
Как я уже говорил, наша компания много работает с задачами real-time обработки данных. Решая различные задачи, мы сталкивались с довольно любопытными и интересными решениями, о которых порой на хабре никто попросту не писал. Вот об одной такой интересной системе мы сегодня вам и расскажем. Сделала ее компания Microsoft, называется она StreamInsight и представляет из себя реализацию так называемого паттерна Complex Event Processing. О том, что это и зачем нужно, мы подробно расскажем внутри.

Вступление
Давным давно, году эдак в 1989-ом, когда трава была зеленее, а в IT все было несколько проще, люди только начинали задумываться о том, что неплохо бы базам данных не только выполнять запросы на запись и чтение, но и как-то сложно реагировать на поступающие данные. Началось все с так называемых Active database systems, которые могли испольнять заданные наборы интрукций при выполнении некоторых заранее определенных условий. Т.е. фактически это был запуск встроенных процедур по внешнему триггеру. В 90-ых появились Data Stream Management Systems, развившие эту идею. Они уже умели работать с непрерывными потоками поступающих данных. Это уже могли быть не редкие запросы, а честный поток real-time данных. Примерно в это же время люди подумали, что подчас данные, приходящие в базу, являются не событиями, а скорее внешними проявлениями этих событий: показаниями датчиков, их регистрирующих, нотификациями и уведомлениями. Такие системы стали называть Complex Event Processing.
Анализируя приходящие данные, такие системы могли как детектировать события (определяя факт их наступления, исходя из внешних данных и заложенной внутренней логики), так и расчитывать аналитические значения (например, считая среднее число происходящих событий за определенный период времени). Таким образом, использование этих систем подразумевало, что их внутренняя логика должна знать о том, какие "реальные" события бывают снаружи, и анализировать поступающий данные с "прицелом" именно на них.
StreamInsight
Проект StreamInsight, зародившийся в недрах Microsoft Research, изначально представлял из себя реализацию именно этого паттерна. С одной стороны, сущетвует целый класс задач, оперериующих с потоками данных, которые требуют иного (по сравнению с реляционными базами данных) подхода к решению. С другой стороны, за последнее время цены на устройства хранения данных упали на порядки, и компании сохраняют огромное кол-во данных о всевозможных аспектах работы систем. Причем, если выражаться бизнес-языком, ценность этих данных подчас стремительно падает во времени: если вы не успели среагировать на событие, вы упускаете свою выгоду.
StreamInsight - платформа для построения приложений, работающих с потоковыми данными. Большая часть обработки происходит в RAM, что позволяет добиться высокой пропускной способдности и низкой латентности. Сердцем этой платформы является движок, в которой крутятся т.н. Standing Queues, написанные на декларативном LINQ. Любой поступающий event сразу попадает на обработку в эти queues.
Система позволяет вам выполнять все, что должен делать "правильный" CEP и даже больше.
Например:
- Считать всевозможные интегральные значения
- Модифицировать и фильтровать поток данных, удалять дубликаты событий
- Обнаруживать сложныие паттерны событий
- Отслеживать "отсутствие" внешнего события
- С последних версий можно реализовать publish/subscribe рассылку
Видно, что возможности и применения этой системы шире, чем академического CEP. При этом список коммерческих применений тоже достаточно велик: веб-аналитика, логистика и операционный анализ, агоритмическая торговля, выявление случаев отмывания денег, мошенничества с платежными картами, мониторинг бизнес-активности и безопасности.
Более полный список сценираев использования можно посмотреть здесь
Вот, скажем, интересный юзкейс в котором SI майнит закономерности используя данные сохраненных логов, а потом обнаруживает эти паттерны в поступающем в реальном времени потоке данных:
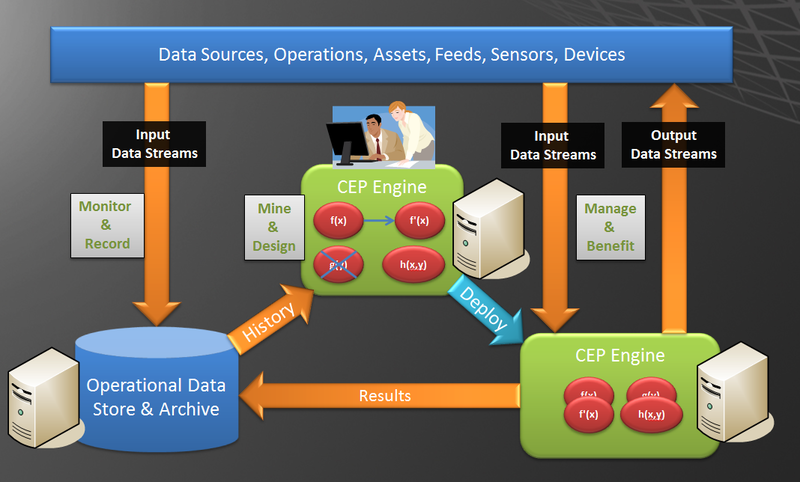
Архитектурные подрбности
Вот еще одна красивая картинка с MSDN, описывающая внутрее устройство SI:
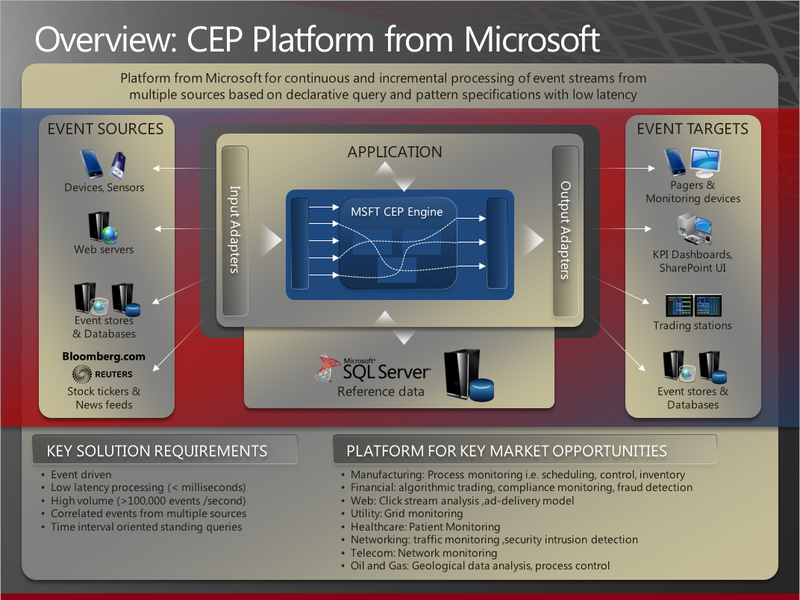
Как уже было сказано, основой движка являются Standing Queues, постоянно крутящиеся внутри движка. Еще одной базовой составляющей являются адаптеры: входные и выходные. Именно они позволяют связывать SI с окружающим миром и использовать всевозможные источники данных. Несколько самых востребованных адаптеров поставляются вместе с платформой, остальные придется писать самим на C#.
Про то, как работают Queues внутри можно со всем подробностями почитать в следующем документе: Автостопом по ГалактикеСтримИнсайту. Я постараюсь описать общую картину, необходимую для понимания.
Во-первых, все события (даже атомарные) внутри движка StreamInsight имеют определенную длительность, event data и payload (содержательную нагрузку). И большинство операндов, работающих с этими событиями, рассматривают так называемые Event Windows - временные окна, внутри которых происходят операции с данными.
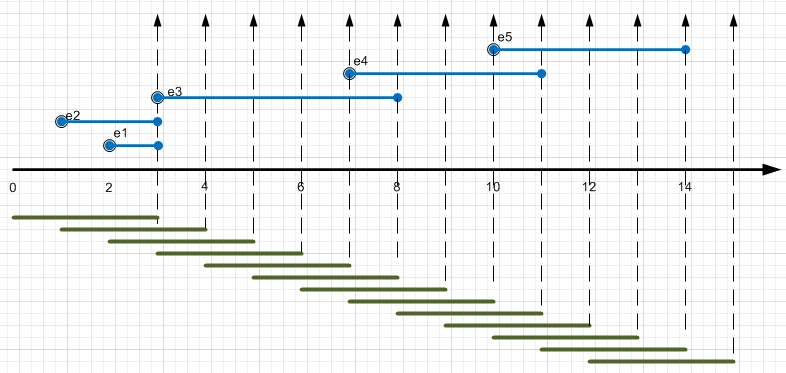
На этой платформе (используя LINQ) можно делать следующее:
- Выборки событий (filter)
- Вычисления на payload (project)
- Корреляция потоков (join)
- Группировка и разбиение потоков (group and apply)
- Аггрегацию (sum, count, ...) внутри временных окон
- Ранкирование (topK) внутри временных окон
Немаловажным моментом является то, что выход с одной Queue можно направить в другую Queue, что позволяет более гибко управлять обработкой данных (например реализовать publish/subscribe)
Развертывание и стоимость
При всем при этом StreamInsight - это не большая и громоздкая система, требующая развитой инфраструктуры. Ее можно использовать прямо в вашем приложении, встроив в виде dll. В таком случае ограничением на производительность будет только объем выделенной оперативной памяти. Также вы можете запустить движок StreamInsight отдельно, в stand-alone режиме. Таким образом вы можете делать системы, в которых продукт применяется в разных местах: около источников информации для фильтрации, и в центре обработки при извлечении нужных данных из потоков.
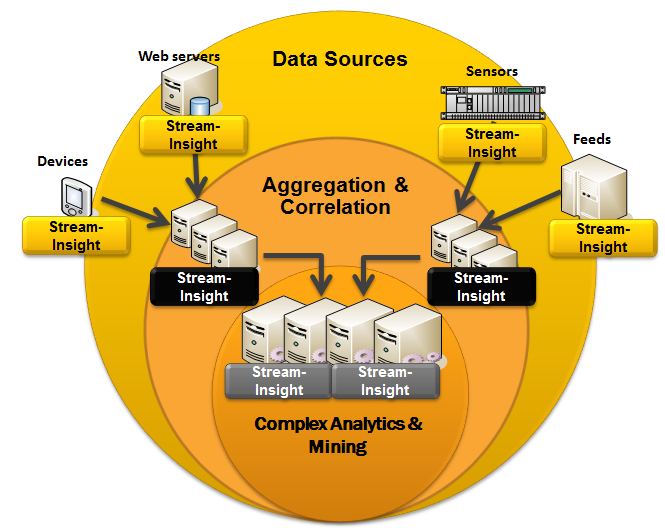
А вот с лицезированием и стоимостью не все так хорошо. Продается StreamInsight только в составе MS SQL сервера, что вызывает некоторые вопросы. Это при том, что SI никак не зависит от Database Engine и связь между этими продуктами является довольно условной. SI можно скачать отдельно от MS SQL Server, но ключ активации от основого продукта все равно понадобится. Есть 2 редакции: Standard и Premium. Подробнее об этом можно почитать здесь. Налицо откровенная проблема маркетологов: ребята из технического отдела придумали отличную технологию, а как ее хорошо продать - так и не смогли придумать. В итоге для того, чтобы реализовать картинку выше вам нужно будет купить изрядное кол-во лицензий MS SQL. И еще учтите, чтобы если лицензия будет ниже Enterprise, то вам искуственно ограничат производительность движка StreamInsight. Остается только надеяться, что через какое-то время ситуация поменяется и появиться возможность использовать эту технологию за пропорциональные деньги.
Austin - StreamInsight in the Cloud
Ну и конечно, для некоторых сценариев существует потребность использовать подобную аналитку в режиме SaaS. Майкрософт постаралась сделать соответсвующий сервис в своем Azure. Правда, продукт до сих пор находится в закрытой бете, и большая часть сведеней закрыта NDA. Так что здесь я расскажу только то, что успел узнать из открытых источников (курс PluralSight и проч.)
Во-первых, есть надежда, что в этой ипостаси StreamInsight может будет нормально покупать за разумные деньги: все же полной БД эта штука за собой не тащит.
Во-вторых, Austin сам заботится о маштабировании в части обработки поступающих данных: вам не нужно думать здесь о горизонтальном масштабировании. Вся остальная структура остается прежней: входные адаптеры, standing queries, выходные адаптеры.
В-третьих, основным сценарием является следующий: есть туча данных, мы их crunch-им, вытягиваем нужные знания и складываем в персистентное хранилище. Таким образом входным адаптером служит REST endpoint c маштабирующим load balancer-ом за ним, а выходные адаптеры умеют складывать результаты обработки сразу в Azure Storage или Azure SQL.
Область применения этого сервиса созвучна с применением cloud-а вообще:
- Источники данных географически распределены или находятся в облаке
- Необходима эластичная, легко маштабируемая мощность
- Нерегулярная и пиковая обработка больших кусков данных
Как я уже отметил, болшая часть материалов находся в данный момент под NDA, и мне не удается найти ни одной полезной картинки без отметки Microsoft Confidential.