
Понимание моделей памяти, используемых в Linux, - это первый шаг к освоению на более высоком уровне структуры операционной системы Linux и ее реализации. В этой статье модели памяти Linux и управление памятью рассматриваются на ознакомительном уровне.
Операционная система Linux использует монолитный подход, при котором определяется набор примитивов или системных вызовов для реализации служб операционной системы, таких как управление процессами, параллельная работа и управление памятью, в нескольких модулях, работающих в режиме супервизора. И хотя Linux в целях совместимости поддерживает модель модуля управления сегментами (segment control unit) как символическое представление, она использует эту модель на минимальном уровне.
Основными задачами управления памятью являются:
- Управление виртуальной памятью - логический уровень между запросами памяти в приложениях и физической памятью.
- Управление физической памятью.
- Управление виртуальной памятью на уровне ядра (модуль ядра, занимающийся распределением памяти - компонент, который пытается удовлетворить запросы к памяти). Запрос может быть выполнен из ядра или из программы пользователя.
- Управление виртуальным адресным пространством.
- Свопинг и кэширование.
Данная статья призвана помочь вам в освоении внутреннего устройства Linux с точки зрения управления памятью операционной системы. Рассматриваются следующие темы:
- Общая модель модуля управления сегментами и ее особенности в Linux.
- Общая модель управления страницами памяти и ее особенности в Linux.
- Физические детали области памяти.
В данной статье не рассматриваются детально вопросы управления памятью в ядре Linux, но информация по общей модели памяти и по работе с ней должна дать вам основу для дальнейшего изучения. Внимание в статье уделяется архитектуре x86, но вы можете использовать эти материалы и с другими аппаратными реализациями.
Архитектура памяти x86
В x86-архитектуре память разделяется на три типа адресов:
- Логический адрес - адрес расположения ячейки памяти, который может быть (а может и нет) связан непосредственно с физическим расположением. Логический адрес обычно используется при запросе информации из контроллера.
- Линейный адрес (или линейное адресное пространство ) - это память, адресация которой начинается с 0. Каждый следующий байт адресуется следующим последовательным номером (0, 1, 2, 3 и т.д.) до конца памяти. Так адресуют память большинство CPU не Intel-архитектуры. В Intel®-архитектурах используется сегментированное адресное пространство, в котором память разделяется на сегменты размером 64KB, а сегментный регистр всегда указывает на базовый адрес адресуемого сегмента. 32-битный режим в этой архитектуре рассматривается как линейное адресное пространство, но в нем тоже используются сегменты.
- Физический адрес - адрес, представленный битами физической адресной шины. Физический адрес может отличаться от логического; в этом случае модуль управления памятью транслирует логический адрес в физический.
CPU использует два модуля для преобразования логического адреса в его физический эквивалент. Первый называется модулем сегментации (segmented unit), а второй - модулем разделения на страницы (paging unit).
Рисунок 1. Два модуля преобразуют адресное пространство![]()
Давайте исследуем модель модуля управления сегментами.
Общая модель модуля управления сегментами
Сущность модели сегментации состоит в том, что память управляется при помощи набора сегментов. Естественно, каждый сегмент имеет отдельное адресное пространство. Сегмент состоит из двух компонентов:
- Базовый адрес - адрес некоторого места физической памяти
- Значение длины , указывающее длину сегмента
Сегментированный адрес тоже состоит из двух компонентов - селектора сегмента и смещения в сегменте. Селектор сегмента указывает на используемый сегмент (то есть, значения базового адреса и длины), а компонент смещения указывает смещение от базового адреса для реального доступа к памяти. Физический адрес реального месторасположения памяти является суммой значений смещения и базового адреса. Если смещение превышает длину сегмента, система генерирует нарушение защиты.
Подведем итоги:
Модуль сегментации представляется как -> модель Сегмент: Смещение также может быть представлен как -> Идентификатор сегмента: Смещение |
Каждый сегмент - это 16-битное поле, называемое идентификатором сегмента или селектором сегмента. Процессоры семейства x86 содержат несколько программируемых регистров, называемых сегментными, которые хранят эти селекторы сегментов. Такими регистрами являются cs (сегмент кода), ds (сегмент данных) и ss (сегмент стека). Каждый идентификатор сегмента указывает сегмент, который представлен 64-битным (8-байтным) дескриптором сегмента. Эти дескрипторы сегментов хранятся в GDT (глобальная таблица дескрипторов) и может быть также сохранена в LDT (локальная таблица дескрипторов).
Рисунок 2. Взаимодействие дескрипторов сегментов и регистров сегментов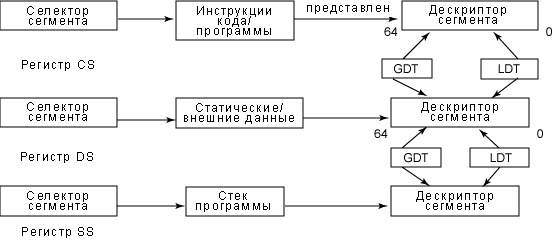
Каждый раз, когда селектор сегмента загружается в сегментный регистр, соответствующий дескриптор сегмента загружается из памяти в соответствующий непрограммируемый регистр CPU. Каждый дескриптор сегмента имеет длину 8 байт и представляет один сегмент в памяти. Они хранятся в таблицах LDT или GDT. Запись элемента дескриптора сегмента содержит и указатель на первый байт в связанном сегменте, представленном полем Base, и 20-битное значение (поле Limit), которое представляет размер сегмента в памяти.
Несколько других полей содержат специальные атрибуты, такие как уровень привилегий и тип сегмента (cs или ds). Тип сегмента представляется в четырехбитном поле Type.
Поскольку используются непрограммируемый регистр, к GDT или LDT не производится обращений до тех пор, пока не будет выполнена трансляция логического адреса в физический. Это ускоряет работу с памятью.
Селектор сегмента содержит:
- 13-битный индекс, указывающий на соответствующий дескриптор сегмента, содержащийся в GDT или LDT.
- Флаг TI (Table Indicator), который указывает, в какой таблице находится дескриптор сегмента. Если флаг равен 0, дескриптор находится в GDT; если 1 - в LDT.
- RPL (request privilege level) определяет текущий уровень привилегий CPU при загрузке соответствующего селектора сегмента в регистр сегмента.
Поскольку дескриптор сегмента имеет длину 8 байт, его относительный адрес в GDT или LDT вычисляется путем умножения самых значимых 13 битов селектора сегмента на 8. Например, если GDT хранится по адресу 0x00020000, и поле Index, указанное селектором сегмента, равно 2, тогда адрес соответствующего дескриптора сегмента равно (2*8) + 0x00020000. Максимальное количество дескрипторов сегмента, которое может быть сохранено в GDT, равно (2^13 - 1) или 8191.
На рисунке 3 показано графическое представление вычисления линейного адреса из логического.
Рисунок 3. Получение линейного адреса из логического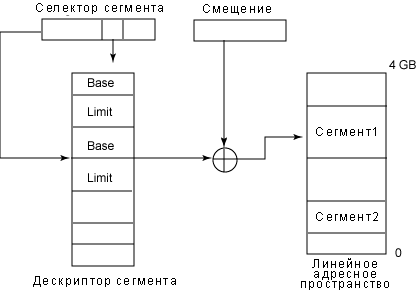
А теперь посмотрим, каковы отличия в Linux?
Модуль управления сегментами в Linux
В Linux эта модель имеет небольшие отличия. Я уже говорил о том, что Linux использует модель сегментирования ограниченно (в основном для совместимости).
В Linux все сегментные регистры указывают на один и тот же диапазон адресов сегментов - другими словами, каждый использует один и тот же набор линейных адресов. Это позволяет Linux использовать ограниченное число дескрипторов сегментов, то есть, все дескрипторы могут храниться в GDT. Двумя преимуществами этой модели являются:
- Управление памятью проще при использовании всеми процессами одинаковых значений сегментных регистров (когда они совместно используют одинаковый набор линейных адресов).
- Может быть достигнута совместимость с большинством архитектур. Некоторые RISC-процессоры тоже поддерживают такой ограниченный метод сегментирования.
На рисунке 4 показаны эти отличия.
Рисунок 4. В Linux сегментные регистры указывают на один и тот же набор адресов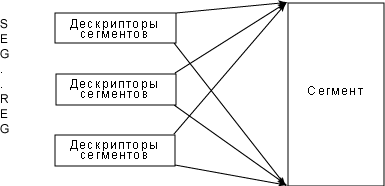
Дескрипторы сегментов
Linux использует следующие дескрипторы сегментов:
- Сегмент кода ядра
- Сегмент данных ядра
- Сегмент кода пользователя
- Сегмент данных пользователя
- Сегмент TSS
- Сегмент LDT по умолчанию
Рассмотрим детально каждый из них.
Дескриптор сегмента кода ядра в GDT имеет следующие значения:
- Base = 0x00000000
- Limit = 0xffffffff (2^32 -1) = 4GB
- G (флаг единицы сегментирования) = 1 для размера сегмента, выраженного в страницах
- S = 1 для обычного сегмента кода или данных
- Type = 0xa для сегмента кода, который можно прочитать и выполнить
- Значение DPL = 0 для режима ядра
Линейный адрес для этого сегмента равен 4 GB. S =1 и type = 0xa обозначают сегмент кода. Селектор находится в регистре cs. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _KERNEL_CS.
Дескриптор сегмента данных ядра имеет аналогичные значения за исключением поля Type, значение которого установлено в 2. Это указывает на то, что сегмент является сегментом данных и селектор хранится в регистре ds. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _KERNEL_DS.
Сегмент кода пользователя используется совместно всеми процессами в пользовательском режиме. Соответствующий дескриптор сегмента, хранящийся в GDT, имеет следующие значения:
- Base = 0x00000000
- Limit = 0xffffffff
- G = 1
- S = 1
- Type = 0xa для сегмента кода, который можно прочитать и выполнить
- DPL = 3 для пользовательского режима
Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _USER_CS.
В дескрипторе сегмента данных пользователя есть только одно изменение по сравнению с предыдущим дескриптором - поле Type установлено в 2 и определяет сегмент данных, которые можно прочитать и записать. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _USER_DS.
Кроме этих дескрипторов сегментов GDT содержит два дополнительных дескриптора сегментов для каждого созданного процесса - для сегментов TSS и LDT.
Каждый дескриптор сегмента TSS указывает на отдельный процесс. TSS хранит информацию об аппаратном контексте для каждого CPU, который принимает участие в переключении контекста. Например, при переключении режимов U->K x86 CPU получает адрес стека режима ядра из TSS.
Каждый процесс имеет свой собственный TSS-дескриптор, хранящийся в GDT. Значения этого дескриптора таковы:
- Base = &tss (адрес поля TSS дескриптора соответствующего процесса; например,
&tss_struct), который определен в файле schedule.h ядра Linux - Limit = 0xeb (сегмент TSS занимает 236 байт)
- Type = 9 или 11
- DPL = 0. Пользовательский режим не обращается к TSS. Флаг G очищен
Все процессы совместно используют сегмент LDT по умолчанию . По умолчанию он содержит нулевой дескриптор сегмента. Этот дескриптор сегмента LDT по умолчанию хранится в GDT. Сгенерированный ядром Linux LDT занимает 24 байта. По умолчанию всегда присутствуют три записи:
LDT[0] = null LDT[1] = сегмент кода пользователя LDT[2] = дескриптор сегмента данных/стека пользователя |
Вычисление TASKS
Знание NR_TASKS (переменной, определяющей количество одновременных процессов, поддерживаемых в Linux. Ее значение по умолчанию в исходном коде ядра равно 512, что позволяет иметь 256 одновременных подключений к одному экземпляру) необходимо для вычисления максимального количества разрешенных записей в GDT.
Максимальное количество разрешенных в GDT записей может быть определено по следующей формуле:
Общее количество записей в GDT = 12 + 2 * NR_TASKS. Возможное количество записей в GDT = 2^13 -1 = 8192. |
Из 8192 дескрипторов сегментов Linux использует 6 дескрипторов сегментов, еще 4 дополнительных для APM-функций (функции расширенного управления питанием), а 4 записи в GDT остаются не использованными. Таким образом, конечное число возможных записей в GDT равно 8192 - 14, или 8180.
В любой момент времени мы не можем иметь более чем 8180 записей в GDT, следовательно:
2 * NR_TASKS = 8180
и NR_TASKS = 8180/2 = 4090
Почему 2 * NR_TASKS? Потому что для каждого созданного процесса загружается не только TSS-дескриптор, используемый для обслуживания переключений контекста, но и LDT-дескриптор.
Это ограничение количества процессов в x86-архитектуре относилось к Linux 2.2, но после ядра 2.4 эта проблема была решена частично путем отказа от переключения аппаратного контекста (которое делало необходимым использование TSS), а также путем замены его переключением процесса.
Теперь, давайте рассмотрим страничную модель.
Обзор модели страничной организации
Модуль управления страницами преобразует линейные адреса в физические (см. рисунок 1). Набор линейных адресов группируется вместе, образуя страницы. Эти линейные адреса непрерывны по своей природе - модуль управления страницами отображает эти наборы непрерывной памяти в соответствующий набор непрерывных физических адресов, называемых страничными фреймами. Обратите внимание на то, что модуль управления страницами представляет RAM разделенным на страничные фреймы фиксированного размера.
По этой причине разбиение на страницы имеет следующие преимущества:
- Права доступа, определенные для страницы, будут действительны для группы линейных адресов, формирующих страницу
- Длина страницы равна длине страничного фрейма
Структура данных, отображающая эти страницы на страничные фреймы, называется, таблицей страниц. Эти таблицы страниц хранятся в основной памяти и инициализируются ядром перед разрешением работы модуля управления страницами. На рисунке 5 показана таблица страниц.
Рисунок 5. Таблица страниц определяет соответствие страниц страничным фреймам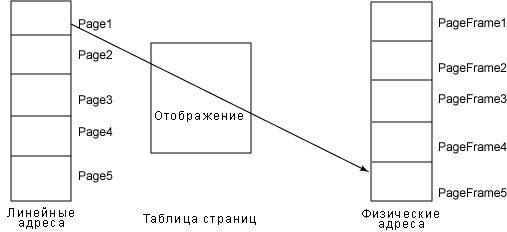
Обратите внимание на то, что набор адресов, содержащихся в Page1, соответствует определенному набору адресов, содержащихся в Page Frame1.
Linux использует модуль разделения на страницы более интенсивно, чем модуль сегментации. Как мы видели ранее в разделе "Linux и сегментация", каждый дескриптор сегмента использует один и тот же набор адресов для линейной адресации, минимизируя необходимость использования модуля сегментации для преобразования логических адресов в линейные. Используя модуль разбиения на страницы более часто, чем модуль сегментации, Linux значительно облегчает управление памятью и обеспечивает переносимость между различными аппаратными платформами.
Поля, используемые при разбиении страниц
Приведем описание полей, используемых для определения страниц в x86-архитектуре и помогающих управлять страницами в Linux. Модуль разбиения на страницы получает линейный адрес, который выдает модуль сегментации. Этот линейный адрес затем разбивается на следующие поля:
- Directory (каталог) представлен десятью MSB (Most Significant Bit - бит двоичного числа, имеющий наибольшее значение; MSB иногда называется "самый левый бит").
- Table (таблица) представлена десятью средними битами.
- Offset (смещение) представлено двенадцатью LSB (Least Significant Bit - бит двоичного числа, представляющий значение единицы, то есть определяющий, является число четным, или нечетным; LSB иногда называют "самым правым битом"; он аналогичен наименее значимой цифре десятичного числа, обозначающей единицы и расположенной на самой правой позиции).
Преобразование линейных адресов в их соответствующее физическое месторасположение является процессом, состоящим из двух шагов. На первом шаге используется таблица преобразования, называемая Page Directory (осуществляет переход от Page Directory к Page Table), а на втором шаге используется таблица, называемая Page Table (Page Table плюс Offset для запрашиваемого фрейма страницы). Этот процесс изображен на рисунке 6.
Рисунок 6. Поля адреса при разбиении на страницы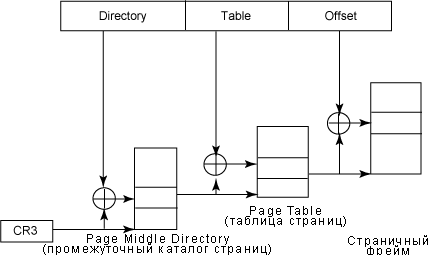
В начале физический адрес Page Directory загружается в регистр cr3. Поле directory в линейном адресе определяет запись в Page Directory, указывающую на нужную Page Table. Адрес в поле table определяет запись в Page Table, которая содержит физический адрес страничного фрейма, содержащего страницу. Поле offset определяет относительную позицию в страничном фрейме. Поскольку длина этого поля равна 12 битам, каждая страница содержит 4 KB данных.
Итак, физический адрес вычисляется следующим образом:
cr3+ Page Directory (10 MSBs) = указываетtable_basetable_base+ Page Table (10 средних бит) = указываетpage_basepage_base+ Offset = физический адрес (страничный фрейм)
Поскольку Page Directory и Page Table занимают 10 бит, они могут адресовать максимум 1024*1024 KB, а Offset может адресовать до 2^12 (4096 байт). Таким образом, суммарное адресуемое пространство в Page Directory равно 1024*1024*4096 (2^32 ячеек памяти, что равно 4 GB). То есть, на x86-архитектурах адресуемое пространство ограничено 4 GB.
Расширенное разбиение на страницы
Расширенное разбиение на страницы получается при удалении таблицы преобразования Page Table; тогда разделение линейного адреса осуществляется между Page Directory (10 MSB) и Offset (22 LSB).
22 бит LSB формируют границу в 4 MB для страничного фрейма (2^22). Расширенное разбиение на страницы существует вместе с обычным разбиением и включается для отображения большого числа непрерывных линейных адресов в соответствующие физические адреса. Операционная система удаляет Page Table и обеспечивает, таким образом, расширенное разбиение на страницы. Это разрешается путем установки флага PSE (page size extension).
36-битный PSE расширяет поддержку 36-битного физического адреса со страницами размером 4 MB и поддерживает также 4-байтную запись страничных каталогов, предоставляя, таким образом, простой механизм адресации физической памяти выше 4 GB и не требуя больших изменений дизайна операционных систем. Такой подход имеет практические ограничения, касающиеся потребности разбиения на страницы.
Модель разбиения на страницы в Linux
Разбиение на страницы в Linux аналогично обычному разбиению, но x86-архитектура имеет трехуровневый табличный механизм, состоящий из:
- Page Global Directory (pgd - глобальный каталог страниц), абстрактный верхний уровень многоуровневых таблиц страниц. Каждый уровень таблицы страниц имеет дело с различными размерами памяти - этот глобальный каталог может работать с областями размером 4 MB. Каждая запись будет являться указателем на более низкоуровневую таблицу каталогов меньшего размера, то есть pgd - это каталог таблиц страниц. Когда код проходит эту структуру (это делают некоторые драйверы), говорится, что выполняется "проход" по таблицам страниц.
- Page Middle Directory (pmd - промежуточный каталог страниц), промежуточный уровень таблиц страниц. На x86-архитектуре pmd не представлен аппаратно, но входит в pgd в коде ядра.
- Page Table Entry (pte - запись таблицы страниц), нижний уровень, работающий со страницами напрямую (ищите
PAGE_SIZE), является значением, которое содержит физический адрес страницы вместе со связанными битами, указывающими, например, что запись корректна, и соответствующая страница присутствует в реальной памяти.
Эта трехуровневая схема разбиения на страницы также реализована в Linux для поддержки областей памяти больших размеров. Если поддержка больших областей памяти не требуется, вы можете вернуться к двухуровневой схеме, установив pmd в "1".
Эти уровни оптимизируются во время компиляции, разрешая второй и третий уровни (с использованием того же самого набора кода) простым разрешением или запретом промежуточного каталога. 32-битные процессоры используют pmd-разбиение, а 64-битые используют pgd-разбиение.
В 64-битных процессорах:
- 21 бит MSB не используются
- 13 бит LSB представлены смещением страницы
- Оставшиеся 30 бит разделены на
- 10 бит для Page Table
- 10 бит для Page Global Directory
- 10 бит для Page Middle Directory
Как видно из архитектуры, для адресации фактически используются 43 бита. То есть, на 64-битных процессорах реально доступно 2 в степени 43 ячеек виртуальной памяти.
Каждый процесс имеет свой собственный набор каталогов страниц и таблиц страниц. Для обращения к страничному фрейму с реальными пользовательскими данными операционная система начинает с загрузки (на x86-архитектурах) pgd в регистр cr3. Linux сохраняет в TSS-сегменте содержимое регистра cr3 и затем загружает другое значение из TSS-сегмента в регистр cr3 каждый раз во время выполнения нового процесса в CPU. В результате модуль разбиения на страницы ссылается на корректный набор таблиц страниц.
Каждая запись в таблице pgd указывает на страничный фрейм, содержащий массив записей pmd, которые, в свою очередь, указывают на страничный фрейм, содержащий pte, который, наконец, указывает на страничный фрейм, содержащий пользовательские данные. Если искомая страница находится в файле подкачки, в таблице pte сохраняется запись файла подкачки, которая используется (при ошибке отсутствия страницы) при поиске страничного фрейма для загрузки в память.
На рисунке 8 показано, что мы добавляем смещение на каждом уровне таблиц страниц для отображения на соответствующую запись страничного фрейма. Эти смещения мы получаем, разбив линейный адрес, принятый из модуля сегментации. Для разбиения линейного адреса, соответствующего каждому компоненту таблицы страниц, в ядре используются различные макросы. Не рассматривая детально эти макросы, давайте посмотрим на схему разбиения линейного адреса.
Рисунок 7. Линейные адреса имеют различные размеры
Резервные страничные фреймы
Linux резервирует несколько станичных фреймов для кода ядра и структур данных. Эти страницы никогда не сбрасываются в файл подкачки на диск. Линейные адреса с 0x0 до 0xc0000000 (PAGE_OFFSET) используются кодом пользователя и кодом ядра. Адреса с PAGE_OFFSET до 0xffffffff используются кодом ядра.
Это означает, что из 4 GB только 3 GB доступны для пользовательского приложения.
Как разрешается разбиение на страницы
Механизм разбиения на страницы, используемый процессами Linux, имеет две фазы:
- Во время начальной загрузки система устанавливает таблицу страниц для 8 MB физической памяти.
- Затем вторая фаза завершает отображение для оставшейся физической памяти.
В фазе первоначальной загрузки за инициализацию разбиения на страницы отвечает вызов startup_32(). Эта функция реализована в файле arch/i386/kernel/head.S. Отображение этих 8 MB происходит с адреса выше PAGE_OFFSET. Инициализация начинается со статически определенного во время компиляции массива, называемого swapper_pg_dir. Во время компиляции он размещается по конкретному адресу (0x00101000).
Определяются записи для двух таблиц, определенных в коде статически - pg0 и pg1. Размер этих страничных фреймов по умолчанию равен 4 KB, если не установлен бит расширения размера страниц (page size extension) (дополнительная информация по PSE находится в разделе "Расширенное разбиение на страницы"). Тогда размер каждой равен 4 MB. Адрес данных, указываемый глобальным массивом, сохраняется в регистре cr3, что, я полагаю, является первым этапом установки модуля разбиения на страницы для процессов Linux. Остальные страничные записи устанавливаются во второй фазе.
Вторая фаза реализована в методе paging_init().
Отображение RAM выполняется между PAGE_OFFSET и адресом, представляющим границу 4 GB (0xFFFFFFFF) в 32-битной x86-архитектуре. Это означает, что RAM размером примерно в 1 GB может быть отображена при загрузке Linux, и это происходит по умолчанию. Однако, если установить HIGHMEM_CONFIG, то физическая память размером более 1 GB может быть отображена для ядра - имейте в виду, что это временная мера. Это делается вызовом kmap().
Зона физической памяти
Я уже показал вам, что ядро Linux (на 32-битной архитектуре) делит виртуальную память в отношении 3:1 - 3 GB виртуальной памяти для пространства пользователя и 1 GB для пространства ядра. Код ядра и его структуры данных должны размещаться в этом 1 GB адресного пространства, но даже еще большим потребителем этого адресного пространства является виртуальное отображение физической памяти.
Это происходит потому, что ядро не может манипулировать памятью, если она не отображена в его адресное пространство. Таким образом, максимальным количеством физической памяти, которое может обработать ядро, является объем памяти, который мог бы отобразиться в виртуальное адресное пространство ядра минус объем, необходимый для отображения самого кода ядра. В итоге Linux на основе x86-системы смогла бы работать с объемом менее 1 GB физической памяти. И это максимум.
Поэтому, для обслуживания большого количества пользователей, для поддержки большего объема памяти, для улучшения производительности и для установки архитектурно-независимого способа описания памяти модель памяти Linux должна была совершенствоваться. Для достижения этих целей в более новой модели каждому CPU был назначен свой банк памяти. Каждый банк называется узлом ; каждый узел разделяется на зоны . Зоны (представляющие диапазоны памяти) далее разбивались на следующие типы:
ZONE_DMA(0-16 MB): Диапазон памяти, расположенный в нижней области памяти, чего требуют некоторые устройства ISA/PCI.ZONE_NORMAL(16-896 MB): Диапазон памяти, который непосредственно отображается ядром в верхние участки физической памяти. Все операции ядра могут выполняться только с использованием этой зоны памяти; таким образом, это самая критичная для производительности зона.ZONE_HIGHMEM(896 MB и выше): Оставшаяся доступная память системы не отображается ядром.
Концепция узла реализована в ядре при помощи структуры struct pglist_data. Зона описывается структурой struct zone_struct. Физический страничный фрейм представлен структурой struct Page, и все эти структуры хранятся в глобальном массиве структур struct mem_map, который размещается в начале NORMAL_ZONE. Эти основные взаимоотношения между узлом, зоной и страничным фреймом показаны на рисунке 9.
Рисунок 8. Взаимоотношения между узлом, зоной и страничным фреймом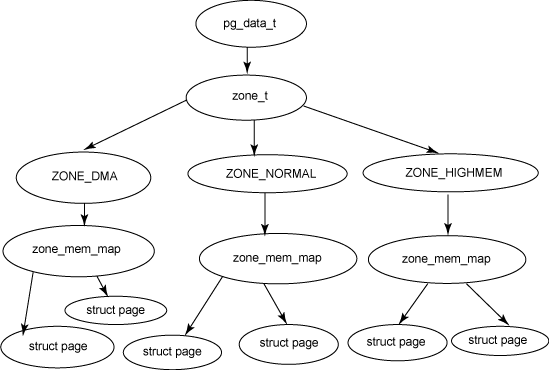
Зона верхней области памяти появилась в системе управления памятью ядра тогда, когда были реализованы расширение виртуальной памяти Pentium II (для доступа к 64 GB памяти средствами PAE - Physical Address Extension - на 32-битных системах) и поддержка 4 GB физической памяти (опять же, на 32-битных системах). Эта концепция применима к платформам x86 и SPARC. Обычно эти 4 GB памяти делают доступными отображение ZONE_HIGHMEM в ZONE_NORMAL посредством kmap(). Обратите внимание, пожалуйста, на то, что не желательно иметь более 16 GB RAM на 32-битной архитектуре даже при разрешенном PAE.
(PAE - разработанное Intel расширение адресов памяти, разрешающее процессорам увеличить количество битов, которые могут быть использованы для адресации физической памяти, с 32 до 36 через поддержку в операционной системе приложений, использующих Address Windowing Extensions API.)
Управление этой зоной физической памяти выполняется распределителем (allocator) зоны. Он отвечает за разделение памяти на несколько зон и рассматривает каждую зону как единицу для распределения. Любой конкретный запрос на распределение использует список зон, в которых распределение может быть предпринято, в порядке от наиболее предпочтительной к наименее предпочтительной.
Например:
- Запрос на пользовательскую страницу должен быть сначала заполнен из "нормальной" зоны (
ZONE_NORMAL); - если завершение неудачно - с
ZONE_HIGHMEM; - если опять неудачно - с ZONE_DMA.
Список зон для такого распределения состоит из зон ZONE_NORMAL, ZONE_HIGHMEM и ZONE_DMA в указанном порядке. С другой стороны, запрос DMA-страницы может быть выполнен из зоны DMA, поэтому список зон для таких запросов содержит только зону DMA.
Заключение
Управление памятью - это большой, комплексный и трудоемкий набор задач, один из тех, в которых разобраться непросто, потому что создание модели поведения системы в реальных условиях в многозадачной среде является трудной работой. Такие компоненты как планирование, разбиение на страницы и взаимодействие процессов предъявляют серьезные требования. Я надеюсь, что эта статья поможет вам разобраться в основных понятиях, необходимых для овладения задачами управления памятью в Linux, и обеспечит вас начальной информацией для дальнейших исследований.