
Введение
Ранжирование документов в поисковых машинах - процесс весьма и весьма сложный. Разработчики постоянно пытаются совершенствовать алгоритмы ранжирования, преследуя, как правило, две большие цели - улучшение качества поиска и уменьшение возможности искусственных воздействий на ранжирование результатов. Та или иная поисковая машина может учитывать множество факторов, так или иначе влияющих на положение конкретного документа в выдаче по конкретному запросу. Большую часть своих достижений в области ранжирования документов разработчики поисковых алгоритмов хранят в строгом секрете, ограничиваясь публикациями либо каких-то весьма общих фактов, либо, наоборот, описанием очень частных задач, возможно, чрезвычайно интересных с точки зрения разработчика, но мало полезных на практике тем, что пытается улучшить ранжирование конкретного сайта по конкретным запросам. Специалисты в области SEO, поэтому, очень ограничены в информации и могут добывать ее только экспериментальным путем, оценивая работу поисковых алгоритмов путем построения так называемой модели "чёрного ящика" с известными выходными и входными параметрами и неизвестным внутренним устройством. Манипулируя входной информацией, т.е. изменяя для конкретных документов факторы, которые учитываются при ранжировании, и оценивая изменение выходной информацией, т.е. положением этих документов в выдаче по конкретным запросам, можно сделать определенные выводы о том, какие факторы и каким образом учитываются поисковыми машинами. Это знание позволит сформировать оптимальную стратегию продвижения ресурса в поисковых машинах в целью привлечения максимального количества целевых посетителей при минимальных затратах.
Специалистов по поисковому продвижению, работающих в России, интересуют, как правило, два сектора рынка, на котором они предлагают свои услуги - русскоязычный и англоязычный поиск. По данным статистических сервисов SpyLog и LiveInternet структура русскоязычного поискового трафика на октябрь 2005 года следующая - около 50% приходится на долю Яндекса, около 20% - на долю Рамблера, и порядка 15% составляет поисковый трафик из Google. Среди остальных поисковых сервисов, только, пожалуй, поиск от Mail.Ru, использующий поисковую выдачу того же Google, с трудом дотягивает до 5%-ного барьера. В англоязычном сегменте по данным агентств Nielsen NetRatings и comScore Media Metrix, поисковый трафик поделен примерно в тех же пропорциях между тремя основными поисковыми сервисами - Google, который с учетом порталов использующих его поисковую выдачу (таких как, например, AOL и Netscape) обслуживает примерно половину поисковых запросов, Yahoo! с долей около 30% и MSN Search с долей порядка 15%. Поэтому влияние различных факторов на ранжирование мы будем оценивать на примере именно этих поисковых машин. Все эти поисковые машины используют одинаковый набор основополагающих факторов, которые можно разделить на 3 большие категории:
1. Статические (не зависящие от запроса).
Как правило, это некий агрегированный показатель, который носит название статического ранга или авторитетности документа и зависит от количества и ранга документов, ссылающихся на данный документ. Он является внешним фактором, так зависит только от внешних показателей, не принимая во внимание содержимое документа.
2. Динамические (зависящие от запроса) внутренние (страничные).
Они учитывают степень соответствия запросу содержимого самого документа.
3. Динамические (зависящие от запроса) внешние (ссылочные).
Как правило, они учитывают степень соответствия запросу текста ссылок на документ (в среде русскоязычных специалистов по оптимизации такой фактор носит название "ссылочное ранжирование"). Также одним из факторов может быть динамический (т.е. зависящий от запроса) ранг документа.
Конкретными поисковыми машинами может использоваться при ранжировании ряд дополнительных факторов. Например, количество документов с сайта, релевантных запросу, но мы опустим их рассмотрение в виду незначительности по сравнению с основными факторами. Рассмотрим основные факторы поподробнее.
1. Статические факторы
Статические факторы измеряют важность или авторитетность страницы, не обращая внимание на ее содержание.
Наиболее известным примером реализации статического фактора является показатель PageRank, использующийся в поисковой машине Google. В основу его вычисления положена вероятностная модель пользователя, блуждающего по документам сети. Предполагается, что он с равной вероятностью может перейти по любой ссылке, которую содержит документ. Так же с некоторой одинаковой для каждого документа вероятностью, пользователь может попасть на него не по ссылке с другого документа (например, набрав вручную адрес документа в адресной строке браузера или воспользовавшись "закладкой"). Таким образом, вероятность того, что пользователь посетит конкретный документ, которая и принята за ранг документа PageRank, равна
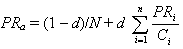
где
PRa - PageRank рассматриваемой страницы,
d - коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не попадет на следующий документ каким-нибудь другим образом),
N - общее количество документов,
PRi - PageRank i-й страницы, ссылающейся на страницу а,
Ci - общее число ссылок на i-й странице.
С ноября 2003 года, после революционного апдейта, названного англоязычными вебмастерами "Florida", в среде западных специалистов по поисковой оптимизации (SEO) стали муссироваться слухи, что Google перешел на модификацию алгоритма PageRank, носящую название Hilltop (http://www.cs.toronto.edu/~georgem/hilltop/). Этот алгоритм, патент на который Google получил в 2001 году, подразумевает использование не статического, а динамического (т.е. зависящего от запроса) ранга документа и основан на алгоритме HITS, использующемся в поисковой машине Teoma. Однако, Google не делал никаких официальных заявлений по поводу того, что при ранжировании теперь используется алгоритм Hilltop. Кроме того, в Google постоянно идут параллельные научные изыскания по модификации алгоритма PageRank, как правило, в плане учета тематики документа и запроса. Так, например, есть исследования по использованию в алгоритме не скалярного, а векторного показателя PageRank - Topic-Sensitive PageRank (http://dbpubs.stanford.edu:8090/pub/2002-6). Но, судя по всему, до широкой реалиазации подобных модификаций дело еще не дошло.
Тем не менее, вполне вероятно, что в классическую модель вычисления PageRank могли быть внесены какие-либо поправки. Ведь основные недостатки этой модели состоят в том, что, во-первых, она требует больших вычислительных мощностей. Во-вторых, все ссылки считаются равноправными, что в реальности, естественно, не так - одни ссылки заметнее и более привлекательны для пользователя, другие - наоборот, упрятаны в "подвалы" или сливаются с окружающим текстом, вероятность перехода по тематической ссылке, напрямую связанной с контентом документа тоже сильно отличается от перехода по никак тематически не связанной ссылке. Официальной информации о введении каких-либо корректировок в классический алгоритм нет, однако нельзя исключать тот факт, что с одной стороны могли быть введены какие-либо упрощения для уменьшения количества вычислений, а с другой стороны - добавлены какие-либо поправки, учитывающие неоднородность ссылок между различными документами. Поэтому более корректно в общей форме можно считать статическим фактором взвешенное некоторым образом количество ссылок на документ. Отсюда напрашивается простой вывод - чем больше ссылок на документ, тем выше его статический ранг. Чем больший статический ранг имеет ссылающийся документ, тем больший вклад он сделает в статический ранг того, документа на который он ссылается. Как правило, из всех страниц сайта, наибольший статический ранг имеют главные страницы - на них ссылаются все внутренние страницы, кроме того, и внешние ссылки ведут, как правило, на них. Далее идут страницы основного меню, которые также имеют ссылки со всех страниц сайта. Далее величина статического ранга спускается по уровням иерархии сайта. Чем плотнее перелинкованы между собой документы сайта, тем более близки будут их статические ранги. Для примера приведем результаты расчета по классическому алгоритму PageRank (при d=0,85) для многоуровневой иерархической структуры:
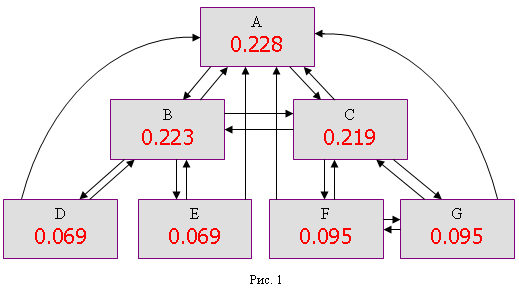
Четко прослеживается уменьшение значения PageRank со спуском по иерархической лестнице (уровни A, B-C и D-E-F-G) и стремление к выравниванию показателей PageRank у более плотно перелинкованных документов (связка С-F-G по сравнению со связкой B-D-E).
Хороший наглядный инструмент для расчетов по классическому алгоритму PageRank для небольших групп документов (максимальное количество равно 26) с произвольно задаваемой структурой перелинковки находится по адресу http://www.webworkshop.net/pagerank_calculator.php. Единственный нюанс - для того, чтобы выполнялось условие равенства суммы значений показателей PageRank единице (вероятность того, что пользователь находится на любой странице), надо результаты расчета для каждой страницы разделить на число документов. С помощью этого сервиса можно наглядно разобраться в том, как распределяется вероятность посещения пользователем документа (PageRank) при различных схемах перелинковки документов.
Схожие реализации определения статических факторов используются, судя по всему и в остальных рассматриваемых поисковых машинах. Например, взвешенный индекс цитирования (ВИЦ) в Яндексе (также в некоторых документах разработчики Яндекса употребляют термин "ссылочный ранг"), или Web Rank в Yahoo! Исключение составляет разве что Рамблер. Его разработчики заявляют, что в качестве статического фактора для каждого документа используется так называемый "коэффициент популярности", который, как и алгоритм PageRank, основан на учете гиперссылок между страницами сети, однако реализация Рамблера дополнительно использует данные о реальной посещаемости страниц, полученные от счетчика Top100.
Показатель PageRank Google интересен еще и тем фактом, что его значение, хотя и явно нелинейно нормированное и весьма грубо округленное, можно узнать для конкретного документа с помощью панели инструментов Google ToolBar. Этот показатель весьма часто используется для оценки значимости конкретного документа в процессе обмена с ним ссылками или приобретения ссылок с него многими SEO-специалистами.
Итак, какое же место занимает статический ранг документа среди других факторов ранжирования? Так как этот показатель не зависит от запроса, то он играет вспомогательную роль, используясь как весовой коэффициент при учете факторов, зависящих от запроса. Однако, этим показателем отнюдь не следует пренебрегать, так как он может существенно усилить эффект от динамических факторов.
2. Динамические внутренние факторы
Эти факторы еще называют страничными факторами. Они измеряют собственно релевантность текста страницы, то есть показывают, насколько содержимое самой страницы соответствует определенному запросу. Это наиболее понятные и логичные показатели, значение которых весьма часто сильно преувеличивается начинающими специалистами в области поисковой оптимизации.
Действительно, раньше соответствие содержимого документа запросу было единственным фактором, использующимся в ранжировании, но легкость манипулирования страничными факторами (любой владелец сайта легко может вносить какие угодно изменения в содержимое страниц), заставила всё большее значение придавать внешним факторам, воздействовать на которые гораздо сложнее.
К основным страничным факторам относятся:
- Внутридокументная частота поисковой фразы
- Элементы форматирования текста
- Вхождение слов запроса в служебные теги и атрибуты
Рассмотрим их поподробнее.
Одним из самых распространенных заблуждений считается, что внутридокументная частота - это просто отношение числа вхождений слов из поисковой фразы к общему количеству слов документа. Разработчики поисковых машин давно и с явным удовольствием занимаются совершенствованием алгоритмов ее расчета. Любителей потеоретизировать могу отослать к замечательному документу под авторством Ильи Сегаловича и Михаила Маслова "Яндекс на РОМИП-2004. Некоторые аспекты полнотекстового поиска и ранжирования в Яндекс", расположенным на корпоративном сайте Яндекса по адресу http://company.yandex.ru/articles/romip2004.xml. В этом документе вам встретятся такие понятия как "препроцессинг запроса", "фильтрация по кворуму", "релевантные пассажи", "расчет веса словопозиции", "функция контрастности" и т.п. То есть вычисление внутридокументной частоты - вещь весьма непростая. Надо полагать, что у разработчиков других поисковых машин дела с этим обстоят не хуже.
Практика же показывает, что достаточно хотя бы одного точного вхождения требуемой поисковой фразы в тексте документа для того, что бы больше не останавливаться на этом вопросе. Тем более пытаться искусственно повысить концентрацию ключевой фразы в ущерб естественности текста. Это является большой ошибкой. В угоду весьма сомнительному выигрышу в плане страничной релевантности, мы рискуем получить большой ущерб в плане юзабилити (пользователю может быть просто неприятно читать "искусственный" текст) и повышенную вероятность санкций со стороны модераторов поисковых машин, если подобное творчество попадется им на глаза.
Что же касается элементов форматирования текста, то за вхождение слов запроса в некоторые области текста, выделенные соответствующими тегами (<h1>, ..., <h6>, <strong>, <em>, <b>, <i>) могут начислять некоторые дополнительные "баллы" в плюс к общему значению релевантности текста документа запросу. Здесь опять же крайне рекомендую не злоупотреблять этими тегами в ущерб читабельности документа. Всё должно быть в меру и как можно естественней.
Вхождение слов запроса в служебные теги и атрибуты тоже можно охарактеризовать как некий "бонус" к общей релевантности текста документа запросу. Наибольший эффект дает точное вхождение поисковой фразы в тег title. Причем, поисковыми машинами могут накладываться ограничения на длину учитываемого фрагмента текста по числу символов или слов в том или ином теге или атрибуте. Эти ограничения могут быть определены в результате несложных экспериментов. Учет служебных тегов и атрибутов различными поисковыми машинами можно представить в виде следующей сводной таблицы:
| Яндекс | Рамблер | Yahoo! | MSN Search | ||
|---|---|---|---|---|---|
| тег <title> | + | + | + | + | + |
| мета-тег <description> | - | - | - | + | - |
| мета-тег <keywords> | + * | - | - | - | - |
| атрибут alt тега <img> | - | + | + | - | - |
| атрибут title тега <img> | - | - | - | - | - |
| атрибут title тега <a> | - | - | - | - | - |
* - при условии наличия ключевого слова в других частях документа
При размещении ключевых слов в различных частях документа следует обращать внимание на то, каким образом это повлияет на формирование сниппетов - кратких аннотаций, создаваемых поисковыми машинами из фрагментов текста документа и приводимых в выдаче по поисковому запросу рядом со ссылкой на документ. Принципы формирования сниппетов в результатах поиска различных поисковых машин довольно легко определяются экспериментальным путем.
Отмечу, что упомянуты наиболее значимые страничные факторы. Различные поисковые машины могут использовать дополнительные факторы, как правило, очень слабо влияющие на релевантность, например, вхождение ключевых слов в URL документа, учитываемое Google.
Не стоит забывать и о том, что общий вклад страничных факторов в итоговое значение релевантности документа запросу усиливается значением статического фактора как весовым коэффициентом. Поэтому, чем больше статический ранг документа, тем больше эффект от страничных факторов. Это особенно чётко прослеживается при ранжировании документов по низкочастотным и малопопулярным запросам, когда влияние динамических внешних факторов стремится к нулю. В этих случаях связка статического ранга и страничных факторов играет основную роль. Однако она становится бессильна, если в дело вступают самые сильные факторы - внешние динамические.
3. Динамические внешние факторы
Динамические внешние или ссылочные факторы измеряют релевантность ссылок на страницу с других страниц, т.е. показывают насколько соответствующей запросу эта страница считается другими документами. Среди русскоязычных SEO-специалистов этот фактор носит название "ссылочного ранжирования".
Влияние конкретной текстовой ссылки на релевантность документа запросу, зависит от нескольких показателей. Один из них - релевантность текста ссылки запросу. Наибольший эффект от текстовой ссылки при ранжировании документа, на который она ведет, по определенному запросу возникает тогда, когда поисковая фраза имеет точное вхождение в её текст. Если же точного вхождения нет, но все слова из поисковой фразы встречаются в тексте ссылки, то эффект от нее при прочих равных будет намного меньше. Если же хотя бы одно слово из поисковой фразы в тексте ссылки не присутствует, то влияние ее может вообще быть равно нулю. Поэтому точное вхождение фразы - очень важный нюанс при учете ссылочных факторов. Отметим также, что поисковые машины Google и Yahoo! при учете ссылочного ранжирования приравнивают к текстовым ссылкам также значение атрибута alt тега <img>, если он находится внутри тега <a> (т.е. изображение, описываемое этим тегом, является ссылкой). Некоторые поисковые машины, например Яндекс, в качестве текстовой ссылки могут учитывать описание сайта в собственном каталоге. Так же поисковые машины могут накладывать ограничения на количество слов или символов текстовой ссылки, учитываемых при определении ее релевантности запросу. Эти ограничения для конкретных поисковиков можно определить с помощью несложных экспериментов.
Другой важный момент - при оценке вклада конкретной текстовой ссылки в общую релевантность учитывается статический ранг ссылающейся страницы как весовой коэффициент. То есть, чем авторитетней ссылающаяся станица, тем больший эффект от текстовой ссылки с нее при прочих равных, будет достигнут.
И, наконец, третья составляющая вклада ссылочного ранжирования от конкретной ссылки на документ в общее значения релевантности этого документа запросу - это статический ранг самого этого документа, который тоже используется в качестве весового коэффициента. Таким образом, эффект от ссылки усиливается дважды - статическим рангом ссылающейся страницы и статическим рангом страницы, на которую она ссылается. Если оба эти значения довольно велики, то получается своеобразный "кумулятивный" эффект, всего одна ссылка может вывести документ в топ поисковой выдачи.
Именно благодаря дополнительному усилению влияния статическим рангом ссылающейся страницы, а также тем, что количество учитываемых ссылок может быть сколь угодно большим, и достигается преимущество влияния ссылочных факторов перед страничными. Вклад страничных факторов в общую релевантность документа запросу ограничен. Мы можем создать идеальный документ по отношению к определенной поисковой фразе, мы можем достичь максимум эффекта от страничных факторов для релевантности по этому запросу, но на этом возможности внутренних факторов исчерпываются, повышать их вклад в общую релевантность документа можно будет только увеличивая статический ранг документа, выступающий весовым коэффициентом. В случае же ссылочных факторов мы можем наращивать эффект почти бесконечно (наши возможности теоретически ограничиваются только числом документов в поисковой базе конкретного поисковика), способствуя появлению на других документах текстовых ссылок, релевантных запросу. Эффект от страничных же факторов при этом вообще может быть нулевой - зачастую в топе поисковой выдачи встречаются документы, в тексте которых вообще не встречается ключевых слов из поисковой фразы, положение достигнуто исключительно за счет текстов внешних ссылок.
Почему же поисковые машины вручили в руки оптимизаторам столь грозное оружие для воздействия на алгоритм, как ссылочное ранжирование? Во-первых, получить ссылку с определенным текстом (а ведь релевантность ссылки запросу - очень важный момент) с чужого сайта - задача довольно сложная. То есть воздействовать на этот фактор сложнее, чем на остальные.
С другой стороны, поисковые машины стараются учитывать ссылочные факторы как можно более осторожно, дабы минимизировать воздействие на них. Разрабатываются различные блокирующие и понижающие фильтры, как автоматические, так и накладываемые вручную. Например, Яндекс автоматически отфильтровывает при учете ссылочного ранжирования так называемые сквозные ссылки, т.е. те, которые содержатся на каждой странице сайта (или, строже говоря, на некотором числе страниц сайта, большем некоторого порогового значения). Также могут накладываться и другие подобные фильтры, призванные отсечь ошибочные, искусственные или малоавторитетные ссылки. Для фильтрации ошибочных и искусственных может применяться отношение числа текстовых ссылок на документ, релевантных данной поисковой фразе, к числу всех текстовых ссылок на документ. Если это отношение слишком мало, то делается вывод об ошибочности, если слишком велико - то об искусственности этих ссылок. Малоавторитетные ссылки могут отфильтровываться при учете ссылочного ранжирования, если значение статического ранга ссылающего документа ниже установленного порогового значения. Также искусственные ссылки могут определяться и отфильтровываться в случае, если в достаточно короткий срок робот проиндексирует подозрительно большое количество внешних ссылок на документ со сравнительно небольшим значением статического ранга. Подобный фильтр, применяемый в Google, получил в среде англоязычных вебмастеров название "sandbox" ("песочница"). Также в Google существует фильтр на учет ссылочного ранжирования для недавно зарегистрированных доменов при ранжировании по широкому ряду коммерческих запросов (это фильтр называют "aging" либо считают разновидностью фильтра "sandbox").
На ресурсы, получить ссылку с которых на любой документ возможно любому желающему без премодерации (так называемые FFA - free-for-all link pages, доски объявлений, форумы, гостевые книги и т.п.), могут накладываться фильтры, блокирующие учет ссылок с этих ресурсов либо только при расчете ссылочного ранжирования либо полностью (т.е. также и при расчете статического ранга). Но, как правило, автоматическая фильтрация подобных ресурсов затруднена и поисковым машинам приходится привлекать для этой работы людские ресурсы.
Явные массовые попытки воздействия на внешние факторы, такие как, например, создание линк-ферм (сообществ сайтов, массово ссылающихся друг на друга) также пресекаются поисковыми машинами. На ресурсы, использующие подобные техники, могут накладываться фильтры, блокирующие учет ссылок на них. Также подобные фильтры могут накладываться на сайты, ведущие массовый беспорядочный и бессистемный обмен ссылками.
Хорошим подспорьем в плане корректного учета ссылок мог бы стать учет тематики ссылающегося документа и документа, на который ведет ссылка. Однако вопрос автоматического точного определения тематики - весьма непростая задача. Поисковые машины, несомненно, проводят исследования в этой области, но судя по всему, до внедрения подобных методов еще весьма далеко.
4. Тактика воздействия на основные факторы
С учетом всего вышесказанного можно сделать вывод, что для хорошего ранжирования по наиболее популярным запросам без ссылочных факторов никак не обойтись. Как бы идеально под нужный запрос ни был составлен ваш документ, какой бы большой статический ранг он ни имел, в выдаче его обойдут конкуренты, заботящиеся о появлении в текстовых ссылках на самые авторитетные страницы своих сайтов (как правило, это главные страницы) точных вхождений поисковой фразы. На штурм высокопопулярных запросов бросаются все ресурсы для естественного (регистрация в каталогах, тематический обмен ссылками, публикация новостей и пресс-релизов на сторонних сайтах и т.п.) и искусственного (покупка ссылок) воздействия именно на внешние факторы - статический ранг и, в первую очередь, ссылочное ранжирование. Страничные факторы здесь вторичны.
Что касается запросов средней популярности, то здесь важен хороший баланс между всеми тремя факторами. Как правило, под такие запросы целесообразно оптимизировать не главную страницу сайта, отданную под высокопопулярные запросы, а страницы, находящиеся ниже в иерархии сайта, т.е. обладающие меньшим статическим рангом. К тому же, как правило, это уже более конкретные запросы и целесообразнее пользователя приводить непосредственно на те страницы, которые содержат информацию по теме запроса. Получить ссылку на внутреннюю страницу сайта естественным путем гораздо сложнее, а дополнительные ресурсы уже задействованы для получения текстовых ссылок, релевантных высокопопулярным запросам. Поэтому фактор ссылочного ранжирования в этом случае весьма ограничен документами, на которых можно получить ссылку, как правило, это ресурсы, позволяющие размещение ссылки без премодерации. Здесь уже более важную роль играют внутренние факторы, т.е. оптимизация содержимого страницы, и правильная организация структуры сайты, т.е. манипулирование статическим рангом внутренних документов сайта.
Эффект от низкопопулярных запросов уже, как правило, не стоит того, что бы тщательно оптимизировать под каждый из них определенные страницы сайта, так как подобных запросов очень много, и это потребует больших временных затрат. Однако, в массе своей низкопопулярные запросы дают хороший целевой трафик, хороший как в количественном, так и в качественном плане. Поэтому здесь большую роль играет наполнение сайта естественным тематическим контентом. Чем больше такого контента, тем больше точных вхождений низкочастотных запросов будет встречаться на страницах сайта. Здесь самую важную роль при ранжировании будет играть статический ранг этих документов, которым можно манипулировать за счет грамотной перелинковки с страницами сайта, имеющими высокий статический ранг за счет внешних ссылок. В этом случае одним из решений может стать использование карты сайта. В результате размещения на всех страниц сайта ссылки на карту, она имеет сравнительно большой статический ранг. А так как с карты сайта присутствуют ссылки на все страницы, то этот статический ранг равномерно перейдёт по ссылкам на все страницы сайта, добавит вес даже наиболее глубоко расположенным страницам. Так, например, для уже приведенной в качестве примера структуры, представленной на рис.1, добавление карты сайта (страницы, которая ссылается на все остальные, и на которую, в свою очередь, ссылаются все остальные) приводит к следующему результату:
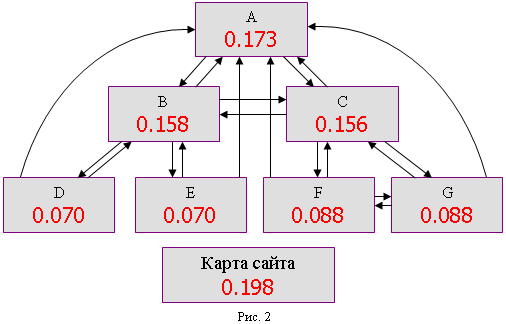
Как видим, разница между величинами значений PageRank (оцениваем относительные, а не абсолютные показатели, так как число документов в группе изменилось, и вероятность распределяется по большему числу документов) для различных документов стала меньше. Вероятности более равномерно распределились между документами.
5. Перспективы развития алгоритмов ранжирования
На мой взгляд, общий вектор, в направлении которого в ближайшее время будут двигаться поисковые машины в плане усовершенствования алгоритмов ранжирования, задан в Заявке на Патент США № 20050071741 "Information Retrieval Based on Historical Data" ("Получение информации, основанное на временных данных"), поданной компанией Google 31 марта 2005 года. В этом документе даны теоретические аспекты учета различных дополнительных факторов для коррекции релевантности документа запросу. Эти факторы разбиты на несколько категорий:
- Временные данные
Дата регистрации домена, дата первой индексации сайта, документа, динамика изменения документа, данные о переходе пользователей (click-through rate) на страницы сайта по ссылкам в результатах поиска и т.п. - Информация о входящих ссылках
Динамика появления и изменения ссылок на документ, возраст ссылок на документ, тематика ссылок на документ, процент схожих текстов ссылок на документ и т.д. - Информация об исходящих ссылках
Динамика появления и изменения исходящих ссылок, качество и тематика ресурсов, на которые ведут ссылки и т.п. - Информация о домене
Дата окончания срока регистрации домена, DNS records, адреса name-серверов, хостинг-компания и расположение хостинга и т.п., динамика изменения этих данных. - Информация о ранжировании
Динамика изменений в ранжировании сайта, учет сезонности и "ажиотажности" тематики сайта и т.п. - Поведение пользователя
Частота визитов пользователей на страницы сайта и продолжительность проведенного там времени и т.п. - Данные, предоставляемые пользователем
Динамика появления страниц сайта в данных, генерируемых пользователями (закладки, кеш и временные файлы браузеров пользователей и т.п.) - Тематика документа
и др.
Все эти дополнительные факторы призваны сделать более корректным учет основных факторов и уменьшить возможность искусственного влияния на них. Некоторые из них, похоже, уже активно используются Google для составления различных фильтров для внешних факторов (упоминавшиеся выше фильтры "sandbox" и "aging"), а некоторые еще ждут своего часа. Другие поисковые машины, вероятно, тоже будут работать в плане автоматического определения и фильтрации искусственных ссылок и контента.
Подытоживая, хотелось бы отметить, что именно естественность содержимого документа и ссылок на него будет всё больше и больше превалировать при ранжировании документов. Новые всё более хитроумные фильтры будет всё сложнее и сложнее обходить искусственным путем, это будет требовать всё больших затрат. Делайте хорошие, интересные для пользователей сайты, наполняйте их качественным уникальным контентом, заботьтесь об их корректной работе с технической точки зрения, популяризируйте их - и будет вам счастье в виде качественного поискового трафика. Ну, и конечно, не забывайте держать руку на пульсе "чёрных ящиков" алгоритмов ранжирования поисковых машин.