
Управление рабочей нагрузкой чрезвычайно важно для бизнеса по требованию. IBM® LoadLeveler® является системой управления заданиями, позволяющей пользователям запустить на выполнение большее число заданий за меньшее время при помощи согласования требований обработки заданий с доступными ресурсами. Поддержка максимального времени безотказной работы системы управления заданиями становится все более важной. Узнайте, как можно достичь повышенной готовности LoadLeveler-кластера с использованием встроенных возможностей LoadLeveler и дальнейшего ее улучшения при помощи программного обеспечения с открытыми исходными кодами.
IBMLoadLeveler - это система управления рабочей нагрузкой, позволяющая пользователям назначать, планировать и выполнять задания в пуле ресурсов. Она обеспечивает динамическое планирование и согласование рабочей нагрузки для оптимального использования ресурсов кластера. Она также предоставляет единый центр управления заданиями и рабочей нагрузкой.
LoadLeveler выполняется в виде набора фоновых процессов (демонов) на каждой клиентской машине. Группа клиентских машин, связывающаяся с центральной машиной управления, называется LoadLeveler-кластером , который определяется при помощи конфигурационного файла.
Для наилучшего усвоения материала вы должны иметь базовые знания по IBM LoadLeveler и кластерам с повышенной готовностью. Вы должны быть также знакомы с первой статьей этой серии "Программное обеспечение повышенной готовности промежуточного уровня в Linux, часть 1: heartbeat и Web-сервер Apache".
Реализация LoadLeveler для повышенной готовности
Каждая машина в LoadLeveler-кластере выполняет одну или несколько ролей в планировании заданий. Эти роли и последствия их неисполнения таковы:
- Машина планирования загрузки: Регистрация задания означает размещение его в очереди машиной планирования загрузки. Машина планирования загрузки запрашивает машину центрального управления (эта роль описывается ниже) найти машину, которая сможет выполнить задание. Машина планирования загрузки хранит также постоянную информацию о задании на диске.
Информация о задании на одной машине планирования загрузки обычно не разделяется с другими машинами планирования загрузки в LoadLeveler-кластере. Эти машины работают независимо, и в случае аварии информация о задании на такой машине будет временно недоступной (но не потерянной). Задания, ожидающие планирования, не будут рассматриваться в течение этого времени. Очень важно восстановить работоспособность как можно скорее. В примере с конфигурацией повышенной готовности для машины планирования загрузки все необходимые локальные файлы и каталоги размещаются на внешнем дисковом хранилище, что делает их доступными для резервной машины планирования загрузки в случае аварии узла. - Машина центрального менеджера: Ролью машины центрального менеджера является поиск одной или нескольких машин, которые выполнят задание, в LoadLeveler-кластере, основываясь на требованиях задания. Найдя такую машину(ы), центральный менеджер уведомляет машину планирования загрузки.
Машина центрального менеджера является центральным пунктом управления для LoadLeveler. LoadLeveler позволяет вам определить альтернативный центральный менеджер, который может взять на себя роль основного центрального менеджера в случае аварии. Подробно об этом рассказывается в следующем разделе.
В случае выхода из строя центрального менеджера без определенного альтернативного центрального менеджера выполняющиеся задания будут выполнены до конца без потери информации, но их статус не будет сообщен пользователям. Новые задания будут приняты узлами планирования и далее перенаправлены центральному менеджеру, когда он возобновит свою работу, либо его роль станет выполнять альтернативный менеджер. - Выполняющая машина: Машина, которая выполняет задание, называется выполняющей машиной.
В случае выхода из строя выполняющего узла, выполняющиеся на нем задания потерпят неудачу и потребуется их перезапуск после восстановления работы узла. Задания начнут выполняться сначала или с последней контрольной точки. Создание контрольных точек может быть выбрано как вариант, или закодировано в приложении. Организация резервного выполняющего узла немедленно обеспечит возможность своевременного перезапуска задания. С резервным узлом или без него, задания, информация о них и контрольные точки не теряются в случае аварии, поскольку их диски все еще доступны (при использовании соответствующих приемов разводки кабелей и организации дискового хранилища).
И узел планирования, и выполняющие узлы хранят постоянную информацию о состоянии своих заданий. Узел планирования и выполняющий узел используют протокол, гарантирующий, что информация о состоянии хранится на диске по крайней мере одного из них. В случае аварии это дает возможность восстановления информации о состоянии либо с узла планирования, либо с выполняющего узла. Ни узел планирования, ни выполняющий узел не удаляет информацию о задании до тех пор, пока она не будет передана и принята другим узлом. В обсуждаемой в этой статье конфигурации информация о заданиях хранится на общем диске. - Подтверждающая машина: Эта машина используется для подтверждения, запроса и снятия заданий и не имеет данных постоянного хранения о задании. Отсутствие таких данных делает обеспечение повышенной готовности для этих машин не актуальным.
Роль, которую играет клиентская машина, зависит от того, какие фоновые процессы (демоны) LoadLeveler сконфигурированы на ней. В целом кластер обеспечивает возможность создания, подтверждения, выполнения и управления последовательными и параллельными пакетными заданиями.
В следующем разделе мы обсудим некоторые из встроенных возможностей LoadLeveler для обеспечения повышенной готовности, а также способы улучшения готовности всей системы при использовании heartbeat.
Установка IBM LoadLeveler
В данном разделе показано, как установить IBM LoadLeveler 3.2 for Linux™ на трех машинах: ha1, ha2 и ha3. Эти шаги основаны на инструкциях по установке, приведенных в Главе 4 документа "LoadLeveler Installation Memo" .
Создайте следующие каталоги для LoadLeveler:
-
- Локальный каталог: /var/loadl
- Домашний каталог: /home/loadl
- Каталог выпуска (release): /opt/ibmll/LoadL/full
- Имя машины центрального менеджера: ha
- Зарегистрируйтесь как root
- Создайте группу с именем loadl. Приведенная ниже команда создает группу
loadlс ID группы 1000 на всех узлах:groupadd g 1000 loadl
- Создайте пользователя с именем loadl. Приведенная ниже команда создает userid
loadlна всех узлах:useradd c loadleveler_user -d /home/loadl -s /bin/bash -u 1000 g 1000 -m loadl
- Установите RPM-пакеты LoadLeveler
- Установите RPM лицензии (в котором
LLIMAGEDIRсодержит установочный RPMS)cd $LLIMAGEDIR rpm -Uvh LoadL-full-license-3.2.0.0-0.i386.rpm
- Установите остальные RPM
cd /opt/ibmll/LoadL/sbin ./install_ll -y -d "$LLIMAGEDIR"
- Установите RPM лицензии (в котором
- Запустите сценарий инициализации llinit
- Создайте локальный каталог:
mkdir /var/loadl
- Настройте права доступа
chown loadl.loadl /var/loadl
- Перейдите в
loadl
IDsu - loadl
- Перейдите из текущего каталога в подкаталог bin каталога редакции, выполнив следующую команду:
cd /opt/ibmll/LoadL/full/bin
- Убедитесь, что вы имеете права на запись в каталогах LoadLeveler home, local и /tmp
- Выполните команду
llinitследующим образом:./llinit -local /var/loadl -release /opt/ibmll/LoadL/full -cm ha
- Создайте локальный каталог:
Создание конфигурации машины планирования загрузки с повышенной готовностью
В данной установке:
- Машина ha1 будет работать как основная машина планирования загрузки
- Машина ha2 будет работать как резервная машина планирования загрузки
- Машина ha3 будет использоваться как выполняющая задания машина
В конфигурации для повышенной готовности необходимые для ha1 файлы и каталоги помещаются на внешнем общем устройстве хранения, что делает их доступными для ha2 в случае выхода из строя узла планирования загрузки. Вот как это установить:
- Зарегистрируйтесь под именем root на узлах ha1 и ha2.
- Создайте следующие каталоги на общем диске (/ha):
- /ha/loadl/execute
- /ha/loadl/spool
- Установите права доступа, выполнив следующие команды на узле ha1:
chown loadl.loadl /ha/loadl/ chown loadl.loadl /ha/loadl/execute chown loadl.loadl /ha/loadl/spool
- Перейдите к ID loadl на узлах ha1 и ha2:
su - loadl
- Установите соответствующие права доступа для общих каталогов при помощи приведенных ниже команд на узле ha1:
chmod 0777 /ha/loadl/execute chmod 775 /ha/loadl/spool
- На узлах ha1 и ha2, удалите каталоги execute и spool в /var/loadl.
rm -rf /var/loadl/execute rm rf /var/loadl/spool
- Создайте символическую ссылку на общие каталоги, используя следующие команды на узлах ha1 и ha2:
ln -s /ha/loadl/execute /var/loadl/execute ln -s /ha/loadl/spool /var/loadl/spool
- Отредактируйте информацию о машине. Ниже показана соответствующая часть файла LoadL_admin (в каталоге /home/loadl) на различных узлах:
- ha1 работает как основная машина планирования загрузки и как центральный менеджер. В производственной среде я рекомендую размещать центральный менеджер и демон планирования загрузки на отдельных машинах.
... ha1: type = machine central_manager = true schedd_host = true ha3: type = machine ... - ha2 работает как резервная машина планирования загрузки и резервный центральный менеджер
... ha2: type = machine central_manager = true schedd_host = true ha3: type = machine ... - ha3 работает как выполняющая машина
... ha: type = machine central_manager = true schedd_host = true ha3: type = machine ...
- ha1 работает как основная машина планирования загрузки и как центральный менеджер. В производственной среде я рекомендую размещать центральный менеджер и демон планирования загрузки на отдельных машинах.
- Измените флажки
RUNS_HEREв файле LoadL_config (в /home/loadl) на различных машинах следующим образом:- ha1 и ha2
... SCHEDD_RUNS_HERE = True STARTD_RUNS_HERE = False ...
Это запретит выполнение заданий на машинах планирования загрузки. Мы хотим, чтобы ha1 и ha2 работали только как машины планирования загрузки. - ha3
... SCHEDD_RUNS_HERE = False STARTD_RUNS_HERE = True ...
- ha1 и ha2
- Отредактируйте файлы /etc/hosts на трех узлах следующим образом:
- ha1
... 9.22.7.46 ha.haw2.ibm.com ha 9.22.7.46 ha2.haw2.ibm.com ha2 ...
- ha2
... 9.22.7.46 ha.haw2.ibm.com ha 9.22.7.46 ha1.haw2.ibm.com ha1 ...
- ha3
... 9.22.7.46 ha.haw2.ibm.com ha 9.22.7.46 ha1.haw2.ibm.com ha1 9.22.7.46 ha2.haw2.ibm.com ha2 ...
- ha1
Настройка heartbeat для управления машиной планирования загрузки
Чтобы настроить heartbeat на управление LoadLeveler:
- Создайте сценарий для запуска и останова процессов LoadLeveler. Очень обобщенный сценарий приведен в листинге 1. Вы можете настроить его под свои требования. Поместите этот сценарий в каталог /etc/rc.d/init.d.
#!/bin/bash # # /etc/rc.d/init.d/loadl # # Запускает процессы loadleveler # # chkconfig: 345 89 56 # description: Runs loadleveler . /etc/init.d/functions # Источник библиотеки function. PATH=/usr/bin:/bin:/opt/ibmll/LoadL/full/bin #==================================================================== SU="sh" if [ "`whoami`" = "root" ]; then SU="su - loadl" fi #==================================================================== start() { echo "$0: starting loadleveler" $SU -c "llctl start" } #==================================================================== stop() { echo "$0: Stoping loadleveler" $SU -c "llctl stop" } case $1 in 'start') start ;; 'stop') stop ;; 'restart') stop start ;; *) echo "usage: $0 {start/stop/restart}" ;; esac - Теперь, настройте файл /etc/ha.d/haresources (на обоих узлах планирования загрузки) и включите в него сценарий loadl. Соответствующая часть модифицированного файла выглядит так:
ha1.haw2.ibm.com 9.22.7.46 Filesystem::hanfs.haw2.ibm.com:/ha::/ha::nfs::rw,hard loadl
Эта строка предписывает, чтобы при запуске heartbeat ha1 приняла IP-адрес кластера, смонтировала общую файловую систему и запустила фоновые процессы LoadLeveler. При останове heartbeat сначала остановит LoadLeveler, затем демонтирует общую файловую систему и, наконец, освободит IP.
Тестирование аварии на машине планирования загрузки
В этом разделе показано, как протестировать повышенную готовность фонового процесса планировщика.
- Запустите службу heartbeat на основном, а затем на резервном узлах при помощи следующей команды:
/etc/rc.d/init.d/heartbeat start
После успешного запуска heartbeat вы должны увидеть новый интерфейс с IP-адресом, который вы сконфигурировали в файле ha.cf. Сразу после запуска heartbeat просмотрите ваш log-файл (по умолчанию - /var/log/ha-log) на основном узле и убедитесь, что был принят IP и затем запущен LoadLeveler. Используйте команду ps для проверки выполнения фоновых процессов LoadLeveler на основном узле. Heartbeat не запускает эти процессы на резервном узле. Это случится только в случае аварии на основном узле. - Запустите фоновые процессы loadleveler на ha3, зарегистрировавшись как пользователь loadl и используя следующую команду:
llctl start
- Сделайте ha3 недоступным в качестве выполняющей машины, остановив фоновый процесс startd. Это необходимо для обеспечения достаточного времени после подтверждения работы для тестирования аварии. Используйте следующую команду как пользователь loadl на узле ha3:
llctl drain startd
- Проверьте, какие задания запланированы на выполнение в LoadLeveler-кластере, используя следующую команду на машине ha1 как пользователь loadl:
llq
На рисунке 1 показана информация, которая отобразится на экране после выполнения этой команды. Отобразится список всех незавершенных заданий на LoadLeveler-кластере.Рисунок 1. Отображаемая командой llq информация на узле ha1
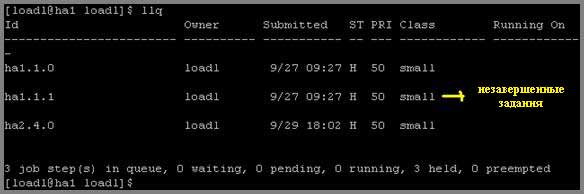
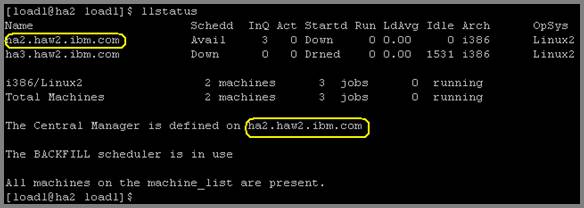
Проверьте состояние машин LoadLeveler-кластера при помощи выполнения следующей команды на машине ha1, зарегистрировавшись как пользователь loadl:llstatus
Рисунок 2. Отображаемая командой llstatus информация на узле ha1

На рисунке 2 вы можете увидеть, что на машине ha1 доступен Scehdd, а Startd остановлен (drained) на машине ha3 в соответствии с шагом 3. - Установите права доступа на каталог samples. Используйте приведенную ниже команду на узле ha3 (на котором будет выполняться задание):
chown loadl.loadl /opt/ibmll/LoadL/full/samples
- Подтвердите задание. Подтвердите одно из примерных заданий, предоставленных с LoadLeveler, выполнив приведенные ниже команды на машине ha1 и зарегистрировавшись как пользователь loadl:
cd /home/loadl/samples llsubmit job1.cmd
Если все нормально, вы увидите примерно такое сообщение:llsubmit: The job "ha1.haw2.ibm.com.23" with 2 job steps has been submitted.
Пример job1 представляет собой задание, состоящее из двух этапов, которое должно вызвать создание двух новых этапов задания. Эти два новых этапа задания перейдут в состояние ожидания (I) при недоступности выполняющей машины. См. рисунок 3.Рисунок 3. Отображаемая командой llq информация на узле ha1 после подтверждения job1

Теперь, остановите машину планирования загрузки. - Эмулирование аварии. Вы можете сделать это, просто остановив heartbeat на основной системе при помощи следующей команды:
/etc/rc.d/init.d/heartbeat stop
Вы увидите, что менее чем за минуту все службы запустятся на резервной машине. Вы можете убедиться в том, что LoadLeveler работает на резервном узле, проверив файл /var/log/ha-log и используя команду ps на резервной машине. Сразу после того, как резервная машина возьмет управление на себя, запустите командыllstatusиllqна резервном узле, зарегистрировавшись как пользователь loadl. На рисунках 4 и 5 показана информация, отображаемая при выполнении этих команд.Рисунок 4. Отображаемая командой llq информация на узле ha2 после аварии
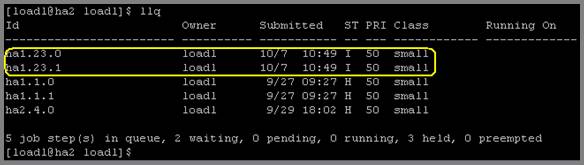
Рисунок 5. Отображаемая командой llq информация на узле ha1 после подтверждения job1
Обратите внимание на рисунки 4 и 5:- Отображаются все старые незавершенные задания, включая два задания, соответствующих заданию, подтвержденному выше на шаге 6. Это доказывает, что информация о задании пережила отказ в работе машины.
- Schedd теперь доступен на машине ha2.
- Startd все еще не работает на машине ha3.
- Продолжите работу фонового процесса startd на машине ha3 при помощи выполнения следующей команды на ha3, зарегистрировавшись как пользователь loadl:
llctl resume startd
Теперь машина ha3 доступна для выполнения заданий. Два задания должны перейти в состояние выполнения и завершиться на машине ha3. Вы можете убедиться в завершении работы, взглянув на файлы .out, созданные этими двумя шагами задания в каталоге /home/loadl/samples на машине ha3. Вы должны увидеть следующие файлы: job1.ha1.23.0.out и job1.ha1.23.1.out. - Снова запустите службу heartbeat на основном узле. Это должно остановить LoadLeveler-процессы на вторичной машине. Основная машина должна также взять контроль над IP-адресом кластера. Запустите службу heartbeat при помощи следующей команды:
/etc/rc.d/init.d/heartbeat start
Вы видите, как, используя общий диск, подтвержденные на выполнение задания перед аварией основного узла планирования загрузки были восстановлены после того, как управление принял на себя резервный узел.
Настройка повышенной готовности центрального менеджера
Если вы решили запустить центральный менеджер на отдельном от планировщика загрузки узле (ha4), вы можете воспользоваться преимуществами встроенных функций обеспечения повышенной готовности центрального менеджера. Для того чтобы попробовать эту конфигурацию, определите машину ha4 в качестве центрального менеджера в конфигурационных файлах всех машин.
Проблемы с взаимодействием по сети, программные или аппаратные сбои могут явиться причиной недоступности центрального менеджера. В таких ситуациях другие машины в LoadLeveler-кластере будут считать, что центральный менеджер больше не работает. Вы можете исправить эту ситуацию, назначив одного или более альтернативных центральных менеджера в настройках машины.
Следующий пример настройки машины определяет машину ha5 альтернативным центральным менеджером:
ha5: type = machine
central_manager = alt
|
Если основной центральный менеджер потерпит аварию, центральным менеджером станет альтернативный. Когда альтернативный становится центральным менеджером, задания не будут потеряны, но регистрация всех машин в кластере в новом центральном менеджере может занять несколько минут. В результате запросы о состоянии заданий могут на короткий промежуток времени быть некорректными.
Когда вы определяете центральные менеджеры, вы должны установить следующие ключевые слова в конфигурационном файле:
CENTRAL_MANAGER_HEARTBEAT_INTERVAL = <время в секундах> CENTRAL_MANAGER_TIMEOUT = <количество heartbeat-интервалов> |
В приведенном ниже примере альтернативный менеджер будет ждать в течение двух интервалов времени, каждый интервал длится 30 секунд:
CENTRAL_MANAGER_HEARTBEAT_INTERVAL = 30 CENTRAL_MANAGER_TIMEOUT = 2 |
Тестирование выхода из строя машины центрального менеджера
Вы можете протестировать аварию, сняв процесс центрального менеджера под названием Loadl_negotiator на машине ha4. Для предотвращения повторного запуска фонового процесса центрального менеджера на этом же узле вы должны установить ключевое слово RESTARTS_PER_HOUR в 0. В течение минуты это вызовет запуск центрального менеджера на альтернативном узле ha5.
Настройка повышенной готовности для выполняющих машин LoadLeveler
Настройка аналогична настройке повышенной готовности для машин планирования загрузни.
Заключение
В этой статье вы увидели, как реализовать повышенную готовность для LoadLeveler-кластера, используя встроенные возможности LoadLeveler, а также как дополнительно улучшить готовность при помощи программного обеспечения с открытыми исходными кодами. В четвертой части этой серии статей будет рассмотрена реализация функций повышенной готовности на IBM WebSphere® Application Server.