
Настроить репликацию между облачной базой данных и базой на on-premise (безоблачном) SQL Server нельзя, потому что SQL Azure еене поддерживает. Как вариант, можно написать приложение с использованием Microsoft Sync Framework, которое будет отслеживать изменения на одном конце и применять их на другом и наоборот. Такое приложение под названием SQL Azure Data Sync было написано в виде Web-сервиса и размещено во всех облачных датацентрах. Оно умеет реплицировать данные между облачными БД на серверахSQL Azure, между SQL Azure и обычным SQL Server или через SQL Azure между обычными SQL Serverами, не связанными друг с другом никакими VPNами. Репликация происходит по схеме hub-spokes, т.е. изменения, произошедшие на одном луче звезды, поступают в центр, который распространяет их во все остальные концы, входящие в ту же группу синхронизации, что и тот, где случились изменения. В роли ступицы, т.е. дистрибутора, выступает БД SQL Azure.
Заходим на Windows Azure Management Portal - см. пост "SQL Azure. Создание сервера"\Рис.1. В данном случае нас интересует секция Data Sync слева внизу под Database:
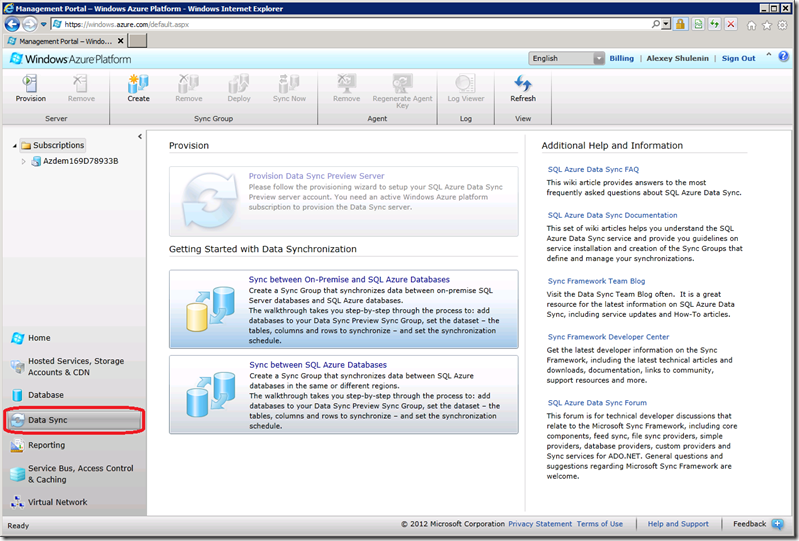
Рис.1
Согласно теме нынешнего поста выбираем в центральной части экрана прямоугольник Sync between On-Premise and SQL AzureDatabases. В данном примере мы рассмотрим репликацию, хотя в строгом смысле это не есть передача транзакций, а, скорее, отражение изменений, между базой данных на обычном SQL Server и в Облаке, т.е. сервер SQL Azure будет не только дистрибутором, но и издателем /подписчиком. Предлагается указать подписку (здесь уже имеется в виду не подписка в смысле репликации, а подписка на Azure), под которую будет заготовлен сервер синхронизации. На момент написания данной статьи в одной облачной подписке можно создавать не более одного сервера синхронизации.
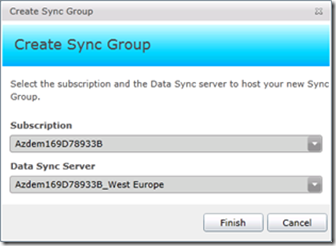
Рис.2
На нем создается группа синхронизации. Под группой синхронизации понимается, условно говоря, подписка, т.е. группа баз на издателе и подписчике, хотя мы рассмотрим двунаправленную репликацию, т.е. подписчик может быть, в свою очередь, издателем, между которыми будут синхронизироваться статьи, если опять же говорить в терминах репликации, т.е. вертикально-горизонтально порезанные таблицы. Открывается визард настройки синхронизации. В отличие от традиционного визарда, представляющего собой череду сменяющих друг друга экранов, здесь теперь все по-новому и заточено под Metro-style интерфейс. Экран темнеет, и на каждом шаге вспыхивают плитки в разных частях экрана, в которые нужно быстро тыкнуть. Я бы еще для развития реакции сделал, чтобы место вспыхивания i-го шага случайно менялось при повторном прохождении визарда. На планшетниках плитка должна биться током, если не сразу на нее кликнул. Сила тока зависит от сложности прохождения. Что-то я увлекся. На первом уровне задаем название группы синхронизации. Еще сразу горит кусок экрана с конфигурацией, хотя по-хорошему заполнять его предстоит на 4-м шаге. Наверное, бонус. Можно заполнить сейчас - без разницы. Под конфигурацией понимается период проведения сеансов связи на предмет синхронизации, а также reconciliation - за кем остается правда, если оба поменяли одну и ту же запись в одной и той же таблице.
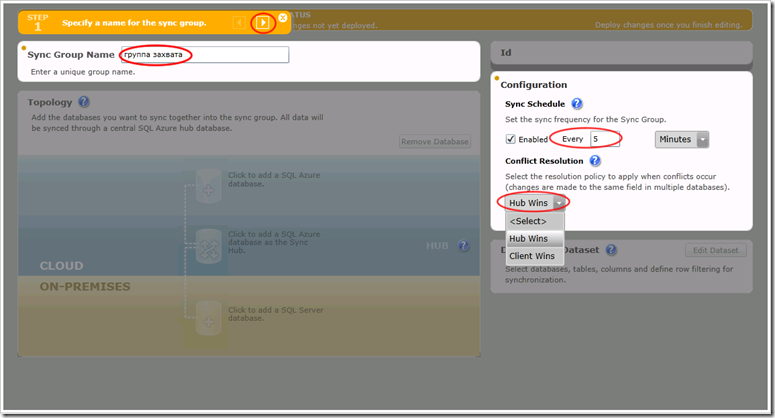
Рис.3
Первый уровень пройден. На втором предстоит задать базу данных на необлачном SQL Server, который будет участвовать в синхронизации. Каждая база данных в текущей версии SQL Azure Data Sync может входить не более, чем в 5 групп синхронизации. В пределах одной группы синхронизации можно создать не более 30 спиц (облачных и необлачных баз данных, обменивающихся между собою информацией), из них необлачных не более 5. Кликаем на обведенную овалом иконку:

Рис.4
Говорим, что это будет новый SQL Server, т.е. в конфигурируемой группе синхронизации он еще не отмечен, и мы предполагаем, что синхронизация будет идти в обоих направлениях: как от SQL Server в Облако, так и обратно:
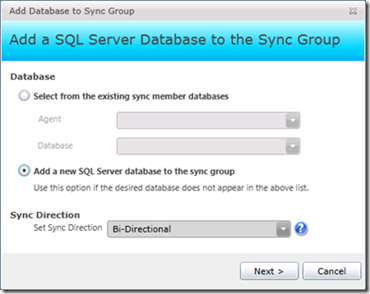
Рис.5
На необлачный (on premise - в помещении) SQL Server необходимо установить специального агента синхронизации с Облаком, либо воспользоваться уже установленным, но т.к. до этого агент не ставился, то устанавливаем:

Рис.6
Будет предложено его поставить из традиционных Microsoft Downloads
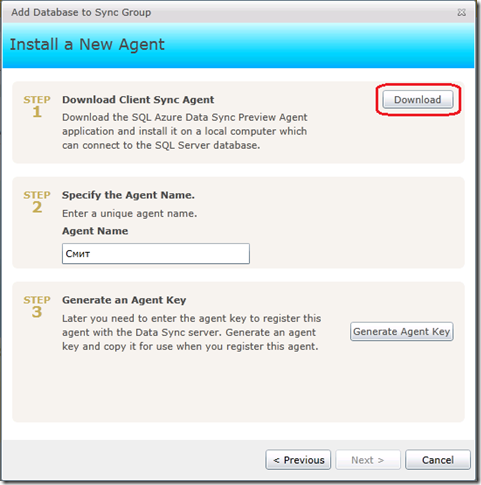
Рис.7
конкретно - с http://www.microsoft.com/en-us/download/details.aspx?id=27693. Я думаю, что никто не будет его скачивать, все будут сразу запускать, т.к. весит он немного - 7.2 МБ, а на машине, которую мы собираемся синхронизировать с Облаком, интернет должен, по определению, быть.
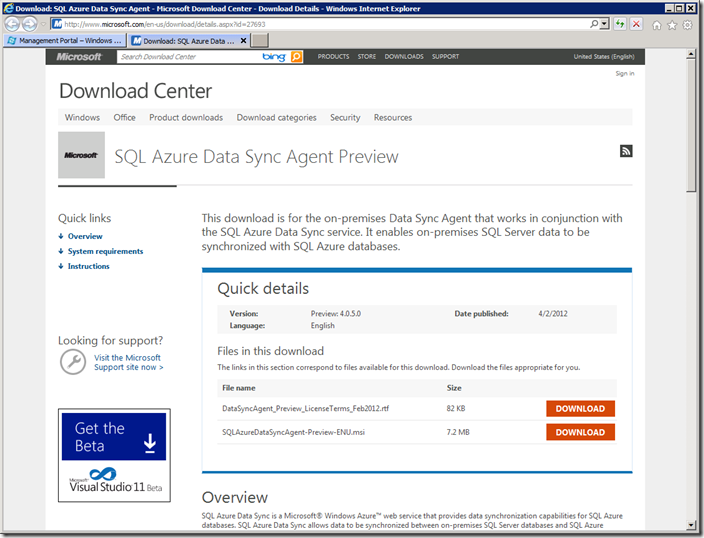
Рис.8
Установка проходит без особых эксцессов
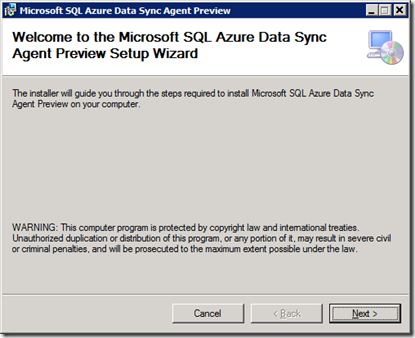
Рис.9
Здесь задается учетная запись, под которой будет работать сервис агента синхронизации (Рис.13). Она должна иметь права на выход вИнтернет и Log On as a Service (Administrative Tools -> Local Security Policy -> Local Policies -> User Rights Assignment). В разделе Data Security написано, что service log-in credentials supplied during the client agent install do not have to be admin credentials . По-видимому, имеется в виду локальный админ. Его она действительно не воспринимает. Доменный администратор проходит:

Рис.10
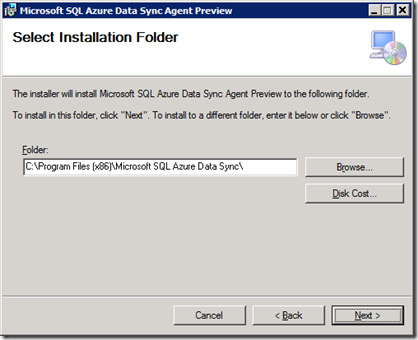
Рис.11
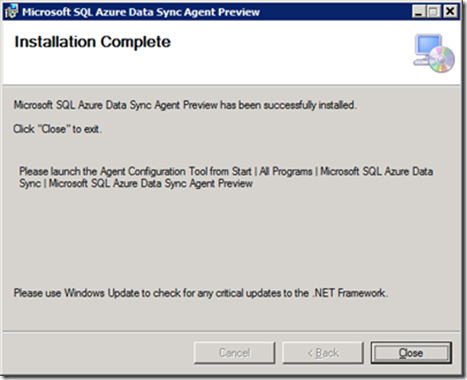
Рис.12
В ходе сетапа устанавливаются конфигурационный клиент Microsoft SQL Azure Data Sync Preview (C:\Program Files (x86)\Microsoft SQL Azure Data Sync\bin\SqlAzureDataSyncAgent.exe) и сервис агента синхронизации Microsoft SQL Azure Data Sync (C:\Program Files (x86)\Microsoft SQL Azure Data Sync\bin\LocalAgentHost.exe), стартуемый под учетной записью Рис.10:
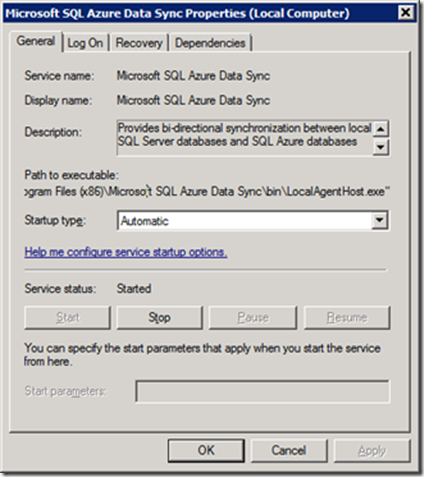
Рис.13
Возвращаемся к Рис.7. Даем агенту агентурную кличку и ключ, чтобы он смог зарегистрироваться на сервере Data Sync, заготовленном на Рис.2. После нажатия кнопки Generate Agent Key сгенерированный ключ появится внизу Рис.13, а рядом будет заботливая кнопочка Copy. Скопируем ключ, т.к. его предстоит предъявить на Рис.15
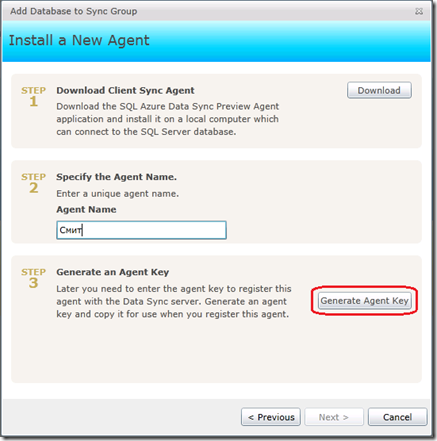
Рис.14
после чего запускаем клиента:
Рис.15
и регистриpуем его на сервере Data Sync (Рис.2) при помощи ключа, выданного на Рис.14:

Рис.16
В конфигурации агента должна быть прописана строка соединения с обычным SQL Server, базу которого мы начали определять для участия в группе синхронизации Рис.5. В нашем примере это будет Northwind1, созданная в предыдущем посте. В случае выбора Windows-аутентификации учетная запись сервиса агента синхронизации Microsoft SQL Azure Data Sync (Рис.10) должна иметь доступ к БД настольного SQL Server, которую предполагается синхронизовать в Облако.

Рис.17
Служба синхронизации обеспечивает шифрование (Encrypted Data) всех конфиденциальных хранящихся в ней данных, в том числе:
• учетные данные пользователя базы данных SQL Azure
• учетные данные пользователя базы данных SQL Server
• файл конфигурации клиентского агента Data Sync
• учетные данные самой службы Data Sync для system storage в Windows Azure.
Жмем кнопку Register слева вверху, чтобы дать понять агенту, какую базу мы собираемся синхронизировать. Покидаем клиентское приложение и возвращаемся к продолжению Рис.5. Кнопка Get Database List на Step 2 наполняет комбобокс Step 3 списком баз, зарегистрированных на агенте по имени Смит (мы дали ему такое имя на Рис.14). Из этого списка выбираем соединение Рис.17
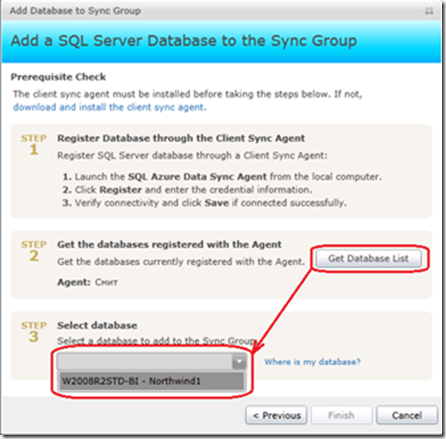
Рис.18
и выходим на следующий уровень. Здесь миссия - задать облачную БД, которая будет выступать в роли дистрибутора:

Рис.19
Предварительно на облачном SQL Server fxv4koqar4 я создал пустую базу по имени Northwind1_Azure. Прописываем строку соединения с ней в мастере синхронизации:
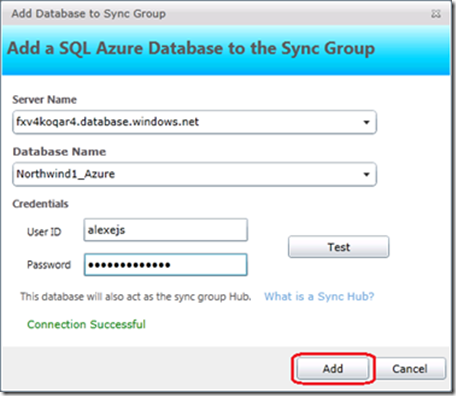
Рис.20
На 4-м уровне с нас спрашивается частота синхронизаций и правило разрешения конфликтов. Мы его прошли еще на Рис.3.
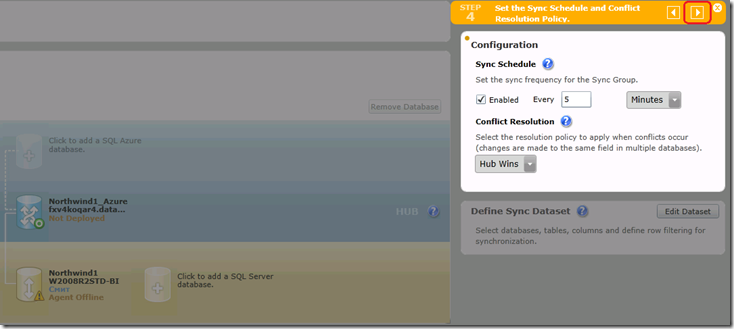
Рис.21
На 5-м уровне предстоит создать статьи репликации. Здесь это называется Sync Dataset:

Рис.22
У нас имеются две базы данных: Northwind1 на локальном SQL Server и пустая Northwind1_Azure в облачном. Для начала мы хотим наполнить Northwind1_Azure, т.е. Northwind1 выступает в качестве источника. Говорим это мастеру синхронизации в верхнем комбобоксе. По нажатию кнопки Get Latest Schema слева отображается список таблиц; при навигации от таблицы к таблице - справа список полей текущей таблицы. В одной группе cинхронизации может участвовать не более 100 таблиц, каждая из которых может иметь не более 1000 полей. Для того или иного поля можно отметить чекбокс Filter. Тогда внизу нарисуется заготовка под условие where по этому полю. Операторы ограничиваются >, <, = и их комбинациями. Например, like еще не домыслили.
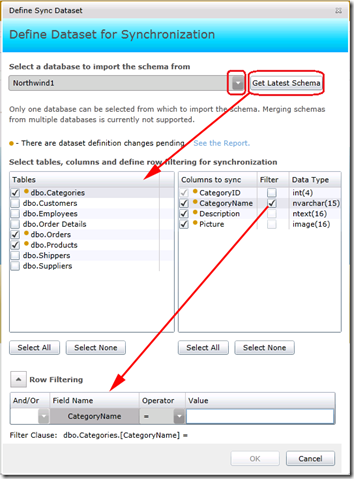
Рис.23
Кнопка ОК сейчас недоступна, потому что у фильтра пустое поле Value. Мы не будем использовать горизонтальное нарезание таблиц (как и вертикальное). Убираем галку фильтра и жмем ставшую доступной ОК.
На 6-м уровне остается нажать кнопку Deploy, чтобы загрузить на сервер Data Sync конфигурацию группы синхронизации
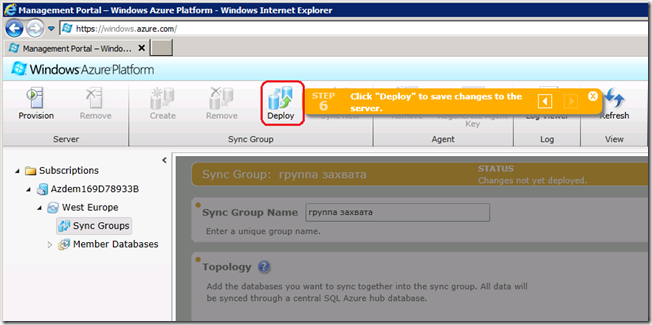
Рис.24
и готово. Экран радостно светлеет, Status: Provisioning в зеленой строке сменяется на Synchronizing и наконец Good:

Рис.25
Говорит, что синхронизация успешно произошла. Сейчас мы поглядим, какой это Сухов. Во-первых, на портале Windows Azure в секцииData Sync имеется просмотр журналов синхронизации - пункт меню Log Viewer, либо слева выбрать соответствующий пункт из участников синхронизации и справа кликнуть View Log. Три нижние строчки в журнале - это перенос в Облако 3-х выбранных на Рис.22 таблиц, но пока я это писал, прошло 5 заданных на Рис.20 минут, проснулся агент Смит, проверил, есть ли для него работа, и снова заснул:

Рис.26
Убеждаемся, что все 3 заказанные таблицы появились в облачной базе и наполнились данными:
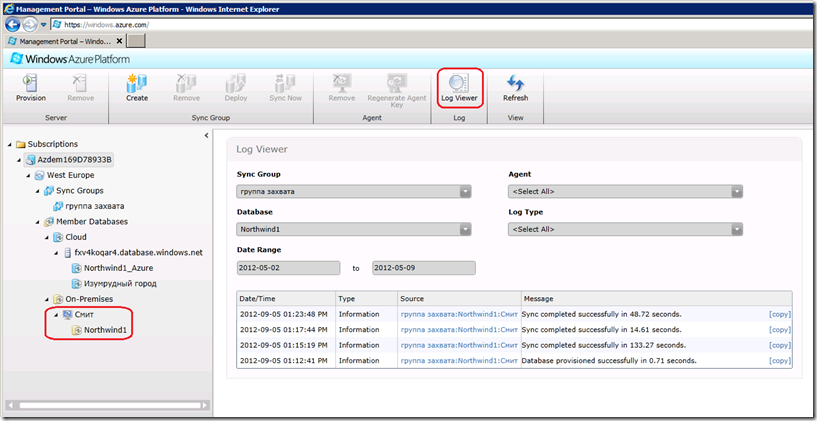
Рис.27
Мы уже знаем, что все соединения с SQL Azure в обязательном порядке шифруются. Синхронизация не является исключением. Во избежание перехвата данных в процессе синхронизации сервис SQL Azure Data Sync шифрует все соединения (Encrypted Connections) между компонентами, в том числе:
• соединение между службой и системной БД в SQL Azure
• соединение между службой и system storage в Windows Azure
• соединения между всеми компонентами облачного сервиса
• соединение между клиентским агентом и облачным сервисом
• соединение между порталом Windows Azure Platform и облачным сервисом.
Проверяем, что в обратную сторону синхронизация тоже работает. Поменяем в Облаке какие-нибудь данные:
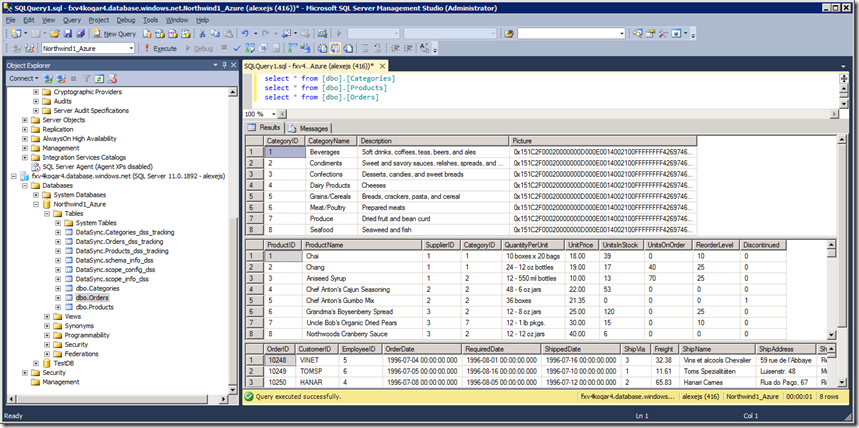
Рис.28
и не позже, чем через 5 мин. эти изменения отразятся в настольной базе Northwind1. Пока что можно обратить внимание, что структуры таблиц Northwind1 переехали в Облако вместе с ограничениями, поэтому delete from Categories where CategoryID = 6 не получится по причине The DELETE statement conflicted with the REFERENCE constraint "FK_Products_Categories". Однако SQL Azure Data Sync не копирует структуру исходной базы в назначение один в один. Cоздаются только отмеченные на Рис.23 таблицы, а в них только те поля, что были отмечены там же. Если по этим полям в источнике имелись индексы, они будут созданы в назначении, за исключением индексов по полям типа XML. Также не переносятся ограничения типа CHECK, триггеры, представления и хранимые процедуры - см. Data Sync FAQ, "Does Data Sync fully create and provision tables?": Because of these limitations we recommend that for production environments you provision the full fidelity schema yourself and not depend on the schema provisioned by Data Sync. The auto provisioning feature of Data Sync works well for trying out the service.
Если впоследствии схема какой-либо из участвующих в синхронизации таблиц, поменяется и эти изменения захочется тоже синхронизировать, единственный способ - пересоздать группу синхронизации (Рис.2, 3, ...) - см. Data Sync FAQ, "Q: I just changed my schema. How do I get the change into my sync group?"
Кроме отмеченных на Рис.23 таблиц, образовались служебные таблицы схемы DataSync в обеих базах. Вот, как выглядит таблицаDataSync.Categories_dss_tracking после внесения изменений Рис.27. Здесь приводятся не все колонки, но и без того что-то это до боли напоминает. Раскрываем таблицу dbo.Categories, смотрим ее триггеры. Правильно, так и есть: Categories_dss_delete_trigger, Categories_dss_insert_trigger, Categories_dss_update_trigger. Это действительно Sync Framework для версий, ранее 2008-го, потому чтоChange Tracking в SQL Azure не поддерживается. В связи с тем, что при создании синхронизации вносятся изменения в структуры баз, It is highly recommended that you test SQL Azure Data Sync on a non-production database to ensure that it does not have an adverse effect on your existing applications - Data Sync FAQ, "Q: Will SQL Azure Data Sync make changes to my database?"
|
Category ID |
update _scope _ local_id |
scope_ update _ peer_ timestamp |
local_update _peer _timestamp |
scope_ create_peer_ timestamp |
local_ create_peer _timestamp |
sync_ row_is_ tombstone |
last _change_ datetime |
| 1 | NULL | 4002 | 925 | 4002 | 9 | 0 | 09-05-12 09:33:58 |
| 2 | 1 | 4003 | 8 | 4002 | 8 | 0 | 09-05-12 09:15:15 |
| 3 | 1 | 4004 | 7 | 4002 | 7 | 0 | 09-05-12 09:15:15 |
| 4 | 1 | 4005 | 6 | 4002 | 6 | 0 | 09-05-12 09:15:15 |
| 5 | 1 | 4006 | 5 | 4002 | 5 | 0 | 09-05-12 09:15:15 |
| 6 | 1 | 4007 | 4 | 4002 | 4 | 0 | 09-05-12 09:15:15 |
| 7 | 1 | 4008 | 3 | 4002 | 3 | 0 | 09-05-12 09:15:15 |
| 8 | 1 | 4009 | 2 | 4002 | 2 | 0 | 09-05-12 09:15:15 |
| 9 | NULL | NULL | 926 | NULL | 926 | 0 | 09-05-12 09:33:58 |
Табл.1
Тем временем можно уже смотреть, что получилось в настольной БД Northwind1:
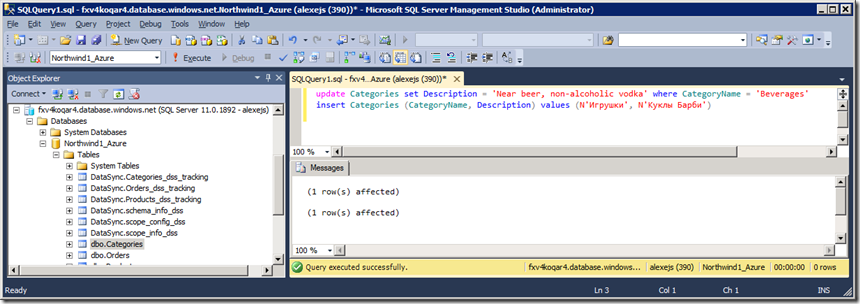
Рис.29
Мы видим, что сделанные изменения доставились в таблицу Northwind.dbo.Categories (записи №№1, 9). Удручает, правда, то, что вместо кириллицы нарисовались знаки вопроса. Домашнее задание: вернитесь на Рис.28 и повторите вставку, чтобы русские буквы все-таки отобразились нормально.
Ограничения текущей версии, такие, как количество издателей/подписчиков в группе синхронизации, количество таблиц, колонок и т.д., я старался проговаривать по ходу повествования. На всякий случай напомню, что все они перечислены в Data Sync FAQ. Существенным ограничением, про которое я до сих пор не упомянул, выступает отсутствие программных интерфейсов - The SQL Azure Data Sync Service has no publicly available API as of the current release - т.е. заскриптовать проделанное на вышеприведенных картинках в настоящий момент нельзя. При необходимости программного доступа пока рекомендуется использовать Sync Framework - по сути, написать свой собственный SQL Azure Data Sync.
Автор статьи: Алексей Шуленин.