
Технология NVIDIA VGX выводит корпоративный PLM на облачную орбиту
Все мы отлично знаем NVIDIA как производителя игровых видеокарт GeForce, профессиональных решений Quadro и Tesla, а также процессоров Tegra для мобильных устройств. Как выяснилось на конференции GTC 2012, пять последних лет инженеры компании работали еще в одном направлении - аппаратно-программной технологией VGX, которая, скорее всего, позволит NVIDIA занять прочное место на рынке серверных решений и облачных вычислений для профессиональных графических приложений. И в выбранной нише конкурентов пока не наблюдается.
Естественно, одним из наиболее важных применений NVIDIA VGX являются приложения PLM.
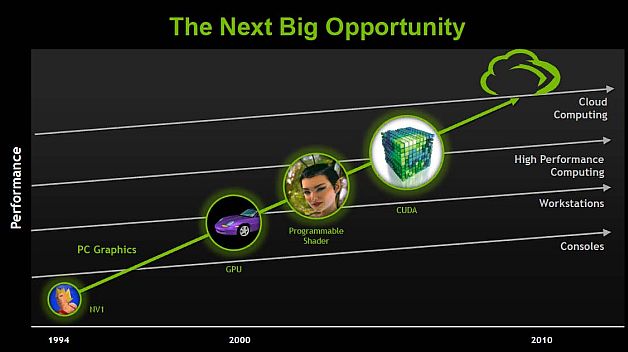
NVIDIA устремляется в облака. (Источник: NVIDIA.)
А в чём, собственно, проблема?
Технологии клиент-серверных архитектур, виртуализации, облачных вычислений и других вариаций на тему "запускаю программу здесь - а вычисляется где-то там" существуют не один десяток лет, и этот рынок фактически был создан крупнейшими корпорациями - поставщиками аппаратного и программного обеспечения. Казалось бы, придумать что-то принципиально новое здесь очень непросто. Но, как известно, талантливые люди всегда находят место для творчества и импровизации.
NVIDIA пошла здесь тем же путём, как и когда-то при изобретении GPU: тогда "тяжелые" приложения (игры и трехмерная визуализация) обрабатывались с неприемлемой скоростью с помощью CPU. Почему бы не создать для них специализированное устройство?
Похожая ситуация существует сейчас и на рынке VDI приложений (Virtual Desktop Infrastructure): серверные CPU отлично справляются с большинством приложений, они могут быть виртуализованы (т.е. один физический CPU назначен многим виртуальным машинам). Но как быть с теми десктопными приложениями, для которых вычислительной мощности CPU недостаточно, и для которых уже более десяти лет используются видеокарты?
Конечно, существуют серверные технологии, использующие GPU. Однако их недостатки довольно очевидны:
- Отсутствие аппаратной виртуализации GPU: либо один GPU отдается в монопольное владение одному пользователю, либо разделение GPU между виртуальными машинами (пользователями) выполняется на программном уровне - как это было сделано в относительно недавнем решении Microsoft RemoteFX.
- Проблема с энергопотреблением: невозможно поставить на сервер большое количество GPU.
- Латентность: одна из причин низкой скорости отклика - это неэффективность программно-аппаратной архитектуры подключения GPU. Например, данные, уже обработанные видеокартой, должны были быть переданы из памяти GPU в память CPU, где они кодировались в видеопоток H.264 и только после этого передавались на машину пользователя.
Несомненно, всё это порождало экономическую нецелесообразность применения GPU на серверах и серьезно ограничивало круг пользователей.
NVIDIA отвечает на вызов выпуском VGX
NVIDIA атаковала проблемы серверного использования GPU по всем фронтам, предложив технологию VGX, состоящую из трех главных компонент: VGX плата на базе Kepler GPU, VGX Hypervisor, VGX USM (User Selectable Machines).
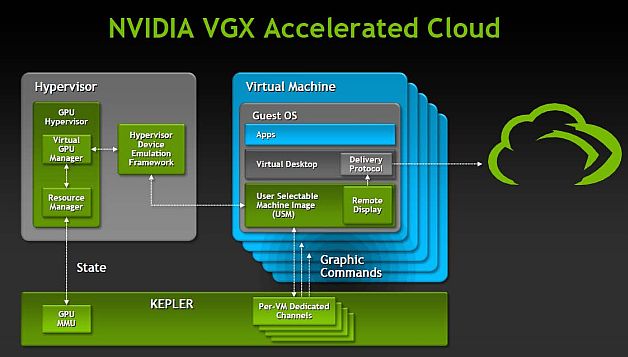
Схема работы VGX. (Источник: NVIDIA.)
Виртуализация GPU достигается за счет использования архитектуры Kepler и специального аппаратного модуля MMU (Memory Management Unit), позволяющего определять, из какой виртуальной машины пришла определенная команда, и возвращать ей результат. Латентность снижена за счет использования Low Latency Remote Display: технологии, включающей поддержку на аппаратном уровне кодировщика данных в видеопоток H.264. Ну а достижение максимальной энергоэффективности ("Производительность / Ватт") было главным приоритетом инженеров при разработке архитектуры Кеплер.
VGX Hypervisor является программной прослойкой между платой VGX и внешними гипервизорами, обеспечивая полную программную поддержку виртуализации GPU.
VGX USM &mdash - это, фактически, набор настроек управления для системного администратора, позволяющий задать параметры виртуальных машин и GPU для групп пользователей.
Сама VGX плата состоит из 4 GPU, в каждом из которых 192 ядра CUDA и 4 ГБ памяти. Она позволяет одновременную работу до сотни пользователей, подключающихся к серверу со своих ПК, смартфонов или планшетов с помощью, например, Citrix Receiver, который уже доступен для Windows, Mac, iPad, Android, а также существует в браузерных вариантах. Чтобы не возникало путаницы с традиционным VDI, вся технология виртуализации называется GPU-VDI.
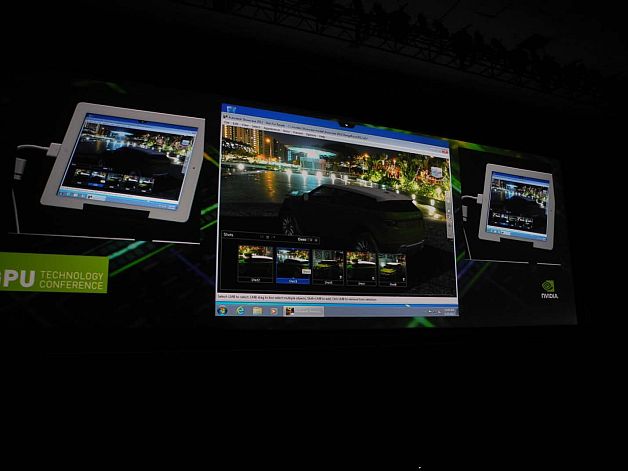
iPad с Citrix Receiver: ОС Windows c 1536 ядрами CUDA. Запущен Autodesk Showcase 2012.
Сравнение работоспособности традиционного VDI (слева) и GPU-VDI (справа).
PLM в облаках и на планшетах: надежды и скептицизм
Технологии - это замечательно, но, чтобы начать зарабатывать на них деньги, должна быть сформирована рыночная ниша. Здесь полезно вспомнить о настроениях, царивших в последнее время в PLM-индустрии относительно перспектив облачных вычислений. Тем более тема "облаков и САПР" приобрела признаки особой известности, которую уже уместно назвать "печальной".
Чего стоит один лишь SolidWorks V6, над которым Dassault Systemes работает пять лет, а вся технология еще окутана - нет, не облаками, а туманом или даже сумраком. Или знаменитый облачный PLM от Autodesk, который, хотя и был воспринят с энтузиазмом, но до сих пор вызывает у публики улыбку и ностальгию по тем временам, когда PLM считался словом из трех букв. Впрочем, известны примеры, когда публичные облачные сервисы вполне работоспособны (Autocad WS, 3ds Max, Компас 3D, To3D, и др.), хотя и не всегда ясно, насколько они коммерчески успешны.
Если обратиться к недавним публикациям мировых и российских аналитиков (Р. Грабовски, О. Шиловицкий, Эл Дин, О. Зыков и др.), то по их мотивам можно сформулировать несколько "облачных" тезисов:
- Облака, безусловно, полезны для почты и обработки текстовых документов. Однако объем и сложность обработки 3D данных и графики не допускает возможность полноценной работы в САПР приложениях.
- Инженеры-проектировщики консервативны - к миграции в облако они не готовы (или просто в этом не нуждаются).
- Безопасность данных в публичных облаках вызывает большие сомнения.
- Привлекательно получить доступ к данным САПР с помощью мобильных устройств на базе Android и iOS.
- С помощью облаков информация о модели станет доступна, например, sales-менеджеру, работающему с потенциальным клиентом вне офиса.
- Облако уже может принести пользу, когда дело доходит до работы с облегченными данными для PLM.
Другой любопытной темой обсуждений является поддержка САПР на планшетах - хотя уже существует множество пользующихся спросом программ просмотра 3D данных, однако текущая производительность мобильных устройств не позволяет полноценно работать с серьезными моделями.
На кого ориентировано решение VGX
Хотя в перспективе NVIDIA собирается поставлять технологию VGX как в публичные, так и в частные облака, тем не менее представители компании признают, что пока главной целью являются корпоративные дата-центры (тем более, что свой интерес к такому применению VGX уже выразили крупнейшие автопроизводители, например, Jaguar Land Rover). На этих серверах будут находиться и соответствующие САПР и PLM приложения под управлением ОС Windows.
Предоставление облачного доступа ориентировано, прежде всего, на так называемых PLM-пользователей - сотрудников, работающих с моделями не на постоянной основе или ограниченным образом. Их число на предприятии (это сотрудники отделов продаж, маркетинга, производства и т.д.) в 8-10 раз больше числа "high-end" пользователей - инженеров-проектировщиков, использующих наиболее широкие возможности САПР и редактирующих "тяжелые" модели. Стоит отметить, что перенос вычислительных мощностей с рабочих станций в дата-центры во многих случаях полезен и с точки зрения удобства и организации бизнеса - это обеспечивает безопасность, защиту от сбоев оборудования, сокращение энергопотребления и предоставляет лучшую инфраструктуру.
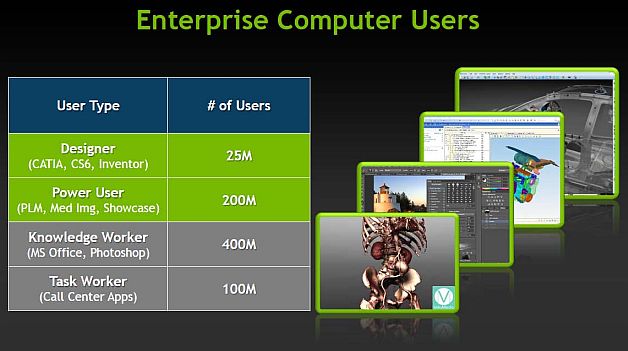
Соотношение групп различных пользователей на предприятиях в мире. (Источник: NVIDIA.)
Похожая ситуация возникает при подходе BYOD ("bring your own device"), когда сотрудники компании имеют возможность получить доступ к корпоративной сети и информации со своих собственных смартфонов, планшетов или ноутбуков, или тогда, когда результат работы необходимо продемонстрировать заказчику, находящемуся вне офиса. Во всех этих случаях технология VGX сможет обеспечить приемлемо высокую скорость работы и усилить безопасность, поскольку все данные остаются в дата-центре.
Но как быть с "high-end" инженерами-проектировщиками, которым необходима полноценная регулярная работа с тяжелыми САПР типа CATIA или NX и большими моделями? Ведь анонсированная плата VGX Board далеко не всегда подходит для их требований. Ответ прост - технология VGX еще будет существенно дорабатываться для различных целевых аудиторий. Так что нам определённо стоит ждать новых анонсов от NVIDIA - во-первых, это видеокарты Quadro с архитектурой Kepler и, во-вторых, основанные на них новые версии плат VGX, предназначенные для самых строгих пользователей.
Еще одним важным направлением работы компании, по-видимому, станет ориентация на публичные облака. Впрочем, здесь для взлёта необходимо не только обеспечить быстроту обработки данных, но и преодолеть консерватизм пользователей, что кажется гораздо более сложной задачей.

3D модель из облака на экране смартфона, планшета и ноутбука. (Источник: NVIDIA.)
В заключение хочется отметить еще одно любопытное следствие распространения VGX: если вскоре на iPad, iPhone, Android-смартфонах и планшетах можно будет увидеть 1536 ядер CUDA и легко запустить трехмерный САПР, то возникает резонный вопрос - а действительно ли нужны "нативные" САПР для этих устройств? Да и упреки в адрес компании Apple в том, что ее продукция не является инженерно-ориентированной, уже не выглядят аргументированными. Ведь даже если у iPad"ов и были проблемы, то теперь они уже решены силами инженеров NVIDIA.