
Часть 4: Особенности хранилищ данных и возможности интеграции
(Part 4: Data Warehousing and Integration Features)
Источник: сайт корпорации Oracle, раздел "Технологические статьи" (Technical Articles), 28 июля 2005,
Аруп Нанда, Oracle ACE, представляет свой список наиболее важных новых возможностей для администраторов баз данных.
Ранее на русском языке в журнале "Oracle Magazine/Русское Издание" опубликованы:
Новые возможности для более эффективного множественного управления материализованными представлениями, опция Query Rewrite (возможность перезаписи запросов), транспортабельные табличные пространства и табличные секции сделают ваше хранилище данных еще более мощным и менее ресурсоемким.
Содержание этого выпуска:
- *прослеживание изменения секции без журналов материализованного представления (MV Logs);
- * возможность перезаписи запроса с несколькими материализованными представлениями;
- *транспортабельное табличное пространство из резервной копии;
- *быстрое разбиение секции для секционированных индекс-организованных таблиц;
- *преобразование LONG в LOB посредством сетевого переопределения;
- *оперативная реорганизация одной секции;
- *удаление таблицы секция за секцией.
Прослеживание изменения секции: нет надобности в журналах материализованного представления
(Partition-Change Tracking: No Need for MV Logs)
Чтобы понять это усовершенствование, сначала нужно понять логику сокращения [числа] секций в течение процесса освежения материализованного представления (MV).
Предположим, что таблица ACCOUNTS секционирована по столбцу ACC_MGR_ID, по одной секции на каждое значение ACC_MGR_ID. На таблице ACCOUNTS было создано материализованное представление ACC_VIEW, которое также секционировано по ACC_MGR_ID, и также по одной секции на каждое значение ACC_MGR_ID, как показано в рисунке ниже:
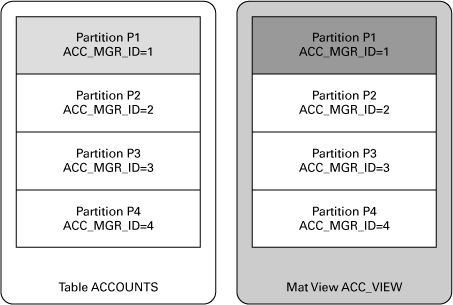
Теперь представим, что в таблице ACCOUNTS были модифицированы записи, но только в секции P1. Чтобы побыстрее обновить MV, нужно освежить только секцию P1, где расположены все данные соответствующего ACC_MGR_ID, а не всю таблицу целиком. Oracle восполняет эту задачу автоматически, прослеживая изменения в секции через механизм, называемый PCT (Partition Change Tracking - прослеживание изменений секции). Однако есть маленькое но: чтобы применить механизм PCT для быстрого обновления, нужно создать MV-журналы, которые пополняются, когда в таблице изменяются строки. Когда выдается команда на обновление, процесс освежения читает MV-журналы, чтобы идентифицировать эти изменения.
Необходимо сказать, это требование увеличивает полное время выполнения операции. Кроме того, дополнительная вставка потребляет CPU-циклы и снижает [эффективную] пропускную способность ввода/вывода.
К счастью, в Oracle Database 10g Release 2 PCT работает без использования MV-журналов. Давайте увидим это на практике. Сначала удостоверимся, что нет никаких MV-журналов на таблице ACCOUNTS.
SQL> select * 2 from dba_mview_logs 3 where master = 'ACCOUNTS'; no rows selected Теперь, обновим запись в таблице. update accounts set last_name = '...' where acc_mgr_id = 3;
Эта запись находится в секции P3.
Теперь вы готовы освежить MV. Но сначала запишем статистику сегментного уровня по всем сегментам таблицы ACCOUNTS. Эти статистические данные понадобятся позже, чтобы увидеть, какие сегменты были задействованы.
select SUBOBJECT_NAME, value from v$segment_statistics where owner = 'ARUP' and OBJECT_NAME = 'ACCOUNTS' and STATISTIC_NAME = 'logical reads' order by SUBOBJECT_NAME / SUBOBJECT_NAME VALUE --- ---------- P1 8320 P10 8624 P2 12112 P3 11856 P4 8800 P5 7904 P6 8256 P7 8016 P8 8272 P9 7840 PMAX 256 11 rows selected.
Освежаем материализованное представление ACC_VIEW, используя быстрое обновление.
execute dbms_mview.refresh('ACC_VIEW','F')
Параметр 'F' указывает, что применяется режим быстрого обновления. Но сработало ли обновление без MV-журналов на таблице?
После завершения освежения снова проверим статистику сегментов таблицы ACCOUNTS. Результаты показаны ниже:
SUBOBJECT_NAME VALUE --- ---------- P1 8320 P10 8624 P2 12112 P3 14656 P4 8800 P5 7904 P6 8256 P7 8016 P8 8272 P9 7840 PMAX 256
Статистика сегментов показывает сегменты, которые участвовали в операциях логического чтения. Эти статистические данные являются собирательными (кумулятивными), и вы можете увидеть изменение в значении вместо абсолютного значения. Если проанализировать приведенные выше значения, то можно видеть, что изменилось только значение для секции P3. Итак, только секция P3 была выбрана процессом обновления, а не таблица целиком, что подтверждает действительное задействование PCT без применения MV-журналов на таблице.
Способность к быстрому освежению материализованного представления, даже когда основные таблицы не имеют MV-журналов, - это мощная и полезная особенность, которая разрешает вам сделать быстрое обновление секционированных материализованных представлений без дополнительной расходов производительности. Эта возможность получает мой голос за самое полезное расширение хранилища данных в Oracle Database 10g Release 2.
Перезапись запроса на нескольких материализованных представлениях
(Query Rewrite with Multiple MVs)
Возможность Query Rewrite (перезапись запроса), введенная в Oracle8 i , мгновенно стала хитом у разработчиков хранилищ данных и АБД. По существу, это механизм перезаписи пользовательских запросов, в которых вместо таблиц применяются материализованные представления, чтобы использовать в своих интересах уже собранные в них промежуточные результаты. Для примера рассмотрим три таблицы в главной базе данных комплекса гостиниц.
SQL> DESC HOTELS Name Null? Type -------------- -------- ------------- HOTEL_ID NOT NULL NUMBER(10) CITY VARCHAR2(20) STATE CHAR(2) MANAGER_NAME VARCHAR2(20) RATE_CLASS CHAR(2) SQL> DESC RESERVATIONS Name Null? Type -------------- -------- ------------- RESV_ID NOT NULL NUMBER(10) HOTEL_ID NUMBER(10) CUST_NAME VARCHAR2(20) START_DATE DATE END_DATE DATE RATE NUMBER(10) SQL> DESC TRANS Name Null? Type -------------- -------- ------------- TRANS_ID NOT NULL NUMBER(10) RESV_ID NOT NULL NUMBER(10) TRANS_DATE DATE ACTUAL_RATE NUMBER(10)
Таблица HOTELS содержит информацию о гостиницах. Когда клиент резервирует номер, создается запись в таблице RESERVATIONS, который содержит определенную квоту мест. Когда клиент освобождает гостиничный номер, деньги транзакции фиксируются в другой таблице TRANS.
Однако, еще до выезда клиента гостиница на основании на готовности комнат, оперативной обстановки, своей заинтересованности и т.д. может предложить ему номер другого разряда и сделать это. Следовательно, заключительный разряд номера может отличаться от того, который был указан при резервировании, и может даже изменяться со дня на день. Чтобы правильно сделать запись этих колебаний, таблица TRANS содержит строку, где находится информация о разрядах в течение каждого дня пребывания.
Чтобы улучшить время ответа, можно построить материализованные представления, основанные на различных запросах, задаваемых пользователями, например:
create materialized view mv_hotel_resv refresh complete enable query rewrite as select city, resv_id, cust_name from hotels h, reservations r where r.hotel_id = h.hotel_id; и/или create materialized view mv_actual_sales refresh complete enable query rewrite as select resv_id, sum(actual_rate) from trans group by resv_id; Тогда запрос select city, cust_name from hotels h, reservations r where r.hotel_id = h.hotel_id; будет перезаписан как select city, cust_name from mv_hotel_resv;
если установлены некоторые параметры, типа query_rewrite_enabled = true. Можно удостовериться, что используется MV, разрешив автотрассировку и выполнив запрос.
SQL> set autot traceonly explain SQL> select city, cust_name 2> from hotels h, reservations r 3> where r.hotel_id = h.hotel_id; Execution Plan ---- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=3 Card=80 Bytes=2480) 1 0 MAT_VIEW ACCESS (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW) (Cost=3 Card=80 Bytes=2480)
Обратите внимание, что запрос выбрал от материализованного представления столбец MV_HOTEL_RESV вместо таблиц HOTELS и RESERVATIONS. Это именно то, что мы хотели.
Точно так же, когда задается запрос, суммирующий фактические расценки для каждого дня бронирования, будет использоваться материализованное представление MV_ACTUAL_SALES, а не таблица TRANS.
Давайте зададим запрос другого типа. Если надо узнать фактические расценки по разным городам, вы спросите:
select city, sum(actual_rate) from hotels h, reservations r, trans t where t.resv_id = r.resv_id and r.hotel_id = h.hotel_id group by city;
Обратите внимание на структуру запроса: из MV_ACTUAL_SALES можно получить RESV_ID и полные расценки по бронированию. Из MV_HOTEL_RESV можно получить CITY и RESV_ID.
Можно ли соединить (join) эти два материализованных представления? Конечно, да, но до Oracle Database 10g Release 2 механизм Query Rewrite автоматически перезаписывал пользовательский запрос, используя только одно из этих MV, но не оба.
Ниже приводится план выполнения [запроса] в базе данных Oracle9i. Как можно видеть, задействованы только MV_HOTEL_RESV и полный просмотр таблицы TRANS.
Execution Plan
----
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=6 Bytes=120)
1 0 SORT (GROUP BY) (Cost=8 Card=6 Bytes=120)
2 1 HASH JOIN (Cost=7 Card=516 Bytes=10320)
3 2 MAT_VIEW REWRITE ACCESS (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=1040)
4 2 TABLE ACCESS (FULL) OF 'TRANS' (TABLE)
(Cost=3 Card=516 Bytes=3612)
Этот подход вырабатывает лишь субоптимальные планы выполнения, даже если есть подходящее материализованное представление. Единственное решение состоит в создании другого MV, соединяющего все три таблицы. Однако такой подход ведет к резкому нарастанию количества материализованных представлений, что значительно увеличивает время, требуемое для их освежения.
В Oracle Database 10g Release 2 эта проблема исчезает. Теперь показанный выше запрос будет перезаписан с использованием обоих MV, как показано в плане выполнения.
Execution Plan
----
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=6 Bytes=120)
1 0 SORT (GROUP BY) (Cost=8 Card=6 Bytes=120)
2 1 HASH JOIN (Cost=7 Card=80 Bytes=1600)
3 2 MAT_VIEW REWRITE ACCESS (FULL) OF 'MV_ACTUAL_SALES' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=560)
4 2 MAT_VIEW REWRITE ACCESS (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=1040)
Обратите внимание, что используются только MV, а не какие-либо другие основные таблицы.
Это расширение дает существенные преимущества в средах хранилищ данных, потому что не нужно создать и обновлять материализованные представления для каждого возможного запроса. Вместо этого, можно создать несколько стратегических MV без избыточно большого числа соединений (joins) и агрегирований (aggregations), и Oracle будет использовать их все, чтобы перезаписать запросы.
Транспортабельное Табличное пространство из резервной копии
(Transportable Tablespace from Backup)
Транспортабельные табличные пространства, введенные в Oracle8 i , обеспечивают весьма существенную возможность быстрой передачи данных между базами данных. Используя этот механизм, можно экспортировать только метаданные табличного пространства, транспортировать файл данных и экспортный дамп-файл на хост-машину целевой базы данных и импортировать метаданные, чтобы "включить" табличное пространство в целевую базу данных. И данные этого табличного пространства немедленно доступны в целевой базе данных. Этот подход решает то, что было тогда одним из самых сложных вопросов в хранилищах данных: быстрое и эффективное перемещение данных между базами данных.
Однако в базе данных OLTP почти никогда невозможно таким образом транспортировать табличные пространства. Если база данных OLTP служит источником данных для хранилища данных, то вы никогда не сможете использовать транспортабельное табличное пространство, чтобы загрузить хранилище.
В Oracle Database 10 g Release 2 моно транспортировать табличное пространство и включить его из другого источника: из вашей резервной копии. Например, если надо транспортировать табличное пространство ACCDATA, вы можете выдать команду RMAN
RMAN> transport tablespace accdata 2> TABLESPACE DESTINATION = '/home/oracle' 3> auxiliary destination = '/home/oracle';
которая создаст вспомогательный экземпляр в расположении /home/oracle и восстановит там файлы из резервной копии. Имя вспомогательного экземпляра образуется произвольно. После создания этого экземпляра процесс в этой директории создает объект каталога (directory object) и восстанавливает файлы табличного пространства ACCDATA (того, которое мы транспортируем) - все совершенно самостоятельно без каких-либо команд с вашей стороны!
Директория /home/oracle будет содержать все файлы данных табличного пространства ACCDATA, дамп-файл с метаданными табличного пространства и самый важный скрипт, называемый impscrpt.sql. Этот скрипт содержит все необходимые команды, чтобы включить это табличное пространство в целевое табличное пространство. Табличное пространство не транспортируется командой impdp, а скорее через запрос к пакету dbms_streams_tablespace_adm.attach_tablespaces. Все необходимые команды могут быть найдены в скрипте.
Но что будет, если что-то идет не так, как надо? В этом случае проведем простую диагностику. Во-первых, вспомогательный экземпляр создает аварийный журнал (alert log file) в директории $ORACLE_HOME/rdbms/log, так что можно проанализировать этот журнал на потенциальные проблемы. Во-вторых, при формулировании RMAN-команды можно переадресовать команды и вывод в журнал, используя соответствующую команду RMAN
rman target=/ log=tts.log
что поместит весь вывод в файл tts.log. Итогда можно проанализировать этот файл на предмет выяснения точной причины отказа.
Наконец, файлы восстановлены в директории TSPITR_<SourceSID>_<AuxSID> в/home/oracle. Например, если SID основной базы данных - ACCT, а SID вспомогательного экземпляра, созданного RMAN, - KYED, то имя директории - TSPITR_ACCT_KYED. Директория в свою очередь имеет две других поддиректории: datafile (для файлов данных) и onlinelog (для redo-журналов). Прежде чем будет закончено создание нового табличного пространства, можно проанализировать директорию, чтобы увидеть, какие файлы восстановлены. (Эти файлы удаляются в конце процесса.)
АБД в течение долгого времени ждали возможности создания транспортабельного табличного пространства из резервной копии RMAN. Но имейте в виду, что вы подключаете транспортируемое табличное пространство из резервной копии, а не оперативное табличное пространство. Поэтому оно не будет сиюминутным.
Быстрое разбиение секции для секционированных индекс-организованных таблиц
(Quick Partition Split for Partitioned, Index-Organized Tables)
Рассмотрим такую ситуацию. Предположим, вы имеете секционированную таблицу. Наступил конец месяца, а вы забыли определить секцию для следующего месяца. Каковы теперь ваши действия?
Ну, конечно, у вас есть единственная возможность - разбить секцию maxvalue на две части: секцию для нового месяца и новую секцию maxvalue. Однако есть небольшая проблема, когда этот подход применяется для секционированных индекс-организованных таблиц. В этом случае сначала создается физическая секция и туда перемещаются строки из секции maxvalue, что расходует циклы CPU, также как и операции ввода/вывода.
В Oracle Database 10g Release 2 этот процесс значительно упрощен. Как показано на рисунке ниже, вы, допустим, определили секцию вплоть до мая, а затем была определена секция PMAX как неограниченная (catch-all) секция. Поскольку на июнь нет никакой заранее определенной секции, июньские данные находятся в секции PMAX. Серо-светлый прямоугольник показывает данные, попавшие в этот сегмент. Поскольку заполнена только часть секции PMAX, только эта часть затенена.
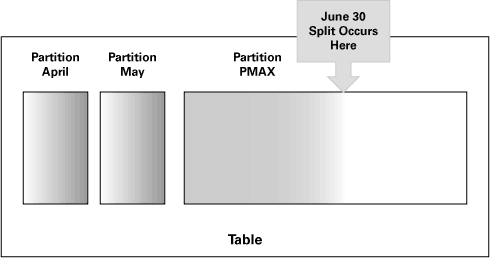
Теперь разбейте секцию PMAX на до 30 июня, чтобы создать июньскую секцию, и на новую секцию PMAX. Поскольку все данные в текущей PMAX войдут в новую июньскую секцию, Oracle Database 10g Release 2 просто создаст новую maxvalue секцию и сделает существующую секцию только что созданной месячной секцией. Это не сопровождается никаким движением данных (и, следовательно, отсутствием "пустого" ввода/вывода и ненужных циклов CPU). И что лучше всего - не изменяются ROWID.
Преобразование LONG в LOB посредством сетевого переопределения
(LONG to LOB Conversion via Online Redef)
Если база данных вашего хранилища данных существует уже продолжительное время и вы [постоянно и много] работали с большими текстовыми данными, то, вероятно, в ней имеется много столбцов с типом данных LONG. Само собой разумеется, что тип данных LONG бесполезен в большинстве случаев для манипуляции с данными, скажем, для типа посредством функции SUBSTR. Вы совершенно определенно захотите преобразовать их к LOB-столбцам.
Это можно сделать оперативно (online), используя пакет DBMS_REDEFINITION. Однако до Oracle Database 10g Release 2 было большое ограничение.
Преобразование LONG-столбцов в LOB происходило с большой деградацией производительности. Вам же желательно выполнить этот процесс с возможно высокой скоростью. Если таблица секционирована, процесс сделан параллельно поперек секции. Однако, если таблица несекционирована, то процесс становится последовательным и может занять много времени.
К счастью, в Oracle Database 10g Release 2 оперативное (online) преобразование из LONG в LOB может производиться параллельно пакетом DBMS_REDEFINITION, даже если таблица несекционирована. Давайте на примере посмотрим, как это работает. Возьмем таблицу, содержащую почтовые сообщения, посланные клиентам. Поскольку тело сообщения, сохраняемого в столбце MESG_TEXT, в общем случае является длинным текстом, столбец был определен как LONG.
SQL> desc acc_mesg Name Null? Type -------------- -------- --------- ACC_NO NOT NULL NUMBER MESG_DT NOT NULL DATE MESG_TEXT LONG
Вы хотите преобразовать этот столбец в CLOB. Сначала создайте пустую временную таблицу с идентичной структурой, кроме последнего столбца, который надо определить как CLOB.
create table ACC_MESG_INT ( acc_no number, mesg_dt date, mesg_text clob ); Теперь запустите процесс переопределения. 1 begin 2 dbms_redefinition.start_redef_table ( 3 UNAME => 'ARUP', 4 ORIG_TABLE => 'ACC_MESG', 5 INT_TABLE => 'ACC_MESG_INT', 6 COL_MAPPING => 'acc_no acc_no, mesg_dt mesg_dt, to_lob(MESG_TEXT) MESG_TEXT' 7 ); 8* end;
Обратите внимание на строку 6, где представлены столбцы. Первые два столбца остались теми же самыми, но третий столбец MESG_TEXT представлен так, чтобы он был заполнен содержимым столбца MESG_TEXT исходной таблицы с применением функции TO_LOB.
Если переопределяемая таблица большая, то надо периодически синхронизировать данные между исходной и целевой таблицами. Этот подход делает финальную синхронизацию быстрее.
begin
dbms_redefinition.sync_interim_table(
uname => 'ARUP',
orig_table => 'ACC_MESG',
int_table => 'ACC_MESG_INT'
);
end;
/
Вероятно, вышеупомянутую команду придется выполнять несколько раз в зависимости от размера таблицы. Наконец, завершите процесс переопределения следующим:
begin
dbms_redefinition.finish_redef_table (
UNAME => 'ARUP',
ORIG_TABLE => 'ACC_MESG',
INT_TABLE => 'ACC_MESG_INT'
);
end;
/
Таблица ACC_MESG изменилась:
SQL> desc acc_mesg
Name Null? Type
-------------- -------- ---------
ACC_NO NOT NULL NUMBER
MESG_DT NOT NULL DATE
MESG_TEXT
Обратите внимание, что столбец MESG_TEXT теперь имеет тип данных CLOB, а не LONG.
Эта возможность очень полезна для преобразования неправильно определенных или унаследованных оставшихся структур данных в более управляемые типы данных.
Оперативная реорганизация одной секции
(Online Reorg of a Single Partition)
Предположим, что имеется таблица TRANS, которая содержит историю сделок (транзакций). Эта таблица секционирована по TRANS_DATE поквартально по секции на каждый квартал. В нормальном течении бизнеса самая последняя секция модифицируется часто. После того, как квартал кончается, в этой секции не может быть больше деятельности, и она может быть перемещена в другое место. Однако это перемещение потребует блокировку на таблице, препятствуя общему доступу к секции. Как же переместить секцию без влияния на ее готовность?
В Oracle Database 10g Release 2 можно использовать оперативное переопределение одной секции. Вы можете выполнить эту задачу, также как применили бы пакет DBMS_REDEFINITION для таблицы в целом, но основной механизм здесь отличен. Принимая во внимание, что обычные таблицы переопределяются, создавая материализованное представление на исходной таблице, одна секция переопределяется посредством метода подмены секции.
Давайте посмотрим, как это работает. Возьмем структуру таблицы TRANS:
SQL> desc trans
Name Null? Type
------ -------- -------------------------
TRANS_ID NUMBER
TRANS_DATE DATE
TXN_TYPE VARCHAR2(1)
ACC_NO NUMBER
TX_AMT NUMBER(12,2)
STATUS
Таблица была секционирована следующим образом:
partition by range (trans_date)
(
partition y03q1 values less than (to_date('04/01/2003','mm/dd/yyyy')),
partition y03q2 values less than (to_date('07/01/2003','mm/dd/yyyy')),
partition y03q3 values less than (to_date('10/01/2003','mm/dd/yyyy')),
partition y03q4 values less than (to_date('01/01/2004','mm/dd/yyyy')),
partition y04q1 values less than (to_date('04/01/2004','mm/dd/yyyy')),
partition y04q2 values less than (to_date('07/01/2004','mm/dd/yyyy')),
partition y04q3 values less than (to_date('10/01/2004','mm/dd/yyyy')),
partition y04q4 values less than (to_date('01/01/2005','mm/dd/yyyy')),
partition y05q1 values less than (to_date('04/01/2005','mm/dd/yyyy')),
partition y05q2 values less than (to_date('07/01/2005','mm/dd/yyyy'))
)
В некоторый момент времени вы решаете переместить секцию Y03Q2 в другое табличное пространство (TRANSY03Q2), которое может быть на диске другого типа, немного помедленнее и дешевле. Чтобы сделать это, сначала удостоверьтесь, что таблицу можно переопределить оперативно:
begin
dbms_redefinition.can_redef_table(
uname => 'ARUP',
tname => 'TRANS',
options_flag => dbms_redefinition.cons_use_rowid,
part_name => 'Y03Q2');
end;
/
Здесь нет никакого вывода, вы имеете только подтверждение. Затем создайте временную таблицу, чтобы разместить данные нужной секции:
create table trans_temp
(
trans_id number,
trans_date date,
txn_type varchar2(1),
acc_no number,
tx_amt number(12,2),
status varchar2(1)
)
tablespace transy03q2
/
Обратите внимание, что хотя таблица TRANS секционирована по диапазону, вы определяете [временную] таблицу как несекционированную. Она создана в желательном табличном пространстве TRANSY03Q2. Если бы таблица TRANS имела какие-либо локальные индексы, надо создать те же индексы (как несекционированные, естественно) для таблицы TRANS_TEMP.
Теперь можно запускать процесс переопределения:
begin
dbms_redefinition.start_redef_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
col_mapping => NULL,
options_flag => dbms_redefinition.cons_use_rowid,
part_name => 'Y03Q2');
end;
/
В этом запросе обратите внимание на несколько позиций. Во-первых, параметр col_mapping установлен в NULL; при переопределении одной секции этот параметр бессмысленен. Во-вторых, новый параметр part_name определяет секцию, которая будет переопределена. В-третьих, обратите внимание на отсутствие параметра COPY_TABLE_DEPENDENTS, который является также бессмысленным, потому что сама таблица не изменяется никоим способом; перемещается только секция.
Если таблица большая, то операция может занять много времени; поэтому синхронизируйте ее на полпути.
begin
dbms_redefinition.sync_interim_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
part_name => 'Y03Q2');
end;
/
Наконец, завершите процесс следующим образом:
begin
dbms_redefinition.finish_redef_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
part_name => 'Y03Q2');
end;
С этого момента секция Y03Q2 находится в табличном пространстве TRANSY03Q2. Если на таблице имелись какие-либо глобальные индексы, они получают отметку UNUSABLE (непригодный) и должны быть перестроены.
Переопределение одной секции полезно для того, чтобы переместить секцию между табличными пространствами, что является обычной задачей жизненного цикла управленческой информации. Однако, есть несколько ограничений. Например, вы не можете изменить методы секционирования (скажем, с секционирования по диапазону на хэш-секционирование) или изменить структуру таблицы в течение процесса переопределения.
Покусочное удаление таблицы
(Drop a Table in Chunks)
Замечали ли вы когда-нибудь, сколько времени занимает удаление за секционированной таблицы? Дело в том, что каждая секция представляет собой сегмент, который должен быть удален. Когда Вы удаляете секционированную таблицу в Oracle Database 10g Release 2, секции удаляются одна за другой. Поскольку каждая секция удаляется индивидуально, требуются меньше ресурсов, чем когда таблица удаляется целиком.
Чтобы увидеть эту новую возможность, надо выставить сессионную трассировку на событие 10046.
alter session set events '10046 trace name context forever, level 12';
Затем удаляем таблицу. Если проанализировать трассовый файл, видно, что секционированная таблица удаляется следующим образом:
delete from tabpart$ where bo# = :1 delete from partobj$ where obj#=:1 delete from partcol$ where obj#=:1 delete from subpartcol$ where obj#=:1
Обратите внимание, что секции удаляются последовательно. Этот подход минимизирует использование ресурсов в течение удаления и улучшает производительность.
В части 5 этой серии я расскажу об особенностях готовности и резервирования, включая механизм Oracle Secure Backup.