создании базы данных, и пользователи хранилища смогут задавать неограниченное число сложных незапланированных запросов, не требующих специальной настройки администратором баз данных. Если запросы бизнес-пользователя к хранилищу, основанному на традиционной базе данных с порядовыми B-tree-индексами не укладываются в порядовую модель данных, индекс или преаггрегацию, необходимо будет провести существенную работу по настройке запроса и дизайну системы, чтобы ответить на эти запросы. Sybase Adaptive Server IQ поддерживает любые модели данных с помощью стандартных средств генерации запросов с открытой архитектурой. Это позволяет строить приложения основываясь только на нуждах бизнес-пользователя, вместо того, чтобы подстраиваться под ограничения, накладываемые технологиями баз данных.
Масштабируемость: обеспечение доступа большого количества пользователей к большим объемам данных
По мере роста числа пользователей хранилищ задача обеспечения бесперебойной и высокоэффективной обработки многочисленных одновременных запросов становится все более важной. Sybase Adaptive Server IQ может выполнять ресурсоемкие операции, такие, например, как загрузка данных, на многих процессорах в среде SMP. Что еще более важно, эта архитектура позволяет обрабатывать запросы параллельно на многих процессорах, и выполнять многочисленные запросы одновременно практически без снижения производительности системы. В то же время эффективность работы традиционных баз данных резко падает при возрастании количества пользователей и объемов данных.
Warehouse Studio обеспечивает полноту решения
Sybase поставляет интегрированную платформу для проектирования, запуска в эксплуатацию и администрирования хранилищ данных - Sybase Warehouse Studio. Этот комплект инструментов для работы с хранилищем обеспечивает лидирующую по индустрии производительность, интеграцию данных и утилизацию компьютерных ресурсов, что позволяет строить решения в таких областях, как анализ рынка, анализ взаимоотношений с клиентами, финансовое планирование. Sybase Warehouse Studio предоставляет все необходимые инструменты для дизайна хранилищ и витрин данных, для интеграции и трансформации данных из различных источников, для визуализации и анализа этих данных, и для единого взгляда на модель данных с помощью интегрированного браузера мета-данных. Warehouse Studio использует преимущества лучших в индустрии средств промежуточного слоя Sybase, чтобы интегрировать и использовать существующие данные, и чтобы распространять данные внутри предприятия и за его пределами. Технологии хранилищ данных Sybase, вместе с программными приложениями наших партнеров, позволяют строить решения, эффективно обеспечивающие любые нужды в хранилищах данных, от витрины, сфокусированной на одном проекте, до информационной структуры всего предприятия.